|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 2 weeks ago | |
README.md
Rakentamassa koneoppimisratkaisuja vastuullisen tekoälyn avulla
Sketchnote: Tomomi Imura
Ennakkotesti
Johdanto
Tässä oppimateriaalissa alat tutkia, miten koneoppiminen vaikuttaa ja voi vaikuttaa jokapäiväiseen elämäämme. Jo nyt järjestelmät ja mallit osallistuvat päivittäisiin päätöksentekotehtäviin, kuten terveydenhuollon diagnooseihin, lainapäätöksiin tai petosten havaitsemiseen. On siis tärkeää, että nämä mallit toimivat luotettavasti ja tuottavat luottamusta herättäviä tuloksia. Kuten mikä tahansa ohjelmistosovellus, myös tekoälyjärjestelmät voivat epäonnistua tai tuottaa ei-toivottuja tuloksia. Siksi on olennaista ymmärtää ja selittää tekoälymallin käyttäytymistä.
Kuvittele, mitä voi tapahtua, jos käyttämäsi data mallien rakentamiseen ei sisällä tiettyjä väestöryhmiä, kuten rotua, sukupuolta, poliittisia näkemyksiä tai uskontoa, tai jos se edustaa näitä ryhmiä epätasapainoisesti. Entä jos mallin tuloksia tulkitaan suosivan tiettyä väestöryhmää? Mitä seurauksia sillä on sovellukselle? Lisäksi, mitä tapahtuu, jos malli tuottaa haitallisia tuloksia ja vahingoittaa ihmisiä? Kuka on vastuussa tekoälyjärjestelmän käyttäytymisestä? Näitä kysymyksiä tutkimme tässä oppimateriaalissa.
Tässä oppitunnissa:
- Opit ymmärtämään oikeudenmukaisuuden merkityksen koneoppimisessa ja siihen liittyvät haitat.
- Tutustut poikkeamien ja epätavallisten tilanteiden tutkimiseen luotettavuuden ja turvallisuuden varmistamiseksi.
- Ymmärrät, miksi on tärkeää suunnitella kaikille osallistavia järjestelmiä.
- Tutkit, miksi on olennaista suojella ihmisten ja datan yksityisyyttä ja turvallisuutta.
- Näet, miksi on tärkeää käyttää "lasilaatikko"-lähestymistapaa tekoälymallien käyttäytymisen selittämiseksi.
- Opit, miksi vastuu on keskeistä tekoälyjärjestelmien luottamuksen rakentamisessa.
Esitiedot
Esitietona suositellaan "Vastuullisen tekoälyn periaatteet" -oppimispolun suorittamista ja alla olevan videon katsomista aiheesta:
Lisätietoja vastuullisesta tekoälystä löydät tästä oppimispolusta

🎥 Klikkaa yllä olevaa kuvaa: Microsoftin lähestymistapa vastuulliseen tekoälyyn
Oikeudenmukaisuus
Tekoälyjärjestelmien tulisi kohdella kaikkia oikeudenmukaisesti ja välttää vaikuttamasta eri ryhmiin eri tavoin. Esimerkiksi, kun tekoälyjärjestelmät antavat suosituksia lääketieteellisestä hoidosta, lainahakemuksista tai työllistymisestä, niiden tulisi antaa samat suositukset kaikille, joilla on samanlaiset oireet, taloudelliset olosuhteet tai ammatilliset pätevyydet. Meillä kaikilla ihmisillä on perittyjä ennakkoluuloja, jotka vaikuttavat päätöksiimme ja toimintaamme. Nämä ennakkoluulot voivat näkyä datassa, jota käytämme tekoälyjärjestelmien kouluttamiseen. Tällainen manipulointi voi joskus tapahtua tahattomasti. On usein vaikeaa tietoisesti tietää, milloin tuot datassa esiin ennakkoluuloja.
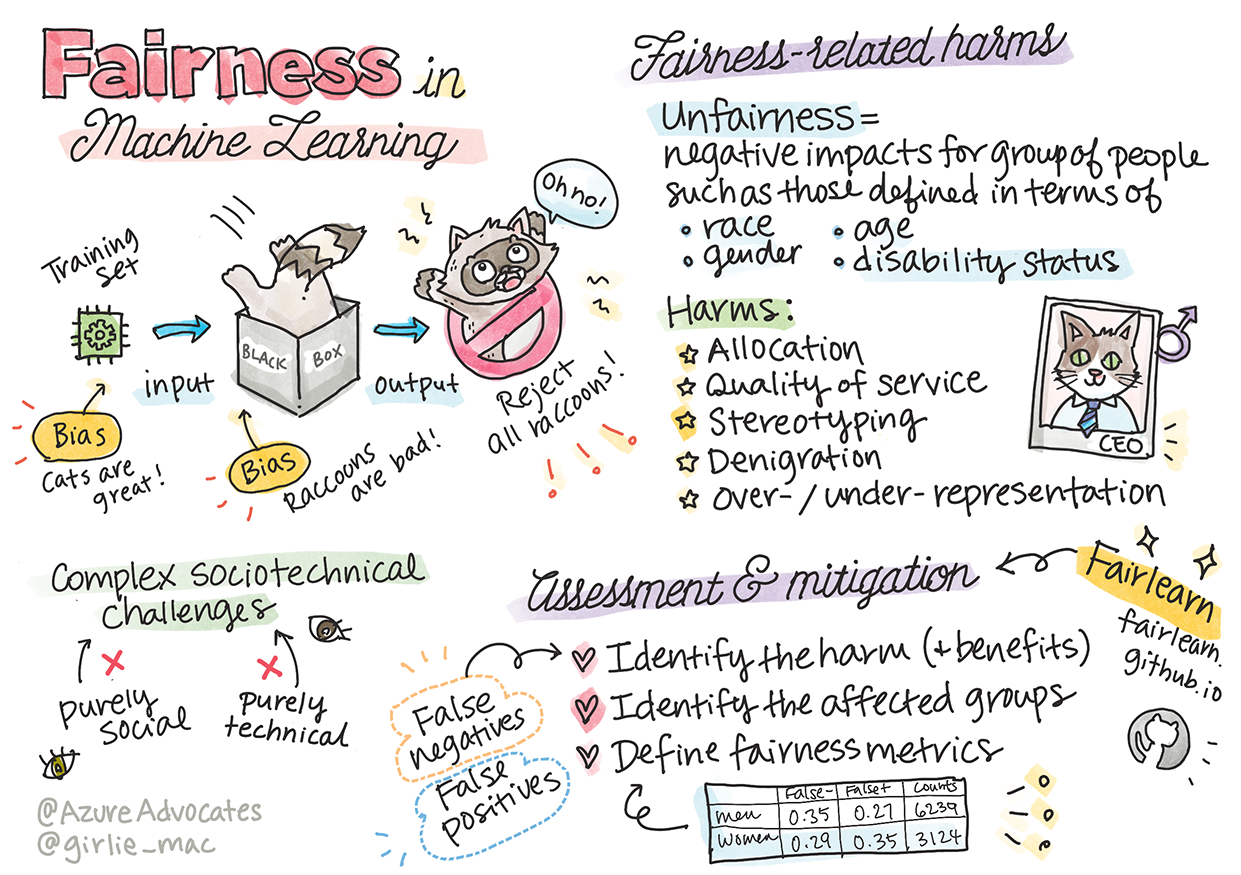
"Epäoikeudenmukaisuus" kattaa negatiiviset vaikutukset tai "haitat" tietylle ihmisryhmälle, kuten rodun, sukupuolen, iän tai vammaisuuden perusteella. Oikeudenmukaisuuteen liittyvät haitat voidaan luokitella seuraavasti:
- Allokaatio, jos esimerkiksi sukupuolta tai etnisyyttä suositaan toisen kustannuksella.
- Palvelun laatu. Jos data koulutetaan tiettyyn skenaarioon, mutta todellisuus on paljon monimutkaisempi, se johtaa huonosti toimivaan palveluun. Esimerkiksi käsisaippua-annostelija, joka ei tunnista tumman ihon sävyjä. Viite
- Halventaminen. Epäreilu kritiikki tai leimaaminen. Esimerkiksi kuvantunnistusteknologia, joka virheellisesti luokitteli tumman ihon sävyisiä ihmisiä gorilloiksi.
- Yli- tai aliedustus. Tietyn ryhmän näkymättömyys tietyssä ammatissa, ja palvelut tai toiminnot, jotka ylläpitävät tätä, aiheuttavat haittaa.
- Stereotypiointi. Tietyn ryhmän yhdistäminen ennalta määrättyihin ominaisuuksiin. Esimerkiksi kielikäännösjärjestelmä englannin ja turkin välillä voi sisältää epätarkkuuksia sukupuoleen liittyvien stereotypioiden vuoksi.
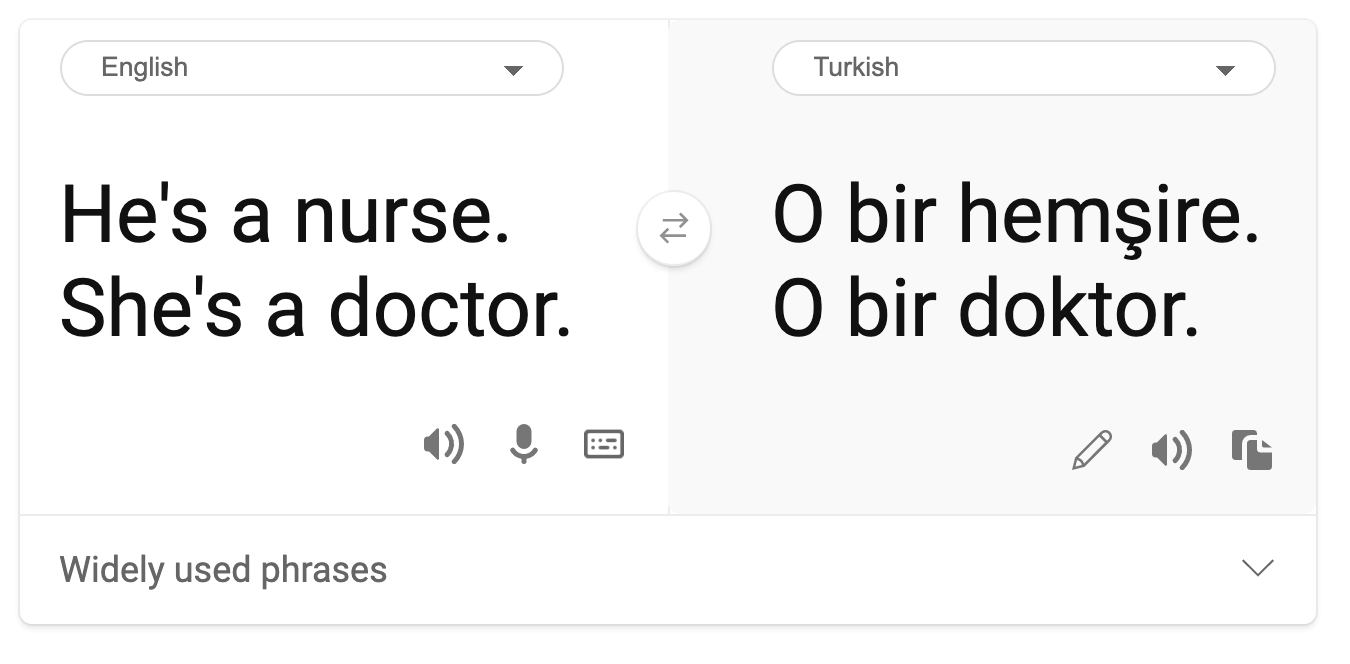
käännös turkiksi

käännös takaisin englanniksi
Kun suunnittelemme ja testaamme tekoälyjärjestelmiä, meidän on varmistettava, että tekoäly on oikeudenmukainen eikä ohjelmoitu tekemään puolueellisia tai syrjiviä päätöksiä, joita ihmisetkään eivät saa tehdä. Oikeudenmukaisuuden takaaminen tekoälyssä ja koneoppimisessa on edelleen monimutkainen sosio-tekninen haaste.
Luotettavuus ja turvallisuus
Luottamuksen rakentamiseksi tekoälyjärjestelmien on oltava luotettavia, turvallisia ja johdonmukaisia sekä normaaleissa että odottamattomissa olosuhteissa. On tärkeää tietää, miten tekoälyjärjestelmät käyttäytyvät erilaisissa tilanteissa, erityisesti poikkeustilanteissa. Tekoälyratkaisuja rakennettaessa on keskityttävä huomattavasti siihen, miten käsitellä monenlaisia olosuhteita, joita tekoälyratkaisut voivat kohdata. Esimerkiksi itseohjautuvan auton on asetettava ihmisten turvallisuus etusijalle. Tämän vuoksi auton tekoälyn on otettava huomioon kaikki mahdolliset skenaariot, kuten yö, ukkosmyrskyt tai lumimyrskyt, kadulle juoksevat lapset, lemmikit, tietyömaat jne. Se, kuinka hyvin tekoälyjärjestelmä pystyy käsittelemään laajan valikoiman olosuhteita luotettavasti ja turvallisesti, heijastaa sitä, kuinka hyvin datatieteilijä tai tekoälykehittäjä on ennakoinut tilanteita suunnittelussa tai testauksessa.
Osallistavuus
Tekoälyjärjestelmät tulisi suunnitella siten, että ne osallistavat ja voimaannuttavat kaikkia. Tekoälyjärjestelmiä suunnitellessaan ja toteuttaessaan datatieteilijät ja tekoälykehittäjät tunnistavat ja ratkaisevat järjestelmän mahdolliset esteet, jotka voisivat tahattomasti sulkea ihmisiä ulkopuolelle. Esimerkiksi maailmassa on miljardi vammaista ihmistä. Tekoälyn kehityksen myötä he voivat helpommin saada pääsyn laajaan valikoimaan tietoa ja mahdollisuuksia jokapäiväisessä elämässään. Esteiden poistaminen luo mahdollisuuksia innovoida ja kehittää tekoälytuotteita, jotka tarjoavat parempia kokemuksia kaikille.
Turvallisuus ja yksityisyys
Tekoälyjärjestelmien tulisi olla turvallisia ja kunnioittaa ihmisten yksityisyyttä. Ihmiset luottavat vähemmän järjestelmiin, jotka vaarantavat heidän yksityisyytensä, tietonsa tai elämänsä. Koneoppimismalleja koulutettaessa luotamme dataan parhaiden tulosten saavuttamiseksi. Tällöin datan alkuperä ja eheys on otettava huomioon. Esimerkiksi, onko data käyttäjän toimittamaa vai julkisesti saatavilla? Lisäksi datan kanssa työskenneltäessä on tärkeää kehittää tekoälyjärjestelmiä, jotka voivat suojata luottamuksellisia tietoja ja vastustaa hyökkäyksiä. Tekoälyn yleistyessä yksityisyyden suojaaminen ja tärkeiden henkilö- ja yritystietojen turvaaminen on yhä kriittisempää ja monimutkaisempaa. Yksityisyyteen ja tietoturvaan liittyvät kysymykset vaativat erityistä huomiota tekoälyssä, koska datan saatavuus on olennaista tekoälyjärjestelmien tarkkojen ja perusteltujen ennusteiden ja päätösten tekemiseksi.
- Teollisuutena olemme saavuttaneet merkittäviä edistysaskeleita yksityisyydessä ja turvallisuudessa, erityisesti GDPR:n (General Data Protection Regulation) kaltaisten säädösten ansiosta.
- Tekoälyjärjestelmien kohdalla meidän on kuitenkin tunnustettava jännite henkilökohtaisemman datan tarpeen ja yksityisyyden välillä.
- Kuten internetin myötä yhdistettyjen tietokoneiden syntyessä, myös tekoälyyn liittyvien turvallisuusongelmien määrä on kasvanut merkittävästi.
- Samalla olemme nähneet tekoälyn käytön turvallisuuden parantamisessa. Esimerkiksi useimmat modernit virustorjuntaohjelmat perustuvat tekoälyyn.
- Meidän on varmistettava, että datatieteen prosessimme sulautuvat harmonisesti uusimpiin yksityisyyden ja turvallisuuden käytäntöihin.
Läpinäkyvyys
Tekoälyjärjestelmien tulisi olla ymmärrettäviä. Läpinäkyvyyden keskeinen osa on tekoälyjärjestelmien ja niiden komponenttien käyttäytymisen selittäminen. Tekoälyjärjestelmien ymmärtämisen parantaminen edellyttää, että sidosryhmät ymmärtävät, miten ja miksi ne toimivat, jotta he voivat tunnistaa mahdolliset suorituskykyongelmat, turvallisuus- ja yksityisyyshuolenaiheet, puolueellisuudet, poissulkevat käytännöt tai ei-toivotut tulokset. Lisäksi uskomme, että niiden, jotka käyttävät tekoälyjärjestelmiä, tulisi olla rehellisiä ja avoimia siitä, milloin, miksi ja miten he päättävät ottaa ne käyttöön. Samoin heidän tulisi kertoa järjestelmien rajoituksista. Esimerkiksi, jos pankki käyttää tekoälyjärjestelmää tukemaan kuluttajalainapäätöksiä, on tärkeää tarkastella tuloksia ja ymmärtää, mitkä tiedot vaikuttavat järjestelmän suosituksiin. Hallitukset ovat alkaneet säännellä tekoälyä eri toimialoilla, joten datatieteilijöiden ja organisaatioiden on selitettävä, täyttääkö tekoälyjärjestelmä sääntelyvaatimukset, erityisesti silloin, kun tulos on ei-toivottu.
- Koska tekoälyjärjestelmät ovat niin monimutkaisia, niiden toiminnan ymmärtäminen ja tulosten tulkitseminen on vaikeaa.
- Tämä ymmärryksen puute vaikuttaa siihen, miten näitä järjestelmiä hallitaan, otetaan käyttöön ja dokumentoidaan.
- Tämä ymmärryksen puute vaikuttaa vielä enemmän päätöksiin, joita tehdään näiden järjestelmien tuottamien tulosten perusteella.
Vastuu
Tekoälyjärjestelmiä suunnittelevien ja käyttävien ihmisten on oltava vastuussa siitä, miten heidän järjestelmänsä toimivat. Vastuun tarve on erityisen tärkeä arkaluonteisten teknologioiden, kuten kasvojentunnistuksen, kohdalla. Viime aikoina kasvojentunnistusteknologian kysyntä on kasvanut, erityisesti lainvalvontaviranomaisten keskuudessa, jotka näkevät teknologian potentiaalin esimerkiksi kadonneiden lasten löytämisessä. Näitä teknologioita voitaisiin kuitenkin käyttää hallitusten toimesta vaarantamaan kansalaisten perusoikeuksia, esimerkiksi mahdollistamalla jatkuva tiettyjen henkilöiden valvonta. Siksi datatieteilijöiden ja organisaatioiden on oltava vastuussa siitä, miten heidän tekoälyjärjestelmänsä vaikuttavat yksilöihin tai yhteiskuntaan.
🎥 Klikkaa yllä olevaa kuvaa: Varoituksia kasvojentunnistuksen massavalvonnasta
Lopulta yksi sukupolvemme suurimmista kysymyksistä, ensimmäisenä sukupolvena, joka tuo tekoälyn yhteiskuntaan, on se, miten varmistamme, että tietokoneet pysyvät vastuussa ihmisille ja miten varmistamme, että tietokoneita suunnittelevat ihmiset pysyvät vastuussa kaikille muille.
Vaikutusten arviointi
Ennen koneoppimismallin kouluttamista on tärkeää suorittaa vaikutusten arviointi ymmärtääkseen tekoälyjärjestelmän tarkoitus, sen aiottu käyttö, missä se otetaan käyttöön ja ketkä ovat vuorovaikutuksessa järjestelmän kanssa. Nämä ovat hyödyllisiä arvioijille tai testaajille, jotta he tietävät, mitkä tekijät on otettava huomioon mahdollisia riskejä ja odotettuja seurauksia tunnistettaessa.
Seuraavat ovat keskeisiä alueita vaikutusten arvioinnissa:
- Haitalliset vaikutukset yksilöihin. On tärkeää olla tietoinen kaikista rajoituksista tai vaatimuksista, tukemattomasta käytöstä tai tunnetuista rajoituksista, jotka voivat haitata järjestelmän suorituskykyä, jotta varmistetaan, ettei järjestelmää käytetä tavalla, joka voisi aiheuttaa haittaa yksilöille.
- Datan vaatimukset. Ymmärtämällä, miten ja missä järjestelmä käyttää dataa, arvioijat voivat tutkia mahdollisia datavaatimuksia, jotka on otettava huomioon (esim. GDPR- tai HIPPA-säädökset). Lisäksi on tarkasteltava, onko datan lähde tai määrä riittävä koulutukseen.
- Vaikutusten yhteenveto. Kerää lista mahdollisista haitoista, joita järjestelmän käytöstä voi aiheutua. Koko koneoppimisen elinkaaren ajan tarkista, onko tunnistettuja ongelmia lievennetty tai ratkaistu.
- Sovellettavat tavoitteet kuudelle ydinperiaatteelle. Arvioi, täyttyvätkö kunkin periaatteen tavoitteet ja onko niissä puutteita.
Vastuullisen tekoälyn debuggaus
Kuten ohjelmistosovelluksen debuggaus, myös tekoälyjärjestelmän debuggaus on välttämätön prosessi järjestelmän ongelmien tunnistamiseksi ja ratkaisemiseksi. On monia tekijöitä, jotka voivat vaikuttaa siihen, että malli ei toimi odotetusti tai vastuullisesti. Useimmat perinteiset mallin suorituskykymittarit ovat määrällisiä yhteenvetoja mallin suorituskyvystä, eivätkä ne riitä analysoimaan, miten malli rikkoo vastuullisen tekoälyn periaatteita. Lisäksi koneoppimismalli on "musta laatikko", mikä vaikeuttaa sen tulosten ymmärtämistä tai selittämistä, kun se tekee virheen. Myöhemmin tässä kurssissa opimme käyttämään vastuullisen tekoälyn hallintapaneelia tekoälyjärjestelmien debuggaamiseen. Hallintapaneeli tarjoaa kokonaisvaltaisen työkalun datatieteilijöille ja tekoälykehittäjille seuraaviin tarkoituksiin:
-
Virheanalyysi. Mallin virhejakautuman tunnistaminen, joka voi vaikuttaa järjestelmän oikeudenmukaisuuteen tai luotett Katso tämä työpaja, joka syventyy aiheisiin:
-
Vastuullisen tekoälyn tavoittelu: Periaatteiden tuominen käytäntöön, esittäjät Besmira Nushi, Mehrnoosh Sameki ja Amit Sharma

🎥 Klikkaa yllä olevaa kuvaa nähdäksesi videon: RAI Toolbox: Avoimen lähdekoodin kehys vastuullisen tekoälyn rakentamiseen, esittäjät Besmira Nushi, Mehrnoosh Sameki ja Amit Sharma
Lue myös:
-
Microsoftin RAI-resurssikeskus: Responsible AI Resources – Microsoft AI
-
Microsoftin FATE-tutkimusryhmä: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Lue Azure Machine Learningin työkaluista, jotka varmistavat oikeudenmukaisuuden:
Tehtävä
Vastuuvapauslauseke:
Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator. Vaikka pyrimme tarkkuuteen, huomioithan, että automaattiset käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäistä asiakirjaa sen alkuperäisellä kielellä tulisi pitää ensisijaisena lähteenä. Kriittisen tiedon osalta suositellaan ammattimaista ihmiskäännöstä. Emme ole vastuussa väärinkäsityksistä tai virhetulkinnoista, jotka johtuvat tämän käännöksen käytöstä.