|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Postskriptum: Modell-Debugging im maschinellen Lernen mit Komponenten des Responsible AI Dashboards
Quiz vor der Vorlesung
Einführung
Maschinelles Lernen beeinflusst unser tägliches Leben. KI findet ihren Weg in einige der wichtigsten Systeme, die uns als Individuen und unsere Gesellschaft betreffen, wie Gesundheitswesen, Finanzen, Bildung und Beschäftigung. Beispielsweise sind Systeme und Modelle an alltäglichen Entscheidungsprozessen beteiligt, wie Diagnosen im Gesundheitswesen oder der Betrugserkennung. Folglich werden die Fortschritte in der KI und ihre beschleunigte Einführung von sich entwickelnden gesellschaftlichen Erwartungen und wachsender Regulierung begleitet. Immer wieder sehen wir Bereiche, in denen KI-Systeme Erwartungen nicht erfüllen, neue Herausforderungen aufzeigen und Regierungen beginnen, KI-Lösungen zu regulieren. Daher ist es wichtig, diese Modelle zu analysieren, um faire, zuverlässige, inklusive, transparente und verantwortungsvolle Ergebnisse für alle zu gewährleisten.
In diesem Lehrplan werden wir uns praktische Werkzeuge ansehen, die verwendet werden können, um zu beurteilen, ob ein Modell Probleme im Bereich der verantwortungsvollen KI aufweist. Traditionelle Debugging-Techniken im maschinellen Lernen basieren oft auf quantitativen Berechnungen wie aggregierter Genauigkeit oder durchschnittlichem Fehlerverlust. Stellen Sie sich vor, was passieren kann, wenn die Daten, die Sie zur Erstellung dieser Modelle verwenden, bestimmte demografische Gruppen wie Rasse, Geschlecht, politische Ansichten oder Religion nicht enthalten oder diese unverhältnismäßig stark repräsentieren. Was ist, wenn die Ausgabe des Modells so interpretiert wird, dass sie eine bestimmte demografische Gruppe bevorzugt? Dies kann zu einer Über- oder Unterrepräsentation dieser sensiblen Merkmale führen, was zu Problemen in Bezug auf Fairness, Inklusivität oder Zuverlässigkeit des Modells führt. Ein weiterer Faktor ist, dass maschinelle Lernmodelle oft als Blackboxen betrachtet werden, was es schwierig macht, die treibenden Faktoren hinter den Vorhersagen eines Modells zu verstehen und zu erklären. All dies sind Herausforderungen, denen sich Datenwissenschaftler und KI-Entwickler stellen müssen, wenn sie nicht über geeignete Werkzeuge verfügen, um die Fairness oder Vertrauenswürdigkeit eines Modells zu debuggen und zu bewerten.
In dieser Lektion lernen Sie, wie Sie Ihre Modelle debuggen können, indem Sie:
- Fehleranalyse: Identifizieren, in welchen Bereichen Ihrer Datenverteilung das Modell hohe Fehlerraten aufweist.
- Modellübersicht: Vergleichende Analysen über verschiedene Datenkohorten durchführen, um Diskrepanzen in den Leistungsmetriken Ihres Modells zu entdecken.
- Datenanalyse: Untersuchen, wo es eine Über- oder Unterrepräsentation Ihrer Daten geben könnte, die Ihr Modell dazu verleiten kann, eine Daten-Demografie gegenüber einer anderen zu bevorzugen.
- Feature-Wichtigkeit: Verstehen, welche Merkmale die Vorhersagen Ihres Modells auf globaler oder lokaler Ebene beeinflussen.
Voraussetzungen
Als Voraussetzung lesen Sie bitte die Übersicht Responsible AI tools for developers.

Fehleranalyse
Traditionelle Leistungsmetriken von Modellen zur Messung der Genauigkeit basieren meist auf Berechnungen von korrekten vs. falschen Vorhersagen. Zum Beispiel kann ein Modell, das zu 89 % genau ist und einen Fehlerverlust von 0,001 aufweist, als leistungsstark angesehen werden. Fehler sind jedoch oft nicht gleichmäßig in Ihrem zugrunde liegenden Datensatz verteilt. Sie könnten eine Modellgenauigkeit von 89 % erzielen, aber feststellen, dass es in bestimmten Bereichen Ihrer Daten Regionen gibt, in denen das Modell zu 42 % fehlerhaft ist. Die Konsequenzen dieser Fehlermuster bei bestimmten Datengruppen können zu Problemen in Bezug auf Fairness oder Zuverlässigkeit führen. Es ist entscheidend, die Bereiche zu verstehen, in denen das Modell gut oder schlecht abschneidet. Die Datenregionen, in denen Ihr Modell viele Ungenauigkeiten aufweist, könnten sich als wichtige demografische Daten herausstellen.

Die Fehleranalyse-Komponente des RAI Dashboards zeigt, wie Modellfehler über verschiedene Kohorten hinweg mit einer Baumvisualisierung verteilt sind. Dies ist nützlich, um Merkmale oder Bereiche zu identifizieren, in denen Ihre Daten eine hohe Fehlerrate aufweisen. Indem Sie sehen, woher die meisten Ungenauigkeiten des Modells stammen, können Sie beginnen, die Ursache zu untersuchen. Sie können auch Datenkohorten erstellen, um Analysen durchzuführen. Diese Datenkohorten helfen im Debugging-Prozess, um festzustellen, warum die Modellleistung in einer Kohorte gut, in einer anderen jedoch fehlerhaft ist.

Die visuellen Indikatoren in der Baumkarte helfen, Problemstellen schneller zu lokalisieren. Zum Beispiel zeigt ein dunklerer Rotton eines Baumknotens eine höhere Fehlerrate an.
Eine weitere Visualisierungsfunktion ist die Heatmap, mit der Benutzer die Fehlerrate anhand eines oder zweier Merkmale untersuchen können, um einen Beitrag zu den Modellfehlern im gesamten Datensatz oder in Kohorten zu finden.

Verwenden Sie die Fehleranalyse, wenn Sie:
- Ein tiefes Verständnis dafür gewinnen möchten, wie Modellfehler über einen Datensatz und mehrere Eingabe- und Merkmalsdimensionen verteilt sind.
- Die aggregierten Leistungsmetriken aufschlüsseln möchten, um fehlerhafte Kohorten automatisch zu entdecken und gezielte Maßnahmen zur Behebung zu ergreifen.
Modellübersicht
Die Bewertung der Leistung eines maschinellen Lernmodells erfordert ein ganzheitliches Verständnis seines Verhaltens. Dies kann erreicht werden, indem mehr als eine Metrik wie Fehlerrate, Genauigkeit, Recall, Präzision oder MAE (Mean Absolute Error) überprüft wird, um Diskrepanzen zwischen den Leistungsmetriken zu finden. Eine Leistungsmetrik mag großartig aussehen, aber Ungenauigkeiten können in einer anderen Metrik aufgedeckt werden. Darüber hinaus hilft der Vergleich der Metriken über den gesamten Datensatz oder Kohorten hinweg, Licht darauf zu werfen, wo das Modell gut oder schlecht abschneidet. Dies ist besonders wichtig, um die Leistung des Modells bei sensiblen vs. unsensiblen Merkmalen (z. B. ethnische Zugehörigkeit, Geschlecht oder Alter von Patienten) zu sehen, um potenzielle Unfairness des Modells aufzudecken. Zum Beispiel kann die Entdeckung, dass das Modell in einer Kohorte mit sensiblen Merkmalen fehlerhafter ist, potenzielle Unfairness aufzeigen.
Die Modellübersicht-Komponente des RAI Dashboards hilft nicht nur bei der Analyse der Leistungsmetriken der Datenrepräsentation in einer Kohorte, sondern gibt Benutzern auch die Möglichkeit, das Verhalten des Modells über verschiedene Kohorten hinweg zu vergleichen.

Die funktionsbasierte Analysefunktion der Komponente ermöglicht es Benutzern, Datensubgruppen innerhalb eines bestimmten Merkmals einzugrenzen, um Anomalien auf granularer Ebene zu identifizieren. Beispielsweise verfügt das Dashboard über eine eingebaute Intelligenz, um Kohorten für ein vom Benutzer ausgewähltes Merkmal automatisch zu generieren (z. B. "time_in_hospital < 3" oder "time_in_hospital >= 7"). Dies ermöglicht es einem Benutzer, ein bestimmtes Merkmal aus einer größeren Datengruppe zu isolieren, um zu sehen, ob es ein Schlüsselfaktor für die fehlerhaften Ergebnisse des Modells ist.

Die Modellübersicht-Komponente unterstützt zwei Klassen von Diskrepanzmetriken:
Diskrepanz in der Modellleistung: Diese Metriken berechnen die Diskrepanz (Differenz) in den Werten der ausgewählten Leistungsmetrik über Untergruppen von Daten. Hier einige Beispiele:
- Diskrepanz in der Genauigkeitsrate
- Diskrepanz in der Fehlerrate
- Diskrepanz in der Präzision
- Diskrepanz im Recall
- Diskrepanz im mittleren absoluten Fehler (MAE)
Diskrepanz in der Auswahlrate: Diese Metrik enthält die Differenz in der Auswahlrate (günstige Vorhersage) zwischen Untergruppen. Ein Beispiel hierfür ist die Diskrepanz in den Kreditgenehmigungsraten. Die Auswahlrate bezeichnet den Anteil der Datenpunkte in jeder Klasse, die als 1 klassifiziert werden (bei binärer Klassifikation) oder die Verteilung der Vorhersagewerte (bei Regression).
Datenanalyse
"Wenn man Daten lange genug foltert, gestehen sie alles" - Ronald Coase
Diese Aussage klingt extrem, aber es stimmt, dass Daten manipuliert werden können, um jede Schlussfolgerung zu unterstützen. Eine solche Manipulation kann manchmal unbeabsichtigt geschehen. Als Menschen haben wir alle Vorurteile, und es ist oft schwierig, bewusst zu erkennen, wann man Vorurteile in Daten einführt. Fairness in KI und maschinellem Lernen zu gewährleisten, bleibt eine komplexe Herausforderung.
Daten sind ein großer blinder Fleck für traditionelle Modellleistungsmetriken. Sie können hohe Genauigkeitswerte haben, aber das spiegelt nicht immer die zugrunde liegenden Datenverzerrungen wider, die in Ihrem Datensatz vorhanden sein könnten. Zum Beispiel, wenn ein Datensatz von Mitarbeitern 27 % Frauen in Führungspositionen und 73 % Männer auf derselben Ebene enthält, könnte ein auf diesen Daten trainiertes Stellenanzeigen-KI-Modell hauptsächlich ein männliches Publikum für Führungspositionen ansprechen. Dieses Ungleichgewicht in den Daten hat die Vorhersage des Modells verzerrt, sodass eine Geschlechterpräferenz entsteht. Dies zeigt ein Fairness-Problem, bei dem ein Geschlechterbias im KI-Modell vorliegt.
Die Datenanalyse-Komponente des RAI Dashboards hilft, Bereiche zu identifizieren, in denen es eine Über- oder Unterrepräsentation im Datensatz gibt. Sie hilft Benutzern, die Ursache von Fehlern und Fairness-Problemen zu diagnostizieren, die durch Datenungleichgewichte oder mangelnde Repräsentation einer bestimmten Datengruppe entstehen. Dies gibt Benutzern die Möglichkeit, Datensätze basierend auf vorhergesagten und tatsächlichen Ergebnissen, Fehlergruppen und spezifischen Merkmalen zu visualisieren. Manchmal kann die Entdeckung einer unterrepräsentierten Datengruppe auch aufzeigen, dass das Modell nicht gut lernt, was zu hohen Ungenauigkeiten führt. Ein Modell mit Datenbias ist nicht nur ein Fairness-Problem, sondern zeigt auch, dass das Modell nicht inklusiv oder zuverlässig ist.

Verwenden Sie die Datenanalyse, wenn Sie:
- Statistiken Ihres Datensatzes erkunden möchten, indem Sie verschiedene Filter auswählen, um Ihre Daten in verschiedene Dimensionen (auch Kohorten genannt) aufzuteilen.
- Die Verteilung Ihres Datensatzes über verschiedene Kohorten und Merkmalsgruppen hinweg verstehen möchten.
- Feststellen möchten, ob Ihre Erkenntnisse zu Fairness, Fehleranalyse und Kausalität (abgeleitet aus anderen Dashboard-Komponenten) auf der Verteilung Ihres Datensatzes basieren.
- Entscheiden möchten, in welchen Bereichen Sie mehr Daten sammeln sollten, um Fehler zu mindern, die durch Repräsentationsprobleme, Label-Rauschen, Merkmalsrauschen, Label-Bias und ähnliche Faktoren entstehen.
Modellinterpretierbarkeit
Maschinelle Lernmodelle werden oft als Blackboxen betrachtet. Es kann schwierig sein zu verstehen, welche Schlüsseldatenmerkmale die Vorhersagen eines Modells antreiben. Es ist wichtig, Transparenz darüber zu schaffen, warum ein Modell eine bestimmte Vorhersage trifft. Zum Beispiel, wenn ein KI-System vorhersagt, dass ein Diabetespatient ein Risiko hat, innerhalb von weniger als 30 Tagen wieder ins Krankenhaus eingeliefert zu werden, sollte es unterstützende Daten liefern können, die zu seiner Vorhersage geführt haben. Solche unterstützenden Datenindikatoren schaffen Transparenz, um Kliniken oder Krankenhäusern zu helfen, fundierte Entscheidungen zu treffen. Darüber hinaus ermöglicht die Fähigkeit, zu erklären, warum ein Modell eine Vorhersage für einen einzelnen Patienten getroffen hat, die Einhaltung von Gesundheitsvorschriften. Wenn Sie maschinelle Lernmodelle in Bereichen einsetzen, die das Leben von Menschen betreffen, ist es entscheidend, das Verhalten eines Modells zu verstehen und zu erklären. Modell-Erklärbarkeit und -Interpretierbarkeit hilft, Fragen in Szenarien wie diesen zu beantworten:
- Modell-Debugging: Warum hat mein Modell diesen Fehler gemacht? Wie kann ich mein Modell verbessern?
- Mensch-KI-Zusammenarbeit: Wie kann ich die Entscheidungen des Modells verstehen und ihm vertrauen?
- Gesetzliche Anforderungen: Erfüllt mein Modell die rechtlichen Vorgaben?
Die Feature-Wichtigkeit-Komponente des RAI Dashboards hilft Ihnen, Ihr Modell zu debuggen und ein umfassendes Verständnis dafür zu gewinnen, wie ein Modell Vorhersagen trifft. Sie ist auch ein nützliches Werkzeug für Fachleute im maschinellen Lernen und Entscheidungsträger, um zu erklären und nachzuweisen, welche Merkmale das Verhalten eines Modells beeinflussen, um gesetzliche Anforderungen zu erfüllen. Benutzer können sowohl globale als auch lokale Erklärungen untersuchen, um zu validieren, welche Merkmale die Vorhersagen eines Modells antreiben. Globale Erklärungen listen die wichtigsten Merkmale auf, die die Gesamtvorhersage eines Modells beeinflusst haben. Lokale Erklärungen zeigen, welche Merkmale zu einer Vorhersage des Modells für einen einzelnen Fall geführt haben. Die Möglichkeit, lokale Erklärungen zu bewerten, ist auch hilfreich beim Debugging oder bei der Prüfung eines bestimmten Falls, um besser zu verstehen und zu interpretieren, warum ein Modell eine korrekte oder fehlerhafte Vorhersage getroffen hat.
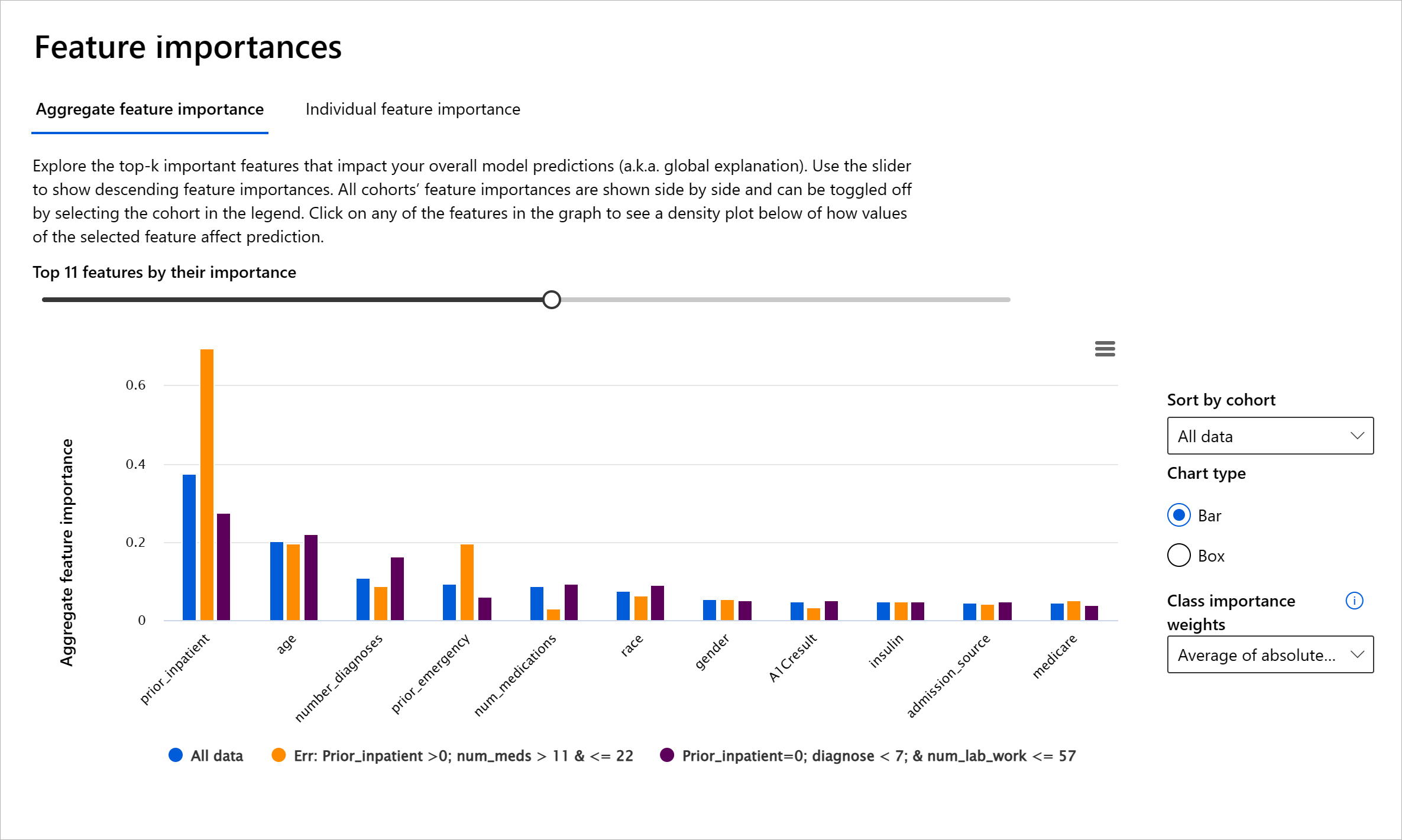
- Globale Erklärungen: Zum Beispiel, welche Merkmale beeinflussen das Gesamtverhalten eines Modells zur Vorhersage von Krankenhauswiedereinweisungen bei Diabetes?
- Lokale Erklärungen: Zum Beispiel, warum wurde ein Diabetespatient über 60 Jahre mit vorherigen Krankenhausaufenthalten vorhergesagt, innerhalb von 30 Tagen wieder oder nicht wieder ins Krankenhaus eingeliefert zu werden?
Im Debugging-Prozess, bei dem die Leistung eines Modells über verschiedene Kohorten untersucht wird, zeigt die Feature-Wichtigkeit, wie stark ein Merkmal die Kohorten beeinflusst. Sie hilft, Anomalien aufzudecken, wenn man den Einfluss eines Merkmals auf die fehlerhaften Vorhersagen eines Modells vergleicht. Die Feature-Wichtigkeit-Komponente kann zeigen, welche Werte in einem Merkmal die Ergebnisse des Modells positiv oder negativ beeinflusst haben. Wenn ein Modell beispielsweise eine fehlerhafte Vorhersage gemacht hat, gibt die Komponente Ihnen die Möglichkeit, ins Detail zu gehen und herauszufinden, welche Merkmale oder Merkmalswerte die Vorhersage beeinflusst haben. Dieses Detailniveau hilft nicht nur beim Debugging, sondern bietet auch Transparenz und Verantwortlichkeit in Prüfungssituationen. Schließlich kann die Komponente helfen, Fairness-Probleme zu identifizieren. Wenn beispielsweise ein sensibles Merkmal wie ethnische Zugehörigkeit oder Geschlecht einen hohen Einfluss auf die Vorhersage eines Modells hat, könnte dies ein Hinweis auf Rassen- oder Geschlechterbias im Modell sein.
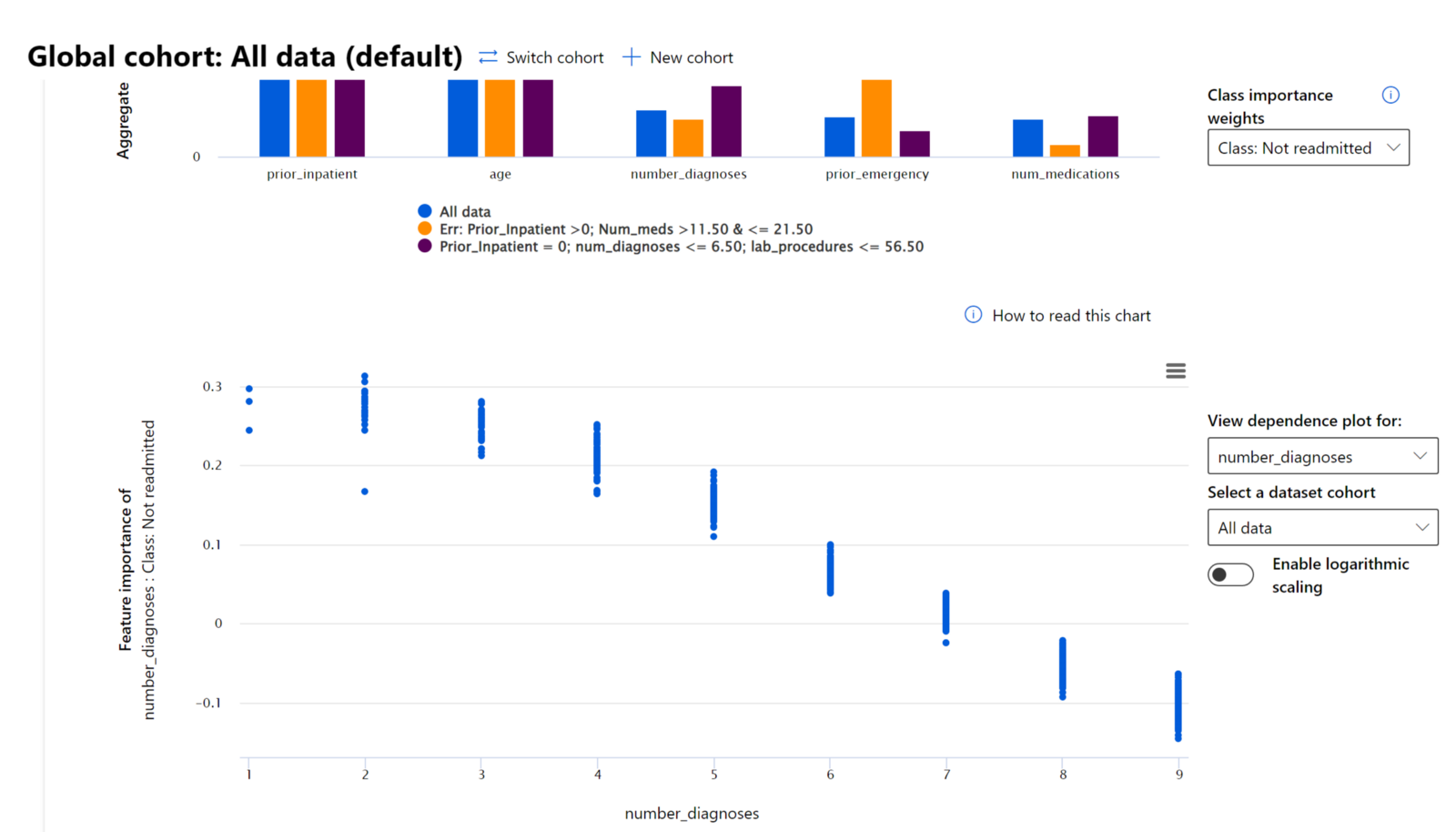
Verwenden Sie Interpretierbarkeit, wenn Sie:
- Bestimmen möchten, wie vertrauenswürdig die Vorhersagen Ihres KI-Systems sind, indem Sie verstehen, welche Merkmale für die Vorhersagen am wichtigsten sind.
- Den Debugging-Prozess Ihres Modells angehen möchten, indem Sie es zuerst verstehen und feststellen, ob das Modell gesunde Merkmale oder lediglich falsche Korrelationen verwendet.
- Potenzielle Quellen von Unfairness aufdecken möchten, indem Sie verstehen, ob das Modell Vorhersagen auf sensiblen Merkmalen oder auf Merkmalen, die stark mit ihnen korreliert sind, basiert.
- Das Vertrauen der Benutzer in die Entscheidungen Ihres Modells aufbauen möchten, indem Sie lokale Erklärungen generieren, um deren Ergebnisse zu veranschaulichen.
- Eine gesetzliche Prüfung eines KI-Systems abschließen möchten, um Modelle zu validieren und die Auswirkungen von Modellentscheidungen auf Menschen zu überwachen.
Fazit
Alle Komponenten des RAI Dashboards sind praktische Werkzeuge, die Ihnen helfen, maschinelle Lernmodelle zu entwickeln, die weniger schädlich und vertrauenswürdiger für die Gesellschaft sind. Sie tragen dazu bei, Bedrohungen der Menschenrechte zu verhindern, wie die Diskriminierung oder den Ausschluss bestimmter Gruppen von Lebenschancen, sowie das Risiko physischer oder psychischer Schäden. Sie helfen auch, Vertrauen in die Entscheidungen Ihres Modells aufzubauen, indem sie lokale Erklärungen generieren, um deren Ergebnisse zu veranschaulichen. Einige der potenziellen Schäden können wie folgt klassifiziert werden:
- Zuweisung: Wenn beispielsweise ein Geschlecht oder eine ethnische Zugehörigkeit gegenüber einer anderen bevorzugt wird.
- Qualität des Dienstes: Wenn Sie die Daten für ein spezifisches Szenario trainieren, die Realität jedoch viel komplexer ist, führt dies zu einem schlecht funktionierenden Dienst.
- Stereotypisierung: Die Zuordnung einer bestimmten Gruppe zu vorgegebenen Eigenschaften.
- Herabwürdigung: Eine unfaire Kritik oder Etikettierung von etwas oder jemandem.
- Über- oder Unterrepräsentation. Die Idee dahinter ist, dass eine bestimmte Gruppe in einem bestimmten Berufsfeld nicht vertreten ist, und jede Dienstleistung oder Funktion, die dies weiter fördert, trägt zu Schaden bei.
Azure RAI-Dashboard
Das Azure RAI-Dashboard basiert auf Open-Source-Tools, die von führenden akademischen Institutionen und Organisationen, einschließlich Microsoft, entwickelt wurden. Diese Tools sind für Datenwissenschaftler und KI-Entwickler von entscheidender Bedeutung, um das Verhalten von Modellen besser zu verstehen, unerwünschte Probleme in KI-Modellen zu erkennen und zu beheben.
-
Erfahren Sie, wie Sie die verschiedenen Komponenten nutzen können, indem Sie die Dokumentation zum RAI-Dashboard lesen.
-
Schauen Sie sich einige Beispiel-Notebooks des RAI-Dashboards an, um verantwortungsvollere KI-Szenarien in Azure Machine Learning zu debuggen.
🚀 Herausforderung
Um statistische oder datenbezogene Verzerrungen von Anfang an zu vermeiden, sollten wir:
- eine Vielfalt an Hintergründen und Perspektiven unter den Personen haben, die an den Systemen arbeiten
- in Datensätze investieren, die die Vielfalt unserer Gesellschaft widerspiegeln
- bessere Methoden entwickeln, um Verzerrungen zu erkennen und zu korrigieren, wenn sie auftreten
Denken Sie über reale Szenarien nach, in denen Unfairness beim Erstellen und Verwenden von Modellen offensichtlich ist. Was sollten wir noch berücksichtigen?
Quiz nach der Vorlesung
Rückblick & Selbststudium
In dieser Lektion haben Sie einige praktische Werkzeuge kennengelernt, um verantwortungsvolle KI in maschinelles Lernen zu integrieren.
Sehen Sie sich diesen Workshop an, um tiefer in die Themen einzutauchen:
- Responsible AI Dashboard: Eine zentrale Anlaufstelle für die Operationalisierung von RAI in der Praxis von Besmira Nushi und Mehrnoosh Sameki

🎥 Klicken Sie auf das Bild oben, um das Video anzusehen: Responsible AI Dashboard: Eine zentrale Anlaufstelle für die Operationalisierung von RAI in der Praxis von Besmira Nushi und Mehrnoosh Sameki
Nutzen Sie die folgenden Materialien, um mehr über verantwortungsvolle KI zu erfahren und vertrauenswürdigere Modelle zu entwickeln:
-
Microsofts RAI-Dashboard-Tools zur Fehlerbehebung bei ML-Modellen: Ressourcen für Responsible AI-Tools
-
Erkunden Sie das Responsible AI Toolkit: Github
-
Microsofts RAI-Ressourcenzentrum: Responsible AI Resources – Microsoft AI
-
Microsofts FATE-Forschungsgruppe: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Aufgabe
Erkunden Sie das RAI-Dashboard
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, beachten Sie bitte, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die sich aus der Nutzung dieser Übersetzung ergeben.