|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Aufbau von Machine-Learning-Lösungen mit verantwortungsbewusster KI
Sketchnote von Tomomi Imura
Quiz vor der Vorlesung
Einführung
In diesem Lehrplan werden Sie entdecken, wie Machine Learning unser tägliches Leben beeinflusst. Schon jetzt sind Systeme und Modelle in alltägliche Entscheidungsprozesse eingebunden, wie z. B. bei medizinischen Diagnosen, Kreditgenehmigungen oder der Betrugserkennung. Daher ist es wichtig, dass diese Modelle zuverlässig arbeiten und vertrauenswürdige Ergebnisse liefern. Genau wie jede andere Softwareanwendung können KI-Systeme Erwartungen nicht erfüllen oder unerwünschte Ergebnisse liefern. Deshalb ist es entscheidend, das Verhalten eines KI-Modells zu verstehen und erklären zu können.
Stellen Sie sich vor, was passieren kann, wenn die Daten, die Sie zur Erstellung dieser Modelle verwenden, bestimmte demografische Gruppen wie Ethnie, Geschlecht, politische Ansichten oder Religion nicht berücksichtigen oder unverhältnismäßig repräsentieren. Was passiert, wenn die Ergebnisse des Modells so interpretiert werden, dass sie eine bestimmte demografische Gruppe bevorzugen? Welche Konsequenzen hat das für die Anwendung? Und was passiert, wenn das Modell ein schädliches Ergebnis liefert? Wer ist für das Verhalten des KI-Systems verantwortlich? Diese Fragen werden wir in diesem Lehrplan untersuchen.
In dieser Lektion werden Sie:
- Ein Bewusstsein für die Bedeutung von Fairness im Machine Learning und fairnessbezogene Schäden entwickeln.
- Die Praxis des Erkundens von Ausreißern und ungewöhnlichen Szenarien kennenlernen, um Zuverlässigkeit und Sicherheit zu gewährleisten.
- Verstehen, warum es wichtig ist, inklusive Systeme zu entwerfen, die alle Menschen einbeziehen.
- Erforschen, wie entscheidend es ist, die Privatsphäre und Sicherheit von Daten und Menschen zu schützen.
- Die Bedeutung eines transparenten Ansatzes erkennen, um das Verhalten von KI-Modellen zu erklären.
- Verstehen, warum Verantwortlichkeit essenziell ist, um Vertrauen in KI-Systeme aufzubauen.
Voraussetzungen
Als Voraussetzung sollten Sie den "Responsible AI Principles"-Lernpfad absolvieren und das folgende Video zum Thema ansehen:
Erfahren Sie mehr über verantwortungsbewusste KI, indem Sie diesem Lernpfad folgen.

🎥 Klicken Sie auf das Bild oben für ein Video: Microsofts Ansatz für verantwortungsbewusste KI
Fairness
KI-Systeme sollten alle Menschen fair behandeln und vermeiden, ähnliche Gruppen unterschiedlich zu beeinflussen. Beispielsweise sollten KI-Systeme bei medizinischen Behandlungen, Kreditanträgen oder Beschäftigungsentscheidungen dieselben Empfehlungen für Menschen mit ähnlichen Symptomen, finanziellen Verhältnissen oder beruflichen Qualifikationen geben. Jeder von uns trägt unbewusste Vorurteile mit sich, die unsere Entscheidungen und Handlungen beeinflussen. Diese Vorurteile können sich in den Daten widerspiegeln, die wir zur Schulung von KI-Systemen verwenden. Solche Verzerrungen können manchmal unbeabsichtigt auftreten. Es ist oft schwierig, bewusst zu erkennen, wann man Vorurteile in Daten einführt.
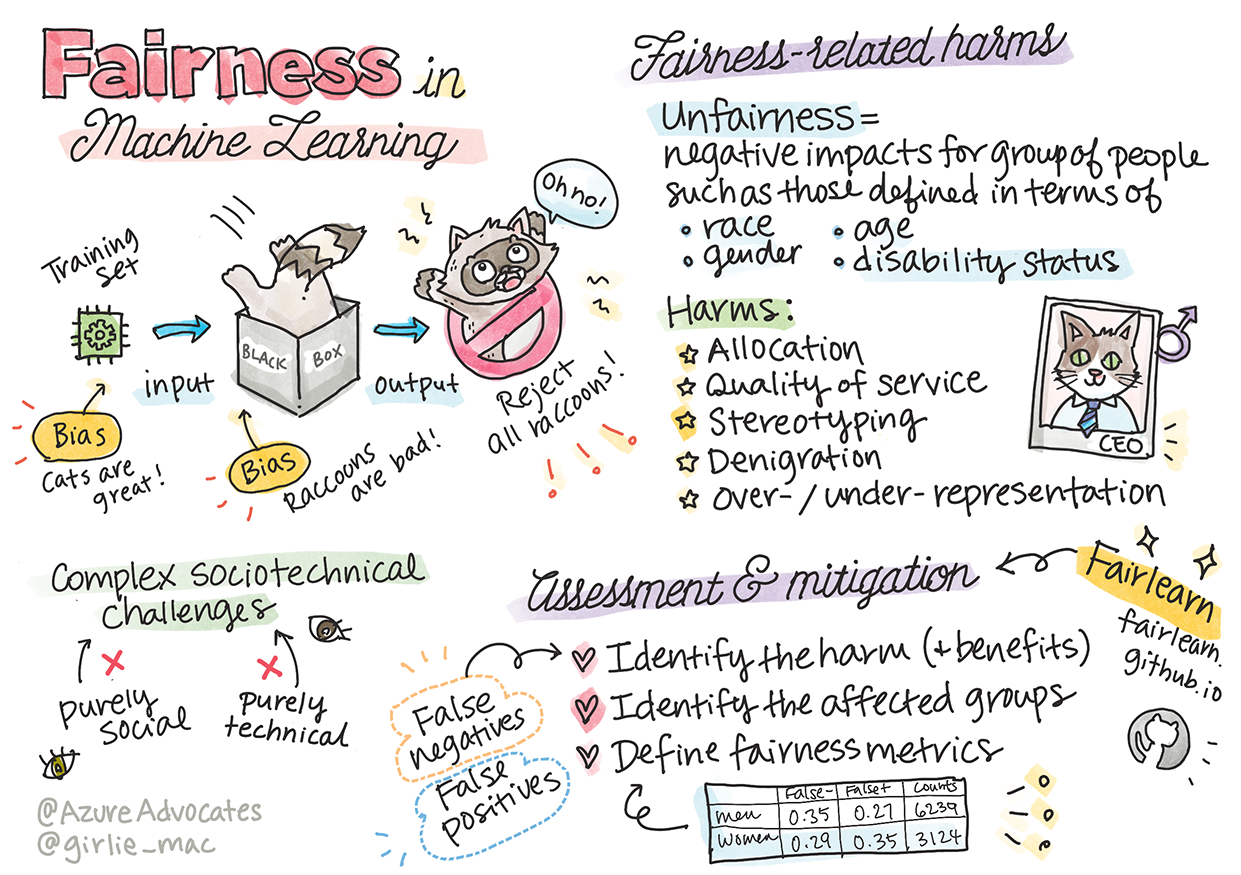
„Unfairness“ umfasst negative Auswirkungen oder „Schäden“ für eine Gruppe von Menschen, z. B. definiert durch Ethnie, Geschlecht, Alter oder Behinderungsstatus. Die Hauptarten von fairnessbezogenen Schäden lassen sich wie folgt klassifizieren:
- Zuweisung: Wenn z. B. ein Geschlecht oder eine Ethnie gegenüber einer anderen bevorzugt wird.
- Qualität des Dienstes: Wenn die Daten für ein spezifisches Szenario trainiert wurden, die Realität jedoch viel komplexer ist, führt dies zu einer schlechten Leistung des Dienstes. Ein Beispiel ist ein Seifenspender, der Menschen mit dunkler Hautfarbe nicht erkennen konnte. Referenz
- Herabwürdigung: Unfaire Kritik oder Etikettierung von etwas oder jemandem. Ein Beispiel ist eine Bildkennzeichnungstechnologie, die dunkelhäutige Menschen fälschlicherweise als Gorillas bezeichnete.
- Über- oder Unterrepräsentation: Die Idee, dass eine bestimmte Gruppe in einem bestimmten Beruf nicht sichtbar ist, und jede Funktion, die dies weiter fördert, trägt zu Schaden bei.
- Stereotypisierung: Die Zuordnung vorgefertigter Eigenschaften zu einer bestimmten Gruppe. Ein Beispiel ist ein Sprachübersetzungssystem zwischen Englisch und Türkisch, das aufgrund von stereotypischen Geschlechterassoziationen Ungenauigkeiten aufweist.
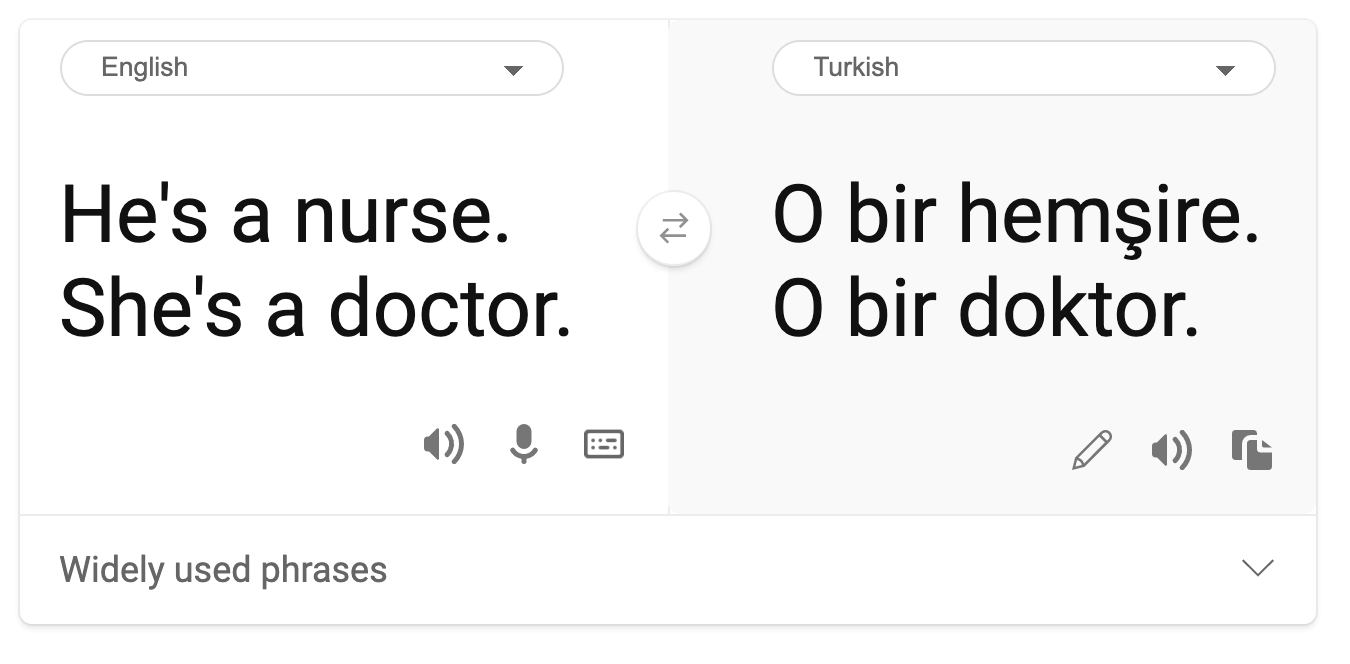
Übersetzung ins Türkische

Übersetzung zurück ins Englische
Beim Entwerfen und Testen von KI-Systemen müssen wir sicherstellen, dass KI fair ist und nicht so programmiert wird, dass sie voreingenommene oder diskriminierende Entscheidungen trifft, die auch Menschen nicht treffen dürfen. Fairness in KI und Machine Learning zu gewährleisten, bleibt eine komplexe soziotechnische Herausforderung.
Zuverlässigkeit und Sicherheit
Um Vertrauen aufzubauen, müssen KI-Systeme zuverlässig, sicher und konsistent unter normalen und unerwarteten Bedingungen sein. Es ist wichtig zu wissen, wie sich KI-Systeme in verschiedenen Situationen verhalten, insbesondere bei Ausreißern. Beim Aufbau von KI-Lösungen sollte ein erheblicher Fokus darauf gelegt werden, wie eine Vielzahl von Umständen gehandhabt werden kann, denen die KI-Lösungen begegnen könnten. Zum Beispiel muss ein selbstfahrendes Auto die Sicherheit der Menschen als oberste Priorität betrachten. Daher muss die KI, die das Auto antreibt, alle möglichen Szenarien berücksichtigen, denen das Auto begegnen könnte, wie z. B. Nacht, Gewitter, Schneestürme, Kinder, die über die Straße rennen, Haustiere, Straßenbauarbeiten usw. Wie gut ein KI-System eine Vielzahl von Bedingungen zuverlässig und sicher bewältigen kann, spiegelt das Maß an Voraussicht wider, das der Datenwissenschaftler oder KI-Entwickler während des Designs oder Tests des Systems berücksichtigt hat.
Inklusivität
KI-Systeme sollten so gestaltet sein, dass sie alle Menschen einbeziehen und befähigen. Beim Entwerfen und Implementieren von KI-Systemen identifizieren und adressieren Datenwissenschaftler und KI-Entwickler potenzielle Barrieren im System, die Menschen unbeabsichtigt ausschließen könnten. Zum Beispiel gibt es weltweit 1 Milliarde Menschen mit Behinderungen. Mit den Fortschritten in der KI können sie leichter auf eine Vielzahl von Informationen und Möglichkeiten in ihrem täglichen Leben zugreifen. Durch die Beseitigung von Barrieren entstehen Chancen, KI-Produkte mit besseren Erfahrungen zu entwickeln, die allen zugutekommen.
Sicherheit und Datenschutz
KI-Systeme sollten sicher sein und die Privatsphäre der Menschen respektieren. Menschen vertrauen Systemen weniger, die ihre Privatsphäre, Informationen oder ihr Leben gefährden. Beim Training von Machine-Learning-Modellen verlassen wir uns auf Daten, um die besten Ergebnisse zu erzielen. Dabei muss die Herkunft und Integrität der Daten berücksichtigt werden. Zum Beispiel: Wurden die Daten von Nutzern bereitgestellt oder waren sie öffentlich zugänglich? Während der Arbeit mit den Daten ist es entscheidend, KI-Systeme zu entwickeln, die vertrauliche Informationen schützen und Angriffen widerstehen können. Da KI immer weiter verbreitet wird, wird der Schutz der Privatsphäre und die Sicherung wichtiger persönlicher und geschäftlicher Informationen immer kritischer und komplexer. Datenschutz- und Datensicherheitsfragen erfordern besondere Aufmerksamkeit, da der Zugang zu Daten für KI-Systeme essenziell ist, um genaue und fundierte Vorhersagen und Entscheidungen über Menschen zu treffen.
- Als Branche haben wir bedeutende Fortschritte im Bereich Datenschutz und Sicherheit gemacht, die maßgeblich durch Vorschriften wie die DSGVO (Datenschutz-Grundverordnung) vorangetrieben wurden.
- Dennoch müssen wir bei KI-Systemen die Spannung zwischen dem Bedarf an mehr persönlichen Daten, um Systeme persönlicher und effektiver zu machen, und dem Datenschutz anerkennen.
- Genau wie bei der Einführung vernetzter Computer mit dem Internet sehen wir auch einen starken Anstieg der Sicherheitsprobleme im Zusammenhang mit KI.
- Gleichzeitig wird KI genutzt, um die Sicherheit zu verbessern. Zum Beispiel werden die meisten modernen Antiviren-Scanner heute von KI-Heuristiken angetrieben.
- Wir müssen sicherstellen, dass unsere Datenwissenschaftsprozesse harmonisch mit den neuesten Datenschutz- und Sicherheitspraktiken zusammenarbeiten.
Transparenz
KI-Systeme sollten verständlich sein. Ein wesentlicher Bestandteil der Transparenz ist die Erklärung des Verhaltens von KI-Systemen und ihrer Komponenten. Die Verbesserung des Verständnisses von KI-Systemen erfordert, dass Interessengruppen verstehen, wie und warum sie funktionieren, damit sie potenzielle Leistungsprobleme, Sicherheits- und Datenschutzbedenken, Vorurteile, ausschließende Praktiken oder unbeabsichtigte Ergebnisse identifizieren können. Wir glauben auch, dass diejenigen, die KI-Systeme nutzen, ehrlich und offen darüber sein sollten, wann, warum und wie sie diese einsetzen. Ebenso über die Grenzen der Systeme, die sie verwenden. Zum Beispiel: Wenn eine Bank ein KI-System zur Unterstützung ihrer Kreditentscheidungen einsetzt, ist es wichtig, die Ergebnisse zu überprüfen und zu verstehen, welche Daten die Empfehlungen des Systems beeinflussen. Regierungen beginnen, KI branchenübergreifend zu regulieren, daher müssen Datenwissenschaftler und Organisationen erklären, ob ein KI-System die regulatorischen Anforderungen erfüllt, insbesondere wenn es zu einem unerwünschten Ergebnis kommt.
- Da KI-Systeme so komplex sind, ist es schwierig zu verstehen, wie sie funktionieren und ihre Ergebnisse zu interpretieren.
- Dieses mangelnde Verständnis beeinflusst, wie diese Systeme verwaltet, operationalisiert und dokumentiert werden.
- Noch wichtiger ist, dass dieses mangelnde Verständnis die Entscheidungen beeinflusst, die auf Basis der Ergebnisse dieser Systeme getroffen werden.
Verantwortlichkeit
Die Menschen, die KI-Systeme entwerfen und einsetzen, müssen für deren Betrieb verantwortlich sein. Die Notwendigkeit der Verantwortlichkeit ist besonders wichtig bei sensiblen Technologien wie Gesichtserkennung. In letzter Zeit gibt es eine wachsende Nachfrage nach Gesichtserkennungstechnologie, insbesondere von Strafverfolgungsbehörden, die das Potenzial der Technologie beispielsweise bei der Suche nach vermissten Kindern sehen. Diese Technologien könnten jedoch von einer Regierung genutzt werden, um die Grundfreiheiten ihrer Bürger zu gefährden, indem sie beispielsweise eine kontinuierliche Überwachung bestimmter Personen ermöglichen. Daher müssen Datenwissenschaftler und Organisationen verantwortlich dafür sein, wie ihr KI-System Einzelpersonen oder die Gesellschaft beeinflusst.
🎥 Klicken Sie auf das Bild oben für ein Video: Warnungen vor Massenüberwachung durch Gesichtserkennung
Letztendlich ist eine der größten Fragen für unsere Generation, als die erste Generation, die KI in die Gesellschaft bringt, wie wir sicherstellen können, dass Computer den Menschen gegenüber rechenschaftspflichtig bleiben und dass die Menschen, die Computer entwerfen, allen anderen gegenüber rechenschaftspflichtig bleiben.
Auswirkungen bewerten
Bevor ein Machine-Learning-Modell trainiert wird, ist es wichtig, eine Auswirkungsbewertung durchzuführen, um den Zweck des KI-Systems zu verstehen: Was ist der beabsichtigte Nutzen? Wo wird es eingesetzt? Und wer wird mit dem System interagieren? Diese Bewertungen helfen Prüfern oder Testern, die das System bewerten, zu wissen, welche Faktoren bei der Identifizierung potenzieller Risiken und erwarteter Konsequenzen zu berücksichtigen sind.
Die folgenden Bereiche stehen bei einer Auswirkungsbewertung im Fokus:
- Negative Auswirkungen auf Einzelpersonen: Es ist wichtig, sich über Einschränkungen, Anforderungen, nicht unterstützte Verwendungen oder bekannte Begrenzungen bewusst zu sein, die die Leistung des Systems beeinträchtigen könnten, um sicherzustellen, dass das System nicht auf eine Weise verwendet wird, die Einzelpersonen schaden könnte.
- Datenanforderungen: Ein Verständnis dafür zu gewinnen, wie und wo das System Daten verwendet, ermöglicht es Prüfern, Datenanforderungen zu identifizieren, die berücksichtigt werden müssen (z. B. DSGVO- oder HIPAA-Datenvorschriften). Außerdem sollte geprüft werden, ob die Quelle oder Menge der Daten für das Training ausreicht.
- Zusammenfassung der Auswirkungen: Eine Liste potenzieller Schäden erstellen, die durch die Nutzung des Systems entstehen könnten. Während des gesamten ML-Lebenszyklus überprüfen, ob die identifizierten Probleme behoben oder adressiert wurden.
- Ziele für die sechs Kernprinzipien: Bewerten, ob die Ziele jedes Prinzips erreicht wurden und ob es Lücken gibt.
Debugging mit verantwortungsbewusster KI
Ähnlich wie beim Debugging einer Softwareanwendung ist das Debugging eines KI-Systems ein notwendiger Prozess, um Probleme im System zu identifizieren und zu lösen. Es gibt viele Faktoren, die dazu führen können, dass ein Modell nicht wie erwartet oder verantwortungsvoll funktioniert. Die meisten traditionellen Leistungsmetriken für Modelle sind quantitative Zusammenfassungen der Modellleistung, die nicht ausreichen, um zu analysieren, wie ein Modell gegen die Prinzipien der verantwortungsbewussten KI verstößt. Darüber hinaus ist ein Machine-Learning-Modell eine Blackbox, die es schwierig macht, die Gründe für seine Ergebnisse zu verstehen oder Erklärungen zu liefern, wenn es Fehler macht. Später in diesem Kurs lernen wir, wie man das Responsible AI Dashboard verwendet, um KI-Systeme zu debuggen. Das Dashboard bietet ein umfassendes Werkzeug für Datenwissenschaftler und KI-Entwickler, um:
- Fehleranalyse: Die Fehlerverteilung des Modells zu identifizieren, die die Fairness oder Zuverlässigkeit des Systems beeinträchtigen könnte.
- Modellübersicht: Zu entdecken, wo es Leistungsunterschiede des Modells über verschiedene Datenkohorten hinweg gibt.
- Datenanalyse: Die Datenverteilung zu verstehen und potenzielle Verzerrungen in den Daten zu identifizieren, die zu Fairness-, Inklusivitäts- und Zuverlässigkeitsproblemen führen könnten.
- Modellinterpretierbarkeit: Zu verstehen, was die Vorhersagen des Modells beeinflusst. Dies hilft, das Verhalten des Modells zu erklären, was für Transparenz und Verantwortlichkeit wichtig ist.
🚀 Herausforderung
Um Schäden von vornherein zu vermeiden, sollten wir:
- eine Vielfalt an Hintergründen und Perspektiven unter den Menschen haben, die an den Systemen arbeiten
- in Datensätze investieren, die die Vielfalt unserer Gesellschaft widerspiegeln
- bessere Methoden im gesamten Machine-Learning-Lebenszyklus entwickeln, um verantwortungsbewusste KI zu erkennen und zu korrigieren, wenn sie auftritt
Denken Sie an reale Szenarien, in denen die Unzuverlässigkeit eines Modells beim Erstellen und Verwenden offensichtlich wird. Was sollten wir noch berücksichtigen?
Quiz nach der Vorlesung
Rückblick & Selbststudium
In dieser Lektion haben Sie einige Grundlagen zu den Konzepten von Fairness und Unfairness im Machine Learning gelernt. Schauen Sie sich diesen Workshop an, um tiefer in die Themen einzutauchen:
- Auf der Suche nach verantwortungsvoller KI: Prinzipien in die Praxis umsetzen von Besmira Nushi, Mehrnoosh Sameki und Amit Sharma

🎥 Klicken Sie auf das Bild oben für ein Video: RAI Toolbox: Ein Open-Source-Framework für den Aufbau verantwortungsvoller KI von Besmira Nushi, Mehrnoosh Sameki und Amit Sharma
Lesen Sie außerdem:
-
Microsofts RAI-Ressourcenzentrum: Responsible AI Resources – Microsoft AI
-
Microsofts FATE-Forschungsgruppe: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Lesen Sie über die Tools von Azure Machine Learning, um Fairness sicherzustellen:
Aufgabe
Haftungsausschluss:
Dieses Dokument wurde mithilfe des KI-Übersetzungsdienstes Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, weisen wir darauf hin, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die sich aus der Nutzung dieser Übersetzung ergeben.