|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
بناء حلول التعلم الآلي باستخدام الذكاء الاصطناعي المسؤول
رسم تخطيطي بواسطة Tomomi Imura
اختبار ما قبل المحاضرة
المقدمة
في هذا المنهج، ستبدأ في اكتشاف كيف يؤثر التعلم الآلي على حياتنا اليومية. حتى الآن، تُستخدم الأنظمة والنماذج في اتخاذ قرارات يومية مثل تشخيصات الرعاية الصحية، الموافقة على القروض، أو اكتشاف الاحتيال. لذلك، من المهم أن تعمل هذه النماذج بشكل جيد لتقديم نتائج موثوقة. مثل أي تطبيق برمجي، قد تخفق أنظمة الذكاء الاصطناعي في تلبية التوقعات أو تؤدي إلى نتائج غير مرغوبة. لهذا السبب، من الضروري فهم وتفسير سلوك نموذج الذكاء الاصطناعي.
تخيل ما يمكن أن يحدث عندما تفتقر البيانات التي تستخدمها لبناء هذه النماذج إلى تمثيل ديموغرافي معين مثل العرق، الجنس، الرؤية السياسية، الدين، أو تمثيل غير متوازن لهذه الفئات. ماذا عن عندما يتم تفسير نتائج النموذج لتفضيل فئة معينة؟ ما هي العواقب على التطبيق؟ بالإضافة إلى ذلك، ماذا يحدث عندما يؤدي النموذج إلى نتائج ضارة تؤثر سلبًا على الناس؟ من المسؤول عن سلوك أنظمة الذكاء الاصطناعي؟ هذه بعض الأسئلة التي سنستكشفها في هذا المنهج.
في هذه الدرس، ستتعلم:
- أهمية الإنصاف في التعلم الآلي والأضرار المرتبطة به.
- التعرف على ممارسة استكشاف الحالات الشاذة والسيناريوهات غير المعتادة لضمان الموثوقية والسلامة.
- فهم الحاجة إلى تمكين الجميع من خلال تصميم أنظمة شاملة.
- استكشاف أهمية حماية الخصوصية وأمن البيانات والأفراد.
- إدراك أهمية النهج الشفاف لتفسير سلوك نماذج الذكاء الاصطناعي.
- التفكير في كيفية أن تكون المساءلة ضرورية لبناء الثقة في أنظمة الذكاء الاصطناعي.
المتطلبات الأساسية
كشرط مسبق، يرجى أخذ مسار التعلم "مبادئ الذكاء الاصطناعي المسؤول" ومشاهدة الفيديو أدناه حول الموضوع:
تعرف على المزيد حول الذكاء الاصطناعي المسؤول من خلال متابعة هذا مسار التعلم

🎥 انقر على الصورة أعلاه لمشاهدة الفيديو: نهج مايكروسوفت تجاه الذكاء الاصطناعي المسؤول
الإنصاف
يجب أن تعامل أنظمة الذكاء الاصطناعي الجميع بإنصاف وتتجنب التأثير على مجموعات متشابهة من الناس بطرق مختلفة. على سبيل المثال، عندما تقدم أنظمة الذكاء الاصطناعي إرشادات حول العلاج الطبي، طلبات القروض، أو التوظيف، يجب أن تقدم نفس التوصيات للجميع بناءً على أعراض مشابهة، ظروف مالية، أو مؤهلات مهنية. كل واحد منا كبشر يحمل تحيزات موروثة تؤثر على قراراتنا وأفعالنا. يمكن أن تكون هذه التحيزات واضحة في البيانات التي نستخدمها لتدريب أنظمة الذكاء الاصطناعي. قد يحدث هذا التلاعب أحيانًا دون قصد. غالبًا ما يكون من الصعب إدراك متى يتم إدخال التحيز في البيانات.
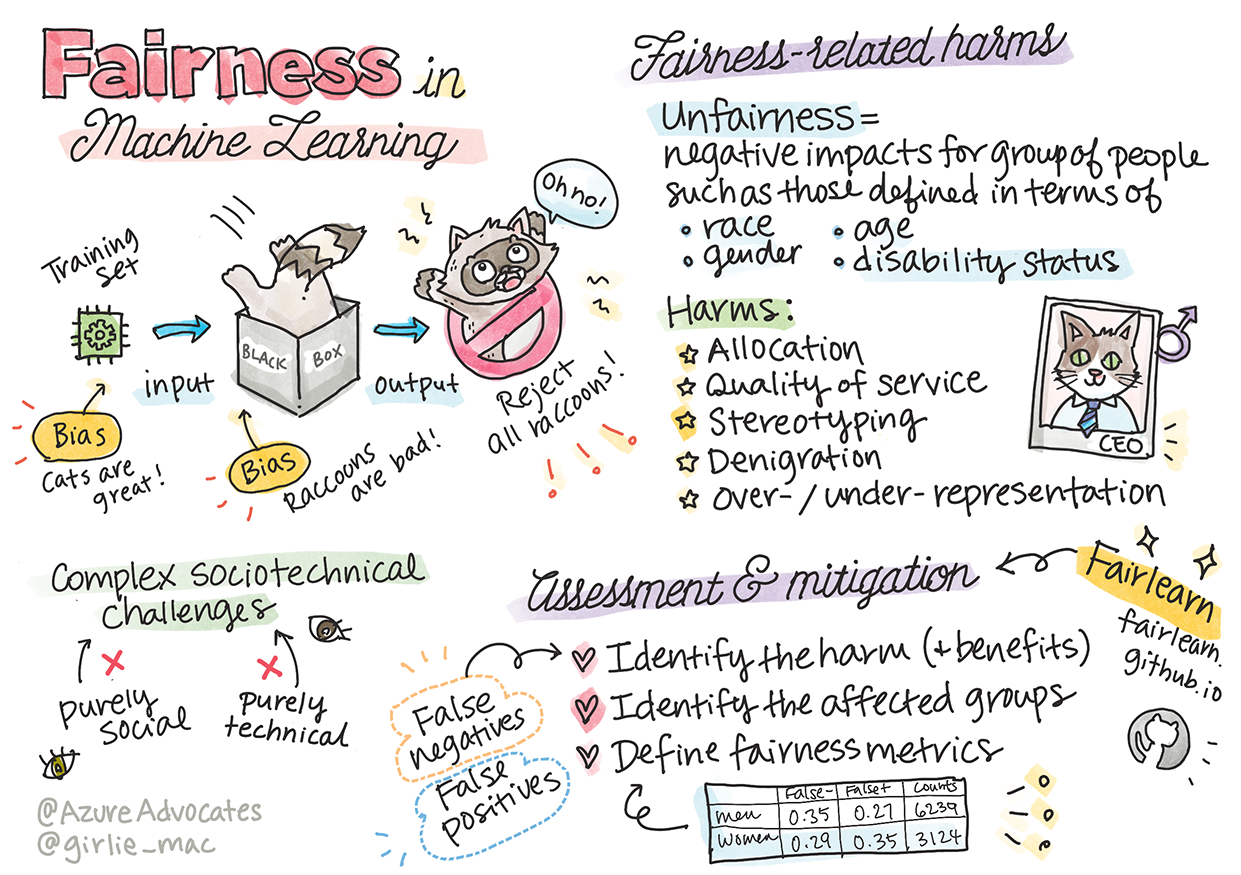
"عدم الإنصاف" يشمل التأثيرات السلبية أو "الأضرار" لمجموعة من الناس، مثل تلك المحددة بناءً على العرق، الجنس، العمر، أو حالة الإعاقة. يمكن تصنيف الأضرار الرئيسية المتعلقة بالإنصاف على النحو التالي:
- التخصيص، إذا تم تفضيل جنس أو عرق معين على آخر.
- جودة الخدمة. إذا تم تدريب البيانات على سيناريو محدد ولكن الواقع أكثر تعقيدًا، يؤدي ذلك إلى خدمة ضعيفة الأداء. على سبيل المثال، موزع صابون يدوي لم يتمكن من التعرف على الأشخاص ذوي البشرة الداكنة. مرجع
- التشهير. انتقاد أو تصنيف شيء أو شخص بشكل غير عادل. على سبيل المثال، تقنية تصنيف الصور التي وصفت بشكل خاطئ صور الأشخاص ذوي البشرة الداكنة كغوريلات.
- التمثيل الزائد أو الناقص. الفكرة هي أن مجموعة معينة لا تُرى في مهنة معينة، وأي خدمة أو وظيفة تستمر في تعزيز ذلك تساهم في الضرر.
- التنميط. ربط مجموعة معينة بصفات محددة مسبقًا. على سبيل المثال، قد يكون هناك أخطاء في نظام ترجمة اللغة بين الإنجليزية والتركية بسبب الكلمات المرتبطة بالتحيزات الجندرية.
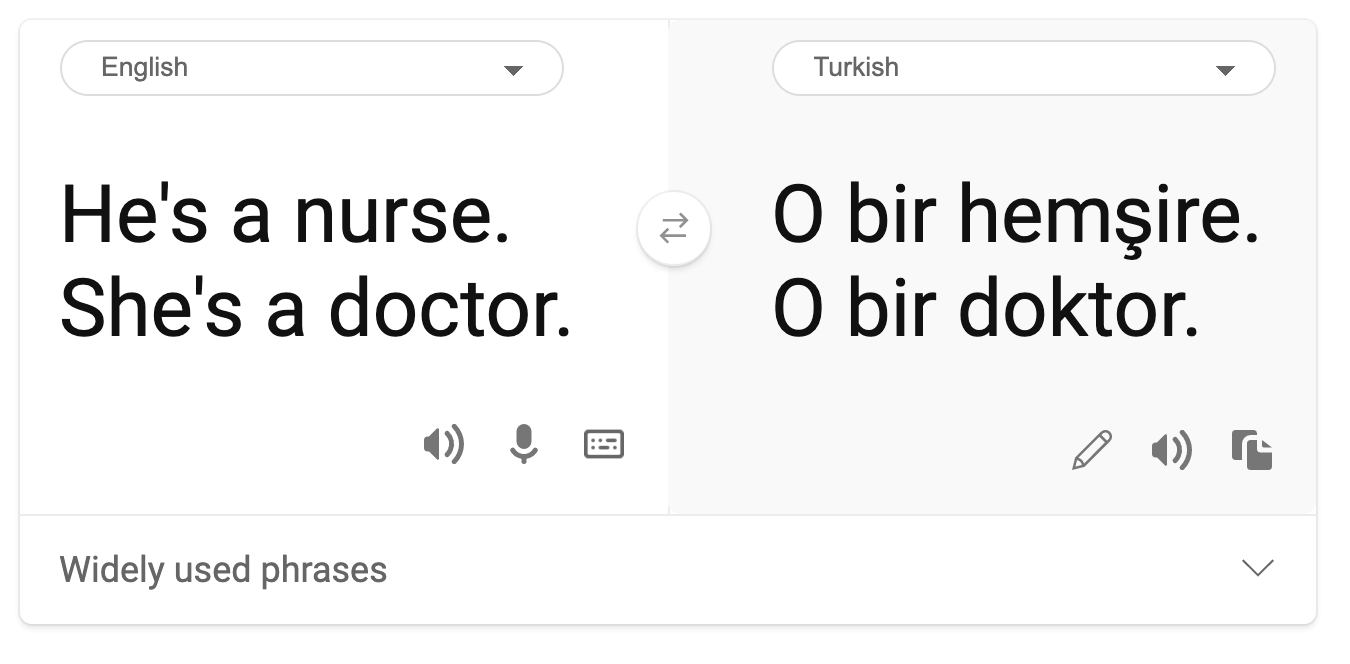
الترجمة إلى التركية

الترجمة إلى الإنجليزية
عند تصميم واختبار أنظمة الذكاء الاصطناعي، يجب أن نضمن أن الذكاء الاصطناعي عادل وغير مبرمج لاتخاذ قرارات متحيزة أو تمييزية، وهي قرارات يُحظر على البشر اتخاذها أيضًا. ضمان الإنصاف في الذكاء الاصطناعي والتعلم الآلي يظل تحديًا اجتماعيًا تقنيًا معقدًا.
الموثوقية والسلامة
لبناء الثقة، يجب أن تكون أنظمة الذكاء الاصطناعي موثوقة وآمنة ومتسقة في الظروف العادية وغير المتوقعة. من المهم معرفة كيف ستتصرف أنظمة الذكاء الاصطناعي في مجموعة متنوعة من المواقف، خاصة عندما تكون هناك حالات شاذة. عند بناء حلول الذكاء الاصطناعي، يجب التركيز بشكل كبير على كيفية التعامل مع مجموعة واسعة من الظروف التي قد تواجهها هذه الحلول. على سبيل المثال، يجب أن تكون السيارة ذاتية القيادة تضع سلامة الناس كأولوية قصوى. نتيجة لذلك، يجب أن يأخذ الذكاء الاصطناعي الذي يشغل السيارة في الاعتبار جميع السيناريوهات الممكنة التي قد تواجهها السيارة مثل الليل، العواصف الرعدية أو الثلوج، الأطفال الذين يركضون عبر الشارع، الحيوانات الأليفة، أعمال الطرق، إلخ. مدى قدرة نظام الذكاء الاصطناعي على التعامل مع مجموعة واسعة من الظروف بشكل موثوق وآمن يعكس مستوى التوقعات التي أخذها عالم البيانات أو مطور الذكاء الاصطناعي في الاعتبار أثناء تصميم أو اختبار النظام.
الشمولية
يجب تصميم أنظمة الذكاء الاصطناعي لتشرك وتمكن الجميع. عند تصميم وتنفيذ أنظمة الذكاء الاصطناعي، يقوم علماء البيانات ومطورو الذكاء الاصطناعي بتحديد ومعالجة الحواجز المحتملة في النظام التي قد تستبعد الناس دون قصد. على سبيل المثال، هناك مليار شخص يعانون من إعاقات حول العالم. مع تقدم الذكاء الاصطناعي، يمكنهم الوصول إلى مجموعة واسعة من المعلومات والفرص بسهولة أكبر في حياتهم اليومية. من خلال معالجة الحواجز، يتم خلق فرص للابتكار وتطوير منتجات الذكاء الاصطناعي بتجارب أفضل تفيد الجميع.
الأمن والخصوصية
يجب أن تكون أنظمة الذكاء الاصطناعي آمنة وتحترم خصوصية الناس. يقل ثقة الناس في الأنظمة التي تعرض خصوصيتهم أو معلوماتهم أو حياتهم للخطر. عند تدريب نماذج التعلم الآلي، نعتمد على البيانات للحصول على أفضل النتائج. أثناء ذلك، يجب مراعاة مصدر البيانات وسلامتها. على سبيل المثال، هل البيانات مقدمة من المستخدم أو متاحة للجمهور؟ بعد ذلك، أثناء العمل مع البيانات، من الضروري تطوير أنظمة الذكاء الاصطناعي التي يمكنها حماية المعلومات السرية ومقاومة الهجمات. مع انتشار الذكاء الاصطناعي، أصبحت حماية الخصوصية وتأمين المعلومات الشخصية والتجارية الهامة أكثر أهمية وتعقيدًا. تتطلب قضايا الخصوصية وأمن البيانات اهتمامًا خاصًا للذكاء الاصطناعي لأن الوصول إلى البيانات ضروري لأنظمة الذكاء الاصطناعي لتقديم توقعات وقرارات دقيقة ومستنيرة حول الناس.
- كصناعة، حققنا تقدمًا كبيرًا في الخصوصية والأمن، مدفوعًا بشكل كبير بتنظيمات مثل اللائحة العامة لحماية البيانات (GDPR).
- ومع ذلك، مع أنظمة الذكاء الاصطناعي، يجب أن نعترف بالتوتر بين الحاجة إلى المزيد من البيانات الشخصية لجعل الأنظمة أكثر شخصية وفعالية - والخصوصية.
- تمامًا كما حدث مع ولادة أجهزة الكمبيوتر المتصلة بالإنترنت، نشهد أيضًا زيادة كبيرة في عدد مشكلات الأمن المتعلقة بالذكاء الاصطناعي.
- في الوقت نفسه، رأينا استخدام الذكاء الاصطناعي لتحسين الأمن. على سبيل المثال، معظم ماسحات الفيروسات الحديثة تعتمد اليوم على استدلالات الذكاء الاصطناعي.
- يجب أن نضمن أن عمليات علم البيانات لدينا تتناغم بشكل متناغم مع أحدث ممارسات الخصوصية والأمن.
الشفافية
يجب أن تكون أنظمة الذكاء الاصطناعي مفهومة. جزء أساسي من الشفافية هو تفسير سلوك أنظمة الذكاء الاصطناعي ومكوناتها. تحسين فهم أنظمة الذكاء الاصطناعي يتطلب أن يفهم أصحاب المصلحة كيف ولماذا تعمل هذه الأنظمة بحيث يمكنهم تحديد مشكلات الأداء المحتملة، مخاوف السلامة والخصوصية، التحيزات، الممارسات الإقصائية، أو النتائج غير المقصودة. نعتقد أيضًا أن أولئك الذين يستخدمون أنظمة الذكاء الاصطناعي يجب أن يكونوا صادقين وصريحين بشأن متى ولماذا وكيف يختارون نشرها، بالإضافة إلى قيود الأنظمة التي يستخدمونها. على سبيل المثال، إذا استخدم بنك نظام ذكاء اصطناعي لدعم قرارات الإقراض للمستهلكين، فمن المهم فحص النتائج وفهم البيانات التي تؤثر على توصيات النظام. بدأت الحكومات في تنظيم الذكاء الاصطناعي عبر الصناعات، لذا يجب على علماء البيانات والمنظمات تفسير ما إذا كان نظام الذكاء الاصطناعي يفي بالمتطلبات التنظيمية، خاصة عندما تكون هناك نتيجة غير مرغوبة.
- نظرًا لأن أنظمة الذكاء الاصطناعي معقدة للغاية، من الصعب فهم كيفية عملها وتفسير النتائج.
- يؤثر هذا النقص في الفهم على طريقة إدارة هذه الأنظمة، تشغيلها، وتوثيقها.
- يؤثر هذا النقص في الفهم بشكل أكثر أهمية على القرارات التي تُتخذ باستخدام النتائج التي تنتجها هذه الأنظمة.
المساءلة
يجب أن يكون الأشخاص الذين يصممون وينشرون أنظمة الذكاء الاصطناعي مسؤولين عن كيفية عمل أنظمتهم. الحاجة إلى المساءلة مهمة بشكل خاص مع التقنيات الحساسة مثل التعرف على الوجه. مؤخرًا، كان هناك طلب متزايد على تقنية التعرف على الوجه، خاصة من المنظمات القانونية التي ترى إمكانات التكنولوجيا في استخدامات مثل العثور على الأطفال المفقودين. ومع ذلك، يمكن أن تُستخدم هذه التقنيات من قبل الحكومات لتعريض الحريات الأساسية لمواطنيها للخطر، على سبيل المثال، من خلال تمكين المراقبة المستمرة لأفراد معينين. لذلك، يجب أن يكون علماء البيانات والمنظمات مسؤولين عن كيفية تأثير نظام الذكاء الاصطناعي على الأفراد أو المجتمع.
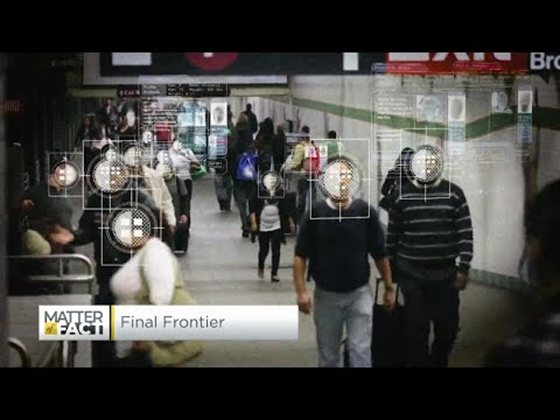
🎥 انقر على الصورة أعلاه لمشاهدة الفيديو: تحذيرات من المراقبة الجماعية عبر التعرف على الوجه
في النهاية، أحد أكبر الأسئلة لجيلنا، كأول جيل يجلب الذكاء الاصطناعي إلى المجتمع، هو كيفية ضمان أن تظل أجهزة الكمبيوتر مسؤولة أمام الناس وكيفية ضمان أن يظل الأشخاص الذين يصممون أجهزة الكمبيوتر مسؤولين أمام الجميع.
تقييم التأثير
قبل تدريب نموذج التعلم الآلي، من المهم إجراء تقييم تأثير لفهم الغرض من نظام الذكاء الاصطناعي؛ ما هو الاستخدام المقصود؛ أين سيتم نشره؛ ومن سيتفاعل مع النظام. هذه التقييمات مفيدة للمراجعين أو المختبرين لتقييم النظام ومعرفة العوامل التي يجب أخذها في الاعتبار عند تحديد المخاطر المحتملة والعواقب المتوقعة.
تشمل المجالات التي يجب التركيز عليها عند إجراء تقييم التأثير:
- التأثير السلبي على الأفراد. إدراك أي قيود أو متطلبات، استخدام غير مدعوم أو أي قيود معروفة تعيق أداء النظام أمر ضروري لضمان عدم استخدام النظام بطريقة قد تسبب ضررًا للأفراد.
- متطلبات البيانات. فهم كيفية وأين سيستخدم النظام البيانات يمكّن المراجعين من استكشاف أي متطلبات بيانات يجب أن تكون على دراية بها (مثل لوائح GDPR أو HIPPA). بالإضافة إلى ذلك، فحص ما إذا كان مصدر أو كمية البيانات كافٍ للتدريب.
- ملخص التأثير. جمع قائمة بالأضرار المحتملة التي قد تنشأ عن استخدام النظام. خلال دورة حياة التعلم الآلي، مراجعة ما إذا كانت المشكلات المحددة قد تم تخفيفها أو معالجتها.
- الأهداف القابلة للتطبيق لكل من المبادئ الستة الأساسية. تقييم ما إذا كانت الأهداف من كل مبدأ قد تم تحقيقها وما إذا كانت هناك أي فجوات.
تصحيح الأخطاء باستخدام الذكاء الاصطناعي المسؤول
مثل تصحيح الأخطاء في تطبيق برمجي، فإن تصحيح الأخطاء في نظام الذكاء الاصطناعي هو عملية ضرورية لتحديد وحل المشكلات في النظام. هناك العديد من العوامل التي قد تؤثر على أداء النموذج بشكل غير متوقع أو غير مسؤول. معظم مقاييس أداء النموذج التقليدية هي تجميعات كمية لأداء النموذج، والتي لا تكفي لتحليل كيفية انتهاك النموذج لمبادئ الذكاء الاصطناعي المسؤول. علاوة على ذلك، يعد نموذج التعلم الآلي صندوقًا أسودًا يجعل من الصعب فهم ما يدفع نتائجه أو تقديم تفسير عندما يرتكب خطأ. لاحقًا في هذه الدورة، سنتعلم كيفية استخدام لوحة معلومات الذكاء الاصطناعي المسؤول للمساعدة في تصحيح أخطاء أنظمة الذكاء الاصطناعي. توفر لوحة المعلومات أداة شاملة لعلماء البيانات ومطوري الذكاء الاصطناعي للقيام بما يلي:
- تحليل الأخطاء. لتحديد توزيع الأخطاء في النموذج الذي يمكن أن يؤثر على إنصاف النظام أو موثوقيته.
- نظرة عامة على النموذج. لاكتشاف أين توجد تفاوتات في أداء النموذج عبر مجموعات البيانات.
- تحليل البيانات. لفهم توزيع البيانات وتحديد أي تحيز محتمل في البيانات قد يؤدي إلى مشكلات في الإنصاف، الشمولية، والموثوقية.
- تفسير النموذج. لفهم ما يؤثر أو يؤثر على توقعات النموذج. يساعد ذلك في تفسير سلوك النموذج، وهو أمر مهم للشفافية والمساءلة.
🚀 التحدي
لمنع الأضرار من أن تُدخل في المقام الأول، يجب علينا:
- ضمان تنوع الخلفيات ووجهات النظر بين الأشخاص الذين يعملون على الأنظمة.
- الاستثمار في مجموعات بيانات تعكس تنوع مجتمعنا.
- تطوير طرق أفضل خلال دورة حياة التعلم الآلي للكشف عن الذكاء الاصطناعي المسؤول وتصحيحه عند حدوثه.
فكر في سيناريوهات واقعية حيث يكون عدم موثوقية النموذج واضحًا في بناء النموذج واستخدامه. ما الذي يجب أن نأخذه في الاعتبار أيضًا؟
اختبار ما بعد المحاضرة
المراجعة والدراسة الذاتية
في هذا الدرس، تعلمت بعض أساسيات مفاهيم الإنصاف وعدم الإنصاف في التعلم الآلي. شاهد هذه الورشة للتعمق أكثر في المواضيع:
- السعي نحو الذكاء الاصطناعي المسؤول: تحويل المبادئ إلى ممارسة بواسطة بسميرة نوشي، مهرنوش ساميكي وأميت شارما

🎥 اضغط على الصورة أعلاه لمشاهدة الفيديو: RAI Toolbox: إطار عمل مفتوح المصدر لبناء ذكاء اصطناعي مسؤول بواسطة بسميرة نوشي، مهرنوش ساميكي، وأميت شارما
اقرأ أيضًا:
-
مركز موارد الذكاء الاصطناعي المسؤول من مايكروسوفت: موارد الذكاء الاصطناعي المسؤول – مايكروسوفت AI
-
مجموعة أبحاث FATE من مايكروسوفت: FATE: العدالة، المساءلة، الشفافية، والأخلاقيات في الذكاء الاصطناعي - أبحاث مايكروسوفت
RAI Toolbox:
اقرأ عن أدوات Azure Machine Learning لضمان العدالة:
المهمة
إخلاء المسؤولية:
تمت ترجمة هذه الوثيقة باستخدام خدمة الترجمة الآلية Co-op Translator. بينما نسعى لتحقيق الدقة، يرجى العلم أن الترجمات الآلية قد تحتوي على أخطاء أو معلومات غير دقيقة. يجب اعتبار الوثيقة الأصلية بلغتها الأصلية المصدر الموثوق. للحصول على معلومات حساسة أو هامة، يُوصى بالاستعانة بترجمة بشرية احترافية. نحن غير مسؤولين عن أي سوء فهم أو تفسيرات خاطئة ناتجة عن استخدام هذه الترجمة.