|
|
1 month ago | |
|---|---|---|
| .. | ||
| README.md | 1 month ago | |
| assignment.md | 1 month ago | |
README.md
Postscript: မော်ဒယ် Debugging ကို Responsible AI Dashboard Components အသုံးပြု၍ Machine Learning တွင် ပြုလုပ်ခြင်း
Pre-lecture quiz
အကျဉ်းချုပ်
Machine learning သည် ကျွန်ုပ်တို့၏ နေ့စဉ်ဘဝများကို အကျိုးသက်ရောက်စေပါသည်။ AI သည် ကျွန်ုပ်တို့၏ လူ့အဖွဲ့အစည်းနှင့် တစ်ဦးချင်းစီအပေါ် သက်ရောက်မှုရှိသော အရေးကြီးသော စနစ်များတွင် ဝင်ရောက်လာပြီး ကျန်းမာရေး၊ ဘဏ္ဍာရေး၊ ပညာရေးနှင့် အလုပ်အကိုင်ကဏ္ဍများတွင် အသုံးပြုလာသည်။ ဥပမာအားဖြင့် ကျန်းမာရေးရောဂါရှာဖွေခြင်း သို့မဟုတ် လိမ်လည်မှုကို ရှာဖွေခြင်းကဲ့သို့သော နေ့စဉ်ဆုံးဖြတ်မှုလုပ်ငန်းစဉ်များတွင် စနစ်များနှင့် မော်ဒယ်များ ပါဝင်နေသည်။ ထို့ကြောင့် AI ၏ တိုးတက်မှုများနှင့် အလျင်အမြန် အသုံးပြုမှုများသည် လူ့အဖွဲ့အစည်း၏ မျှော်လင့်ချက်များနှင့် အတူတိုးတက်လာပြီး အစိုးရများက AI ဖြေရှင်းချက်များကို စတင်ထိန်းချုပ်လာသည်။ ထို့ကြောင့် မော်ဒယ်များကို လူတိုင်းအတွက် တရားမျှတမှု၊ ယုံကြည်စိတ်ချရမှု၊ ပါဝင်မှု၊ ထင်ရှားမှုနှင့် တာဝန်ယူမှုရှိသော ရလဒ်များပေးနိုင်ရန် အကဲဖြတ်ရန် အရေးကြီးပါသည်။
ဒီသင်ခန်းစာတွင် မော်ဒယ်တွင် Responsible AI ပြဿနာများရှိမရှိကို အကဲဖြတ်ရန် အသုံးပြုနိုင်သော လက်တွေ့ကိရိယာများကို လေ့လာပါမည်။ ရှေးရိုးစဉ်လာ Machine Learning Debugging နည်းလမ်းများသည် စုစုပေါင်းတိကျမှု သို့မဟုတ် အလျော့အတိကျမှုများကို အခြေခံ၍ တွက်ချက်မှုများဖြစ်သည်။ သင်၏ မော်ဒယ်များကို တည်ဆောက်ရန် အသုံးပြုသော ဒေတာတွင် လူမျိုး၊ လိင်၊ နိုင်ငံရေးအမြင်၊ ဘာသာရေးကဲ့သို့သော အမျိုးအစားများ မပါဝင်ခြင်း သို့မဟုတ် အလွန်များလွန်းသော အမျိုးအစားများ ပါဝင်ခြင်းဖြစ်ပါက ဘာဖြစ်နိုင်မလဲ စဉ်းစားကြည့်ပါ။ မော်ဒယ်၏ ရလဒ်သည် အချို့သော အမျိုးအစားများကို အားပေးသောအနေဖြင့် အဓိပ္ပာယ်ဖွင့်ဆိုခြင်းဖြစ်ပါကလည်း မျှတမှု၊ ပါဝင်မှု သို့မဟုတ် ယုံကြည်စိတ်ချရမှု ပြဿနာများ ဖြစ်ပေါ်စေနိုင်ပါသည်။ ထို့အပြင် Machine Learning မော်ဒယ်များသည် "Black Boxes" အဖြစ် ရှိနေသောကြောင့် မော်ဒယ်၏ ခန့်မှန်းချက်များကို ဘာက အားပေးနေသည်ကို နားလည်ရန် ခက်ခဲစေပါသည်။ ဒီအရာများသည် မော်ဒယ်၏ တရားမျှတမှု သို့မဟုတ် ယုံကြည်စိတ်ချရမှုကို Debugging ပြုလုပ်ရန် လုံလောက်သော ကိရိယာများ မရှိသောအခါ Data Scientist များနှင့် AI Developer များ ရင်ဆိုင်ရသော စိန်ခေါ်မှုများဖြစ်သည်။
ဒီသင်ခန်းစာတွင် သင်သည် မော်ဒယ်များကို Debugging ပြုလုပ်ရန် အောက်ပါအရာများကို လေ့လာပါမည်-
- Error Analysis: မော်ဒယ်၏ အမှားနှုန်းများ မြင့်မားသော ဒေတာဖြန့်ဝေမှုနေရာများကို ရှာဖွေပါ။
- Model Overview: မော်ဒယ်၏ စွမ်းဆောင်ရည် metrics များတွင် ကွာဟမှုများကို ရှာဖွေရန် ဒေတာ cohorts များအကြား နှိုင်းယှဉ်အကဲဖြတ်မှု ပြုလုပ်ပါ။
- Data Analysis: သင့်မော်ဒယ်သည် အချို့သော ဒေတာအမျိုးအစားများကို အားပေးရန် skew ဖြစ်စေသော ဒေတာ၏ over-representation သို့မဟုတ် under-representation ရှိနေသောနေရာများကို စုံစမ်းပါ။
- Feature Importance: မော်ဒယ်၏ ခန့်မှန်းချက်များကို Global Level သို့မဟုတ် Local Level တွင် အားပေးနေသော features များကို နားလည်ပါ။
ကြိုတင်လိုအပ်ချက်
ကြိုတင်လိုအပ်ချက်အနေဖြင့် Responsible AI tools for developers ကို ပြန်လည်သုံးသပ်ပါ။

Error Analysis
ရိုးရာ မော်ဒယ်စွမ်းဆောင်ရည် metrics များသည် တိကျမှုကို တိုင်းတာရန် အမှန်/အမှား ခန့်မှန်းချက်များအပေါ် အခြေခံ၍ တွက်ချက်မှုများဖြစ်သည်။ ဥပမာအားဖြင့် မော်ဒယ်သည် 89% တိကျမှုနှုန်းနှင့် 0.001 အမှားဆုံးရှုံးမှုရှိသည်ဟု သတ်မှတ်ခြင်းသည် စွမ်းဆောင်ရည်ကောင်းမွန်သည်ဟု ယူဆနိုင်သည်။ သို့သော် အမှားများသည် သင့်ဒေတာအတွင်း တူညီစွာ မဖြန့်ဝေထားနိုင်ပါ။ သင် 89% တိကျမှုနှုန်းရရှိနိုင်သော်လည်း မော်ဒယ်သည် သင့်ဒေတာ၏ အချို့သောနေရာများတွင် 42% အမှားနှုန်းရှိနေသည်ကို ရှာဖွေနိုင်ပါသည်။ ဒေတာအုပ်စုအချို့တွင် အမှားများရှိနေသော ဒီအခြေအနေများသည် မျှတမှု သို့မဟုတ် ယုံကြည်စိတ်ချရမှု ပြဿနာများကို ဖြစ်ပေါ်စေနိုင်ပါသည်။ မော်ဒယ်သည် ဘယ်နေရာတွင် ကောင်းမွန်စွာ လုပ်ဆောင်နေသည် သို့မဟုတ် မလုပ်ဆောင်နိုင်သည်ကို နားလည်ရန် အရေးကြီးပါသည်။
Error Analysis component သည် RAI dashboard တွင် မော်ဒယ်၏ အမှားဖြန့်ဝေမှုကို tree visualization ဖြင့် ဖော်ပြသည်။ ဒါသည် သင့်ဒေတာတွင် အမှားနှုန်းများ မြင့်မားသော features သို့မဟုတ် နေရာများကို ရှာဖွေရာတွင် အထောက်အကူပြုသည်။
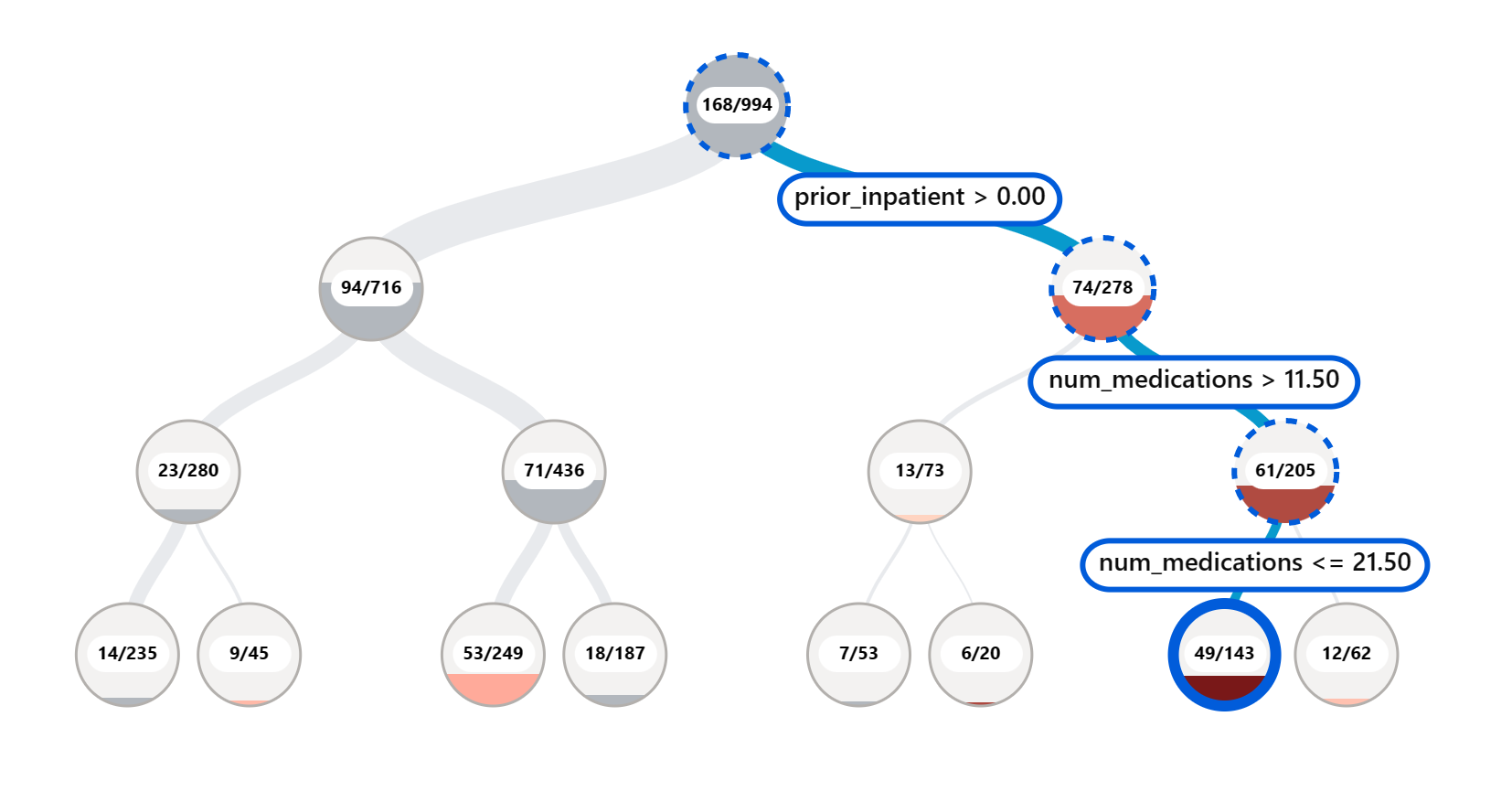
Tree map တွင် အနီရောင်မှောင်သော node များသည် အမှားနှုန်းများ မြင့်မားနေသည်ကို မြန်ဆန်စွာ ရှာဖွေရန် visual indicators အဖြစ် အသုံးပြုနိုင်သည်။
Heat map သည် feature တစ်ခု သို့မဟုတ် feature နှစ်ခုကို အသုံးပြု၍ မော်ဒယ်၏ အမှားများကို စုံစမ်းရန် အသုံးပြုနိုင်သော visualization တစ်ခုဖြစ်သည်။
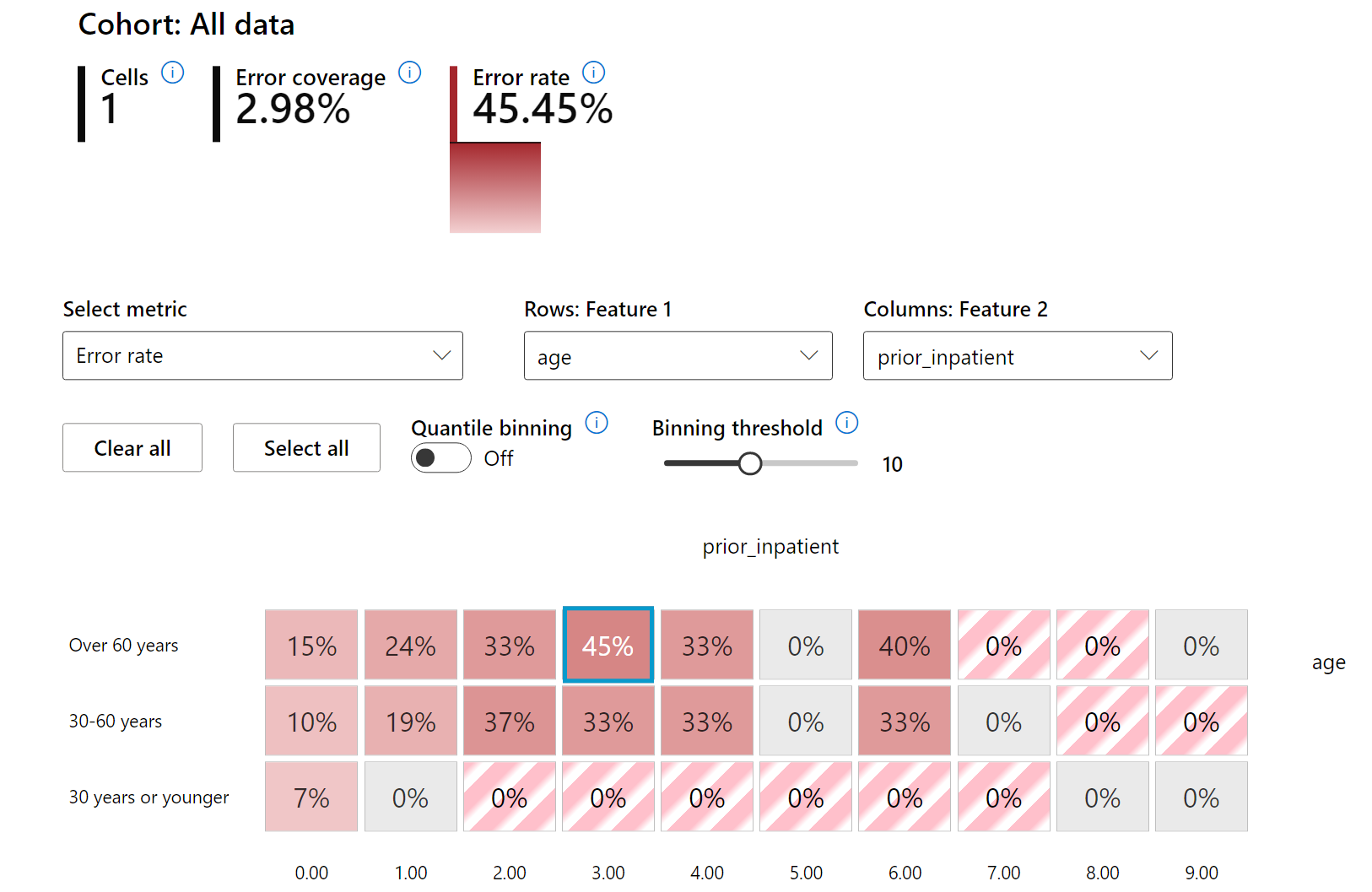
Error Analysis ကို သင်လိုအပ်သောအခါ အသုံးပြုပါ-
- မော်ဒယ်၏ အမှားများသည် ဒေတာအတွင်း ဘယ်လိုဖြန့်ဝေထားသည်ကို နက်ရှိုင်းစွာ နားလည်ရန်။
- စုစုပေါင်း စွမ်းဆောင်ရည် metrics များကို ခွဲခြမ်းစိတ်ဖြာပြီး အမှားများရှိသော cohorts များကို ရှာဖွေ၍ ပြဿနာများကို Targeted mitigation ဖြင့် ဖြေရှင်းရန်။
Model Overview
Machine learning မော်ဒယ်၏ စွမ်းဆောင်ရည်ကို အကဲဖြတ်ရန် မော်ဒယ်၏ အပြုသဘောဆောင်သောနှင့် အနုတ်သဘောဆောင်သော metrics များကို Comprehensive Analysis ပြုလုပ်ရန် လိုအပ်သည်။ Metrics တစ်ခုကောင်းမွန်နေသော်လည်း အခြား metrics တွင် အမှားများကို ရှာဖွေနိုင်ပါသည်။ ထို့အပြင် Sensitive features (ဥပမာ- လူမျိုး၊ လိင်၊ အသက်) နှင့် insensitive features အကြား performance disparities များကို ရှာဖွေခြင်းသည် မော်ဒယ်၏ fairness ပြဿနာများကို ရှာဖွေရာတွင် အရေးကြီးပါသည်။
Model Overview component သည် RAI dashboard တွင် မော်ဒယ်၏ စွမ်းဆောင်ရည် metrics များကို cohort များအကြား နှိုင်းယှဉ်အကဲဖြတ်ရန် အထောက်အကူပြုသည်။
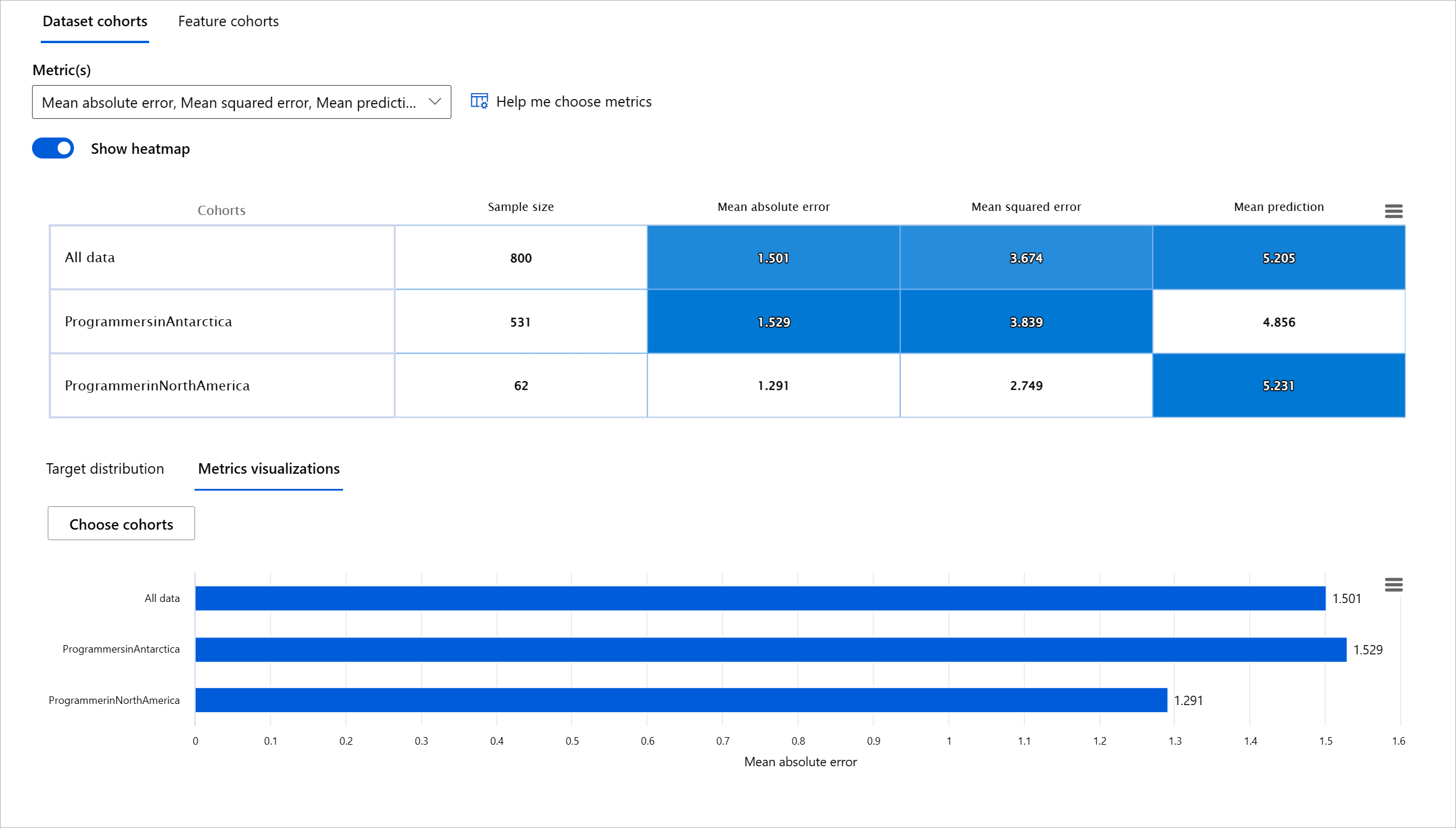
Feature-based analysis functionality သည် feature တစ်ခုကို Narrow Down ပြုလုပ်၍ granular level တွင် anomalies များကို ရှာဖွေရန် အထောက်အကူပြုသည်။
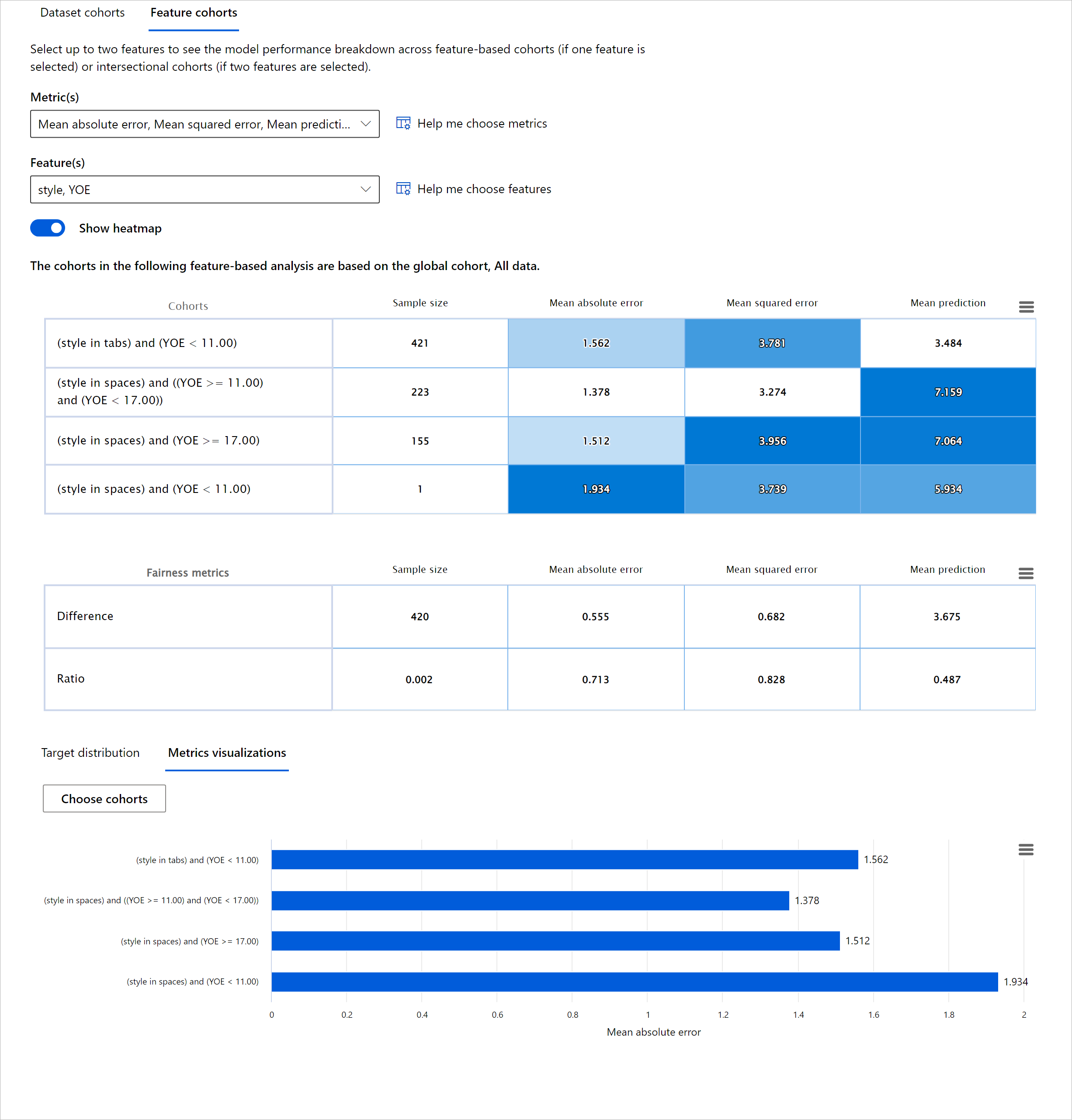
Model Overview component သည် disparity metrics နှစ်မျိုးကို ပံ့ပိုးသည်-
Disparity in model performance: Performance metrics များ၏ subgroups အကြား disparity ကို တွက်ချက်သည်။ ဥပမာ-
- Accuracy rate disparity
- Error rate disparity
- Precision disparity
- Recall disparity
- Mean absolute error (MAE) disparity
Disparity in selection rate: Subgroups အကြား selection rate disparity ကို တွက်ချက်သည်။ ဥပမာ- ချေးငွေ အတည်ပြုနှုန်း disparity။
Data Analysis
"If you torture the data long enough, it will confess to anything" - Ronald Coase
ဒီစကားသည် အလွန်ကြမ်းတမ်းသော်လည်း ဒေတာကို မည်သည့်အကျိုးဆောင်ချက်ကိုမဆို ထောက်ခံရန် Manipulate ပြုလုပ်နိုင်သည်ဟု အမှန်ပါသည်။ ဒေတာကို Manipulate ပြုလုပ်ခြင်းသည် တစ်ခါတစ်ရံ မတော်တဆဖြစ်နိုင်ပါသည်။ လူသားများအနေဖြင့် bias ရှိပြီး ဒေတာတွင် bias ထည့်သွင်းနေသည်ကို သိရှိရန် ခက်ခဲပါသည်။ AI နှင့် Machine Learning တွင် fairness ကို အာမခံရန် အလွန်ခက်ခဲသော စိန်ခေါ်မှုတစ်ခုဖြစ်သည်။
Data Analysis component သည် RAI dashboard တွင် ဒေတာ၏ over-representation နှင့် under-representation ရှိနေသောနေရာများကို ရှာဖွေရာတွင် အထောက်အကူပြုသည်။ ဒေတာ၏ imbalance များကြောင့် fairness ပြဿနာများကို ရှာဖွေခြင်းနှင့် root cause ကို စုံစမ်းရန် အထောက်အကူပြုသည်။
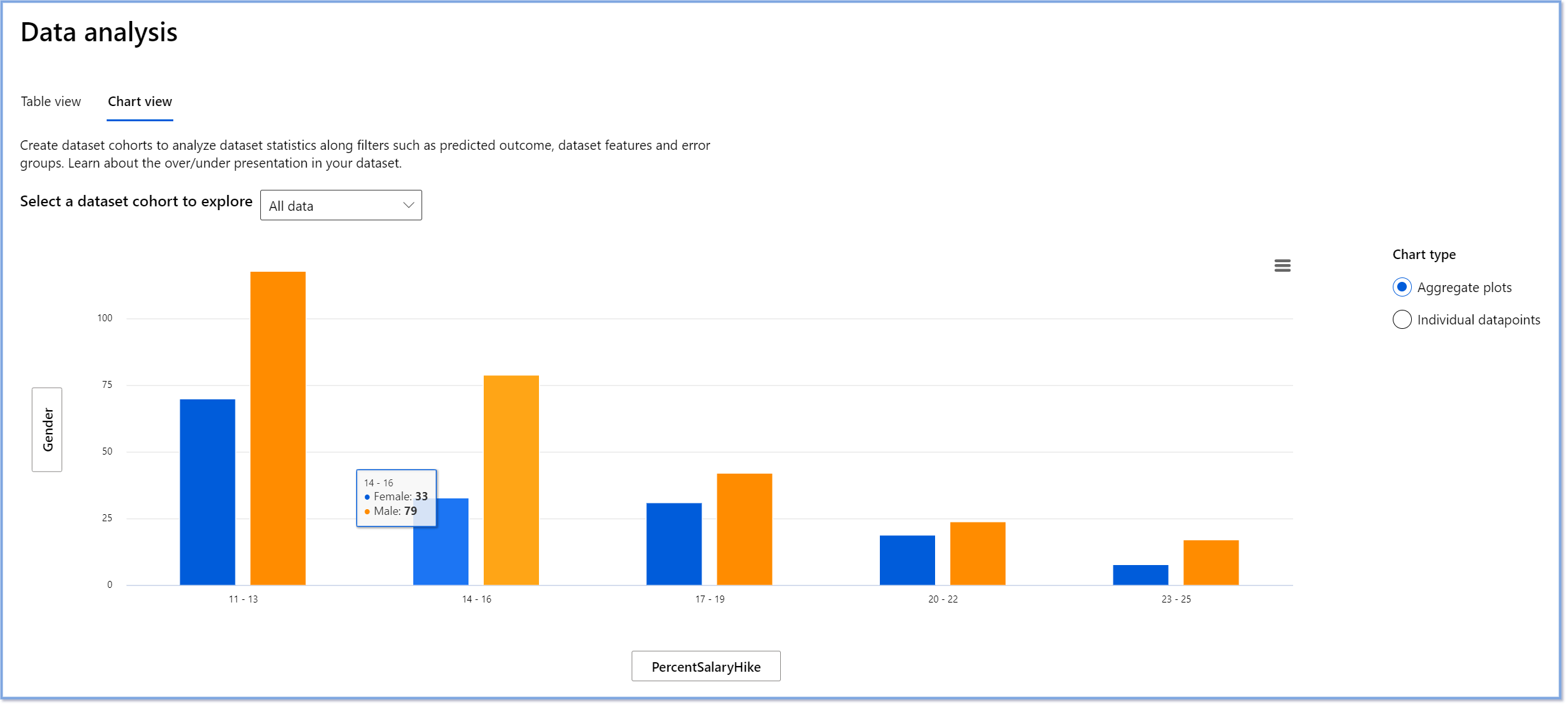
Data Analysis ကို သင်လိုအပ်သောအခါ အသုံးပြုပါ-
- သင့်ဒေတာ၏ statistics များကို filters များရွေးချယ်၍ dimensions များအဖြစ် slice ပြုလုပ်ရန်။
- Dataset distribution ကို cohorts နှင့် feature groups များအတွင်း နားလည်ရန်။
- Fairness, error analysis နှင့် causality ရလဒ်များသည် ဒေတာ၏ distribution ကြောင့်ဖြစ်သည်ကို သတ်မှတ်ရန်။
- Representation issues, label noise, feature noise, label bias စသည်တို့ကြောင့် error များကို လျှော့ချရန် ဒေတာကို စုဆောင်းရန်။
Model Interpretability
Machine learning မော်ဒယ်များသည် "Black Boxes" ဖြစ်သောကြောင့် ခန့်မှန်းချက်များကို ဘာ features အားပေးနေသည်ကို နားလည်ရန် ခက်ခဲပါသည်။ မော်ဒယ်၏ ခန့်မှန်းချက်များကို ဘာကြောင့်ဖြစ်သည်ကို ရှင်းလင်းရန် transparency ပေးရန် အရေးကြီးပါသည်။ Feature Importance component သည် RAI dashboard တွင် မော်ဒယ်၏ ခန့်မှန်းချက်များကို Debugging ပြုလုပ်ရန် အထောက်အကူပြုသည်။
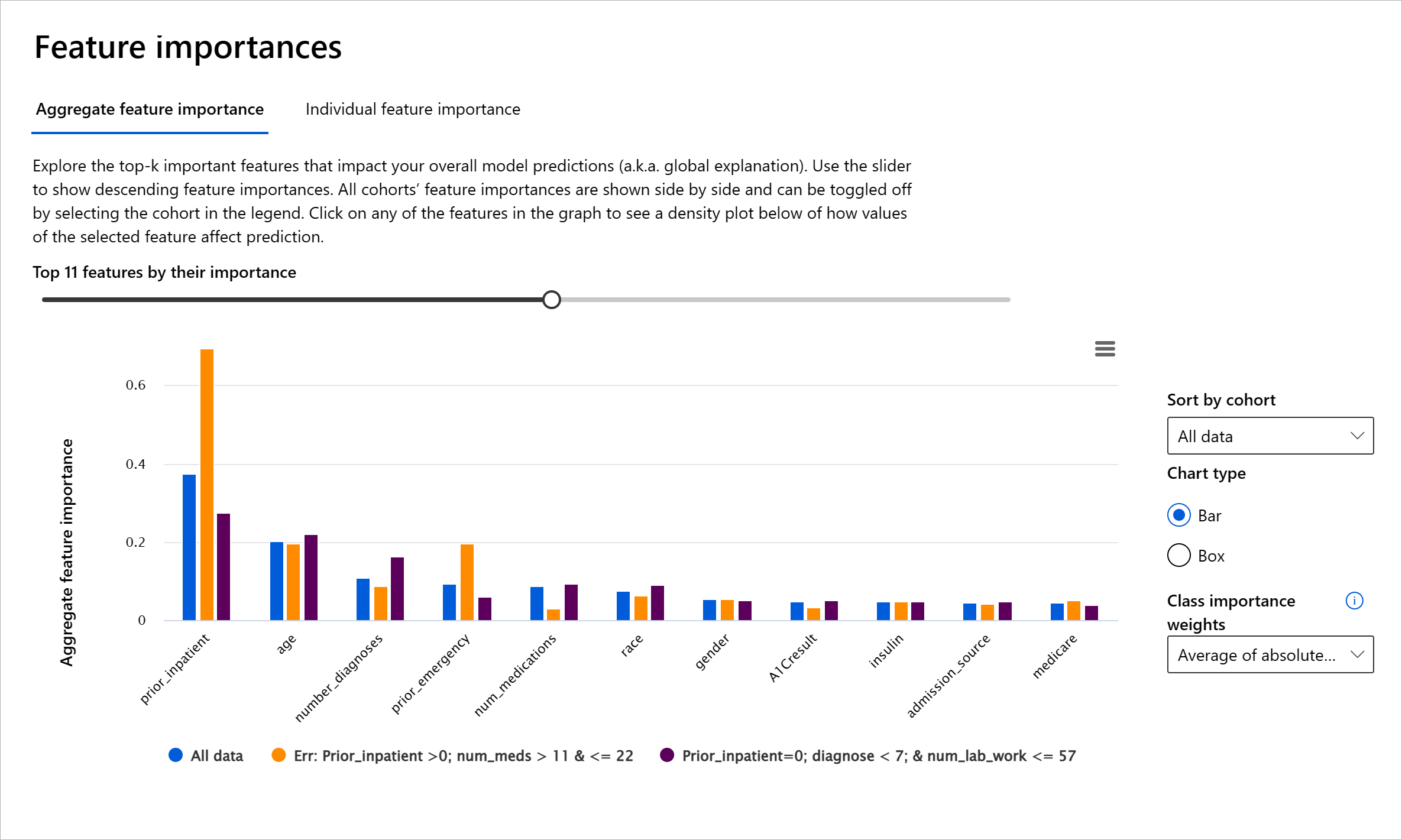
Global explanations: မော်ဒယ်၏ စုစုပေါင်း ခန့်မှန်းချက်များကို အားပေးသော features များကို ဖော်ပြသည်။ Local explanations: မော်ဒယ်၏ ခန့်မှန်းချက်တစ်ခုကို အားပေးသော features များကို ဖော်ပြသည်။
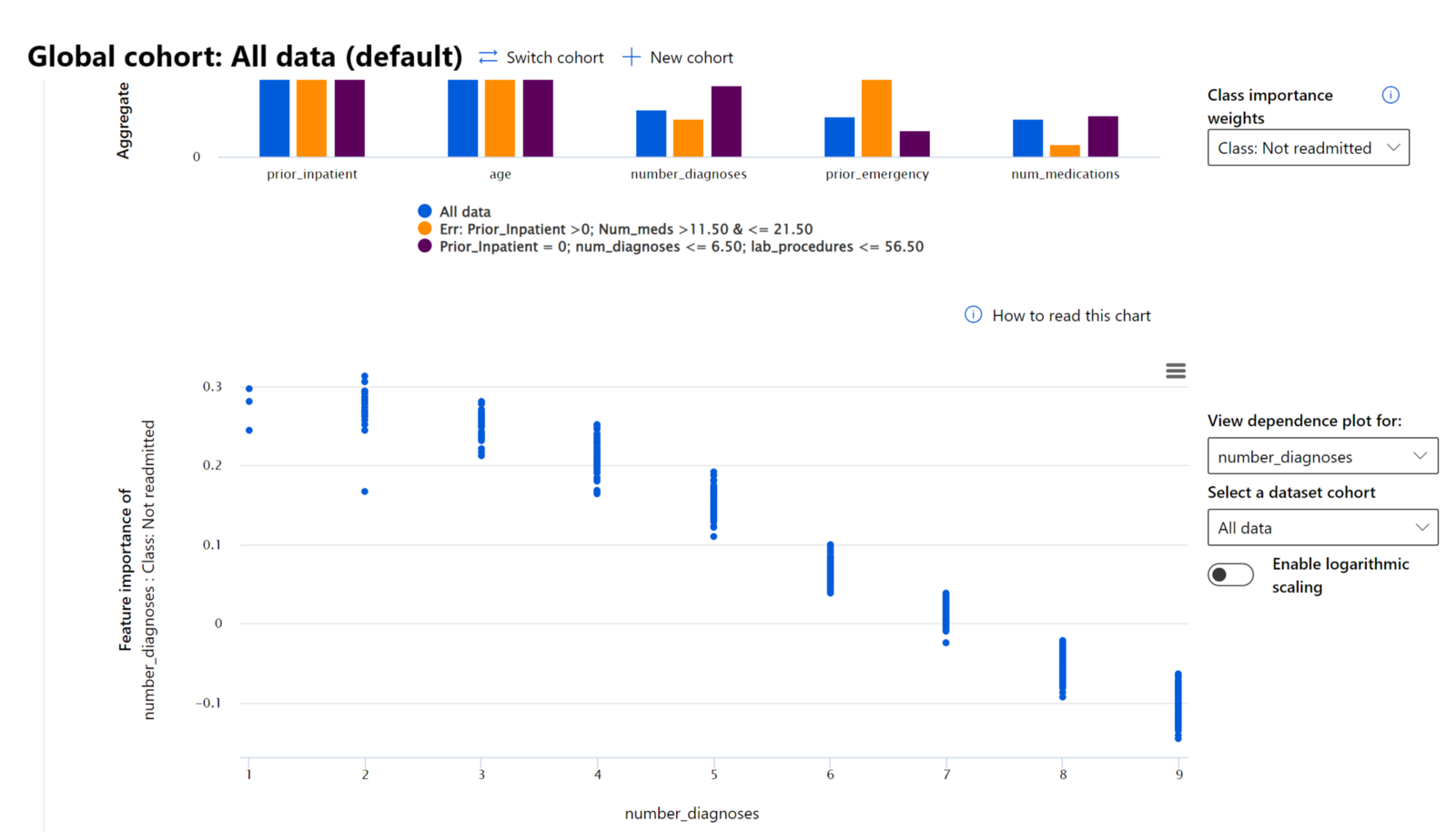
Interpretability ကို သင်လိုအပ်သောအခါ အသုံးပြုပါ-
- AI စနစ်၏ ခန့်မှန်းချက်များကို ယုံကြည်စိတ်ချရမှုရှိသည်ကို သတ်မှတ်ရန်။
- Debugging ပြုလုပ်ရန် မော်ဒယ်ကို နားလည်ပြီး Healthy features သို့မဟုတ် False correlations ကို ရှာဖွေရန်။
- Fairness ပြဿနာများကို ရှာဖွေရန် Sensitive features သို့မဟုတ် Correlated features များကို နားလည်ရန်။
- User trust တည်ဆောက်ရန် Local explanations များကို ဖော်ပြရန်။
- Regulatory audit ပြုလုပ်ရန် မော်ဒယ်များကို Validate ပြုလုပ်ပြီး လူသားများအပေါ် မော်ဒယ်၏ ဆုံးဖြတ်ချက်များ၏ သက်ရောက်မှုကို စောင့်ကြည့်ရန်။
နိဂုံး
RAI dashboard components များသည် လူ့အဖွဲ့အစည်းအပေါ် အနည်းဆုံးအန္တရာယ်ရှိပြီး ယုံကြည်စိတ်ချရသော Machine Learning မော်ဒယ်များ တည်ဆောက်ရန် အထောက်အကူပြုသည်။ Human rights ကို ထိခိုက်မှုမှ ကာကွယ်ရန်၊ အချို့သောအုပ်စုများကို အခွင့်အလမ်းများမှ ခွဲထုတ်ခြင်းမှ ကာကွယ်ရန်၊ ရုပ်ပိုင်းဆိုင်ရာ သို့မဟုတ် စိတ်ပိုင်းဆိုင်ရာ ထိခိုက်မှုများမှ ကာကွယ်ရန် အထောက်အကူပြုသည်။ Potential harms များကို အောက်ပါအတိုင်း ခွဲခြားနိုင်သည်-
- Allocation: ဥပမာ- လူမျိုး သို့မဟုတ် လိင်ကို အခြားအမျိုးအစားထက် အားပေးခြင်း။
- Quality of service: ဒေတာကို တစ်ခုတည်းသော အခြေအနေအတွက် training ပြုလုပ်ပြီး အမှန်တကယ်မှာ ပိုမိုရှုပ်ထွေးသောအခါ၊ poor performing service ဖြစ်စေသည်။
- Stereotyping: အုပ်စုတစ်ခုကို သတ်မှတ် attributes များနှင့် ဆက်စပ်ခြင်း။
- Denigration: တစ်စုံတစ်ခု သို့မဟုတ် တစ်စုံတစ်ဦးကို မတရားစွာ ဝေဖန်ခြင်း။
- အလွန်များခြင်း သို့မဟုတ် အလွန်နည်းခြင်း။ အဓိကအကြောင်းအရာမှာ အချို့သောအဖွဲ့အစည်းများသည် အချို့သောအလုပ်အကိုင်များတွင် မမြင်တွေ့ရခြင်းဖြစ်ပြီး၊ ထိုအခြေအနေကို ဆက်လက်မြှင့်တင်နေသော ဝန်ဆောင်မှု သို့မဟုတ် လုပ်ဆောင်မှုများသည် အနာတရကို ဖြစ်ပေါ်စေခြင်းဖြစ်သည်။
Azure RAI Dashboard
Azure RAI Dashboard သည် Microsoft အပါအဝင် ထိပ်တန်းပညာရေးအဖွဲ့အစည်းများနှင့် အဖွဲ့အစည်းများမှ ဖွံ့ဖြိုးတိုးတက်လာသော အခမဲ့အရင်းအမြစ်များပေါ်တွင် တည်ဆောက်ထားပြီး၊ ဒေတာသိပ္ပံပညာရှင်များနှင့် AI ဖွံ့ဖြိုးတိုးတက်ရေးလုပ်ငန်းများအတွက် မော်ဒယ်အပြုအမူကို ပိုမိုနားလည်စေခြင်း၊ AI မော်ဒယ်များမှ မလိုလားအပ်သောပြဿနာများကို ရှာဖွေပြီး လျှော့ချနိုင်ရန် အရေးပါသောအခန်းကဏ္ဍတစ်ခုဖြစ်သည်။
-
RAI Dashboard အကြောင်းအရာများ ကိုကြည့်ရှု၍ အစိတ်အပိုင်းများကို အသုံးပြုနည်းကို လေ့လာပါ။
-
Azure Machine Learning တွင် ပိုမိုတာဝန်ရှိသော AI အခြေအနေများကို အကောင်းဆုံးရှာဖွေခြင်းအတွက် RAI Dashboard နမူနာ notebook များ ကိုကြည့်ရှုပါ။
🚀 စိန်ခေါ်မှု
စစ်မှန်သော သို့မဟုတ် ဒေတာအလွှာများမှ အစပျိုးမဖြစ်စေရန်၊ ကျွန်ုပ်တို့သည် အောက်ပါအချက်များကို လုပ်ဆောင်သင့်သည်-
- စနစ်များတွင် လုပ်ဆောင်နေသောသူများအကြား နောက်ခံနှင့် အမြင်များ၏ အမျိုးမျိုးကို ရှိစေရန်
- ကျွန်ုပ်တို့၏ လူ့အဖွဲ့အစည်း၏ အမျိုးမျိုးကို အကျိုးသက်ရောက်စေသော ဒေတာများအတွက် ရင်းနှီးမြှုပ်နှံရန်
- အလွှာများကို ရှာဖွေပြီး ပြင်ဆင်နိုင်သော နည်းလမ်းများကို ပိုမိုကောင်းမွန်စေရန် ဖွံ့ဖြိုးတိုးတက်စေရန်
မော်ဒယ်တည်ဆောက်ခြင်းနှင့် အသုံးပြုခြင်းတွင် မတရားမှုများကို တွေ့ရှိရသော အမှန်တကယ်အခြေအနေများကို စဉ်းစားပါ။ ကျွန်ုပ်တို့အနေဖြင့် အခြားဘာများကို ထည့်သွင်းစဉ်းစားသင့်သနည်း?
Post-lecture quiz
ပြန်လည်သုံးသပ်ခြင်းနှင့် ကိုယ်တိုင်လေ့လာခြင်း
ဒီသင်ခန်းစာမှာ သင်သည် Machine Learning တွင် တာဝန်ရှိသော AI ကို ပေါင်းစပ်အသုံးပြုရန် အကောင်းဆုံးကိရိယာများကို လေ့လာခဲ့ပါသည်။
ဒီအကြောင်းအရာများကို ပိုမိုနက်ရှိုင်းစွာ လေ့လာရန် workshop ကို ကြည့်ရှုပါ-
- Responsible AI Dashboard: တာဝန်ရှိသော AI ကို လက်တွေ့အသုံးချရန်အတွက် အစုံအလင်ဖြစ်သော Besmira Nushi နှင့် Mehrnoosh Sameki

🎥 အထက်ပါပုံကို နှိပ်၍ Responsible AI Dashboard: တာဝန်ရှိသော AI ကို လက်တွေ့အသုံးချရန်အတွက် အစုံအလင် Besmira Nushi နှင့် Mehrnoosh Sameki ၏ ဗီဒီယိုကို ကြည့်ရှုပါ
တာဝန်ရှိသော AI နှင့် ပိုမိုယုံကြည်ရသော မော်ဒယ်များကို တည်ဆောက်နည်းကို လေ့လာရန် အောက်ပါအထောက်အထားများကို ကိုးကားပါ-
-
ML မော်ဒယ်များကို Debugging ပြုလုပ်ရန် Microsoft ၏ RAI Dashboard Tools: Responsible AI tools resources
-
Responsible AI toolkit ကို ရှာဖွေပါ: Github
-
Microsoft ၏ RAI အရင်းအမြစ်စင်တာ: Responsible AI Resources – Microsoft AI
-
Microsoft ၏ FATE သုတေသနအဖွဲ့: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
လုပ်ငန်းတာဝန်
ဝက်ဘ်ဆိုက်မှတ်ချက်:
ဤစာရွက်စာတမ်းကို AI ဘာသာပြန်ဝန်ဆောင်မှု Co-op Translator ကို အသုံးပြု၍ ဘာသာပြန်ထားပါသည်။ ကျွန်ုပ်တို့သည် တိကျမှန်ကန်မှုအတွက် ကြိုးစားနေပါသော်လည်း၊ အလိုအလျောက်ဘာသာပြန်ဆိုမှုများတွင် အမှားများ သို့မဟုတ် မတိကျမှုများ ပါဝင်နိုင်သည်ကို ကျေးဇူးပြု၍ သတိပြုပါ။ မူရင်းစာရွက်စာတမ်းကို ၎င်း၏ မူလဘာသာစကားဖြင့် အာဏာတည်သောရင်းမြစ်အဖြစ် သတ်မှတ်သင့်ပါသည်။ အရေးကြီးသော အချက်အလက်များအတွက် လူ့ဘာသာပြန်ပညာရှင်များမှ ပြန်ဆိုမှုကို အကြံပြုပါသည်။ ဤဘာသာပြန်ကို အသုံးပြုခြင်းမှ ဖြစ်ပေါ်လာသော နားလည်မှုမှားများ သို့မဟုတ် အဓိပ္ပါယ်မှားများအတွက် ကျွန်ုပ်တို့သည် တာဝန်မယူပါ။