|
|
8 months ago | |
|---|---|---|
| .. | ||
| solution | 8 months ago | |
| README.md | 8 months ago | |
| assignment.md | 8 months ago | |
README.md
CartPole Pateni
Önceki derste çözmekte olduğumuz problem, gerçek hayat senaryolarına pek uygulanabilir olmayan bir oyuncak problem gibi görünebilir. Ancak durum böyle değil, çünkü birçok gerçek dünya problemi de bu senaryoyu paylaşır - Satranç veya Go oynamak da dahil. Bunlar benzerdir çünkü verilen kurallara sahip bir tahtamız ve ayrık bir durumumuz vardır.
Ders Öncesi Quiz
Giriş
Bu derste, Q-Öğrenme prensiplerini sürekli durum olan bir probleme uygulayacağız, yani bir veya daha fazla gerçek sayı ile verilen bir duruma. Aşağıdaki problemle ilgileneceğiz:
Problem: Peter kurtlardan kaçmak istiyorsa daha hızlı hareket edebilmelidir. Peter'ın kaymayı, özellikle dengeyi korumayı, Q-Öğrenme kullanarak nasıl öğrenebileceğini göreceğiz.

Peter ve arkadaşları kurtlardan kaçmak için yaratıcı oluyorlar! Görsel: Jen Looper
Dengelemeyi basitleştirilmiş bir versiyon olan CartPole problemi olarak kullanacağız. CartPole dünyasında, sola veya sağa hareket edebilen yatay bir kaydırıcımız var ve amaç, kaydırıcının üstündeki dikey direği dengelemek. Ekim 2023'e kadar olan verilere dayalı olarak eğitildiniz.
Ön Gereksinimler
Bu derste, farklı ortamları simüle etmek için OpenAI Gym adlı bir kütüphane kullanacağız. Bu dersin kodunu yerel olarak (örneğin, Visual Studio Code'dan) çalıştırabilirsiniz, bu durumda simülasyon yeni bir pencerede açılacaktır. Kodu çevrimiçi çalıştırırken, kodda bazı değişiklikler yapmanız gerekebilir, bu durum burada açıklanmıştır.
OpenAI Gym
Önceki derste, oyunun kuralları ve durum, kendimiz tanımladığımız Board sınıfı tarafından verilmişti. Burada, denge direğinin arkasındaki fiziği simüle edecek özel bir simülasyon ortamı kullanacağız. Takviye öğrenme algoritmalarını eğitmek için en popüler simülasyon ortamlarından biri, OpenAI tarafından sürdürülen Gym adlı bir ortamdır. Bu gym'i kullanarak, cartpole simülasyonundan Atari oyunlarına kadar farklı ortamlar oluşturabiliriz.
Not: OpenAI Gym tarafından sunulan diğer ortamları buradan görebilirsiniz.
İlk olarak, gym'i yükleyelim ve gerekli kütüphaneleri içe aktaralım (kod bloğu 1):
import sys
!{sys.executable} -m pip install gym
import gym
import matplotlib.pyplot as plt
import numpy as np
import random
Egzersiz - bir cartpole ortamı başlatma
Cartpole dengeleme problemi ile çalışmak için ilgili ortamı başlatmamız gerekiyor. Her ortam şunlarla ilişkilidir:
-
Gözlem alanı: Ortamdan aldığımız bilgilerin yapısını tanımlar. Cartpole problemi için, direğin konumu, hızı ve bazı diğer değerleri alırız.
-
Eylem alanı: Olası eylemleri tanımlar. Bizim durumumuzda eylem alanı ayrık olup, iki eylemden oluşur - sol ve sağ. (kod bloğu 2)
-
Başlatmak için aşağıdaki kodu yazın:
env = gym.make("CartPole-v1") print(env.action_space) print(env.observation_space) print(env.action_space.sample())
Ortamın nasıl çalıştığını görmek için, 100 adımlık kısa bir simülasyon çalıştıralım. Her adımda, alınacak bir eylemi sağlıyoruz - bu simülasyonda action_space'ten rastgele bir eylem seçiyoruz.
-
Aşağıdaki kodu çalıştırın ve neye yol açtığını görün.
✅ Bu kodu yerel Python kurulumunda çalıştırmanız tercih edilir! (kod bloğu 3)
env.reset() for i in range(100): env.render() env.step(env.action_space.sample()) env.close()Şuna benzer bir şey görmelisiniz:

-
Simülasyon sırasında, nasıl hareket edileceğine karar vermek için gözlemler almamız gerekir. Aslında, step fonksiyonu mevcut gözlemleri, bir ödül fonksiyonunu ve simülasyonun devam edip etmeyeceğini belirten done bayrağını döndürür: (kod bloğu 4)
env.reset() done = False while not done: env.render() obs, rew, done, info = env.step(env.action_space.sample()) print(f"{obs} -> {rew}") env.close()Not defterinin çıktısında buna benzer bir şey görmelisiniz:
[ 0.03403272 -0.24301182 0.02669811 0.2895829 ] -> 1.0 [ 0.02917248 -0.04828055 0.03248977 0.00543839] -> 1.0 [ 0.02820687 0.14636075 0.03259854 -0.27681916] -> 1.0 [ 0.03113408 0.34100283 0.02706215 -0.55904489] -> 1.0 [ 0.03795414 0.53573468 0.01588125 -0.84308041] -> 1.0 ... [ 0.17299878 0.15868546 -0.20754175 -0.55975453] -> 1.0 [ 0.17617249 0.35602306 -0.21873684 -0.90998894] -> 1.0Simülasyonun her adımında döndürülen gözlem vektörü şu değerleri içerir:
- Arabanın konumu
- Arabanın hızı
- Direğin açısı
- Direğin dönme hızı
-
Bu sayıların minimum ve maksimum değerlerini alın: (kod bloğu 5)
print(env.observation_space.low) print(env.observation_space.high)Ayrıca, her simülasyon adımında ödül değerinin her zaman 1 olduğunu fark edebilirsiniz. Bunun nedeni, amacımızın mümkün olduğunca uzun süre hayatta kalmak, yani direği makul bir dikey pozisyonda en uzun süre tutmaktır.
✅ Aslında, CartPole simülasyonu, 100 ardışık denemede 195 ortalama ödül elde etmeyi başardığımızda çözülmüş kabul edilir.
Durum ayrıklaştırma
Q-Öğrenme'de, her durumda ne yapacağımızı tanımlayan bir Q-Tablosu oluşturmamız gerekir. Bunu yapabilmek için, durumun ayrık olması gerekir, daha kesin olarak, sonlu sayıda ayrık değer içermelidir. Bu nedenle, gözlemlerimizi ayrıklaştırmamız ve bunları sonlu bir durum kümesine eşlememiz gerekir.
Bunu yapmanın birkaç yolu vardır:
- Kovalar halinde bölme. Belirli bir değerin aralığını biliyorsak, bu aralığı bir dizi kovaya bölebiliriz ve ardından değeri ait olduğu kova numarasıyla değiştirebiliriz. Bu, numpy
digitizeyöntemi kullanılarak yapılabilir. Bu durumda, durum boyutunu kesin olarak bileceğiz, çünkü bu, dijitalleştirme için seçtiğimiz kova sayısına bağlı olacaktır.
✅ Değerleri belirli bir sonlu aralığa (örneğin, -20'den 20'ye) getirmek için lineer enterpolasyon kullanabiliriz ve ardından sayıları yuvarlayarak tamsayıya dönüştürebiliriz. Bu bize durum boyutu üzerinde biraz daha az kontrol sağlar, özellikle de giriş değerlerinin kesin aralıklarını bilmiyorsak. Örneğin, bizim durumumuzda 4 değerden 2'sinin değerlerinde üst/alt sınırlar yoktur, bu da sonsuz sayıda duruma neden olabilir.
Örneğimizde, ikinci yaklaşımı kullanacağız. Daha sonra fark edeceğiniz gibi, tanımlanmamış üst/alt sınırlara rağmen, bu değerler nadiren belirli sonlu aralıkların dışında değerler alır, bu nedenle aşırı değerli durumlar çok nadir olacaktır.
-
Modelimizden gözlemi alacak ve 4 tamsayı değerinden oluşan bir demet üretecek fonksiyon burada: (kod bloğu 6)
def discretize(x): return tuple((x/np.array([0.25, 0.25, 0.01, 0.1])).astype(np.int)) -
Kovalar kullanarak başka bir ayrıklaştırma yöntemini de inceleyelim: (kod bloğu 7)
def create_bins(i,num): return np.arange(num+1)*(i[1]-i[0])/num+i[0] print("Sample bins for interval (-5,5) with 10 bins\n",create_bins((-5,5),10)) ints = [(-5,5),(-2,2),(-0.5,0.5),(-2,2)] # intervals of values for each parameter nbins = [20,20,10,10] # number of bins for each parameter bins = [create_bins(ints[i],nbins[i]) for i in range(4)] def discretize_bins(x): return tuple(np.digitize(x[i],bins[i]) for i in range(4)) -
Şimdi kısa bir simülasyon çalıştıralım ve bu ayrık ortam değerlerini gözlemleyelim. Hem
discretizeanddiscretize_binskullanmayı deneyin ve fark olup olmadığını görün.✅ discretize_bins, kova numarasını döndürür, bu 0 tabanlıdır. Dolayısıyla, giriş değişkeninin etrafındaki değerler için 0, aralığın ortasındaki numarayı (10) döndürür. Discretize'de, çıktı değerlerinin aralığını önemsemedik, negatif olmalarına izin verdik, bu nedenle durum değerleri kaydırılmamış ve 0, 0'a karşılık gelir. (kod bloğu 8)
env.reset() done = False while not done: #env.render() obs, rew, done, info = env.step(env.action_space.sample()) #print(discretize_bins(obs)) print(discretize(obs)) env.close()✅ Ortamın nasıl çalıştığını görmek istiyorsanız env.render ile başlayan satırı yorumdan çıkarın. Aksi takdirde arka planda çalıştırabilirsiniz, bu daha hızlıdır. Q-Öğrenme sürecimiz sırasında bu "görünmez" yürütmeyi kullanacağız.
Q-Tablosu yapısı
Önceki dersimizde, durum 0'dan 8'e kadar olan basit bir sayı çiftiydi ve bu nedenle Q-Tablosunu 8x8x2 şeklinde bir numpy tensörü ile temsil etmek uygundu. Kovalar ayrıklaştırmasını kullanırsak, durum vektörümüzün boyutu da bilinir, bu yüzden aynı yaklaşımı kullanabiliriz ve durumu 20x20x10x10x2 şeklinde bir dizi ile temsil edebiliriz (burada 2, eylem alanının boyutudur ve ilk boyutlar gözlem alanındaki her parametre için kullanmayı seçtiğimiz kova sayısına karşılık gelir).
Ancak, bazen gözlem alanının kesin boyutları bilinmez. discretize fonksiyonu durumunda, bazı orijinal değerler bağlanmadığı için durumun belirli sınırlar içinde kaldığından asla emin olamayabiliriz. Bu nedenle, biraz farklı bir yaklaşım kullanacağız ve Q-Tablosunu bir sözlükle temsil edeceğiz.
-
(state,action) çiftini sözlük anahtarı olarak kullanın ve değer Q-Tablosu giriş değerine karşılık gelir. (kod bloğu 9)
Q = {} actions = (0,1) def qvalues(state): return [Q.get((state,a),0) for a in actions]Burada, belirli bir durum için Q-Tablosu değerlerinin bir listesini döndüren
qvalues()fonksiyonunu da tanımlıyoruz, bu tüm olası eylemlere karşılık gelir. Giriş Q-Tablosunda mevcut değilse, varsayılan olarak 0 döndüreceğiz.
Q-Öğrenmeye Başlayalım
Şimdi Peter'a dengeyi öğretmeye hazırız!
-
İlk olarak, bazı hiperparametreleri ayarlayalım: (kod bloğu 10)
# hyperparameters alpha = 0.3 gamma = 0.9 epsilon = 0.90Burada,
alphais the learning rate that defines to which extent we should adjust the current values of Q-Table at each step. In the previous lesson we started with 1, and then decreasedalphato lower values during training. In this example we will keep it constant just for simplicity, and you can experiment with adjustingalphavalues later.gammais the discount factor that shows to which extent we should prioritize future reward over current reward.epsilonis the exploration/exploitation factor that determines whether we should prefer exploration to exploitation or vice versa. In our algorithm, we will inepsilonpercent of the cases select the next action according to Q-Table values, and in the remaining number of cases we will execute a random action. This will allow us to explore areas of the search space that we have never seen before.✅ In terms of balancing - choosing random action (exploration) would act as a random punch in the wrong direction, and the pole would have to learn how to recover the balance from those "mistakes"
Improve the algorithm
We can also make two improvements to our algorithm from the previous lesson:
-
Calculate average cumulative reward, over a number of simulations. We will print the progress each 5000 iterations, and we will average out our cumulative reward over that period of time. It means that if we get more than 195 point - we can consider the problem solved, with even higher quality than required.
-
Calculate maximum average cumulative result,
Qmax, and we will store the Q-Table corresponding to that result. When you run the training you will notice that sometimes the average cumulative result starts to drop, and we want to keep the values of Q-Table that correspond to the best model observed during training.
-
Collect all cumulative rewards at each simulation at
rewardsvektörünü daha sonra çizim için saklıyoruz. (kod bloğu 11)def probs(v,eps=1e-4): v = v-v.min()+eps v = v/v.sum() return v Qmax = 0 cum_rewards = [] rewards = [] for epoch in range(100000): obs = env.reset() done = False cum_reward=0 # == do the simulation == while not done: s = discretize(obs) if random.random()<epsilon: # exploitation - chose the action according to Q-Table probabilities v = probs(np.array(qvalues(s))) a = random.choices(actions,weights=v)[0] else: # exploration - randomly chose the action a = np.random.randint(env.action_space.n) obs, rew, done, info = env.step(a) cum_reward+=rew ns = discretize(obs) Q[(s,a)] = (1 - alpha) * Q.get((s,a),0) + alpha * (rew + gamma * max(qvalues(ns))) cum_rewards.append(cum_reward) rewards.append(cum_reward) # == Periodically print results and calculate average reward == if epoch%5000==0: print(f"{epoch}: {np.average(cum_rewards)}, alpha={alpha}, epsilon={epsilon}") if np.average(cum_rewards) > Qmax: Qmax = np.average(cum_rewards) Qbest = Q cum_rewards=[]
Bu sonuçlardan fark edebileceğiniz şeyler:
-
Hedefimize yakınız. 100'den fazla ardışık simülasyon çalıştırmasında 195 kümülatif ödül alma hedefimize çok yakınız veya aslında başardık! Daha küçük sayılar alsak bile, 5000 çalıştırma üzerinden ortalama alıyoruz ve resmi kriterde sadece 100 çalıştırma gereklidir.
-
Ödül düşmeye başlıyor. Bazen ödül düşmeye başlar, bu da Q-Tablosunda zaten öğrenilmiş değerleri daha kötü duruma getirenlerle "bozabileceğimiz" anlamına gelir.
Bu gözlem, eğitim ilerlemesini çizdiğimizde daha net görülür.
Eğitim İlerlemesini Çizmek
Eğitim sırasında, her yinelemede kümülatif ödül değerini rewards vektörüne topladık. İşte bunu yineleme sayısına karşı çizdiğimizde nasıl göründüğü:
plt.plot(rewards)
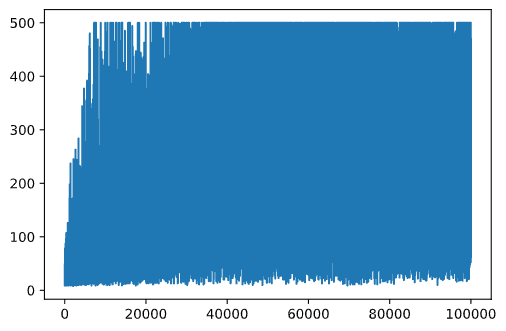
Bu grafikten bir şey anlamak mümkün değil, çünkü stokastik eğitim sürecinin doğası gereği eğitim oturumlarının uzunluğu büyük ölçüde değişir. Bu grafiği daha anlamlı hale getirmek için, örneğin 100 deney üzerinde hareketli ortalama hesaplayabiliriz. Bu, np.convolve kullanılarak uygun bir şekilde yapılabilir: (kod bloğu 12)
def running_average(x,window):
return np.convolve(x,np.ones(window)/window,mode='valid')
plt.plot(running_average(rewards,100))
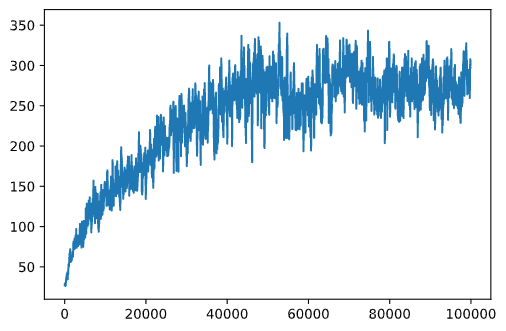
Hiperparametreleri Değiştirme
Öğrenmeyi daha kararlı hale getirmek için, eğitim sırasında bazı hiperparametrelerimizi ayarlamak mantıklıdır. Özellikle:
-
Öğrenme oranı için,
alpha, we may start with values close to 1, and then keep decreasing the parameter. With time, we will be getting good probability values in the Q-Table, and thus we should be adjusting them slightly, and not overwriting completely with new values. -
Increase epsilon. We may want to increase the
epsilonslowly, in order to explore less and exploit more. It probably makes sense to start with lower value ofepsilonve neredeyse 1'e kadar çıkın.
Görev 1: Hiperparametre değerleriyle oynayın ve daha yüksek kümülatif ödül elde edip edemeyeceğinizi görün. 195'in üzerine çıkabiliyor musunuz?
Görev 2: Problemi resmi olarak çözmek için, 100 ardışık çalıştırma boyunca 195 ortalama ödül almanız gerekir. Bunu eğitim sırasında ölçün ve problemi resmi olarak çözdüğünüzden emin olun!
Sonucu Aksiyon Halinde Görmek
Eğitilmiş modelin nasıl davrandığını görmek ilginç olurdu. Simülasyonu çalıştıralım ve eğitim sırasında olduğu gibi Q-Tablosundaki olasılık dağılımına göre eylem seçme stratejisini izleyelim: (kod bloğu 13)
obs = env.reset()
done = False
while not done:
s = discretize(obs)
env.render()
v = probs(np.array(qvalues(s)))
a = random.choices(actions,weights=v)[0]
obs,_,done,_ = env.step(a)
env.close()
Şuna benzer bir şey görmelisiniz:

🚀Meydan Okuma
Görev 3: Burada, Q-Tablosunun son kopyasını kullandık, bu en iyisi olmayabilir. En iyi performans gösteren Q-Tablosunu
Qbestvariable! Try the same example with the best-performing Q-Table by copyingQbestover toQand see if you notice the difference.
Task 4: Here we were not selecting the best action on each step, but rather sampling with corresponding probability distribution. Would it make more sense to always select the best action, with the highest Q-Table value? This can be done by using
np.argmaxfonksiyonunu kullanarak, en yüksek Q-Tablosu değerine karşılık gelen eylem numarasını bulmak için bu stratejiyi uygulayın ve dengelemeyi iyileştirip iyileştirmediğini görün.
Ders Sonrası Quiz
Ödev
Sonuç
Artık ajanları yalnızca oyunun istenen durumunu tanımlayan bir ödül fonksiyonu sağlayarak ve arama alanını zekice keşfetme fırsatı vererek iyi sonuçlar elde etmeyi nasıl eğiteceğimizi öğrendik. Q-Öğrenme algoritmasını ayrık ve sürekli ortamlar durumunda başarıyla uyguladık, ancak ayrık eylemlerle.
Eylem durumunun da sürekli olduğu ve gözlem alanının çok daha karmaşık olduğu durumları da incelemek önemlidir, örneğin Atari oyun ekranından gelen görüntü gibi. Bu tür problemler, iyi sonuçlar elde etmek için genellikle daha güçlü makine öğrenme teknikleri, örneğin sinir ağları, kullanmamızı gerektirir. Bu daha ileri konular, ileri düzey AI kursumuzun konusudur.
Feragatname: Bu belge, makine tabanlı yapay zeka çeviri hizmetleri kullanılarak çevrilmiştir. Doğruluk için çaba göstersek de, otomatik çevirilerin hata veya yanlışlıklar içerebileceğini lütfen unutmayın. Orijinal belgenin kendi dilindeki hali yetkili kaynak olarak kabul edilmelidir. Kritik bilgiler için profesyonel insan çevirisi tavsiye edilir. Bu çevirinin kullanımından doğabilecek herhangi bir yanlış anlama veya yanlış yorumlamadan sorumlu değiliz.