|
|
8 months ago | |
|---|---|---|
| .. | ||
| solution | 8 months ago | |
| README.md | 8 months ago | |
| assignment.md | 8 months ago | |
README.md
Vigezo vya awali
Katika somo hili, tutatumia maktaba inayoitwa OpenAI Gym kusimulia mazingira tofauti. Unaweza kuendesha msimbo wa somo hili kwenye kompyuta yako (mfano kutoka Visual Studio Code), ambapo simulizi itafunguka kwenye dirisha jipya. Unapoendesha msimbo mtandaoni, unaweza kuhitaji kufanya mabadiliko kadhaa kwenye msimbo, kama ilivyoelezwa hapa.
OpenAI Gym
Katika somo lililopita, sheria za mchezo na hali zilitolewa na darasa la Board ambalo tulilifafanua wenyewe. Hapa tutatumia mazingira maalum ya simulizi, ambayo yatasimulia fizikia ya fimbo inayosawazisha. Mojawapo ya mazingira maarufu ya simulizi kwa mafunzo ya algorithimu za kujifunza kuimarisha inaitwa Gym, ambayo inadumishwa na OpenAI. Kwa kutumia gym hii tunaweza kuunda mazingira tofauti kutoka simulizi ya cartpole hadi michezo ya Atari.
Kumbuka: Unaweza kuona mazingira mengine yanayopatikana kutoka OpenAI Gym hapa.
Kwanza, wacha tufunge gym na tuagize maktaba zinazohitajika (msimbo wa block 1):
import sys
!{sys.executable} -m pip install gym
import gym
import matplotlib.pyplot as plt
import numpy as np
import random
Zoezi - anzisha mazingira ya cartpole
Ili kufanya kazi na tatizo la kusawazisha cartpole, tunahitaji kuanzisha mazingira yanayolingana. Kila mazingira yanaunganishwa na:
-
Nafasi ya uchunguzi inayofafanua muundo wa taarifa tunazopokea kutoka kwa mazingira. Kwa tatizo la cartpole, tunapokea nafasi ya fimbo, kasi na thamani nyinginezo.
-
Nafasi ya hatua inayofafanua hatua zinazowezekana. Katika kesi yetu nafasi ya hatua ni ya kidijitali, na inajumuisha hatua mbili - kushoto na kulia. (msimbo wa block 2)
-
Ili kuanzisha, andika msimbo ufuatao:
env = gym.make("CartPole-v1") print(env.action_space) print(env.observation_space) print(env.action_space.sample())
Ili kuona jinsi mazingira yanavyofanya kazi, wacha tuendeshe simulizi fupi kwa hatua 100. Katika kila hatua, tunatoa moja ya hatua zinazochukuliwa - katika simulizi hii tunachagua hatua kwa nasibu kutoka action_space.
-
Endesha msimbo hapa chini na uone matokeo.
✅ Kumbuka kuwa inapendekezwa kuendesha msimbo huu kwenye usakinishaji wa Python wa ndani! (msimbo wa block 3)
env.reset() for i in range(100): env.render() env.step(env.action_space.sample()) env.close()Unapaswa kuona kitu kinachofanana na picha hii:

-
Wakati wa simulizi, tunahitaji kupata uchunguzi ili kuamua jinsi ya kuchukua hatua. Kwa kweli, kazi ya hatua inarejesha uchunguzi wa sasa, kazi ya tuzo, na bendera ya kumaliza inayoweka wazi kama ina maana kuendelea na simulizi au la: (msimbo wa block 4)
env.reset() done = False while not done: env.render() obs, rew, done, info = env.step(env.action_space.sample()) print(f"{obs} -> {rew}") env.close()Mwishowe utaona kitu kama hiki kwenye matokeo ya daftari:
[ 0.03403272 -0.24301182 0.02669811 0.2895829 ] -> 1.0 [ 0.02917248 -0.04828055 0.03248977 0.00543839] -> 1.0 [ 0.02820687 0.14636075 0.03259854 -0.27681916] -> 1.0 [ 0.03113408 0.34100283 0.02706215 -0.55904489] -> 1.0 [ 0.03795414 0.53573468 0.01588125 -0.84308041] -> 1.0 ... [ 0.17299878 0.15868546 -0.20754175 -0.55975453] -> 1.0 [ 0.17617249 0.35602306 -0.21873684 -0.90998894] -> 1.0Vector ya uchunguzi inayorejeshwa katika kila hatua ya simulizi inajumuisha thamani zifuatazo:
- Nafasi ya gari
- Kasi ya gari
- Pembe ya fimbo
- Kiwango cha mzunguko wa fimbo
-
Pata thamani ndogo na kubwa ya namba hizo: (msimbo wa block 5)
print(env.observation_space.low) print(env.observation_space.high)Unaweza pia kugundua kuwa thamani ya tuzo katika kila hatua ya simulizi ni 1 kila wakati. Hii ni kwa sababu lengo letu ni kuishi kwa muda mrefu iwezekanavyo, yaani kuweka fimbo katika nafasi ya wima kwa muda mrefu zaidi.
✅ Kwa kweli, simulizi ya CartPole inachukuliwa kuwa imetatuliwa ikiwa tutafanikiwa kupata wastani wa tuzo ya 195 katika majaribio 100 mfululizo.
Ugawanyaji wa hali
Katika Q-Learning, tunahitaji kujenga Jedwali la Q linalofafanua nini cha kufanya katika kila hali. Ili kufanya hivyo, tunahitaji hali kuwa ya kidijitali, kwa usahihi zaidi, inapaswa kuwa na idadi ndogo ya thamani za kidijitali. Kwa hivyo, tunahitaji kwa namna fulani kugawanya uchunguzi wetu, kuziunganisha kwenye seti ndogo ya hali.
Kuna njia kadhaa tunaweza kufanya hivi:
- Gawa katika sehemu. Ikiwa tunajua kipindi cha thamani fulani, tunaweza kugawa kipindi hiki katika idadi ya sehemu, na kisha kubadilisha thamani kwa namba ya sehemu ambayo inahusiana nayo. Hii inaweza kufanywa kwa kutumia njia ya numpy
digitize. Katika kesi hii, tutajua kwa usahihi ukubwa wa hali, kwa sababu itategemea idadi ya sehemu tunazochagua kwa ajili ya digitalization.
✅ Tunaweza kutumia usawazishaji wa mstari kuleta thamani kwa kipindi fulani (sema, kutoka -20 hadi 20), na kisha kubadilisha namba kuwa namba za tarakimu kwa kuzungusha. Hii inatupa udhibiti mdogo wa ukubwa wa hali, hasa ikiwa hatujui mipaka halisi ya thamani za ingizo. Kwa mfano, katika kesi yetu 2 kati ya 4 hazina mipaka ya juu/chini ya thamani zao, ambazo zinaweza kusababisha idadi isiyo na kikomo ya hali.
Katika mfano wetu, tutatumia mbinu ya pili. Kama utakavyogundua baadaye, licha ya mipaka isiyoeleweka ya juu/chini, thamani hizo mara chache huchukua thamani nje ya vipindi fulani, hivyo hali hizo zenye thamani za juu zitakuwa nadra sana.
-
Hapa kuna kazi itakayochukua uchunguzi kutoka kwa mfano wetu na kutoa jozi ya thamani za tarakimu 4: (msimbo wa block 6)
def discretize(x): return tuple((x/np.array([0.25, 0.25, 0.01, 0.1])).astype(np.int)) -
Wacha pia tuchunguze njia nyingine ya ugawanyaji kwa kutumia sehemu: (msimbo wa block 7)
def create_bins(i,num): return np.arange(num+1)*(i[1]-i[0])/num+i[0] print("Sample bins for interval (-5,5) with 10 bins\n",create_bins((-5,5),10)) ints = [(-5,5),(-2,2),(-0.5,0.5),(-2,2)] # intervals of values for each parameter nbins = [20,20,10,10] # number of bins for each parameter bins = [create_bins(ints[i],nbins[i]) for i in range(4)] def discretize_bins(x): return tuple(np.digitize(x[i],bins[i]) for i in range(4)) -
Wacha sasa tuendeshe simulizi fupi na kuchunguza thamani hizo za mazingira ya kidijitali. Jisikie huru kujaribu zote
discretizeanddiscretize_binsna kuona kama kuna tofauti.✅ discretize_bins inarejesha namba ya sehemu, ambayo ni ya msingi 0. Kwa hivyo kwa thamani za ingizo karibu na 0 inarejesha namba kutoka katikati ya kipindi (10). Katika discretize, hatukujali kuhusu wigo wa thamani za matokeo, tukiruhusu kuwa hasi, hivyo thamani za hali hazijahamishwa, na 0 inahusiana na 0. (msimbo wa block 8)
env.reset() done = False while not done: #env.render() obs, rew, done, info = env.step(env.action_space.sample()) #print(discretize_bins(obs)) print(discretize(obs)) env.close()✅ Ondoa mstari unaoanza na env.render ikiwa unataka kuona jinsi mazingira yanavyotekelezwa. Vinginevyo unaweza kuutekeleza kwa siri, ambayo ni haraka zaidi. Tutatumia utekelezaji huu wa "kisiri" wakati wa mchakato wetu wa Q-Learning.
Muundo wa Jedwali la Q
Katika somo letu lililopita, hali ilikuwa jozi rahisi ya namba kutoka 0 hadi 8, na hivyo ilikuwa rahisi kuwakilisha Jedwali la Q kwa tensor ya numpy yenye umbo la 8x8x2. Ikiwa tunatumia ugawanyaji wa sehemu, ukubwa wa vector yetu ya hali pia unajulikana, hivyo tunaweza kutumia mbinu hiyo hiyo na kuwakilisha hali kwa safu yenye umbo la 20x20x10x10x2 (hapa 2 ni kipimo cha nafasi ya hatua, na vipimo vya kwanza vinahusiana na idadi ya sehemu tulizochagua kutumia kwa kila moja ya vigezo katika nafasi ya uchunguzi).
Hata hivyo, wakati mwingine vipimo halisi vya nafasi ya uchunguzi havijulikani. Katika kesi ya kazi ya discretize, hatuwezi kuwa na uhakika kwamba hali yetu inakaa ndani ya mipaka fulani, kwa sababu baadhi ya thamani za awali hazina mipaka. Kwa hivyo, tutatumia mbinu tofauti kidogo na kuwakilisha Jedwali la Q kwa kamusi.
-
Tumia jozi (state,action) kama ufunguo wa kamusi, na thamani itahusiana na thamani ya ingizo la Jedwali la Q. (msimbo wa block 9)
Q = {} actions = (0,1) def qvalues(state): return [Q.get((state,a),0) for a in actions]Hapa pia tunafafanua kazi
qvalues(), inayorejesha orodha ya thamani za Jedwali la Q kwa hali fulani inayohusiana na hatua zote zinazowezekana. Ikiwa ingizo halipo kwenye Jedwali la Q, tutarejesha 0 kama chaguo-msingi.
Wacha tuanze Q-Learning
Sasa tuko tayari kumfundisha Peter kusawazisha!
-
Kwanza, wacha tuchague baadhi ya vigezo vya msingi: (msimbo wa block 10)
# hyperparameters alpha = 0.3 gamma = 0.9 epsilon = 0.90Hapa,
alphais the learning rate that defines to which extent we should adjust the current values of Q-Table at each step. In the previous lesson we started with 1, and then decreasedalphato lower values during training. In this example we will keep it constant just for simplicity, and you can experiment with adjustingalphavalues later.gammais the discount factor that shows to which extent we should prioritize future reward over current reward.epsilonis the exploration/exploitation factor that determines whether we should prefer exploration to exploitation or vice versa. In our algorithm, we will inepsilonpercent of the cases select the next action according to Q-Table values, and in the remaining number of cases we will execute a random action. This will allow us to explore areas of the search space that we have never seen before.✅ In terms of balancing - choosing random action (exploration) would act as a random punch in the wrong direction, and the pole would have to learn how to recover the balance from those "mistakes"
Improve the algorithm
We can also make two improvements to our algorithm from the previous lesson:
-
Calculate average cumulative reward, over a number of simulations. We will print the progress each 5000 iterations, and we will average out our cumulative reward over that period of time. It means that if we get more than 195 point - we can consider the problem solved, with even higher quality than required.
-
Calculate maximum average cumulative result,
Qmax, and we will store the Q-Table corresponding to that result. When you run the training you will notice that sometimes the average cumulative result starts to drop, and we want to keep the values of Q-Table that correspond to the best model observed during training.
-
Collect all cumulative rewards at each simulation at
rewardsvector kwa ajili ya kuchora baadaye. (msimbo wa block 11)def probs(v,eps=1e-4): v = v-v.min()+eps v = v/v.sum() return v Qmax = 0 cum_rewards = [] rewards = [] for epoch in range(100000): obs = env.reset() done = False cum_reward=0 # == do the simulation == while not done: s = discretize(obs) if random.random()<epsilon: # exploitation - chose the action according to Q-Table probabilities v = probs(np.array(qvalues(s))) a = random.choices(actions,weights=v)[0] else: # exploration - randomly chose the action a = np.random.randint(env.action_space.n) obs, rew, done, info = env.step(a) cum_reward+=rew ns = discretize(obs) Q[(s,a)] = (1 - alpha) * Q.get((s,a),0) + alpha * (rew + gamma * max(qvalues(ns))) cum_rewards.append(cum_reward) rewards.append(cum_reward) # == Periodically print results and calculate average reward == if epoch%5000==0: print(f"{epoch}: {np.average(cum_rewards)}, alpha={alpha}, epsilon={epsilon}") if np.average(cum_rewards) > Qmax: Qmax = np.average(cum_rewards) Qbest = Q cum_rewards=[]
Unachoweza kugundua kutoka kwa matokeo hayo:
-
Karibu na lengo letu. Tuko karibu sana na kufikia lengo la kupata tuzo ya 195 kwa jumla katika mfululizo wa majaribio 100+, au tunaweza kuwa tumelifanikisha! Hata kama tunapata namba ndogo, bado hatujui, kwa sababu tunachukua wastani wa majaribio 5000, na ni majaribio 100 tu yanahitajika katika vigezo rasmi.
-
Tuzo inaanza kushuka. Wakati mwingine tuzo inaanza kushuka, ambayo inamaanisha kuwa tunaweza "kuharibu" thamani zilizojifunza tayari kwenye Jedwali la Q na zile zinazofanya hali kuwa mbaya zaidi.
Uchunguzi huu unaonekana wazi zaidi ikiwa tutachora maendeleo ya mafunzo.
Kuchora Maendeleo ya Mafunzo
Wakati wa mafunzo, tumekusanya thamani ya tuzo ya jumla katika kila moja ya kurudia kwenye vector ya rewards. Hivi ndivyo inavyoonekana tunapochora dhidi ya namba ya kurudia:
plt.plot(rewards)
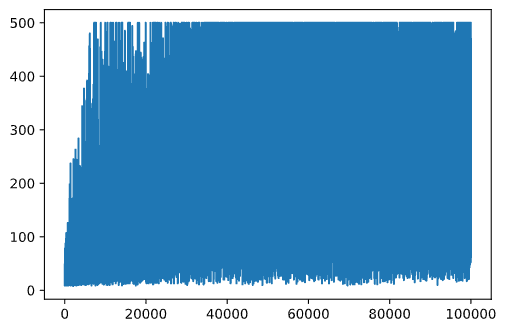
Kutoka kwenye grafu hii, haiwezekani kusema chochote, kwa sababu kutokana na asili ya mchakato wa mafunzo ya nasibu urefu wa vikao vya mafunzo hutofautiana sana. Ili kuelewa zaidi grafu hii, tunaweza kuhesabu wastani wa kukimbia juu ya mfululizo wa majaribio, tuseme 100. Hii inaweza kufanywa kwa urahisi kwa kutumia np.convolve: (msimbo wa block 12)
def running_average(x,window):
return np.convolve(x,np.ones(window)/window,mode='valid')
plt.plot(running_average(rewards,100))
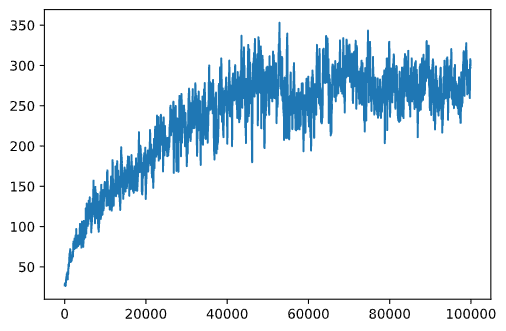
Kurekebisha vigezo vya msingi
Ili kufanya mafunzo kuwa thabiti zaidi, ina maana kurekebisha baadhi ya vigezo vyetu vya msingi wakati wa mafunzo. Hasa:
-
Kwa kiwango cha kujifunza,
alpha, we may start with values close to 1, and then keep decreasing the parameter. With time, we will be getting good probability values in the Q-Table, and thus we should be adjusting them slightly, and not overwriting completely with new values. -
Increase epsilon. We may want to increase the
epsilonslowly, in order to explore less and exploit more. It probably makes sense to start with lower value ofepsilon, na kuhamia karibu na 1.
Kazi 1: Cheza na thamani za vigezo vya msingi na uone kama unaweza kufikia tuzo ya juu zaidi. Je, unapata zaidi ya 195?
Kazi 2: Ili kutatua tatizo rasmi, unahitaji kupata tuzo ya wastani ya 195 katika majaribio 100 mfululizo. Pima hilo wakati wa mafunzo na hakikisha kuwa umetatua tatizo rasmi!
Kuona matokeo kwa vitendo
Itakuwa ya kuvutia kuona jinsi mfano uliyojifunza unavyofanya kazi. Wacha tuendeshe simulizi na kufuata mkakati wa kuchagua hatua kama wakati wa mafunzo, tukichagua kulingana na usambazaji wa uwezekano kwenye Jedwali la Q: (msimbo wa block 13)
obs = env.reset()
done = False
while not done:
s = discretize(obs)
env.render()
v = probs(np.array(qvalues(s)))
a = random.choices(actions,weights=v)[0]
obs,_,done,_ = env.step(a)
env.close()
Unapaswa kuona kitu kama hiki:

🚀Changamoto
Kazi 3: Hapa, tulikuwa tunatumia nakala ya mwisho ya Jedwali la Q, ambalo linaweza lisiwe bora zaidi. Kumbuka kuwa tumehifadhi Jedwali la Q linalofanya kazi bora zaidi kwenye
Qbestvariable! Try the same example with the best-performing Q-Table by copyingQbestover toQand see if you notice the difference.
Task 4: Here we were not selecting the best action on each step, but rather sampling with corresponding probability distribution. Would it make more sense to always select the best action, with the highest Q-Table value? This can be done by using
np.argmaxili kupata namba ya hatua inayohusiana na thamani ya juu zaidi ya Jedwali la Q. Tekeleza mkakati huu na uone kama unaboreshwa kusawazisha.
Jaribio la baada ya somo
Kazi
Hitimisho
Sasa tumejifunza jinsi ya kufundisha mawakala kufikia matokeo mazuri kwa kuwapa tuzo inayoelezea hali inayotakiwa ya mchezo, na kwa kuwapa fursa ya kuchunguza nafasi ya utafutaji kwa busara. Tumefanikiwa kutumia algorithimu ya Q-Learning katika hali za mazingira ya kidijitali na endelevu, lakini na hatua za kidijitali.
Ni muhimu pia kujifunza hali ambapo hatua ya hali pia ni endelevu, na wakati nafasi ya uchunguzi ni ngumu zaidi, kama picha kutoka skrini ya mchezo wa Atari. Katika matatizo hayo tunahitaji mara nyingi kutumia mbinu za kujifunza mashine zenye nguvu zaidi, kama vile mitandao ya neva, ili kufikia matokeo mazuri. Mada hizo za juu zaidi ni somo la kozi yetu ya AI ya juu zaidi inayokuja.
Kanusho: Hati hii imetafsiriwa kwa kutumia huduma za tafsiri za AI zinazotumia mashine. Ingawa tunajitahidi kwa usahihi, tafadhali fahamu kwamba tafsiri za kiotomatiki zinaweza kuwa na makosa au kutokuwa sahihi. Hati asili katika lugha yake ya asili inapaswa kuzingatiwa kama chanzo rasmi. Kwa habari muhimu, tafsiri ya kitaalamu ya kibinadamu inapendekezwa. Hatutawajibika kwa kutoelewana au tafsiri zisizo sahihi zinazotokana na matumizi ya tafsiri hii.