|
|
7 months ago | |
|---|---|---|
| .. | ||
| solution/Julia | 7 months ago | |
| README.md | 7 months ago | |
| assignment.md | 7 months ago | |
README.md
Agrupamento K-Means
Questionário pré-aula
Nesta lição, você aprenderá como criar clusters usando Scikit-learn e o conjunto de dados de música nigeriana que você importou anteriormente. Vamos abordar os fundamentos do K-Means para Agrupamento. Lembre-se de que, como você aprendeu na lição anterior, existem muitas maneiras de trabalhar com clusters e o método que você usa depende dos seus dados. Vamos experimentar o K-Means, pois é a técnica de agrupamento mais comum. Vamos começar!
Termos que você aprenderá sobre:
- Pontuação de Silhueta
- Método do cotovelo
- Inércia
- Variância
Introdução
Agrupamento K-Means é um método derivado do domínio do processamento de sinais. Ele é usado para dividir e particionar grupos de dados em 'k' clusters usando uma série de observações. Cada observação trabalha para agrupar um determinado ponto de dados mais próximo de sua 'média' mais próxima, ou o ponto central de um cluster.
Os clusters podem ser visualizados como diagramas de Voronoi, que incluem um ponto (ou 'semente') e sua região correspondente.

infográfico por Jen Looper
O processo de agrupamento K-Means executa-se em um processo de três etapas:
- O algoritmo seleciona k pontos centrais amostrando do conjunto de dados. Após isso, ele repete:
- Ele atribui cada amostra ao centróide mais próximo.
- Ele cria novos centróides tomando o valor médio de todas as amostras atribuídas aos centróides anteriores.
- Em seguida, ele calcula a diferença entre os novos e antigos centróides e repete até que os centróides se estabilizem.
Uma desvantagem de usar o K-Means é que você precisará estabelecer 'k', que é o número de centróides. Felizmente, o 'método do cotovelo' ajuda a estimar um bom valor inicial para 'k'. Você irá experimentá-lo em um minuto.
Pré-requisito
Você trabalhará no arquivo notebook.ipynb desta lição, que inclui a importação de dados e a limpeza preliminar que você fez na última lição.
Exercício - preparação
Comece dando mais uma olhada nos dados das músicas.
-
Crie um boxplot, chamando
boxplot()para cada coluna:plt.figure(figsize=(20,20), dpi=200) plt.subplot(4,3,1) sns.boxplot(x = 'popularity', data = df) plt.subplot(4,3,2) sns.boxplot(x = 'acousticness', data = df) plt.subplot(4,3,3) sns.boxplot(x = 'energy', data = df) plt.subplot(4,3,4) sns.boxplot(x = 'instrumentalness', data = df) plt.subplot(4,3,5) sns.boxplot(x = 'liveness', data = df) plt.subplot(4,3,6) sns.boxplot(x = 'loudness', data = df) plt.subplot(4,3,7) sns.boxplot(x = 'speechiness', data = df) plt.subplot(4,3,8) sns.boxplot(x = 'tempo', data = df) plt.subplot(4,3,9) sns.boxplot(x = 'time_signature', data = df) plt.subplot(4,3,10) sns.boxplot(x = 'danceability', data = df) plt.subplot(4,3,11) sns.boxplot(x = 'length', data = df) plt.subplot(4,3,12) sns.boxplot(x = 'release_date', data = df)Esses dados estão um pouco ruidosos: ao observar cada coluna como um boxplot, você pode ver os outliers.
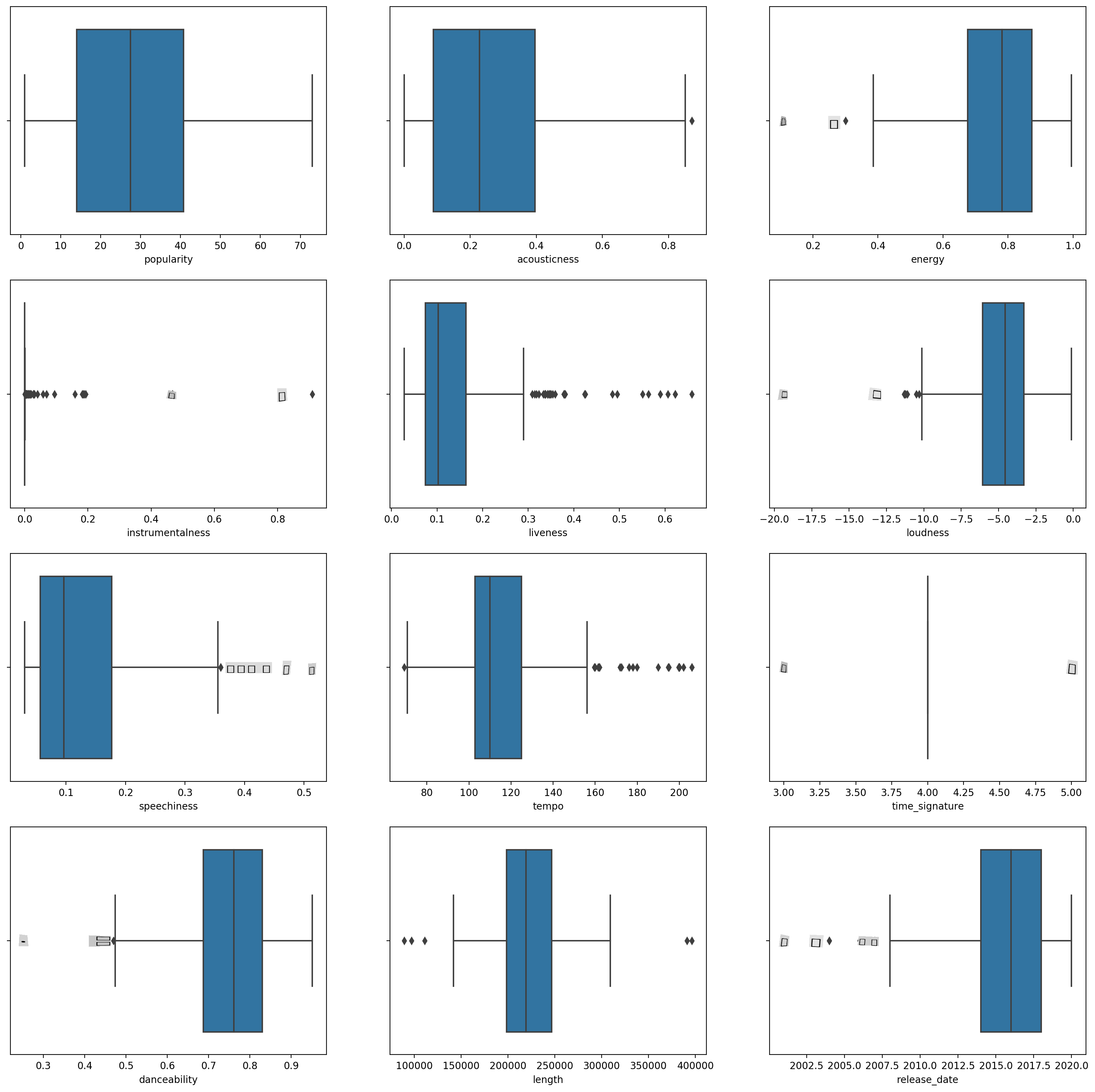
Você poderia percorrer o conjunto de dados e remover esses outliers, mas isso tornaria os dados bastante mínimos.
-
Por enquanto, escolha quais colunas você usará para seu exercício de agrupamento. Escolha aquelas com faixas semelhantes e codifique a coluna
artist_top_genrecomo dados numéricos:from sklearn.preprocessing import LabelEncoder le = LabelEncoder() X = df.loc[:, ('artist_top_genre','popularity','danceability','acousticness','loudness','energy')] y = df['artist_top_genre'] X['artist_top_genre'] = le.fit_transform(X['artist_top_genre']) y = le.transform(y) -
Agora você precisa decidir quantos clusters deseja atingir. Você sabe que existem 3 gêneros de música que extraímos do conjunto de dados, então vamos tentar 3:
from sklearn.cluster import KMeans nclusters = 3 seed = 0 km = KMeans(n_clusters=nclusters, random_state=seed) km.fit(X) # Predict the cluster for each data point y_cluster_kmeans = km.predict(X) y_cluster_kmeans
Você verá um array impresso com clusters previstos (0, 1 ou 2) para cada linha do dataframe.
-
Use esse array para calcular uma 'pontuação de silhueta':
from sklearn import metrics score = metrics.silhouette_score(X, y_cluster_kmeans) score
Pontuação de Silhueta
Busque uma pontuação de silhueta mais próxima de 1. Essa pontuação varia de -1 a 1, e se a pontuação for 1, o cluster é denso e bem separado de outros clusters. Um valor próximo de 0 representa clusters sobrepostos com amostras muito próximas da fronteira de decisão dos clusters vizinhos. (Fonte)
Nossa pontuação é .53, ou seja, bem no meio. Isso indica que nossos dados não estão particularmente bem ajustados a esse tipo de agrupamento, mas vamos continuar.
Exercício - construir um modelo
-
Importe
KMeanse inicie o processo de agrupamento.from sklearn.cluster import KMeans wcss = [] for i in range(1, 11): kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42) kmeans.fit(X) wcss.append(kmeans.inertia_)Existem algumas partes aqui que merecem explicação.
🎓 range: Estas são as iterações do processo de agrupamento
🎓 random_state: "Determina a geração de números aleatórios para a inicialização do centróide." Fonte
🎓 WCSS: "somas de quadrados dentro do cluster" mede a distância média quadrada de todos os pontos dentro de um cluster em relação ao centróide do cluster. Fonte.
🎓 Inércia: Os algoritmos K-Means tentam escolher centróides para minimizar a 'inércia', "uma medida de quão internamente coerentes são os clusters." Fonte. O valor é anexado à variável wcss em cada iteração.
🎓 k-means++: No Scikit-learn você pode usar a otimização 'k-means++', que "inicializa os centróides para serem (geralmente) distantes uns dos outros, levando a resultados provavelmente melhores do que a inicialização aleatória."
Método do cotovelo
Anteriormente, você deduziu que, como você segmentou 3 gêneros de música, deveria escolher 3 clusters. Mas será que é isso mesmo?
-
Use o 'método do cotovelo' para ter certeza.
plt.figure(figsize=(10,5)) sns.lineplot(x=range(1, 11), y=wcss, marker='o', color='red') plt.title('Elbow') plt.xlabel('Number of clusters') plt.ylabel('WCSS') plt.show()Use a variável
wcssque você construiu na etapa anterior para criar um gráfico mostrando onde está a 'curva' no cotovelo, que indica o número ótimo de clusters. Talvez sejam 3!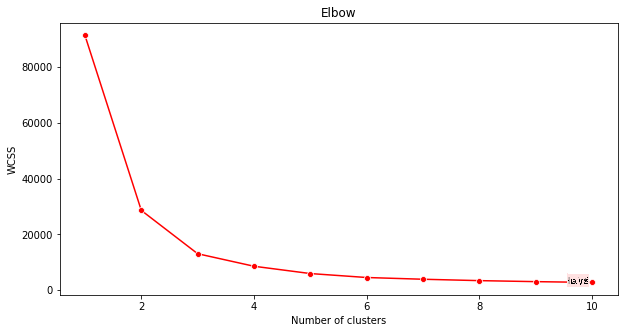
Exercício - exibir os clusters
-
Tente o processo novamente, desta vez definindo três clusters, e exiba os clusters como um gráfico de dispersão:
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters = 3) kmeans.fit(X) labels = kmeans.predict(X) plt.scatter(df['popularity'],df['danceability'],c = labels) plt.xlabel('popularity') plt.ylabel('danceability') plt.show() -
Verifique a precisão do modelo:
labels = kmeans.labels_ correct_labels = sum(y == labels) print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size)) print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))A precisão deste modelo não é muito boa, e a forma dos clusters dá uma dica do porquê.

Esses dados estão muito desbalanceados, com pouca correlação e há muita variância entre os valores das colunas para agrupar bem. De fato, os clusters que se formam provavelmente são fortemente influenciados ou distorcidos pelas três categorias de gênero que definimos acima. Isso foi um processo de aprendizado!
Na documentação do Scikit-learn, você pode ver que um modelo como este, com clusters não muito bem demarcados, tem um problema de 'variância':
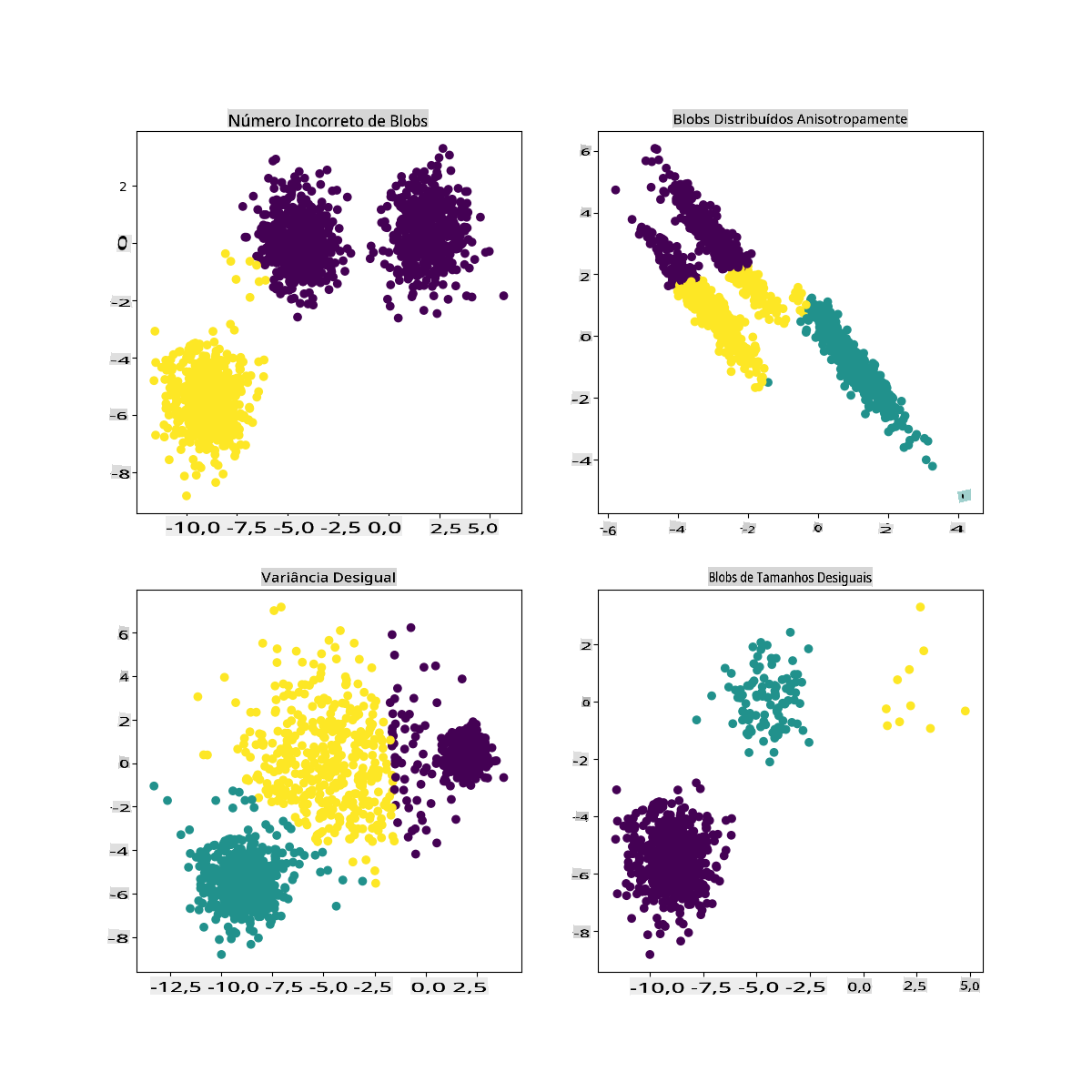
Infográfico do Scikit-learn
Variância
A variância é definida como "a média das diferenças quadradas em relação à Média" (Fonte). No contexto deste problema de agrupamento, refere-se a dados cujos números do nosso conjunto de dados tendem a divergir um pouco demais da média.
✅ Este é um ótimo momento para pensar em todas as maneiras que você poderia corrigir esse problema. Ajustar os dados um pouco mais? Usar colunas diferentes? Usar um algoritmo diferente? Dica: Tente normalizar seus dados e testar outras colunas.
Tente esta 'calculadora de variância' para entender melhor o conceito.
🚀Desafio
Passe algum tempo com este notebook, ajustando parâmetros. Você consegue melhorar a precisão do modelo limpando mais os dados (removendo outliers, por exemplo)? Você pode usar pesos para dar mais peso a amostras de dados específicas. O que mais você pode fazer para criar melhores clusters?
Dica: Tente normalizar seus dados. Há um código comentado no notebook que adiciona normalização padrão para que as colunas de dados se assemelhem mais em termos de faixa. Você descobrirá que, enquanto a pontuação de silhueta diminui, a 'curva' no gráfico do cotovelo se suaviza. Isso acontece porque deixar os dados não normalizados permite que dados com menos variância tenham mais peso. Leia um pouco mais sobre esse problema aqui.
Questionário pós-aula
Revisão & Autoestudo
Dê uma olhada em um Simulador K-Means como este. Você pode usar esta ferramenta para visualizar pontos de dados amostrais e determinar seus centróides. Você pode editar a aleatoriedade dos dados, o número de clusters e o número de centróides. Isso ajuda você a ter uma ideia de como os dados podem ser agrupados?
Além disso, dê uma olhada neste material sobre K-Means da Stanford.
Tarefa
Tente diferentes métodos de agrupamento
Isenção de responsabilidade:
Este documento foi traduzido utilizando serviços de tradução automática baseados em IA. Embora nos esforcemos pela precisão, esteja ciente de que traduções automatizadas podem conter erros ou imprecisões. O documento original em sua língua nativa deve ser considerado a fonte autoritativa. Para informações críticas, recomenda-se a tradução profissional por um humano. Não nos responsabilizamos por quaisquer mal-entendidos ou interpretações errôneas decorrentes do uso desta tradução.