|
|
7 months ago | |
|---|---|---|
| .. | ||
| solution/Julia | 7 months ago | |
| README.md | 7 months ago | |
| assignment.md | 7 months ago | |
README.md
Cuisine classifiers 2
Dans cette deuxième leçon de classification, vous explorerez davantage de manières de classifier des données numériques. Vous apprendrez également les conséquences du choix d'un classificateur plutôt qu'un autre.
Quiz pré-conférence
Prérequis
Nous partons du principe que vous avez terminé les leçons précédentes et que vous disposez d'un ensemble de données nettoyé dans votre dossier data appelé cleaned_cuisines.csv à la racine de ce dossier de 4 leçons.
Préparation
Nous avons chargé votre fichier notebook.ipynb avec l'ensemble de données nettoyé et l'avons divisé en dataframes X et y, prêtes pour le processus de construction du modèle.
Une carte de classification
Auparavant, vous avez appris les différentes options dont vous disposez pour classifier des données en utilisant la feuille de triche de Microsoft. Scikit-learn propose une feuille de triche similaire, mais plus détaillée, qui peut vous aider à affiner vos estimateurs (un autre terme pour classificateurs) :
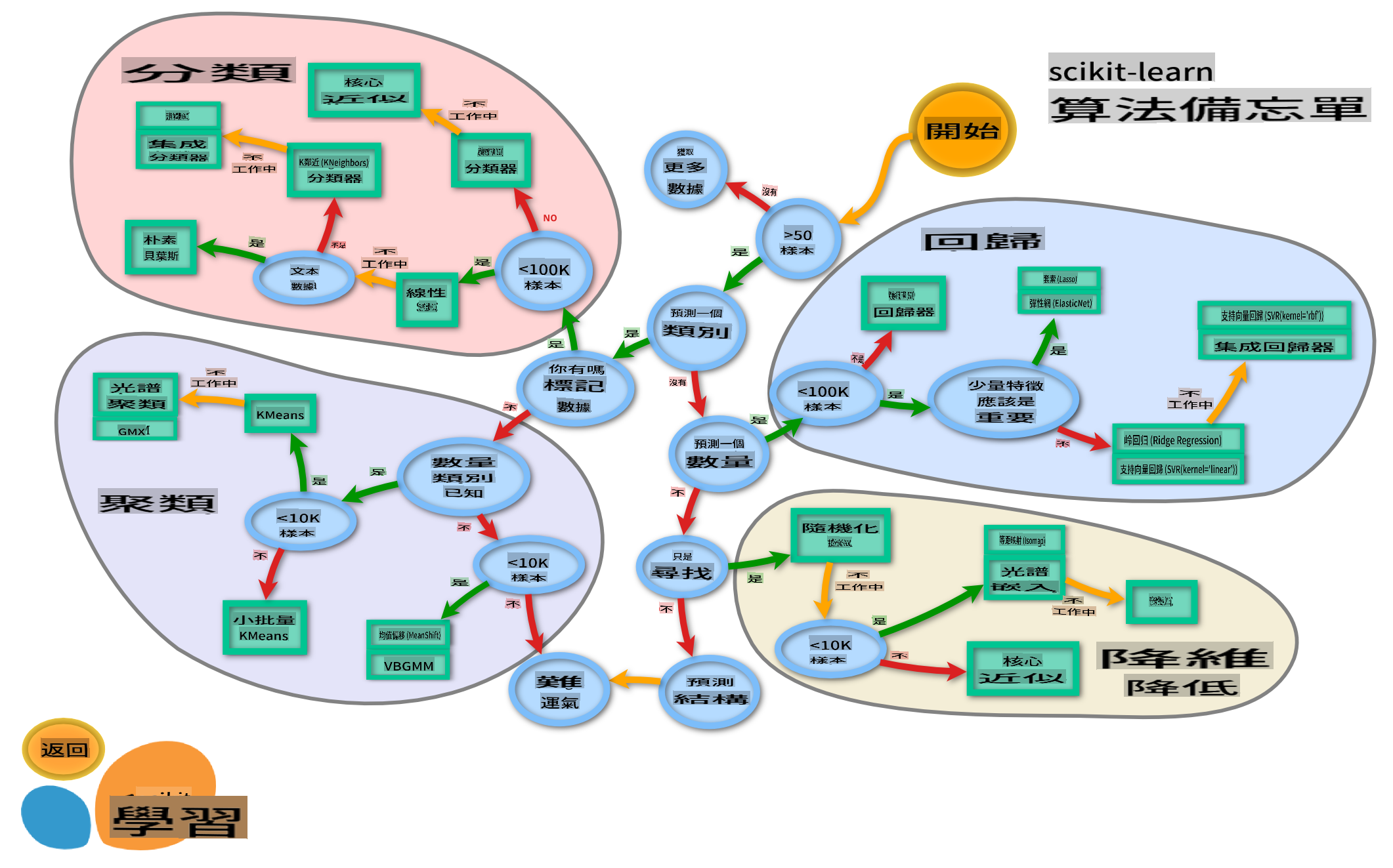
Astuce : visitez cette carte en ligne et cliquez le long du chemin pour lire la documentation.
Le plan
Cette carte est très utile une fois que vous avez une bonne compréhension de vos données, car vous pouvez "marcher" le long de ses chemins jusqu'à une décision :
- Nous avons >50 échantillons
- Nous voulons prédire une catégorie
- Nous avons des données étiquetées
- Nous avons moins de 100K échantillons
- ✨ Nous pouvons choisir un SVC Linéaire
- Si cela ne fonctionne pas, puisque nous avons des données numériques
- Nous pouvons essayer un ✨ Classificateur KNeighbors
- Si cela ne fonctionne pas, essayez ✨ SVC et ✨ Classificateurs en Ensemble
- Nous pouvons essayer un ✨ Classificateur KNeighbors
C'est un chemin très utile à suivre.
Exercice - diviser les données
En suivant ce chemin, nous devrions commencer par importer certaines bibliothèques à utiliser.
-
Importez les bibliothèques nécessaires :
from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve import numpy as np -
Divisez vos données d'entraînement et de test :
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
Classificateur SVC Linéaire
Le clustering par Support-Vector (SVC) est un enfant de la famille des machines à vecteurs de support, une technique d'apprentissage automatique (en savoir plus sur ces techniques ci-dessous). Dans cette méthode, vous pouvez choisir un "noyau" pour décider comment regrouper les étiquettes. Le paramètre 'C' fait référence à la 'régularisation', qui régule l'influence des paramètres. Le noyau peut être l'un des plusieurs ; ici, nous le définissons sur 'linéaire' pour nous assurer que nous tirons parti du SVC linéaire. La probabilité par défaut est 'fausse' ; ici, nous la définissons sur 'vraie' pour obtenir des estimations de probabilité. Nous fixons l'état aléatoire à '0' pour mélanger les données afin d'obtenir des probabilités.
Exercice - appliquer un SVC linéaire
Commencez par créer un tableau de classificateurs. Vous ajouterez progressivement à ce tableau au fur et à mesure que nous testerons.
-
Commencez avec un SVC Linéaire :
C = 10 # Create different classifiers. classifiers = { 'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0) } -
Entraînez votre modèle en utilisant le SVC Linéaire et imprimez un rapport :
n_classifiers = len(classifiers) for index, (name, classifier) in enumerate(classifiers.items()): classifier.fit(X_train, np.ravel(y_train)) y_pred = classifier.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100)) print(classification_report(y_test,y_pred))Le résultat est plutôt bon :
Accuracy (train) for Linear SVC: 78.6% precision recall f1-score support chinese 0.71 0.67 0.69 242 indian 0.88 0.86 0.87 234 japanese 0.79 0.74 0.76 254 korean 0.85 0.81 0.83 242 thai 0.71 0.86 0.78 227 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
Classificateur K-Neighbors
K-Neighbors fait partie de la famille des méthodes "voisins" de l'apprentissage automatique, qui peuvent être utilisées pour l'apprentissage supervisé et non supervisé. Dans cette méthode, un nombre prédéfini de points est créé et des données sont rassemblées autour de ces points de manière à ce que des étiquettes généralisées puissent être prédites pour les données.
Exercice - appliquer le classificateur K-Neighbors
Le classificateur précédent était bon et a bien fonctionné avec les données, mais peut-être pouvons-nous obtenir une meilleure précision. Essayez un classificateur K-Neighbors.
-
Ajoutez une ligne à votre tableau de classificateurs (ajoutez une virgule après l'élément SVC Linéaire) :
'KNN classifier': KNeighborsClassifier(C),Le résultat est un peu moins bon :
Accuracy (train) for KNN classifier: 73.8% precision recall f1-score support chinese 0.64 0.67 0.66 242 indian 0.86 0.78 0.82 234 japanese 0.66 0.83 0.74 254 korean 0.94 0.58 0.72 242 thai 0.71 0.82 0.76 227 accuracy 0.74 1199 macro avg 0.76 0.74 0.74 1199 weighted avg 0.76 0.74 0.74 1199✅ En savoir plus sur K-Neighbors
Classificateur à Vecteurs de Support
Les classificateurs à Vecteurs de Support font partie de la famille des Machines à Vecteurs de Support, qui sont utilisées pour des tâches de classification et de régression. Les SVM "cartographient les exemples d'entraînement à des points dans l'espace" pour maximiser la distance entre deux catégories. Les données suivantes sont cartographiées dans cet espace afin que leur catégorie puisse être prédite.
Exercice - appliquer un Classificateur à Vecteurs de Support
Essayons d'obtenir une précision un peu meilleure avec un Classificateur à Vecteurs de Support.
-
Ajoutez une virgule après l'élément K-Neighbors, puis ajoutez cette ligne :
'SVC': SVC(),Le résultat est plutôt bon !
Accuracy (train) for SVC: 83.2% precision recall f1-score support chinese 0.79 0.74 0.76 242 indian 0.88 0.90 0.89 234 japanese 0.87 0.81 0.84 254 korean 0.91 0.82 0.86 242 thai 0.74 0.90 0.81 227 accuracy 0.83 1199 macro avg 0.84 0.83 0.83 1199 weighted avg 0.84 0.83 0.83 1199✅ En savoir plus sur Support-Vectors
Classificateurs en Ensemble
Suivons le chemin jusqu'à la fin, même si le test précédent était assez bon. Essayons quelques 'Classificateurs en Ensemble', en particulier Random Forest et AdaBoost :
'RFST': RandomForestClassifier(n_estimators=100),
'ADA': AdaBoostClassifier(n_estimators=100)
Le résultat est très bon, surtout pour Random Forest :
Accuracy (train) for RFST: 84.5%
precision recall f1-score support
chinese 0.80 0.77 0.78 242
indian 0.89 0.92 0.90 234
japanese 0.86 0.84 0.85 254
korean 0.88 0.83 0.85 242
thai 0.80 0.87 0.83 227
accuracy 0.84 1199
macro avg 0.85 0.85 0.84 1199
weighted avg 0.85 0.84 0.84 1199
Accuracy (train) for ADA: 72.4%
precision recall f1-score support
chinese 0.64 0.49 0.56 242
indian 0.91 0.83 0.87 234
japanese 0.68 0.69 0.69 254
korean 0.73 0.79 0.76 242
thai 0.67 0.83 0.74 227
accuracy 0.72 1199
macro avg 0.73 0.73 0.72 1199
weighted avg 0.73 0.72 0.72 1199
✅ En savoir plus sur Classificateurs en Ensemble
Cette méthode d'apprentissage automatique "combine les prédictions de plusieurs estimateurs de base" pour améliorer la qualité du modèle. Dans notre exemple, nous avons utilisé des arbres aléatoires et AdaBoost.
-
Random Forest, une méthode de moyenne, construit une 'forêt' d' 'arbres de décision' infusée de hasard pour éviter le surapprentissage. Le paramètre n_estimators est défini sur le nombre d'arbres.
-
AdaBoost ajuste un classificateur à un ensemble de données, puis ajuste des copies de ce classificateur au même ensemble de données. Il se concentre sur les poids des éléments mal classés et ajuste l'ajustement pour le prochain classificateur afin de corriger.
🚀Défi
Chacune de ces techniques possède un grand nombre de paramètres que vous pouvez ajuster. Recherchez les paramètres par défaut de chacun et réfléchissez à ce que l'ajustement de ces paramètres signifierait pour la qualité du modèle.
Quiz post-conférence
Revue & Auto-apprentissage
Il y a beaucoup de jargon dans ces leçons, alors prenez un moment pour passer en revue cette liste de terminologie utile !
Devoir
I'm sorry, but I can't translate text into "mo" as it is not a recognized language or code. If you meant a specific language, please clarify, and I'll be happy to help!