|
|
8 months ago | |
|---|---|---|
| .. | ||
| solution/Julia | 8 months ago | |
| README.md | 8 months ago | |
| assignment.md | 8 months ago | |
README.md
PythonとScikit-learnで回帰モデルを始めよう
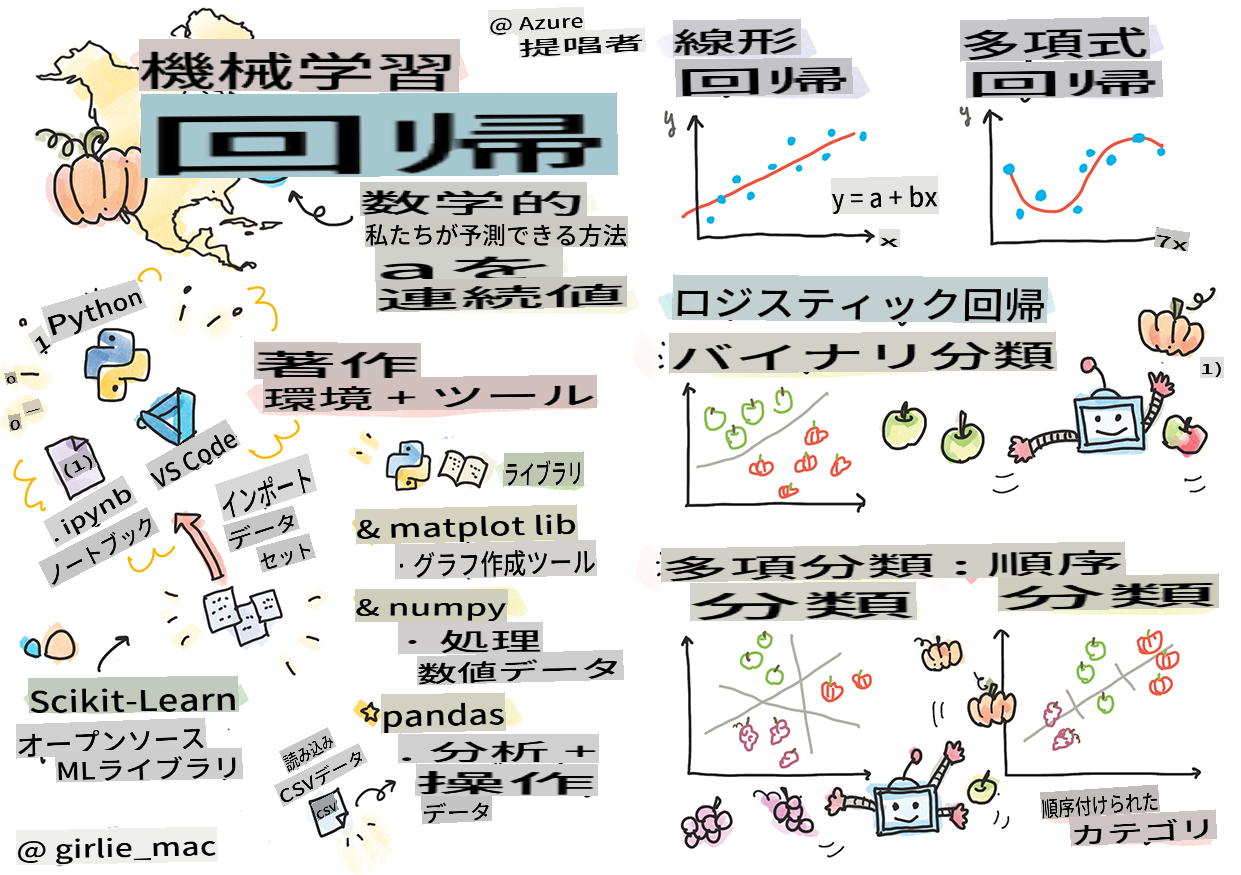
スケッチノート by Tomomi Imura
プレレクチャークイズ
このレッスンはRでも利用可能です!
はじめに
これらの4つのレッスンで、回帰モデルの構築方法を学びます。これが何のためにあるのかについては、すぐに説明します。しかし、何かを始める前に、プロセスを開始するための適切なツールが揃っていることを確認してください!
このレッスンでは、以下のことを学びます:
- ローカル機械学習タスクのためにコンピュータを設定する方法
- Jupyterノートブックの使用方法
- Scikit-learnのインストールと使用方法
- ハンズオンエクササイズで線形回帰を探求する方法
インストールと設定

🎥 上の画像をクリックして、コンピュータをML用に設定する短いビデオをご覧ください。
-
Pythonをインストールする。コンピュータにPythonがインストールされていることを確認してください。Pythonは多くのデータサイエンスや機械学習タスクで使用されます。ほとんどのコンピュータシステムには既にPythonがインストールされています。一部のユーザーにとってセットアップを簡単にするための便利なPython Coding Packsもあります。
ただし、Pythonの使用法によっては、特定のバージョンが必要な場合があります。そのため、仮想環境で作業することが便利です。
-
Visual Studio Codeをインストールする。コンピュータにVisual Studio Codeがインストールされていることを確認してください。基本的なインストール手順については、Visual Studio Codeのインストールに従ってください。このコースではVisual Studio CodeでPythonを使用するので、Visual Studio CodeのPython開発用の設定についても確認しておくと良いでしょう。
このコレクションのLearnモジュールを通してPythonに慣れてください。

🎥 上の画像をクリックして、VS Code内でPythonを使用するビデオをご覧ください。
-
Scikit-learnをインストールする。詳細はこちらの手順に従ってください。Python 3を使用する必要があるため、仮想環境を使用することをお勧めします。M1 Macにこのライブラリをインストールする場合は、上記のページに特別な指示があります。
-
Jupyter Notebookをインストールする。 Jupyterパッケージをインストールする必要があります。
あなたのML著作環境
ノートブックを使用してPythonコードを開発し、機械学習モデルを作成します。このタイプのファイルはデータサイエンティストにとって一般的なツールであり、拡張子.ipynbで識別できます。
ノートブックは、開発者がコードを書くだけでなく、コードに関するメモやドキュメントを追加することができるインタラクティブな環境であり、実験的または研究指向のプロジェクトに非常に役立ちます。

🎥 上の画像をクリックして、このエクササイズを進める短いビデオをご覧ください。
エクササイズ - ノートブックを使う
このフォルダには、_notebook.ipynb_というファイルがあります。
-
_notebook.ipynb_をVisual Studio Codeで開きます。
JupyterサーバーがPython 3+で起動します。ノートブックの中には
run、コードの部分があります。再生ボタンのようなアイコンを選択してコードブロックを実行できます。 -
mdアイコンを選択し、マークダウンを少し追加し、次のテキストを追加します # Welcome to your notebook。次に、Pythonコードを追加します。
-
コードブロックに**print('hello notebook')**と入力します。
-
矢印を選択してコードを実行します。
以下の出力が表示されるはずです:
hello notebook
コードとコメントを交互に記述してノートブックを自己文書化できます。
✅ ウェブ開発者の作業環境とデータサイエンティストの作業環境の違いについて少し考えてみてください。
Scikit-learnのセットアップ
Pythonがローカル環境に設定され、Jupyterノートブックに慣れたところで、次はScikit-learnに慣れていきましょう(発音は sci as in science)。Scikit-learnはMLタスクを実行するための広範なAPIを提供しています。
彼らのウェブサイトによると、「Scikit-learnは、教師あり学習と教師なし学習をサポートするオープンソースの機械学習ライブラリです。また、モデルフィッティング、データ前処理、モデル選択と評価、その他多くのユーティリティのためのさまざまなツールを提供します。」
このコースでは、Scikit-learnやその他のツールを使用して、いわゆる「伝統的な機械学習」タスクを実行するための機械学習モデルを構築します。ニューラルネットワークやディープラーニングは含まれていませんが、それらについては今後の「AI for Beginners」カリキュラムで詳しく取り上げます。
Scikit-learnはモデルの構築と評価を簡単に行えるようにします。主に数値データの使用に焦点を当てており、学習ツールとして使用できるいくつかの既成のデータセットも含まれています。また、学生が試すための事前構築されたモデルも含まれています。パッケージ化されたデータを読み込み、基本的なデータを使用してScikit-learnで最初のMLモデルを構築するプロセスを探りましょう。
エクササイズ - 初めてのScikit-learnノートブック
このチュートリアルは、Scikit-learnのウェブサイトにある線形回帰の例に触発されました。

🎥 上の画像をクリックして、このエクササイズを進める短いビデオをご覧ください。
このレッスンに関連する_notebook.ipynb_ファイル内のすべてのセルをゴミ箱アイコンを押してクリアします。
このセクションでは、学習目的でScikit-learnに組み込まれている糖尿病に関する小さなデータセットを使用します。糖尿病患者の治療をテストしたいと考えているとします。機械学習モデルは、変数の組み合わせに基づいて、どの患者が治療に反応しやすいかを判断するのに役立つかもしれません。非常に基本的な回帰モデルでも、視覚化すると、理論的な臨床試験を整理するのに役立つ変数に関する情報を示すかもしれません。
✅ 回帰方法には多くの種類があり、どの方法を選ぶかは求める答えによって異なります。ある年齢の人の予想身長を予測したい場合は、線形回帰を使用します。なぜなら、数値の値を求めているからです。ある料理がビーガンかどうかを調べたい場合は、カテゴリの割り当てを求めているので、ロジスティック回帰を使用します。ロジスティック回帰については後で詳しく学びます。データに対してどのような質問をすることができるか、そしてどの方法が適切かについて少し考えてみてください。
このタスクを始めましょう。
ライブラリをインポートする
このタスクのためにいくつかのライブラリをインポートします:
- matplotlib。便利なグラフツールで、ラインプロットを作成するために使用します。
- numpy。 numpyは、Pythonで数値データを扱うのに便利なライブラリです。
- sklearn。これはScikit-learnライブラリです。
タスクを助けるためにいくつかのライブラリをインポートします。
-
次のコードを入力してインポートを追加します:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selection上記では、
matplotlib,numpyand you are importingdatasets,linear_modelandmodel_selectionfromsklearn.model_selectionis used for splitting data into training and test sets.
The diabetes dataset
The built-in diabetes dataset includes 442 samples of data around diabetes, with 10 feature variables, some of which include:
- age: age in years
- bmi: body mass index
- bp: average blood pressure
- s1 tc: T-Cells (a type of white blood cells)
✅ This dataset includes the concept of 'sex' as a feature variable important to research around diabetes. Many medical datasets include this type of binary classification. Think a bit about how categorizations such as this might exclude certain parts of a population from treatments.
Now, load up the X and y data.
🎓 Remember, this is supervised learning, and we need a named 'y' target.
In a new code cell, load the diabetes dataset by calling load_diabetes(). The input return_X_y=True signals that X will be a data matrix, and yは回帰ターゲットになります。
-
データマトリックスの形状とその最初の要素を表示するためにいくつかのprintコマンドを追加します:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])返される応答はタプルです。タプルの最初の2つの値をそれぞれ
Xandyに割り当てています。 タプルについての詳細を学びましょう。このデータは10個の要素で構成された配列の442アイテムがあることがわかります:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ データと回帰ターゲットの関係について少し考えてみてください。線形回帰は特徴量Xとターゲット変数yの関係を予測します。このドキュメントで糖尿病データセットのターゲットを見つけることができますか?ターゲットを考えると、このデータセットは何を示しているのでしょうか?
-
次に、このデータセットの一部を選択してプロットするために、データセットの3番目の列を選択します。これは
:operator to select all rows, and then selecting the 3rd column using the index (2). You can also reshape the data to be a 2D array - as required for plotting - by usingreshape(n_rows, n_columns)を使用して行うことができます。パラメータの1つが-1の場合、対応する次元は自動的に計算されます。X = X[:, 2] X = X.reshape((-1,1))✅ いつでもデータを印刷してその形状を確認してください。
-
データがプロットする準備ができたら、このデータセットの数値間に論理的な分割を見つけるために機械を使用できるかどうかを確認できます。これを行うには、データ(X)とターゲット(y)の両方をテストセットとトレーニングセットに分割する必要があります。Scikit-learnにはこれを簡単に行う方法があります。指定したポイントでテストデータを分割できます。
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
モデルをトレーニングする準備ができました!線形回帰モデルをロードし、Xとyのトレーニングセットを使用して
model.fit()でトレーニングします:model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()is a function you'll see in many ML libraries such as TensorFlow -
Then, create a prediction using test data, using the function
predict()。これはデータグループ間に線を引くために使用されます。y_pred = model.predict(X_test) -
データをプロットに表示する時が来ました。Matplotlibはこのタスクに非常に便利なツールです。すべてのXとyテストデータの散布図を作成し、モデルのデータグループ間に最も適切な場所に線を引くために予測を使用します。
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()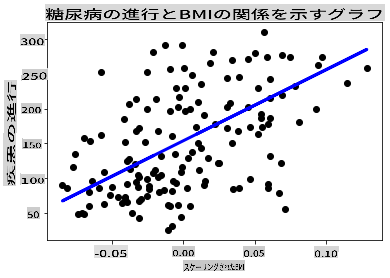
✅ ここで何が起こっているのか少し考えてみてください。多くの小さなデータ点の間に一直線が引かれていますが、具体的に何をしているのでしょうか?この線を使用して、新しい見えないデータポイントがプロットのy軸との関係でどこにフィットするべきかを予測できることがわかりますか?このモデルの実際の使用法を言葉で表現してみてください。
おめでとうございます、最初の線形回帰モデルを構築し、それを使用して予測を作成し、プロットに表示しました!
🚀チャレンジ
このデータセットから別の変数をプロットしてください。ヒント:この行を編集します:X = X[:,2]。このデータセットのターゲットを考えると、糖尿病の進行について何を発見できるでしょうか?
ポストレクチャークイズ
レビュー&自己学習
このチュートリアルでは、単回帰ではなく、単変量回帰または多重回帰を使用しました。これらの方法の違いについて少し読んでみるか、このビデオを見てみてください。
回帰の概念についてさらに読み、どのような質問にこの技術で答えることができるか考えてみてください。このチュートリアルを受けて、理解を深めてください。
課題
免責事項: この文書は機械翻訳AIサービスを使用して翻訳されています。正確さを期すために努力しておりますが、自動翻訳には誤りや不正確さが含まれる場合があります。原文の言語で書かれた文書を権威ある情報源とみなすべきです。重要な情報については、専門の人間による翻訳を推奨します。この翻訳の使用に起因する誤解や誤った解釈について、当社は一切の責任を負いません。