|
|
8 months ago | |
|---|---|---|
| .. | ||
| solution | 8 months ago | |
| README.md | 8 months ago | |
| assignment.md | 8 months ago | |
README.md
Utangulizi wa Kujifunza kwa Kuimarisha na Q-Learning
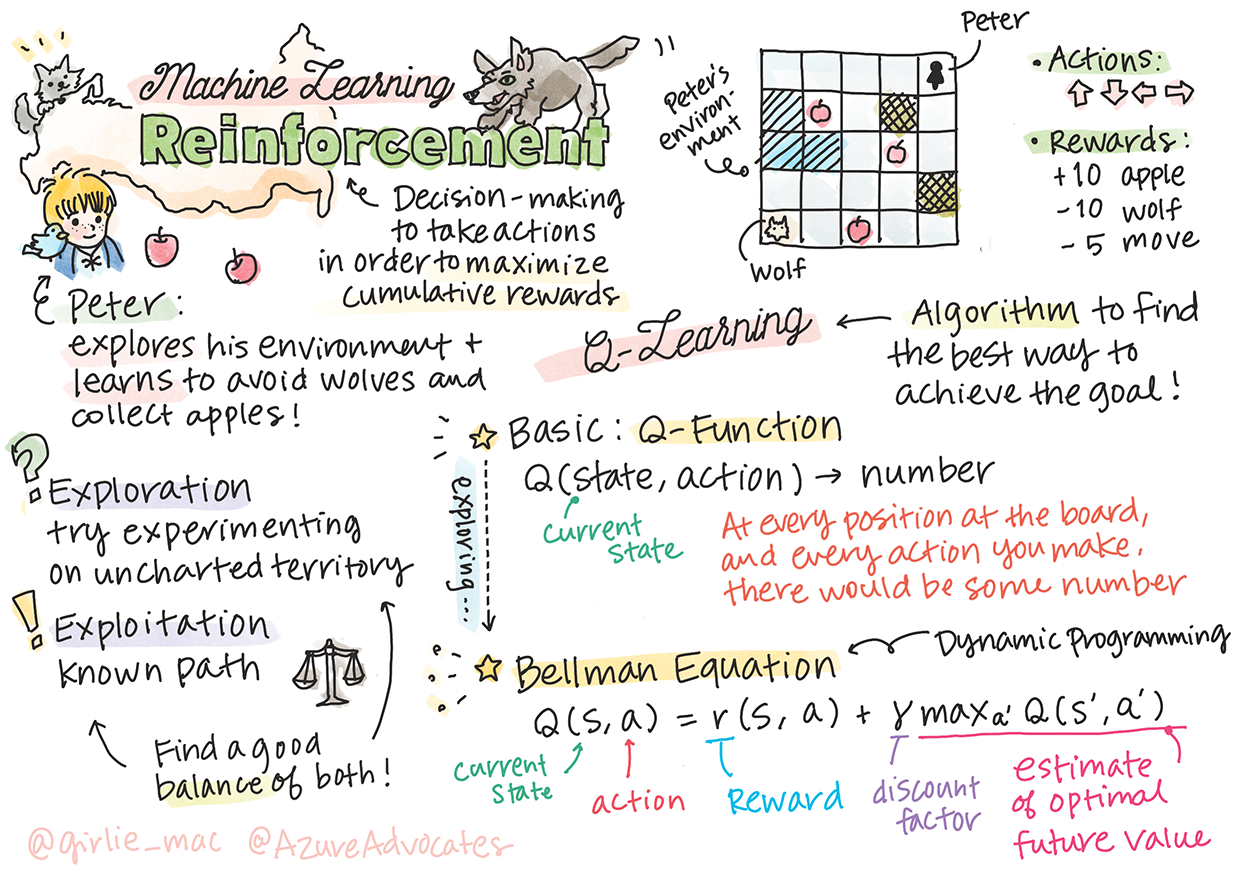
Sketchnote na Tomomi Imura
Kujifunza kwa kuimarisha kunahusisha dhana tatu muhimu: wakala, baadhi ya hali, na seti ya vitendo kwa kila hali. Kwa kutekeleza kitendo katika hali maalum, wakala hupewa tuzo. Fikiria tena mchezo wa kompyuta wa Super Mario. Wewe ni Mario, uko kwenye kiwango cha mchezo, umesimama karibu na ukingo wa mwamba. Juu yako kuna sarafu. Wewe ukiwa Mario, katika kiwango cha mchezo, katika nafasi maalum ... hiyo ndiyo hali yako. Kusonga hatua moja kulia (kitendo) kutakupeleka kwenye ukingo, na hiyo itakupa alama ndogo ya nambari. Hata hivyo, kubonyeza kitufe cha kuruka kutakupa alama na utabaki hai. Hiyo ni matokeo chanya na hiyo inapaswa kukupa alama chanya ya nambari.
Kwa kutumia kujifunza kwa kuimarisha na simulator (mchezo), unaweza kujifunza jinsi ya kucheza mchezo ili kuongeza tuzo ambayo ni kubaki hai na kupata alama nyingi iwezekanavyo.

🎥 Bofya picha hapo juu kumsikiliza Dmitry akijadili Kujifunza kwa Kuimarisha
Jaribio la kabla ya somo
Mahitaji na Mipangilio
Katika somo hili, tutakuwa tukijaribu na baadhi ya nambari katika Python. Unapaswa kuwa na uwezo wa kuendesha nambari ya Jupyter Notebook kutoka somo hili, ama kwenye kompyuta yako au mahali pengine kwenye wingu.
Unaweza kufungua notebook ya somo na kupitia somo hili kujenga.
Kumbuka: Ikiwa unafungua nambari hii kutoka kwenye wingu, pia unahitaji kupata faili la
rlboard.py, ambalo linatumika katika nambari ya notebook. Ongeza kwenye saraka moja na notebook.
Utangulizi
Katika somo hili, tutachunguza ulimwengu wa Peter na Mbwa Mwitu, uliohamasishwa na hadithi ya muziki ya Kirusi, Sergei Prokofiev. Tutatumia Kujifunza kwa Kuimarisha kumruhusu Peter kuchunguza mazingira yake, kukusanya matofaa matamu na kuepuka kukutana na mbwa mwitu.
Kujifunza kwa Kuimarisha (RL) ni mbinu ya kujifunza inayoturuhusu kujifunza tabia bora ya wakala katika mazingira fulani kwa kuendesha majaribio mengi. Wakala katika mazingira haya anapaswa kuwa na lengo, lililofafanuliwa na kazi ya tuzo.
Mazingira
Kwa urahisi, tuchukulie ulimwengu wa Peter kuwa ubao wa mraba wa ukubwa width x height, kama hivi:
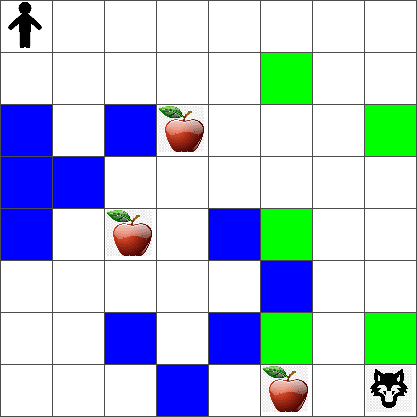
Kila seli katika ubao huu inaweza kuwa:
- ardhi, ambayo Peter na viumbe wengine wanaweza kutembea.
- maji, ambayo huwezi kutembea.
- mti au nyasi, mahali ambapo unaweza kupumzika.
- tofaa, ambalo linawakilisha kitu ambacho Peter angefurahi kukipata ili kujilisha.
- mbwa mwitu, ambaye ni hatari na anapaswa kuepukwa.
Kuna moduli ya Python tofauti, rlboard.py, ambayo ina nambari ya kufanya kazi na mazingira haya. Kwa sababu nambari hii si muhimu kwa kuelewa dhana zetu, tutaleta moduli na kuitumia kuunda ubao wa mfano (code block 1):
from rlboard import *
width, height = 8,8
m = Board(width,height)
m.randomize(seed=13)
m.plot()
Nambari hii inapaswa kuchapisha picha ya mazingira inayofanana na ile hapo juu.
Vitendo na sera
Katika mfano wetu, lengo la Peter litakuwa kupata tofaa, huku akiepuka mbwa mwitu na vikwazo vingine. Ili kufanya hivyo, anaweza kutembea tu hadi apate tofaa.
Kwa hivyo, katika nafasi yoyote, anaweza kuchagua kati ya moja ya vitendo vifuatavyo: juu, chini, kushoto na kulia.
Tutafafanua vitendo hivyo kama kamusi, na kuziunganisha na jozi za mabadiliko ya kuratibu yanayolingana. Kwa mfano, kusonga kulia (R) would correspond to a pair (1,0). (code block 2):
actions = { "U" : (0,-1), "D" : (0,1), "L" : (-1,0), "R" : (1,0) }
action_idx = { a : i for i,a in enumerate(actions.keys()) }
Kwa muhtasari, mkakati na lengo la hali hii ni kama ifuatavyo:
-
Mkakati, wa wakala wetu (Peter) unafafanuliwa na kinachoitwa sera. Sera ni kazi inayorejesha kitendo katika hali yoyote iliyotolewa. Katika kesi yetu, hali ya tatizo inawakilishwa na ubao, ikijumuisha nafasi ya sasa ya mchezaji.
-
Lengo, la kujifunza kwa kuimarisha ni hatimaye kujifunza sera nzuri ambayo itaturuhusu kutatua tatizo kwa ufanisi. Hata hivyo, kama msingi, tuchukulie sera rahisi zaidi inayoitwa kutembea kwa nasibu.
Kutembea kwa nasibu
Kwanza, tutatue tatizo letu kwa kutekeleza mkakati wa kutembea kwa nasibu. Kwa kutembea kwa nasibu, tutachagua kwa nasibu kitendo kinachofuata kutoka kwa vitendo vilivyoruhusiwa, hadi tufikie tofaa (code block 3).
-
Tekeleza kutembea kwa nasibu na nambari hapa chini:
def random_policy(m): return random.choice(list(actions)) def walk(m,policy,start_position=None): n = 0 # number of steps # set initial position if start_position: m.human = start_position else: m.random_start() while True: if m.at() == Board.Cell.apple: return n # success! if m.at() in [Board.Cell.wolf, Board.Cell.water]: return -1 # eaten by wolf or drowned while True: a = actions[policy(m)] new_pos = m.move_pos(m.human,a) if m.is_valid(new_pos) and m.at(new_pos)!=Board.Cell.water: m.move(a) # do the actual move break n+=1 walk(m,random_policy)Wito kwa
walkunapaswa kurejesha urefu wa njia inayolingana, ambayo inaweza kutofautiana kutoka kwa kukimbia moja hadi nyingine. -
Endesha jaribio la kutembea mara kadhaa (sema, 100), na uchapishe takwimu zinazotokana (code block 4):
def print_statistics(policy): s,w,n = 0,0,0 for _ in range(100): z = walk(m,policy) if z<0: w+=1 else: s += z n += 1 print(f"Average path length = {s/n}, eaten by wolf: {w} times") print_statistics(random_policy)Kumbuka kuwa urefu wa wastani wa njia ni karibu hatua 30-40, ambayo ni nyingi, ikizingatiwa kuwa umbali wa wastani hadi tofaa lililo karibu ni karibu hatua 5-6.
Unaweza pia kuona jinsi harakati za Peter zinavyoonekana wakati wa kutembea kwa nasibu:
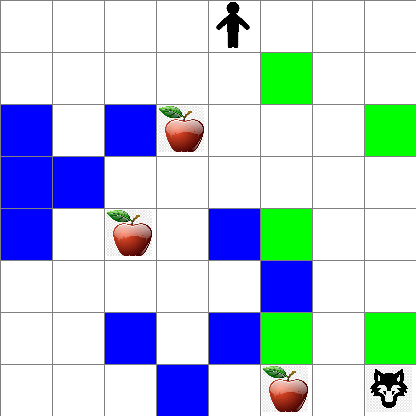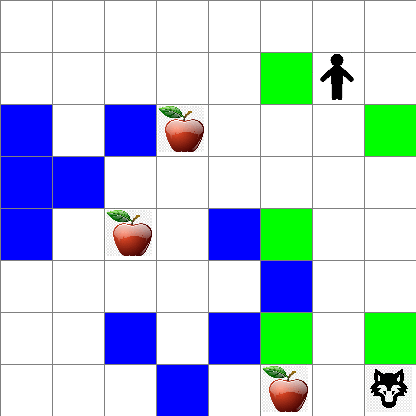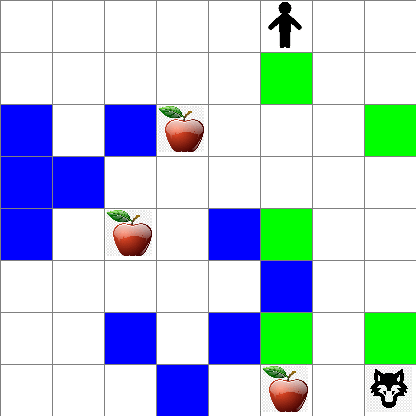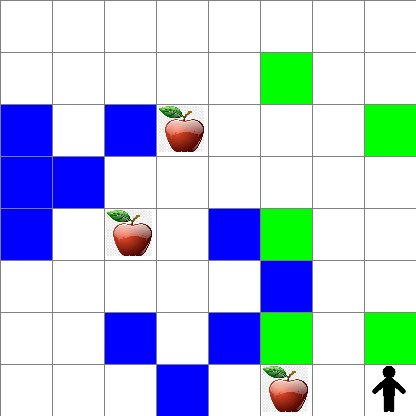
Kazi ya tuzo
Ili kufanya sera yetu kuwa ya akili zaidi, tunahitaji kuelewa ni hatua gani ni "bora" kuliko nyingine. Ili kufanya hivyo, tunahitaji kufafanua lengo letu.
Lengo linaweza kufafanuliwa kwa maneno ya kazi ya tuzo, ambayo itarejesha thamani fulani ya alama kwa kila hali. Nambari inavyokuwa juu, ndivyo kazi ya tuzo inavyokuwa bora. (code block 5)
move_reward = -0.1
goal_reward = 10
end_reward = -10
def reward(m,pos=None):
pos = pos or m.human
if not m.is_valid(pos):
return end_reward
x = m.at(pos)
if x==Board.Cell.water or x == Board.Cell.wolf:
return end_reward
if x==Board.Cell.apple:
return goal_reward
return move_reward
Jambo la kuvutia kuhusu kazi za tuzo ni kwamba katika hali nyingi, tunapewa tuzo kubwa mwishoni mwa mchezo. Hii inamaanisha kuwa algoriti yetu inapaswa kwa namna fulani kukumbuka hatua "nzuri" zinazoongoza kwenye tuzo chanya mwishoni, na kuongeza umuhimu wake. Vivyo hivyo, hatua zote zinazoongoza kwenye matokeo mabaya zinapaswa kukatishwa tamaa.
Q-Learning
Algoriti ambayo tutajadili hapa inaitwa Q-Learning. Katika algoriti hii, sera inafafanuliwa na kazi (au muundo wa data) unaoitwa Q-Table. Inaandika "uzuri" wa kila kitendo katika hali iliyotolewa.
Inaitwa Q-Table kwa sababu mara nyingi ni rahisi kuiwakilisha kama meza, au safu nyingi. Kwa kuwa ubao wetu una vipimo vya width x height, tunaweza kuwakilisha Q-Table kwa kutumia safu ya numpy yenye umbo width x height x len(actions): (code block 6)
Q = np.ones((width,height,len(actions)),dtype=np.float)*1.0/len(actions)
Kumbuka kwamba tunaanzisha maadili yote ya Q-Table na thamani sawa, katika kesi yetu - 0.25. Hii inalingana na sera ya "kutembea kwa nasibu", kwa sababu hatua zote katika kila hali ni nzuri sawa. Tunaweza kupitisha Q-Table kwa plot function in order to visualize the table on the board: m.plot(Q).

In the center of each cell there is an "arrow" that indicates the preferred direction of movement. Since all directions are equal, a dot is displayed.
Now we need to run the simulation, explore our environment, and learn a better distribution of Q-Table values, which will allow us to find the path to the apple much faster.
Essence of Q-Learning: Bellman Equation
Once we start moving, each action will have a corresponding reward, i.e. we can theoretically select the next action based on the highest immediate reward. However, in most states, the move will not achieve our goal of reaching the apple, and thus we cannot immediately decide which direction is better.
Remember that it is not the immediate result that matters, but rather the final result, which we will obtain at the end of the simulation.
In order to account for this delayed reward, we need to use the principles of dynamic programming, which allow us to think about out problem recursively.
Suppose we are now at the state s, and we want to move to the next state s'. By doing so, we will receive the immediate reward r(s,a), defined by the reward function, plus some future reward. If we suppose that our Q-Table correctly reflects the "attractiveness" of each action, then at state s' we will chose an action a that corresponds to maximum value of Q(s',a'). Thus, the best possible future reward we could get at state s will be defined as maxa'Q(s',a') (maximum here is computed over all possible actions a' at state s').
This gives the Bellman formula for calculating the value of the Q-Table at state s, given action a:

Here γ is the so-called discount factor that determines to which extent you should prefer the current reward over the future reward and vice versa.
Learning Algorithm
Given the equation above, we can now write pseudo-code for our learning algorithm:
- Initialize Q-Table Q with equal numbers for all states and actions
- Set learning rate α ← 1
- Repeat simulation many times
- Start at random position
- Repeat
- Select an action a at state s
- Execute action by moving to a new state s'
- If we encounter end-of-game condition, or total reward is too small - exit simulation
- Compute reward r at the new state
- Update Q-Function according to Bellman equation: Q(s,a) ← (1-α)Q(s,a)+α(r+γ maxa'Q(s',a'))
- s ← s'
- Update the total reward and decrease α.
Exploit vs. explore
In the algorithm above, we did not specify how exactly we should choose an action at step 2.1. If we are choosing the action randomly, we will randomly explore the environment, and we are quite likely to die often as well as explore areas where we would not normally go. An alternative approach would be to exploit the Q-Table values that we already know, and thus to choose the best action (with higher Q-Table value) at state s. This, however, will prevent us from exploring other states, and it's likely we might not find the optimal solution.
Thus, the best approach is to strike a balance between exploration and exploitation. This can be done by choosing the action at state s with probabilities proportional to values in the Q-Table. In the beginning, when Q-Table values are all the same, it would correspond to a random selection, but as we learn more about our environment, we would be more likely to follow the optimal route while allowing the agent to choose the unexplored path once in a while.
Python implementation
We are now ready to implement the learning algorithm. Before we do that, we also need some function that will convert arbitrary numbers in the Q-Table into a vector of probabilities for corresponding actions.
-
Create a function
probs():def probs(v,eps=1e-4): v = v-v.min()+eps v = v/v.sum() return vTunaongeza
epschache kwenye vector ya awali ili kuepuka mgawanyiko kwa 0 katika kesi ya awali, wakati vipengele vyote vya vector ni sawa.
Endesha algoriti ya kujifunza kupitia majaribio 5000, pia huitwa epochs: (code block 8)
for epoch in range(5000):
# Pick initial point
m.random_start()
# Start travelling
n=0
cum_reward = 0
while True:
x,y = m.human
v = probs(Q[x,y])
a = random.choices(list(actions),weights=v)[0]
dpos = actions[a]
m.move(dpos,check_correctness=False) # we allow player to move outside the board, which terminates episode
r = reward(m)
cum_reward += r
if r==end_reward or cum_reward < -1000:
lpath.append(n)
break
alpha = np.exp(-n / 10e5)
gamma = 0.5
ai = action_idx[a]
Q[x,y,ai] = (1 - alpha) * Q[x,y,ai] + alpha * (r + gamma * Q[x+dpos[0], y+dpos[1]].max())
n+=1
Baada ya kutekeleza algoriti hii, Q-Table inapaswa kusasishwa na maadili ambayo yanafafanua mvuto wa hatua tofauti katika kila hatua. Tunaweza kujaribu kuonyesha Q-Table kwa kuchora vector kwenye kila seli ambayo itaelekeza kwenye mwelekeo unaotakiwa wa harakati. Kwa urahisi, tunachora duara ndogo badala ya kichwa cha mshale.
Kuangalia sera
Kwa kuwa Q-Table inaorodhesha "mvuto" wa kila kitendo katika kila hali, ni rahisi kuitumia kufafanua urambazaji bora katika ulimwengu wetu. Katika kesi rahisi zaidi, tunaweza kuchagua kitendo kinacholingana na thamani ya juu zaidi ya Q-Table: (code block 9)
def qpolicy_strict(m):
x,y = m.human
v = probs(Q[x,y])
a = list(actions)[np.argmax(v)]
return a
walk(m,qpolicy_strict)
Ukijaribu nambari hapo juu mara kadhaa, unaweza kugundua kuwa wakati mwingine inagoma, na unahitaji kubonyeza kitufe cha STOP kwenye notebook ili kuikomesha. Hii inatokea kwa sababu kunaweza kuwa na hali ambapo hali mbili "zinaelekeza" kwa kila mmoja kwa thamani bora ya Q, ambapo wakala huishia kusonga kati ya hali hizo bila kikomo.
🚀Changamoto
Kazi 1: Badilisha
walkfunction to limit the maximum length of path by a certain number of steps (say, 100), and watch the code above return this value from time to time.
Task 2: Modify the
walkfunction so that it does not go back to the places where it has already been previously. This will preventwalkfrom looping, however, the agent can still end up being "trapped" in a location from which it is unable to escape.
Navigation
A better navigation policy would be the one that we used during training, which combines exploitation and exploration. In this policy, we will select each action with a certain probability, proportional to the values in the Q-Table. This strategy may still result in the agent returning back to a position it has already explored, but, as you can see from the code below, it results in a very short average path to the desired location (remember that print_statistics inaendesha simulizi mara 100): (code block 10)
def qpolicy(m):
x,y = m.human
v = probs(Q[x,y])
a = random.choices(list(actions),weights=v)[0]
return a
print_statistics(qpolicy)
Baada ya kuendesha nambari hii, unapaswa kupata urefu wa wastani wa njia ndogo sana kuliko hapo awali, katika safu ya hatua 3-6.
Kuchunguza mchakato wa kujifunza
Kama tulivyosema, mchakato wa kujifunza ni usawa kati ya uchunguzi na uchunguzi wa maarifa yaliyopatikana kuhusu muundo wa nafasi ya tatizo. Tumeona kwamba matokeo ya kujifunza (uwezo wa kusaidia wakala kupata njia fupi kwenda kwenye lengo) yameboreshwa, lakini pia ni ya kuvutia kuona jinsi urefu wa wastani wa njia unavyobadilika wakati wa mchakato wa kujifunza:
Muhtasari wa Kujifunza
-
Urefu wa wastani wa njia unaongezeka. Tunachokiona hapa ni kwamba mwanzoni, urefu wa wastani wa njia unaongezeka. Hii inaweza kuwa kutokana na ukweli kwamba tunapojua chochote kuhusu mazingira, tunatarajiwa kukwama katika hali mbaya, maji au mbwa mwitu. Tunapojifunza zaidi na kuanza kutumia maarifa haya, tunaweza kuchunguza mazingira kwa muda mrefu zaidi, lakini bado hatujui vizuri mahali tofaa yalipo.
-
Urefu wa njia unapungua, tunapojifunza zaidi. Mara tu tunapojifunza vya kutosha, inakuwa rahisi kwa wakala kufikia lengo, na urefu wa njia unaanza kupungua. Hata hivyo, bado tuko wazi kwa uchunguzi, kwa hivyo mara nyingi tunatoka kwenye njia bora, na kuchunguza chaguzi mpya, na kufanya njia kuwa ndefu kuliko ilivyo bora.
-
Urefu unaongezeka ghafla. Tunachokiona pia kwenye grafu hii ni kwamba wakati fulani, urefu uliongezeka ghafla. Hii inaonyesha asili ya mchakato wa stochastic, na kwamba tunaweza wakati fulani "kuharibu" coefficients za Q-Table kwa kuandika tena na maadili mapya. Hii inapaswa kupunguzwa kwa kupunguza kiwango cha kujifunza (kwa mfano, kuelekea mwisho wa mafunzo, tunarekebisha maadili ya Q-Table kwa thamani ndogo).
Kwa ujumla, ni muhimu kukumbuka kwamba mafanikio na ubora wa mchakato wa kujifunza hutegemea sana vigezo, kama vile kiwango cha kujifunza, kupungua kwa kiwango cha kujifunza, na sababu ya punguzo. Hizi mara nyingi huitwa vigezo vya hyper, ili kuwatofautisha na vigezo, ambavyo tunaboresha wakati wa mafunzo (kwa mfano, coefficients za Q-Table). Mchakato wa kupata maadili bora ya vigezo vya hyper unaitwa uboresha wa vigezo vya hyper, na unastahili mada tofauti.
Jaribio la baada ya somo
Kazi
Kanusho: Hati hii imetafsiriwa kwa kutumia huduma za tafsiri za AI zinazotegemea mashine. Ingawa tunajitahidi kwa usahihi, tafadhali fahamu kuwa tafsiri za kiotomatiki zinaweza kuwa na makosa au kutokuwepo kwa usahihi. Hati asilia katika lugha yake ya awali inapaswa kuchukuliwa kama chanzo chenye mamlaka. Kwa habari muhimu, tafsiri ya kitaalamu ya binadamu inapendekezwa. Hatutawajibika kwa kutoelewana au tafsiri zisizo sahihi zinazotokana na matumizi ya tafsiri hii.