|
|
8 months ago | |
|---|---|---|
| .. | ||
| README.md | 8 months ago | |
| assignment.md | 8 months ago | |
README.md
サポートベクター回帰を用いた時系列予測
前回のレッスンでは、ARIMAモデルを使用して時系列予測を行う方法を学びました。今回は、連続データを予測するために使用される回帰モデルであるサポートベクター回帰モデルについて見ていきます。
事前クイズ
はじめに
このレッスンでは、回帰のためのSVM: Support Vector Machine、つまりSVR: サポートベクター回帰を用いてモデルを構築する具体的な方法を学びます。
時系列におけるSVRの役割 1
時系列予測におけるSVRの重要性を理解する前に、知っておくべき重要な概念をいくつか紹介します:
- 回帰: 与えられた入力セットから連続値を予測するための教師あり学習技術です。アイデアは、特徴空間内の最大数のデータポイントを持つ曲線(または直線)にフィットさせることです。詳細はこちらをクリックしてください。
- サポートベクターマシン (SVM): 分類、回帰、および外れ値検出のために使用される教師あり機械学習モデルの一種です。モデルは特徴空間内の超平面であり、分類の場合は境界として機能し、回帰の場合は最適なフィットラインとして機能します。SVMでは、カーネル関数を使用してデータセットをより高次元の空間に変換し、容易に分離可能にすることが一般的です。SVMの詳細はこちらをクリックしてください。
- サポートベクター回帰 (SVR): SVMの一種で、最大数のデータポイントを持つ最適なフィットライン(SVMの場合は超平面)を見つけるためのものです。
なぜSVRを使うのか? 1
前回のレッスンでは、時系列データを予測するための非常に成功した統計的線形方法であるARIMAについて学びました。しかし、多くの場合、時系列データには線形モデルではマッピングできない非線形性が含まれています。このような場合、回帰タスクにおいてデータの非線形性を考慮できるSVMの能力が、時系列予測においてSVRを成功させる理由となります。
演習 - SVRモデルの構築
データ準備の最初のステップは、前回のARIMAのレッスンと同じです。
このレッスンの/workingフォルダーを開き、notebook.ipynbファイルを見つけてください。2
-
ノートブックを実行し、必要なライブラリをインポートします: 2
import sys sys.path.append('../../')import os import warnings import matplotlib.pyplot as plt import numpy as np import pandas as pd import datetime as dt import math from sklearn.svm import SVR from sklearn.preprocessing import MinMaxScaler from common.utils import load_data, mape -
/data/energy.csvファイルからデータをPandasデータフレームに読み込み、確認します: 2energy = load_data('../../data')[['load']] -
2012年1月から2014年12月までの利用可能なすべてのエネルギーデータをプロットします: 2
energy.plot(y='load', subplots=True, figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()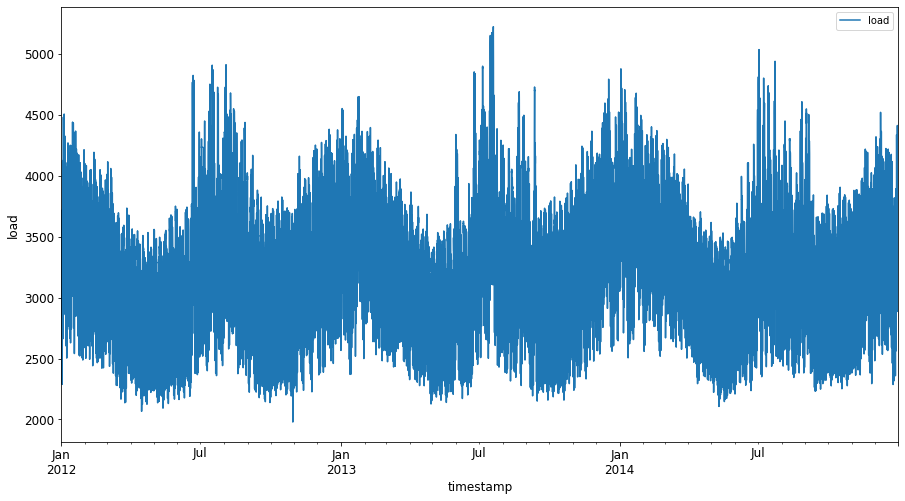
それでは、SVRモデルを構築しましょう。
トレーニングデータとテストデータの作成
データが読み込まれたので、トレーニングセットとテストセットに分割します。その後、SVRに必要なタイムステップベースのデータセットを作成するためにデータを再形成します。モデルはトレーニングセットでトレーニングされます。トレーニングが終了した後、トレーニングセット、テストセット、そして全データセットでその精度を評価し、全体的なパフォーマンスを確認します。テストセットがトレーニングセットより後の期間をカバーするようにして、モデルが将来の時間から情報を得ないようにする必要があります2(これは過剰適合と呼ばれる状況です)。
-
トレーニングセットには2014年9月1日から10月31日までの2ヶ月間を割り当てます。テストセットには2014年11月1日から12月31日までの2ヶ月間が含まれます: 2
train_start_dt = '2014-11-01 00:00:00' test_start_dt = '2014-12-30 00:00:00' -
違いを視覚化します: 2
energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)][['load']].rename(columns={'load':'train'}) \ .join(energy[test_start_dt:][['load']].rename(columns={'load':'test'}), how='outer') \ .plot(y=['train', 'test'], figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()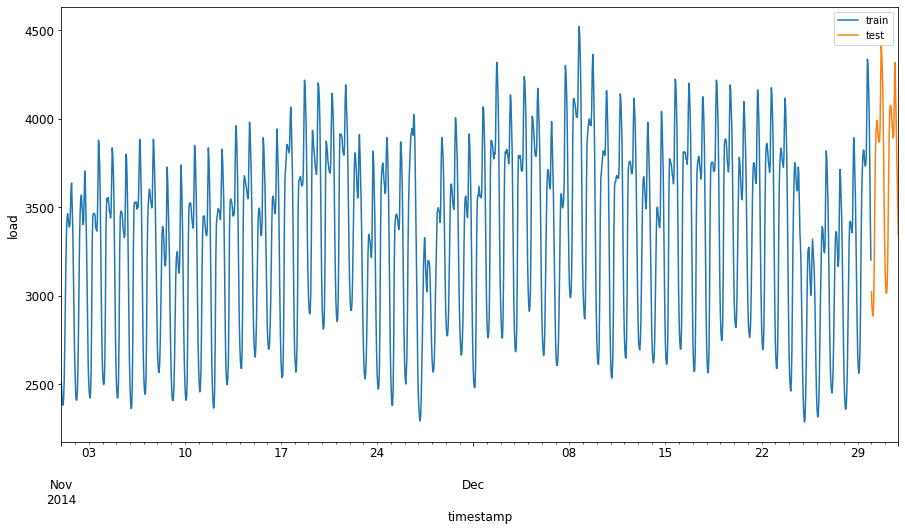
トレーニング用データの準備
次に、データをフィルタリングおよびスケーリングしてトレーニング用に準備する必要があります。必要な期間と列のみを含むようにデータセットをフィルタリングし、データが0から1の範囲に投影されるようにスケーリングします。
-
元のデータセットをフィルタリングして、前述の期間ごとのセットと、必要な列「load」と日付のみを含むようにします: 2
train = energy.copy()[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']] test = energy.copy()[energy.index >= test_start_dt][['load']] print('Training data shape: ', train.shape) print('Test data shape: ', test.shape)Training data shape: (1416, 1) Test data shape: (48, 1) -
トレーニングデータを(0, 1)の範囲にスケーリングします: 2
scaler = MinMaxScaler() train['load'] = scaler.fit_transform(train) -
次に、テストデータをスケーリングします: 2
test['load'] = scaler.transform(test)
タイムステップを持つデータの作成 1
SVRのために、入力データを[batch, timesteps]. So, you reshape the existing train_data and test_dataの形式に変換します。新しい次元がタイムステップを参照するようになります。
# Converting to numpy arrays
train_data = train.values
test_data = test.values
この例では、timesteps = 5とします。つまり、モデルへの入力は最初の4つのタイムステップのデータであり、出力は5番目のタイムステップのデータとなります。
timesteps=5
ネストされたリスト内包表記を使用してトレーニングデータを2Dテンソルに変換します:
train_data_timesteps=np.array([[j for j in train_data[i:i+timesteps]] for i in range(0,len(train_data)-timesteps+1)])[:,:,0]
train_data_timesteps.shape
(1412, 5)
テストデータを2Dテンソルに変換します:
test_data_timesteps=np.array([[j for j in test_data[i:i+timesteps]] for i in range(0,len(test_data)-timesteps+1)])[:,:,0]
test_data_timesteps.shape
(44, 5)
トレーニングデータとテストデータから入力と出力を選択します:
x_train, y_train = train_data_timesteps[:,:timesteps-1],train_data_timesteps[:,[timesteps-1]]
x_test, y_test = test_data_timesteps[:,:timesteps-1],test_data_timesteps[:,[timesteps-1]]
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
(1412, 4) (1412, 1)
(44, 4) (44, 1)
SVRの実装 1
それでは、SVRを実装する時が来ました。この実装について詳しく知りたい場合は、このドキュメントを参照してください。私たちの実装では、以下のステップに従います:
SVR()を呼び出してモデルを定義し、fit()and passing in the model hyperparameters: kernel, gamma, c and epsilon- Prepare the model for the training data by calling the
predict()関数を使用します。
次に、SVRモデルを作成します。ここではRBFカーネルを使用し、ハイパーパラメータgamma、C、およびepsilonをそれぞれ0.5、10、および0.05に設定します。
model = SVR(kernel='rbf',gamma=0.5, C=10, epsilon = 0.05)
トレーニングデータにモデルを適合させる 1
model.fit(x_train, y_train[:,0])
SVR(C=10, cache_size=200, coef0=0.0, degree=3, epsilon=0.05, gamma=0.5,
kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
モデル予測を行う 1
y_train_pred = model.predict(x_train).reshape(-1,1)
y_test_pred = model.predict(x_test).reshape(-1,1)
print(y_train_pred.shape, y_test_pred.shape)
(1412, 1) (44, 1)
SVRを構築しました!次に、それを評価する必要があります。
モデルの評価 1
評価のために、まずデータを元のスケールに戻します。次に、パフォーマンスを確認するために、元の時系列プロットと予測された時系列プロットをプロットし、MAPE結果も出力します。
予測された出力と元の出力をスケールバックします:
# Scaling the predictions
y_train_pred = scaler.inverse_transform(y_train_pred)
y_test_pred = scaler.inverse_transform(y_test_pred)
print(len(y_train_pred), len(y_test_pred))
# Scaling the original values
y_train = scaler.inverse_transform(y_train)
y_test = scaler.inverse_transform(y_test)
print(len(y_train), len(y_test))
トレーニングデータとテストデータでモデルのパフォーマンスを確認する 1
データセットからタイムスタンプを抽出し、プロットのx軸に表示します。最初のtimesteps-1値を最初の出力の入力として使用しているため、出力のタイムスタンプはその後に開始します。
train_timestamps = energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)].index[timesteps-1:]
test_timestamps = energy[test_start_dt:].index[timesteps-1:]
print(len(train_timestamps), len(test_timestamps))
1412 44
トレーニングデータの予測をプロットします:
plt.figure(figsize=(25,6))
plt.plot(train_timestamps, y_train, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(train_timestamps, y_train_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.title("Training data prediction")
plt.show()
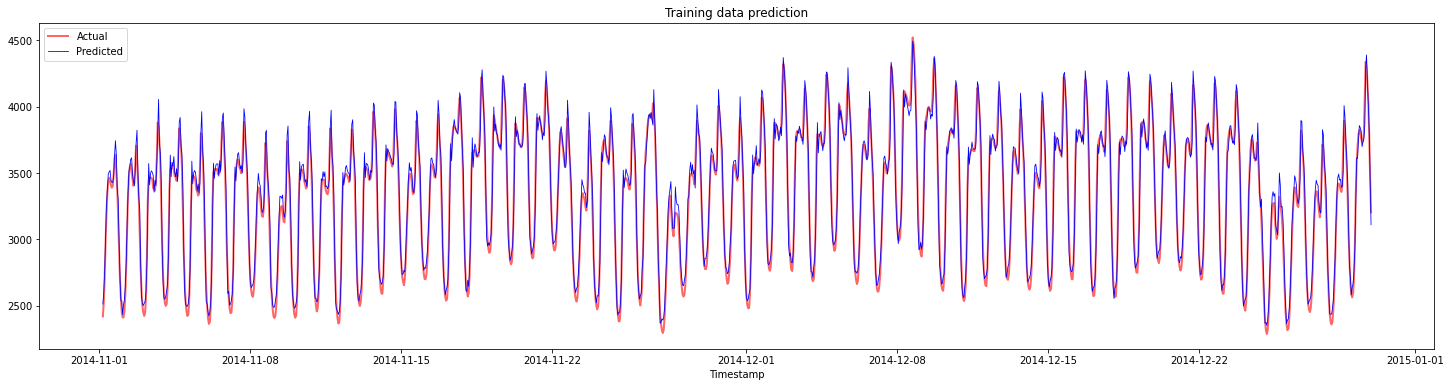
トレーニングデータのMAPEを出力します
print('MAPE for training data: ', mape(y_train_pred, y_train)*100, '%')
MAPE for training data: 1.7195710200875551 %
テストデータの予測をプロットします
plt.figure(figsize=(10,3))
plt.plot(test_timestamps, y_test, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(test_timestamps, y_test_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.show()
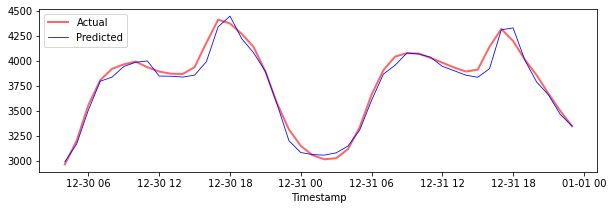
テストデータのMAPEを出力します
print('MAPE for testing data: ', mape(y_test_pred, y_test)*100, '%')
MAPE for testing data: 1.2623790187854018 %
🏆 テストデータセットで非常に良い結果を得ました!
全データセットでモデルのパフォーマンスを確認する 1
# Extracting load values as numpy array
data = energy.copy().values
# Scaling
data = scaler.transform(data)
# Transforming to 2D tensor as per model input requirement
data_timesteps=np.array([[j for j in data[i:i+timesteps]] for i in range(0,len(data)-timesteps+1)])[:,:,0]
print("Tensor shape: ", data_timesteps.shape)
# Selecting inputs and outputs from data
X, Y = data_timesteps[:,:timesteps-1],data_timesteps[:,[timesteps-1]]
print("X shape: ", X.shape,"\nY shape: ", Y.shape)
Tensor shape: (26300, 5)
X shape: (26300, 4)
Y shape: (26300, 1)
# Make model predictions
Y_pred = model.predict(X).reshape(-1,1)
# Inverse scale and reshape
Y_pred = scaler.inverse_transform(Y_pred)
Y = scaler.inverse_transform(Y)
plt.figure(figsize=(30,8))
plt.plot(Y, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(Y_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.show()
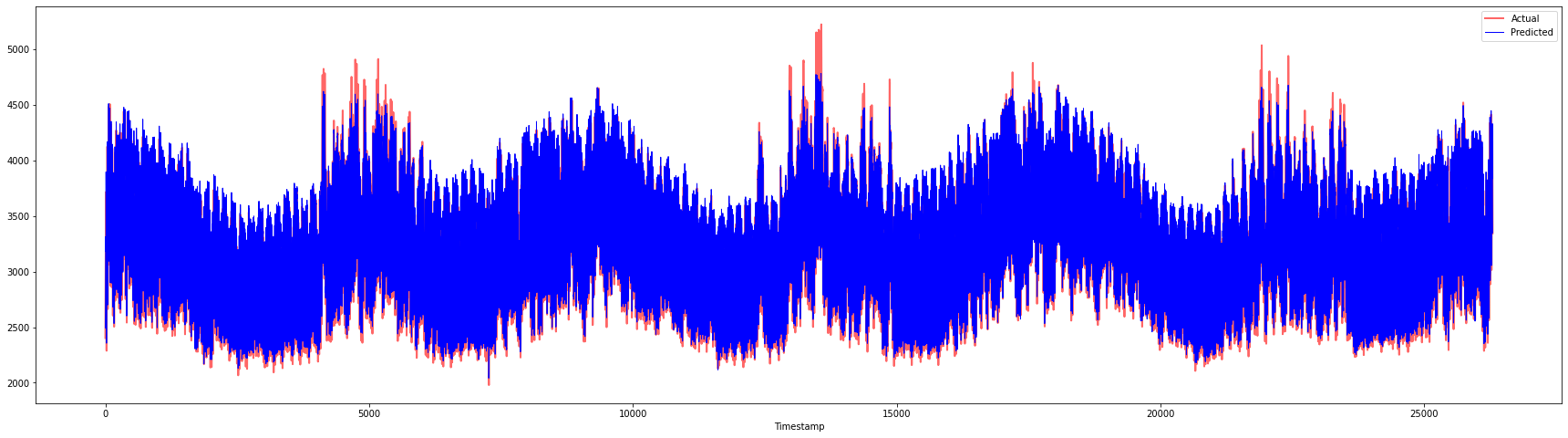
print('MAPE: ', mape(Y_pred, Y)*100, '%')
MAPE: 2.0572089029888656 %
🏆 素晴らしいプロットで、精度の高いモデルを示しています。よくできました!
🚀チャレンジ
- モデルを作成する際にハイパーパラメータ(gamma、C、epsilon)を調整して、テストデータでの最適な結果を得るセットを評価してみてください。これらのハイパーパラメータについて詳しく知りたい場合は、こちらのドキュメントを参照してください。
- モデルに対して異なるカーネル関数を使用し、データセットでのパフォーマンスを分析してみてください。役立つドキュメントはこちらにあります。
- モデルが予測を行うために振り返る
timestepsの値を異なるものにしてみてください。
事後クイズ
レビューと自己学習
このレッスンでは、時系列予測のためのSVRの応用を紹介しました。SVRについてさらに詳しく知りたい場合は、このブログを参照してください。このscikit-learnのドキュメントでは、SVM全般、SVR、および異なるカーネル関数の使用方法やそのパラメータなど、他の実装の詳細についても包括的な説明が提供されています。
課題
クレジット
免責事項: この文書は、機械ベースのAI翻訳サービスを使用して翻訳されています。正確さを期していますが、自動翻訳には誤りや不正確さが含まれる可能性があることをご了承ください。元の言語で書かれた原文が権威ある情報源と見なされるべきです。重要な情報については、専門の人間による翻訳をお勧めします。この翻訳の使用に起因する誤解や誤認については、一切の責任を負いかねます。
-
このセクションのテキスト、コード、および出力はAnirbanMukherjeeXDによって提供されました。 ↩︎