|
|
8 months ago | |
|---|---|---|
| .. | ||
| README.md | 8 months ago | |
| assignment.md | 8 months ago | |
README.md
Previsione di Serie Temporali con Support Vector Regressor
Nella lezione precedente, hai imparato a utilizzare il modello ARIMA per fare previsioni su serie temporali. Ora vedrai il modello Support Vector Regressor, che è un modello di regressione usato per prevedere dati continui.
Quiz Pre-lezione
Introduzione
In questa lezione, scoprirai un modo specifico per costruire modelli con SVM: Support Vector Machine per la regressione, o SVR: Support Vector Regressor.
SVR nel contesto delle serie temporali 1
Prima di comprendere l'importanza di SVR nella previsione delle serie temporali, ecco alcuni concetti importanti che devi conoscere:
- Regressione: Tecnica di apprendimento supervisionato per prevedere valori continui da un insieme di input dato. L'idea è di adattare una curva (o linea) nello spazio delle caratteristiche che ha il maggior numero di punti dati. Clicca qui per maggiori informazioni.
- Support Vector Machine (SVM): Un tipo di modello di apprendimento supervisionato utilizzato per classificazione, regressione e rilevamento di anomalie. Il modello è un iperpiano nello spazio delle caratteristiche, che nel caso della classificazione agisce come un confine, e nel caso della regressione agisce come la linea di miglior adattamento. In SVM, una funzione Kernel viene generalmente utilizzata per trasformare il dataset in uno spazio con un numero maggiore di dimensioni, in modo che possano essere facilmente separabili. Clicca qui per maggiori informazioni sulle SVM.
- Support Vector Regressor (SVR): Un tipo di SVM, per trovare la linea di miglior adattamento (che nel caso di SVM è un iperpiano) che ha il maggior numero di punti dati.
Perché SVR? 1
Nell'ultima lezione hai imparato l'ARIMA, che è un metodo statistico lineare molto efficace per prevedere i dati delle serie temporali. Tuttavia, in molti casi, i dati delle serie temporali presentano non-linearità, che non possono essere mappate da modelli lineari. In questi casi, la capacità di SVM di considerare la non-linearità nei dati per compiti di regressione rende SVR efficace nella previsione delle serie temporali.
Esercizio - costruisci un modello SVR
I primi passi per la preparazione dei dati sono gli stessi della lezione precedente su ARIMA.
Apri la cartella /working in questa lezione e trova il file notebook.ipynb.2
-
Esegui il notebook e importa le librerie necessarie: 2
import sys sys.path.append('../../')import os import warnings import matplotlib.pyplot as plt import numpy as np import pandas as pd import datetime as dt import math from sklearn.svm import SVR from sklearn.preprocessing import MinMaxScaler from common.utils import load_data, mape -
Carica i dati dal file
/data/energy.csvin un dataframe Pandas e dai un'occhiata: 2energy = load_data('../../data')[['load']] -
Traccia tutti i dati energetici disponibili da gennaio 2012 a dicembre 2014: 2
energy.plot(y='load', subplots=True, figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()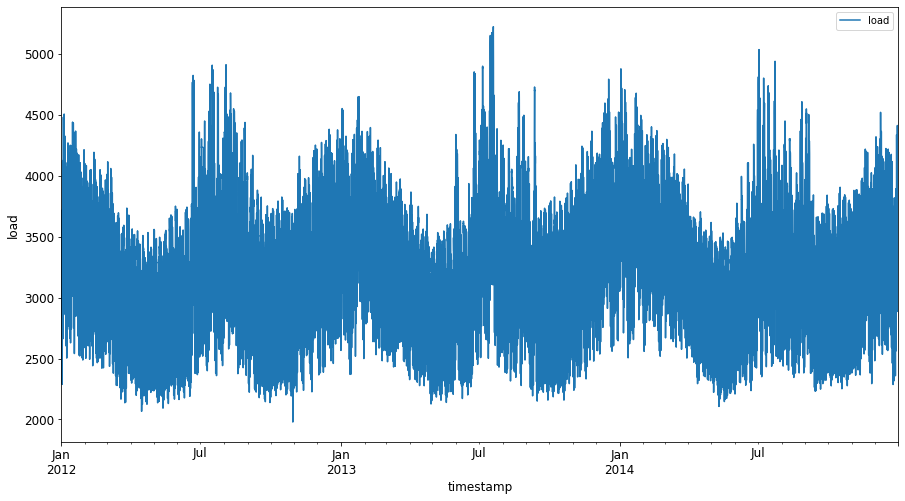
Ora, costruiamo il nostro modello SVR.
Crea set di dati per l'addestramento e il test
Ora i tuoi dati sono caricati, quindi puoi separarli in set di addestramento e test. Poi ridimensionerai i dati per creare un dataset basato sui passi temporali che sarà necessario per il SVR. Addestrerai il tuo modello sul set di addestramento. Dopo che il modello ha finito l'addestramento, valuterai la sua accuratezza sul set di addestramento, sul set di test e poi sull'intero dataset per vedere le prestazioni complessive. Devi assicurarti che il set di test copra un periodo successivo nel tempo rispetto al set di addestramento per garantire che il modello non acquisisca informazioni dai periodi futuri 2 (una situazione nota come Overfitting).
-
Assegna un periodo di due mesi dal 1 settembre al 31 ottobre 2014 al set di addestramento. Il set di test includerà il periodo di due mesi dal 1 novembre al 31 dicembre 2014: 2
train_start_dt = '2014-11-01 00:00:00' test_start_dt = '2014-12-30 00:00:00' -
Visualizza le differenze: 2
energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)][['load']].rename(columns={'load':'train'}) \ .join(energy[test_start_dt:][['load']].rename(columns={'load':'test'}), how='outer') \ .plot(y=['train', 'test'], figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()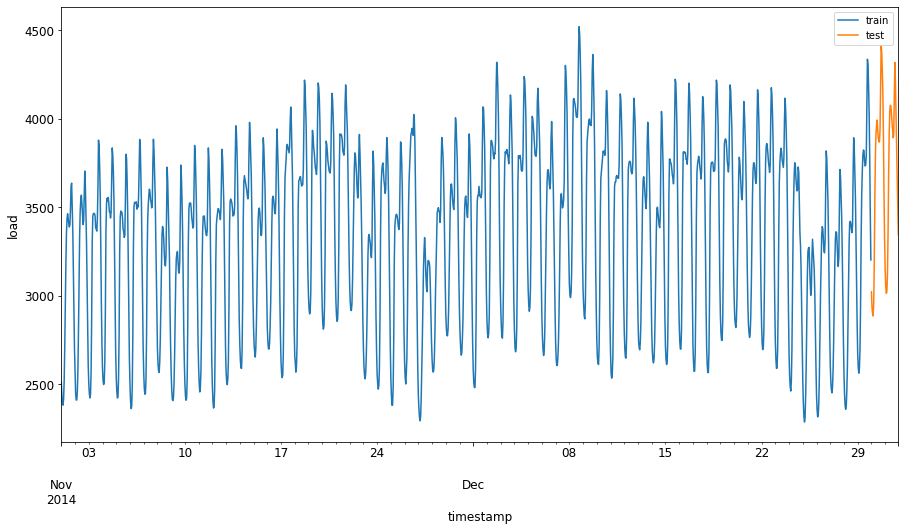
Prepara i dati per l'addestramento
Ora, devi preparare i dati per l'addestramento eseguendo il filtraggio e la scalatura dei dati. Filtra il tuo dataset per includere solo i periodi di tempo e le colonne necessarie, e scala i dati per garantire che siano proiettati nell'intervallo 0,1.
-
Filtra il dataset originale per includere solo i periodi di tempo sopra menzionati per set e includendo solo la colonna necessaria 'load' più la data: 2
train = energy.copy()[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']] test = energy.copy()[energy.index >= test_start_dt][['load']] print('Training data shape: ', train.shape) print('Test data shape: ', test.shape)Training data shape: (1416, 1) Test data shape: (48, 1) -
Scala i dati di addestramento per essere nell'intervallo (0, 1): 2
scaler = MinMaxScaler() train['load'] = scaler.fit_transform(train) -
Ora, scala i dati di test: 2
test['load'] = scaler.transform(test)
Crea dati con passi temporali 1
Per il SVR, trasformi i dati di input in forma [batch, timesteps]. So, you reshape the existing train_data and test_data in modo che ci sia una nuova dimensione che si riferisce ai passi temporali.
# Converting to numpy arrays
train_data = train.values
test_data = test.values
Per questo esempio, prendiamo timesteps = 5. Quindi, gli input al modello sono i dati per i primi 4 passi temporali, e l'output sarà i dati per il 5° passo temporale.
timesteps=5
Convertire i dati di addestramento in un tensore 2D utilizzando la comprensione delle liste nidificate:
train_data_timesteps=np.array([[j for j in train_data[i:i+timesteps]] for i in range(0,len(train_data)-timesteps+1)])[:,:,0]
train_data_timesteps.shape
(1412, 5)
Convertire i dati di test in un tensore 2D:
test_data_timesteps=np.array([[j for j in test_data[i:i+timesteps]] for i in range(0,len(test_data)-timesteps+1)])[:,:,0]
test_data_timesteps.shape
(44, 5)
Selezionare input e output dai dati di addestramento e test:
x_train, y_train = train_data_timesteps[:,:timesteps-1],train_data_timesteps[:,[timesteps-1]]
x_test, y_test = test_data_timesteps[:,:timesteps-1],test_data_timesteps[:,[timesteps-1]]
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
(1412, 4) (1412, 1)
(44, 4) (44, 1)
Implementa SVR 1
Ora, è il momento di implementare SVR. Per leggere di più su questa implementazione, puoi fare riferimento a questa documentazione. Per la nostra implementazione, seguiamo questi passaggi:
- Definisci il modello chiamando
SVR()and passing in the model hyperparameters: kernel, gamma, c and epsilon - Prepare the model for the training data by calling the
fit()function - Make predictions calling the
predict()function
Ora creiamo un modello SVR. Qui usiamo il kernel RBF, e impostiamo gli iperparametri gamma, C ed epsilon rispettivamente a 0.5, 10 e 0.05.
model = SVR(kernel='rbf',gamma=0.5, C=10, epsilon = 0.05)
Adatta il modello ai dati di addestramento 1
model.fit(x_train, y_train[:,0])
SVR(C=10, cache_size=200, coef0=0.0, degree=3, epsilon=0.05, gamma=0.5,
kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
Fai previsioni con il modello 1
y_train_pred = model.predict(x_train).reshape(-1,1)
y_test_pred = model.predict(x_test).reshape(-1,1)
print(y_train_pred.shape, y_test_pred.shape)
(1412, 1) (44, 1)
Hai costruito il tuo SVR! Ora dobbiamo valutarlo.
Valuta il tuo modello 1
Per la valutazione, prima scaleremo indietro i dati alla nostra scala originale. Poi, per verificare le prestazioni, tracceremo il grafico della serie temporale originale e prevista, e stamperemo anche il risultato MAPE.
Scala l'output previsto e originale:
# Scaling the predictions
y_train_pred = scaler.inverse_transform(y_train_pred)
y_test_pred = scaler.inverse_transform(y_test_pred)
print(len(y_train_pred), len(y_test_pred))
# Scaling the original values
y_train = scaler.inverse_transform(y_train)
y_test = scaler.inverse_transform(y_test)
print(len(y_train), len(y_test))
Verifica le prestazioni del modello sui dati di addestramento e di test 1
Estrarremo i timestamp dal dataset per mostrarli sull'asse x del nostro grafico. Nota che stiamo utilizzando i primi timesteps-1 valori come input per il primo output, quindi i timestamp per l'output inizieranno dopo.
train_timestamps = energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)].index[timesteps-1:]
test_timestamps = energy[test_start_dt:].index[timesteps-1:]
print(len(train_timestamps), len(test_timestamps))
1412 44
Traccia le previsioni per i dati di addestramento:
plt.figure(figsize=(25,6))
plt.plot(train_timestamps, y_train, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(train_timestamps, y_train_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.title("Training data prediction")
plt.show()
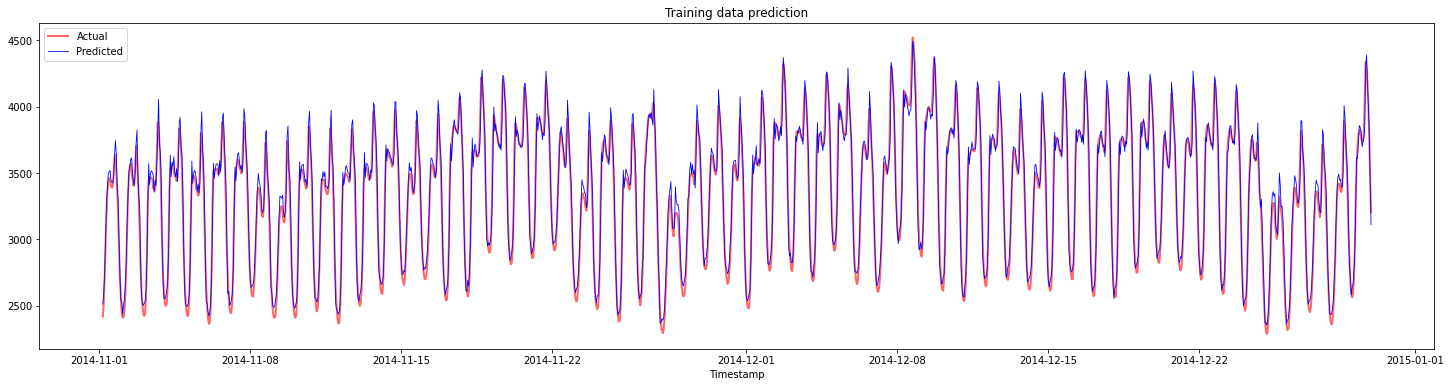
Stampa MAPE per i dati di addestramento
print('MAPE for training data: ', mape(y_train_pred, y_train)*100, '%')
MAPE for training data: 1.7195710200875551 %
Traccia le previsioni per i dati di test
plt.figure(figsize=(10,3))
plt.plot(test_timestamps, y_test, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(test_timestamps, y_test_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.show()
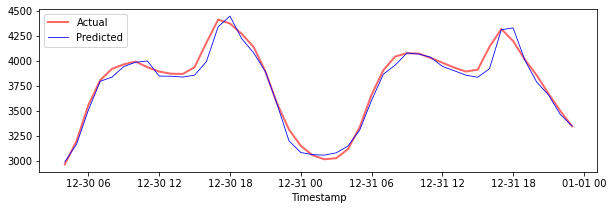
Stampa MAPE per i dati di test
print('MAPE for testing data: ', mape(y_test_pred, y_test)*100, '%')
MAPE for testing data: 1.2623790187854018 %
🏆 Hai ottenuto un ottimo risultato sul dataset di test!
Verifica le prestazioni del modello sull'intero dataset 1
# Extracting load values as numpy array
data = energy.copy().values
# Scaling
data = scaler.transform(data)
# Transforming to 2D tensor as per model input requirement
data_timesteps=np.array([[j for j in data[i:i+timesteps]] for i in range(0,len(data)-timesteps+1)])[:,:,0]
print("Tensor shape: ", data_timesteps.shape)
# Selecting inputs and outputs from data
X, Y = data_timesteps[:,:timesteps-1],data_timesteps[:,[timesteps-1]]
print("X shape: ", X.shape,"\nY shape: ", Y.shape)
Tensor shape: (26300, 5)
X shape: (26300, 4)
Y shape: (26300, 1)
# Make model predictions
Y_pred = model.predict(X).reshape(-1,1)
# Inverse scale and reshape
Y_pred = scaler.inverse_transform(Y_pred)
Y = scaler.inverse_transform(Y)
plt.figure(figsize=(30,8))
plt.plot(Y, color = 'red', linewidth=2.0, alpha = 0.6)
plt.plot(Y_pred, color = 'blue', linewidth=0.8)
plt.legend(['Actual','Predicted'])
plt.xlabel('Timestamp')
plt.show()
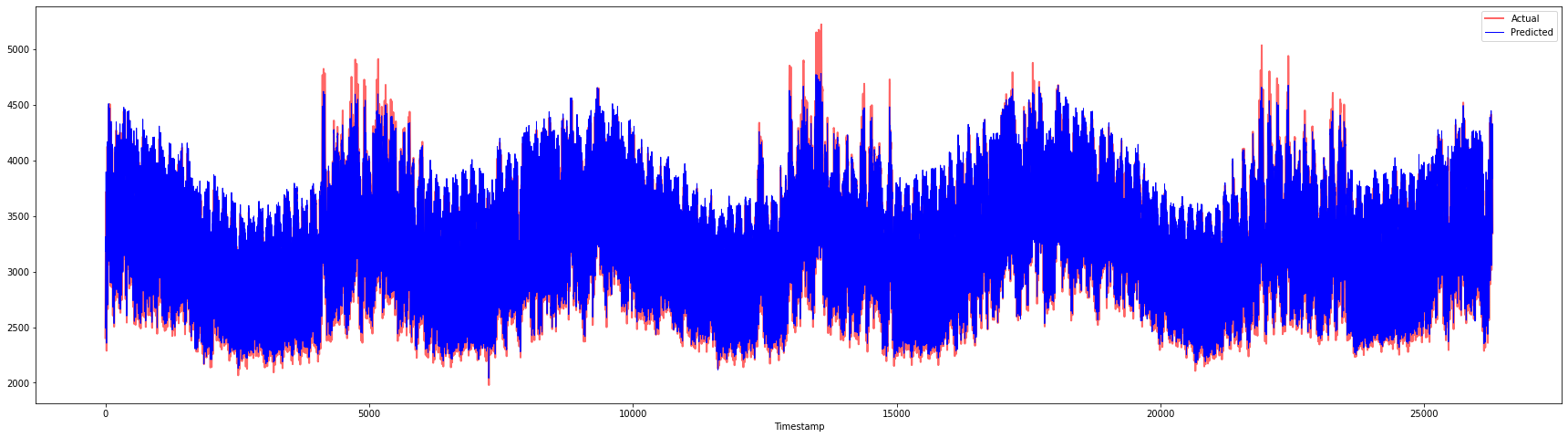
print('MAPE: ', mape(Y_pred, Y)*100, '%')
MAPE: 2.0572089029888656 %
🏆 Grafici molto belli, che mostrano un modello con buona accuratezza. Ben fatto!
🚀Sfida
- Prova a modificare gli iperparametri (gamma, C, epsilon) durante la creazione del modello e valuta sui dati per vedere quale set di iperparametri dà i migliori risultati sui dati di test. Per saperne di più su questi iperparametri, puoi fare riferimento al documento qui.
- Prova a usare diverse funzioni kernel per il modello e analizza le loro prestazioni sul dataset. Un documento utile può essere trovato qui.
- Prova a usare diversi valori per
timestepsper far sì che il modello guardi indietro per fare la previsione.
Quiz Post-lezione
Revisione & Studio Autonomo
Questa lezione era per introdurre l'applicazione di SVR per la previsione delle serie temporali. Per leggere di più su SVR, puoi fare riferimento a questo blog. Questa documentazione su scikit-learn fornisce una spiegazione più completa sulle SVM in generale, SVR e anche altri dettagli di implementazione come le diverse funzioni kernel che possono essere utilizzate, e i loro parametri.
Compito
Crediti
Disclaimer: Questo documento è stato tradotto utilizzando servizi di traduzione automatizzata basati su intelligenza artificiale. Sebbene ci impegniamo per l'accuratezza, si prega di essere consapevoli che le traduzioni automatiche possono contenere errori o inesattezze. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale umana. Non siamo responsabili per eventuali malintesi o interpretazioni errate derivanti dall'uso di questa traduzione.
-
Il testo, il codice e l'output in questa sezione sono stati contribuiti da @AnirbanMukherjeeXD ↩︎
-
Il testo, il codice e l'output in questa sezione sono stati presi da ARIMA ↩︎