\r\n",
" \r\n",
" Infographic by Dasani Madipalli\r\n",
"\r\n",
"\r\n",
"\r\n",
"\r\n",
"#### Introduction\r\n",
"\r\n",
"So far you have explored what regression is with sample data gathered from the pumpkin pricing dataset that we will use throughout this lesson. You have also visualized it using `ggplot2`.💪\r\n",
"\r\n",
"Now you are ready to dive deeper into regression for ML. In this lesson, you will learn more about two types of regression: *basic linear regression* and *polynomial regression*, along with some of the math underlying these techniques.\r\n",
"\r\n",
"> Throughout this curriculum, we assume minimal knowledge of math, and seek to make it accessible for students coming from other fields, so watch for notes, 🧮 callouts, diagrams, and other learning tools to aid in comprehension.\r\n",
"\r\n",
"#### Preparation\r\n",
"\r\n",
"As a reminder, you are loading this data so as to ask questions of it.\r\n",
"\r\n",
"- When is the best time to buy pumpkins?\r\n",
"\r\n",
"- What price can I expect of a case of miniature pumpkins?\r\n",
"\r\n",
"- Should I buy them in half-bushel baskets or by the 1 1/9 bushel box? Let's keep digging into this data.\r\n",
"\r\n",
"In the previous lesson, you created a `tibble` (a modern reimagining of the data frame) and populated it with part of the original dataset, standardizing the pricing by the bushel. By doing that, however, you were only able to gather about 400 data points and only for the fall months. Maybe we can get a little more detail about the nature of the data by cleaning it more? We'll see... 🕵️♀️\r\n",
"\r\n",
"For this task, we'll require the following packages:\r\n",
"\r\n",
"- `tidyverse`: The [tidyverse](https://www.tidyverse.org/) is a [collection of R packages](https://www.tidyverse.org/packages) designed to makes data science faster, easier and more fun!\r\n",
"\r\n",
"- `tidymodels`: The [tidymodels](https://www.tidymodels.org/) framework is a [collection of packages](https://www.tidymodels.org/packages/) for modeling and machine learning.\r\n",
"\r\n",
"- `janitor`: The [janitor package](https://github.com/sfirke/janitor) provides simple little tools for examining and cleaning dirty data.\r\n",
"\r\n",
"- `corrplot`: The [corrplot package](https://cran.r-project.org/web/packages/corrplot/vignettes/corrplot-intro.html) provides a visual exploratory tool on correlation matrix that supports automatic variable reordering to help detect hidden patterns among variables.\r\n",
"\r\n",
"You can have them installed as:\r\n",
"\r\n",
"`install.packages(c(\"tidyverse\", \"tidymodels\", \"janitor\", \"corrplot\"))`\r\n",
"\r\n",
"The script below checks whether you have the packages required to complete this module and installs them for you in case they are missing."
],
"metadata": {
"id": "WqQPS1OAsg3H"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"suppressWarnings(if (!require(\"pacman\")) install.packages(\"pacman\"))\r\n",
"\r\n",
"pacman::p_load(tidyverse, tidymodels, janitor, corrplot)"
],
"outputs": [],
"metadata": {
"id": "tA4C2WN3skCf",
"colab": {
"base_uri": "https://localhost:8080/"
},
"outputId": "c06cd805-5534-4edc-f72b-d0d1dab96ac0"
}
},
{
"cell_type": "markdown",
"source": [
"We'll later load these awesome packages and make them available in our current R session. (This is for mere illustration, `pacman::p_load()` already did that for you)\r\n",
"\r\n",
"## 1. A linear regression line\r\n",
"\r\n",
"As you learned in Lesson 1, the goal of a linear regression exercise is to be able to plot a *line* *of* *best fit* to:\r\n",
"\r\n",
"- **Show variable relationships**. Show the relationship between variables\r\n",
"\r\n",
"- **Make predictions**. Make accurate predictions on where a new data point would fall in relationship to that line.\r\n",
"\r\n",
"To draw this type of line, we use a statistical technique called **Least-Squares Regression**. The term `least-squares` means that all the data points surrounding the regression line are squared and then added up. Ideally, that final sum is as small as possible, because we want a low number of errors, or `least-squares`. As such, the line of best fit is the line that gives us the lowest value for the sum of the squared errors - hence the name *least squares regression*.\r\n",
"\r\n",
"We do so since we want to model a line that has the least cumulative distance from all of our data points. We also square the terms before adding them since we are concerned with its magnitude rather than its direction.\r\n",
"\r\n",
"> **🧮 Show me the math**\r\n",
">\r\n",
"> This line, called the *line of best fit* can be expressed by [an equation](https://en.wikipedia.org/wiki/Simple_linear_regression):\r\n",
">\r\n",
"> Y = a + bX\r\n",
">\r\n",
"> `X` is the '`explanatory variable` or `predictor`'. `Y` is the '`dependent variable` or `outcome`'. The slope of the line is `b` and `a` is the y-intercept, which refers to the value of `Y` when `X = 0`.\r\n",
">\r\n",
"\r\n",
"> \r\n",
" Infographic by Jen Looper\r\n",
">\r\n",
"> First, calculate the slope `b`.\r\n",
">\r\n",
"> In other words, and referring to our pumpkin data's original question: \"predict the price of a pumpkin per bushel by month\", `X` would refer to the price and `Y` would refer to the month of sale.\r\n",
">\r\n",
"> 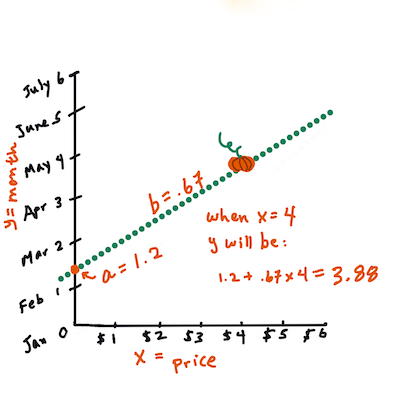\r\n",
" Infographic by Jen Looper\r\n",
"> \r\n",
"> Calculate the value of Y. If you're paying around \\$4, it must be April!\r\n",
">\r\n",
"> The math that calculates the line must demonstrate the slope of the line, which is also dependent on the intercept, or where `Y` is situated when `X = 0`.\r\n",
">\r\n",
"> You can observe the method of calculation for these values on the [Math is Fun](https://www.mathsisfun.com/data/least-squares-regression.html) web site. Also visit [this Least-squares calculator](https://www.mathsisfun.com/data/least-squares-calculator.html) to watch how the numbers' values impact the line.\r\n",
"\r\n",
"Not so scary, right? 🤓\r\n",
"\r\n",
"#### Correlation\r\n",
"\r\n",
"One more term to understand is the **Correlation Coefficient** between given X and Y variables. Using a scatterplot, you can quickly visualize this coefficient. A plot with datapoints scattered in a neat line have high correlation, but a plot with datapoints scattered everywhere between X and Y have a low correlation.\r\n",
"\r\n",
"A good linear regression model will be one that has a high (nearer to 1 than 0) Correlation Coefficient using the Least-Squares Regression method with a line of regression.\r\n",
"\r\n"
],
"metadata": {
"id": "cdX5FRpvsoP5"
}
},
{
"cell_type": "markdown",
"source": [
"## **2. A dance with data: creating a data frame that will be used for modelling**\r\n",
"\r\n",
"
\r\n",
" \r\n",
" Artwork by @allison_horst\r\n",
"\r\n",
"\r\n",
""
],
"metadata": {
"id": "WdUKXk7Bs8-V"
}
},
{
"cell_type": "markdown",
"source": [
"Load up required libraries and dataset. Convert the data to a data frame containing a subset of the data:\n",
"\n",
"- Only get pumpkins priced by the bushel\n",
"\n",
"- Convert the date to a month\n",
"\n",
"- Calculate the price to be an average of high and low prices\n",
"\n",
"- Convert the price to reflect the pricing by bushel quantity\n",
"\n",
"> We covered these steps in the [previous lesson](https://github.com/microsoft/ML-For-Beginners/blob/main/2-Regression/2-Data/solution/lesson_2-R.ipynb)."
],
"metadata": {
"id": "fMCtu2G2s-p8"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Load the core Tidyverse packages\r\n",
"library(tidyverse)\r\n",
"library(lubridate)\r\n",
"\r\n",
"# Import the pumpkins data\r\n",
"pumpkins <- read_csv(file = \"https://raw.githubusercontent.com/microsoft/ML-For-Beginners/main/2-Regression/data/US-pumpkins.csv\")\r\n",
"\r\n",
"\r\n",
"# Get a glimpse and dimensions of the data\r\n",
"glimpse(pumpkins)\r\n",
"\r\n",
"\r\n",
"# Print the first 50 rows of the data set\r\n",
"pumpkins %>% \r\n",
" slice_head(n = 5)"
],
"outputs": [],
"metadata": {
"id": "ryMVZEEPtERn"
}
},
{
"cell_type": "markdown",
"source": [
"In the spirit of sheer adventure, let's explore the [`janitor package`](github.com/sfirke/janitor) that provides simple functions for examining and cleaning dirty data. For instance, let's take a look at the column names for our data:"
],
"metadata": {
"id": "xcNxM70EtJjb"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Return column names\r\n",
"pumpkins %>% \r\n",
" names()"
],
"outputs": [],
"metadata": {
"id": "5XtpaIigtPfW"
}
},
{
"cell_type": "markdown",
"source": [
"🤔 We can do better. Let's make these column names `friendR` by converting them to the [snake_case](https://en.wikipedia.org/wiki/Snake_case) convention using `janitor::clean_names`. To find out more about this function: `?clean_names`"
],
"metadata": {
"id": "IbIqrMINtSHe"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Clean names to the snake_case convention\r\n",
"pumpkins <- pumpkins %>% \r\n",
" clean_names(case = \"snake\")\r\n",
"\r\n",
"# Return column names\r\n",
"pumpkins %>% \r\n",
" names()"
],
"outputs": [],
"metadata": {
"id": "a2uYvclYtWvX"
}
},
{
"cell_type": "markdown",
"source": [
"Much tidyR 🧹! Now, a dance with the data using `dplyr` as in the previous lesson! 💃\n"
],
"metadata": {
"id": "HfhnuzDDtaDd"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Select desired columns\r\n",
"pumpkins <- pumpkins %>% \r\n",
" select(variety, city_name, package, low_price, high_price, date)\r\n",
"\r\n",
"\r\n",
"\r\n",
"# Extract the month from the dates to a new column\r\n",
"pumpkins <- pumpkins %>%\r\n",
" mutate(date = mdy(date),\r\n",
" month = month(date)) %>% \r\n",
" select(-date)\r\n",
"\r\n",
"\r\n",
"\r\n",
"# Create a new column for average Price\r\n",
"pumpkins <- pumpkins %>% \r\n",
" mutate(price = (low_price + high_price)/2)\r\n",
"\r\n",
"\r\n",
"# Retain only pumpkins with the string \"bushel\"\r\n",
"new_pumpkins <- pumpkins %>% \r\n",
" filter(str_detect(string = package, pattern = \"bushel\"))\r\n",
"\r\n",
"\r\n",
"# Normalize the pricing so that you show the pricing per bushel, not per 1 1/9 or 1/2 bushel\r\n",
"new_pumpkins <- new_pumpkins %>% \r\n",
" mutate(price = case_when(\r\n",
" str_detect(package, \"1 1/9\") ~ price/(1.1),\r\n",
" str_detect(package, \"1/2\") ~ price*2,\r\n",
" TRUE ~ price))\r\n",
"\r\n",
"# Relocate column positions\r\n",
"new_pumpkins <- new_pumpkins %>% \r\n",
" relocate(month, .before = variety)\r\n",
"\r\n",
"\r\n",
"# Display the first 5 rows\r\n",
"new_pumpkins %>% \r\n",
" slice_head(n = 5)"
],
"outputs": [],
"metadata": {
"id": "X0wU3gQvtd9f"
}
},
{
"cell_type": "markdown",
"source": [
"Good job!👌 You now have a clean, tidy data set on which you can build your new regression model!\n",
"\n",
"Mind a scatter plot?\n"
],
"metadata": {
"id": "UpaIwaxqth82"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Set theme\r\n",
"theme_set(theme_light())\r\n",
"\r\n",
"# Make a scatter plot of month and price\r\n",
"new_pumpkins %>% \r\n",
" ggplot(mapping = aes(x = month, y = price)) +\r\n",
" geom_point(size = 1.6)\r\n"
],
"outputs": [],
"metadata": {
"id": "DXgU-j37tl5K"
}
},
{
"cell_type": "markdown",
"source": [
"A scatter plot reminds us that we only have month data from August through December. We probably need more data to be able to draw conclusions in a linear fashion.\n",
"\n",
"Let's take a look at our modelling data again:"
],
"metadata": {
"id": "Ve64wVbwtobI"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Display first 5 rows\r\n",
"new_pumpkins %>% \r\n",
" slice_head(n = 5)"
],
"outputs": [],
"metadata": {
"id": "HFQX2ng1tuSJ"
}
},
{
"cell_type": "markdown",
"source": [
"What if we wanted to predict the `price` of a pumpkin based on the `city` or `package` columns which are of type character? Or even more simply, how could we find the correlation (which requires both of its inputs to be numeric) between, say, `package` and `price`? 🤷🤷\n",
"\n",
"Machine learning models work best with numeric features rather than text values, so you generally need to convert categorical features into numeric representations.\n",
"\n",
"This means that we have to find a way to reformat our predictors to make them easier for a model to use effectively, a process known as `feature engineering`."
],
"metadata": {
"id": "7hsHoxsStyjJ"
}
},
{
"cell_type": "markdown",
"source": [
"## 3. Preprocessing data for modelling with recipes 👩🍳👨🍳\n",
"\n",
"Activities that reformat predictor values to make them easier for a model to use effectively has been termed `feature engineering`.\n",
"\n",
"Different models have different preprocessing requirements. For instance, least squares requires `encoding categorical variables` such as month, variety and city_name. This simply involves `translating` a column with `categorical values` into one or more `numeric columns` that take the place of the original.\n",
"\n",
"For example, suppose your data includes the following categorical feature:\n",
"\n",
"| city |\n",
"|:-------:|\n",
"| Denver |\n",
"| Nairobi |\n",
"| Tokyo |\n",
"\n",
"You can apply *ordinal encoding* to substitute a unique integer value for each category, like this:\n",
"\n",
"| city |\n",
"|:----:|\n",
"| 0 |\n",
"| 1 |\n",
"| 2 |\n",
"\n",
"And that's what we'll do to our data!\n",
"\n",
"In this section, we'll explore another amazing Tidymodels package: [recipes](https://tidymodels.github.io/recipes/) - which is designed to help you preprocess your data **before** training your model. At its core, a recipe is an object that defines what steps should be applied to a data set in order to get it ready for modelling.\n",
"\n",
"Now, let's create a recipe that prepares our data for modelling by substituting a unique integer for all the observations in the predictor columns:"
],
"metadata": {
"id": "AD5kQbcvt3Xl"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Specify a recipe\r\n",
"pumpkins_recipe <- recipe(price ~ ., data = new_pumpkins) %>% \r\n",
" step_integer(all_predictors(), zero_based = TRUE)\r\n",
"\r\n",
"\r\n",
"# Print out the recipe\r\n",
"pumpkins_recipe"
],
"outputs": [],
"metadata": {
"id": "BNaFKXfRt9TU"
}
},
{
"cell_type": "markdown",
"source": [
"Awesome! 👏 We just created our first recipe that specifies an outcome (price) and its corresponding predictors and that all the predictor columns should be encoded into a set of integers 🙌! Let's quickly break it down:\r\n",
"\r\n",
"- The call to `recipe()` with a formula tells the recipe the *roles* of the variables using `new_pumpkins` data as the reference. For instance the `price` column has been assigned an `outcome` role while the rest of the columns have been assigned a `predictor` role.\r\n",
"\r\n",
"- `step_integer(all_predictors(), zero_based = TRUE)` specifies that all the predictors should be converted into a set of integers with the numbering starting at 0.\r\n",
"\r\n",
"We are sure you may be having thoughts such as: \"This is so cool!! But what if I needed to confirm that the recipes are doing exactly what I expect them to do? 🤔\"\r\n",
"\r\n",
"That's an awesome thought! You see, once your recipe is defined, you can estimate the parameters required to actually preprocess the data, and then extract the processed data. You don't typically need to do this when you use Tidymodels (we'll see the normal convention in just a minute-\\> `workflows`) but it can come in handy when you want to do some kind of sanity check for confirming that recipes are doing what you expect.\r\n",
"\r\n",
"For that, you'll need two more verbs: `prep()` and `bake()` and as always, our little R friends by [`Allison Horst`](https://github.com/allisonhorst/stats-illustrations) help you in understanding this better!\r\n",
"\r\n",
"
\r\n",
" \r\n",
" Artwork by @allison_horst\r\n",
"\r\n",
"\r\n",
""
],
"metadata": {
"id": "KEiO0v7kuC9O"
}
},
{
"cell_type": "markdown",
"source": [
"[`prep()`](https://recipes.tidymodels.org/reference/prep.html): estimates the required parameters from a training set that can be later applied to other data sets. For instance, for a given predictor column, what observation will be assigned integer 0 or 1 or 2 etc\n",
"\n",
"[`bake()`](https://recipes.tidymodels.org/reference/bake.html): takes a prepped recipe and applies the operations to any data set.\n",
"\n",
"That said, lets prep and bake our recipes to really confirm that under the hood, the predictor columns will be first encoded before a model is fit."
],
"metadata": {
"id": "Q1xtzebuuTCP"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Prep the recipe\r\n",
"pumpkins_prep <- prep(pumpkins_recipe)\r\n",
"\r\n",
"# Bake the recipe to extract a preprocessed new_pumpkins data\r\n",
"baked_pumpkins <- bake(pumpkins_prep, new_data = NULL)\r\n",
"\r\n",
"# Print out the baked data set\r\n",
"baked_pumpkins %>% \r\n",
" slice_head(n = 10)"
],
"outputs": [],
"metadata": {
"id": "FGBbJbP_uUUn"
}
},
{
"cell_type": "markdown",
"source": [
"Woo-hoo!🥳 The processed data `baked_pumpkins` has all it's predictors encoded confirming that indeed the preprocessing steps defined as our recipe will work as expected. This makes it harder for you to read but much more intelligible for Tidymodels! Take some time to find out what observation has been mapped to a corresponding integer.\n",
"\n",
"It is also worth mentioning that `baked_pumpkins` is a data frame that we can perform computations on.\n",
"\n",
"For instance, let's try to find a good correlation between two points of your data to potentially build a good predictive model. We'll use the function `cor()` to do this. Type `?cor()` to find out more about the function."
],
"metadata": {
"id": "1dvP0LBUueAW"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Find the correlation between the city_name and the price\r\n",
"cor(baked_pumpkins$city_name, baked_pumpkins$price)\r\n",
"\r\n",
"# Find the correlation between the package and the price\r\n",
"cor(baked_pumpkins$package, baked_pumpkins$price)\r\n"
],
"outputs": [],
"metadata": {
"id": "3bQzXCjFuiSV"
}
},
{
"cell_type": "markdown",
"source": [
"As it turns out, there's only weak correlation between the City and Price. However there's a bit better correlation between the Package and its Price. That makes sense, right? Normally, the bigger the produce box, the higher the price.\n",
"\n",
"While we are at it, let's also try and visualize a correlation matrix of all the columns using the `corrplot` package."
],
"metadata": {
"id": "BToPWbgjuoZw"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Load the corrplot package\r\n",
"library(corrplot)\r\n",
"\r\n",
"# Obtain correlation matrix\r\n",
"corr_mat <- cor(baked_pumpkins %>% \r\n",
" # Drop columns that are not really informative\r\n",
" select(-c(low_price, high_price)))\r\n",
"\r\n",
"# Make a correlation plot between the variables\r\n",
"corrplot(corr_mat, method = \"shade\", shade.col = NA, tl.col = \"black\", tl.srt = 45, addCoef.col = \"black\", cl.pos = \"n\", order = \"original\")"
],
"outputs": [],
"metadata": {
"id": "ZwAL3ksmutVR"
}
},
{
"cell_type": "markdown",
"source": [
"🤩🤩 Much better.\r\n",
"\r\n",
"A good question to now ask of this data will be: '`What price can I expect of a given pumpkin package?`' Let's get right into it!\r\n",
"\r\n",
"> Note: When you **`bake()`** the prepped recipe **`pumpkins_prep`** with **`new_data = NULL`**, you extract the processed (i.e. encoded) training data. If you had another data set for example a test set and would want to see how a recipe would pre-process it, you would simply bake **`pumpkins_prep`** with **`new_data = test_set`**\r\n",
"\r\n",
"## 4. Build a linear regression model\r\n",
"\r\n",
"
\r\n",
" \r\n",
" Infographic by Dasani Madipalli\r\n",
"\r\n",
"\r\n",
""
],
"metadata": {
"id": "YqXjLuWavNxW"
}
},
{
"cell_type": "markdown",
"source": [
"Now that we have build a recipe, and actually confirmed that the data will be pre-processed appropriately, let's now build a regression model to answer the question: `What price can I expect of a given pumpkin package?`\n",
"\n",
"#### Train a linear regression model using the training set\n",
"\n",
"As you may have already figured out, the column *price* is the `outcome` variable while the *package* column is the `predictor` variable.\n",
"\n",
"To do this, we'll first split the data such that 80% goes into training and 20% into test set, then define a recipe that will encode the predictor column into a set of integers, then build a model specification. We won't prep and bake our recipe since we already know it will preprocess the data as expected."
],
"metadata": {
"id": "Pq0bSzCevW-h"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"set.seed(2056)\r\n",
"# Split the data into training and test sets\r\n",
"pumpkins_split <- new_pumpkins %>% \r\n",
" initial_split(prop = 0.8)\r\n",
"\r\n",
"\r\n",
"# Extract training and test data\r\n",
"pumpkins_train <- training(pumpkins_split)\r\n",
"pumpkins_test <- testing(pumpkins_split)\r\n",
"\r\n",
"\r\n",
"\r\n",
"# Create a recipe for preprocessing the data\r\n",
"lm_pumpkins_recipe <- recipe(price ~ package, data = pumpkins_train) %>% \r\n",
" step_integer(all_predictors(), zero_based = TRUE)\r\n",
"\r\n",
"\r\n",
"\r\n",
"# Create a linear model specification\r\n",
"lm_spec <- linear_reg() %>% \r\n",
" set_engine(\"lm\") %>% \r\n",
" set_mode(\"regression\")"
],
"outputs": [],
"metadata": {
"id": "CyoEh_wuvcLv"
}
},
{
"cell_type": "markdown",
"source": [
"Good job! Now that we have a recipe and a model specification, we need to find a way of bundling them together into an object that will first preprocess the data (prep+bake behind the scenes), fit the model on the preprocessed data and also allow for potential post-processing activities. How's that for your peace of mind!🤩\n",
"\n",
"In Tidymodels, this convenient object is called a [`workflow`](https://workflows.tidymodels.org/) and conveniently holds your modeling components! This is what we'd call *pipelines* in *Python*.\n",
"\n",
"So let's bundle everything up into a workflow!📦"
],
"metadata": {
"id": "G3zF_3DqviFJ"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Hold modelling components in a workflow\r\n",
"lm_wf <- workflow() %>% \r\n",
" add_recipe(lm_pumpkins_recipe) %>% \r\n",
" add_model(lm_spec)\r\n",
"\r\n",
"# Print out the workflow\r\n",
"lm_wf"
],
"outputs": [],
"metadata": {
"id": "T3olroU3v-WX"
}
},
{
"cell_type": "markdown",
"source": [
"\n",
"👌 Into the bargain, a workflow can be fit/trained in much the same way a model can."
],
"metadata": {
"id": "zd1A5tgOwEPX"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Train the model\r\n",
"lm_wf_fit <- lm_wf %>% \r\n",
" fit(data = pumpkins_train)\r\n",
"\r\n",
"# Print the model coefficients learned \r\n",
"lm_wf_fit"
],
"outputs": [],
"metadata": {
"id": "NhJagFumwFHf"
}
},
{
"cell_type": "markdown",
"source": [
"From the model output, we can see the coefficients learned during training. They represent the coefficients of the line of best fit that gives us the lowest overall error between the actual and predicted variable.\n",
"\n",
"\n",
"#### Evaluate model performance using the test set\n",
"\n",
"It's time to see how the model performed 📏! How do we do this?\n",
"\n",
"Now that we've trained the model, we can use it to make predictions for the test_set using `parsnip::predict()`. Then we can compare these predictions to the actual label values to evaluate how well (or not!) the model is working.\n",
"\n",
"Let's start with making predictions for the test set then bind the columns to the test set."
],
"metadata": {
"id": "_4QkGtBTwItF"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Make predictions for the test set\r\n",
"predictions <- lm_wf_fit %>% \r\n",
" predict(new_data = pumpkins_test)\r\n",
"\r\n",
"\r\n",
"# Bind predictions to the test set\r\n",
"lm_results <- pumpkins_test %>% \r\n",
" select(c(package, price)) %>% \r\n",
" bind_cols(predictions)\r\n",
"\r\n",
"\r\n",
"# Print the first ten rows of the tibble\r\n",
"lm_results %>% \r\n",
" slice_head(n = 10)"
],
"outputs": [],
"metadata": {
"id": "UFZzTG0gwTs9"
}
},
{
"cell_type": "markdown",
"source": [
"\n",
"Yes, you have just trained a model and used it to make predictions!🔮 Is it any good, let's evaluate the model's performance!\n",
"\n",
"In Tidymodels, we do this using `yardstick::metrics()`! For linear regression, let's focus on the following metrics:\n",
"\n",
"- `Root Mean Square Error (RMSE)`: The square root of the [MSE](https://en.wikipedia.org/wiki/Mean_squared_error). This yields an absolute metric in the same unit as the label (in this case, the price of a pumpkin). The smaller the value, the better the model (in a simplistic sense, it represents the average price by which the predictions are wrong!)\n",
"\n",
"- `Coefficient of Determination (usually known as R-squared or R2)`: A relative metric in which the higher the value, the better the fit of the model. In essence, this metric represents how much of the variance between predicted and actual label values the model is able to explain."
],
"metadata": {
"id": "0A5MjzM7wW9M"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Evaluate performance of linear regression\r\n",
"metrics(data = lm_results,\r\n",
" truth = price,\r\n",
" estimate = .pred)"
],
"outputs": [],
"metadata": {
"id": "reJ0UIhQwcEH"
}
},
{
"cell_type": "markdown",
"source": [
"There goes the model performance. Let's see if we can get a better indication by visualizing a scatter plot of the package and price then use the predictions made to overlay a line of best fit.\n",
"\n",
"This means we'll have to prep and bake the test set in order to encode the package column then bind this to the predictions made by our model."
],
"metadata": {
"id": "fdgjzjkBwfWt"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Encode package column\r\n",
"package_encode <- lm_pumpkins_recipe %>% \r\n",
" prep() %>% \r\n",
" bake(new_data = pumpkins_test) %>% \r\n",
" select(package)\r\n",
"\r\n",
"\r\n",
"# Bind encoded package column to the results\r\n",
"lm_results <- lm_results %>% \r\n",
" bind_cols(package_encode %>% \r\n",
" rename(package_integer = package)) %>% \r\n",
" relocate(package_integer, .after = package)\r\n",
"\r\n",
"\r\n",
"# Print new results data frame\r\n",
"lm_results %>% \r\n",
" slice_head(n = 5)\r\n",
"\r\n",
"\r\n",
"# Make a scatter plot\r\n",
"lm_results %>% \r\n",
" ggplot(mapping = aes(x = package_integer, y = price)) +\r\n",
" geom_point(size = 1.6) +\r\n",
" # Overlay a line of best fit\r\n",
" geom_line(aes(y = .pred), color = \"orange\", size = 1.2) +\r\n",
" xlab(\"package\")\r\n",
" \r\n"
],
"outputs": [],
"metadata": {
"id": "R0nw719lwkHE"
}
},
{
"cell_type": "markdown",
"source": [
"Great! As you can see, the linear regression model does not really well generalize the relationship between a package and its corresponding price.\r\n",
"\r\n",
"🎃 Congratulations, you just created a model that can help predict the price of a few varieties of pumpkins. Your holiday pumpkin patch will be beautiful. But you can probably create a better model!\r\n",
"\r\n",
"## 5. Build a polynomial regression model\r\n",
"\r\n",
"
\r\n",
" \r\n",
" Infographic by Dasani Madipalli\r\n",
"\r\n",
"\r\n",
""
],
"metadata": {
"id": "HOCqJXLTwtWI"
}
},
{
"cell_type": "markdown",
"source": [
"Sometimes our data may not have a linear relationship, but we still want to predict an outcome. Polynomial regression can help us make predictions for more complex non-linear relationships.\n",
"\n",
"Take for instance the relationship between the package and price for our pumpkins data set. While sometimes there's a linear relationship between variables - the bigger the pumpkin in volume, the higher the price - sometimes these relationships can't be plotted as a plane or straight line.\n",
"\n",
"> ✅ Here are [some more examples](https://online.stat.psu.edu/stat501/lesson/9/9.8) of data that could use polynomial regression\n",
">\n",
"> Take another look at the relationship between Variety to Price in the previous plot. Does this scatterplot seem like it should necessarily be analyzed by a straight line? Perhaps not. In this case, you can try polynomial regression.\n",
">\n",
"> ✅ Polynomials are mathematical expressions that might consist of one or more variables and coefficients\n",
"\n",
"#### Train a polynomial regression model using the training set\n",
"\n",
"Polynomial regression creates a *curved line* to better fit nonlinear data.\n",
"\n",
"Let's see whether a polynomial model will perform better in making predictions. We'll follow a somewhat similar procedure as we did before:\n",
"\n",
"- Create a recipe that specifies the preprocessing steps that should be carried out on our data to get it ready for modelling i.e: encoding predictors and computing polynomials of degree *n*\n",
"\n",
"- Build a model specification\n",
"\n",
"- Bundle the recipe and model specification into a workflow\n",
"\n",
"- Create a model by fitting the workflow\n",
"\n",
"- Evaluate how well the model performs on the test data\n",
"\n",
"Let's get right into it!\n"
],
"metadata": {
"id": "VcEIpRV9wzYr"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Specify a recipe\r\n",
"poly_pumpkins_recipe <-\r\n",
" recipe(price ~ package, data = pumpkins_train) %>%\r\n",
" step_integer(all_predictors(), zero_based = TRUE) %>% \r\n",
" step_poly(all_predictors(), degree = 4)\r\n",
"\r\n",
"\r\n",
"# Create a model specification\r\n",
"poly_spec <- linear_reg() %>% \r\n",
" set_engine(\"lm\") %>% \r\n",
" set_mode(\"regression\")\r\n",
"\r\n",
"\r\n",
"# Bundle recipe and model spec into a workflow\r\n",
"poly_wf <- workflow() %>% \r\n",
" add_recipe(poly_pumpkins_recipe) %>% \r\n",
" add_model(poly_spec)\r\n",
"\r\n",
"\r\n",
"# Create a model\r\n",
"poly_wf_fit <- poly_wf %>% \r\n",
" fit(data = pumpkins_train)\r\n",
"\r\n",
"\r\n",
"# Print learned model coefficients\r\n",
"poly_wf_fit\r\n",
"\r\n",
" "
],
"outputs": [],
"metadata": {
"id": "63n_YyRXw3CC"
}
},
{
"cell_type": "markdown",
"source": [
"#### Evaluate model performance\n",
"\n",
"👏👏You've built a polynomial model let's make predictions on the test set!"
],
"metadata": {
"id": "-LHZtztSxDP0"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Make price predictions on test data\r\n",
"poly_results <- poly_wf_fit %>% predict(new_data = pumpkins_test) %>% \r\n",
" bind_cols(pumpkins_test %>% select(c(package, price))) %>% \r\n",
" relocate(.pred, .after = last_col())\r\n",
"\r\n",
"\r\n",
"# Print the results\r\n",
"poly_results %>% \r\n",
" slice_head(n = 10)"
],
"outputs": [],
"metadata": {
"id": "YUFpQ_dKxJGx"
}
},
{
"cell_type": "markdown",
"source": [
"Woo-hoo, let's evaluate how the model performed on the test_set using `yardstick::metrics()`."
],
"metadata": {
"id": "qxdyj86bxNGZ"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"metrics(data = poly_results, truth = price, estimate = .pred)"
],
"outputs": [],
"metadata": {
"id": "8AW5ltkBxXDm"
}
},
{
"cell_type": "markdown",
"source": [
"🤩🤩 Much better performance.\n",
"\n",
"The `rmse` decreased from about 7. to about 3. an indication that of a reduced error between the actual price and the predicted price. You can *loosely* interpret this as meaning that on average, incorrect predictions are wrong by around \\$3. The `rsq` increased from about 0.4 to 0.8.\n",
"\n",
"All these metrics indicate that the polynomial model performs way better than the linear model. Good job!\n",
"\n",
"Let's see if we can visualize this!"
],
"metadata": {
"id": "6gLHNZDwxYaS"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Bind encoded package column to the results\r\n",
"poly_results <- poly_results %>% \r\n",
" bind_cols(package_encode %>% \r\n",
" rename(package_integer = package)) %>% \r\n",
" relocate(package_integer, .after = package)\r\n",
"\r\n",
"\r\n",
"# Print new results data frame\r\n",
"poly_results %>% \r\n",
" slice_head(n = 5)\r\n",
"\r\n",
"\r\n",
"# Make a scatter plot\r\n",
"poly_results %>% \r\n",
" ggplot(mapping = aes(x = package_integer, y = price)) +\r\n",
" geom_point(size = 1.6) +\r\n",
" # Overlay a line of best fit\r\n",
" geom_line(aes(y = .pred), color = \"midnightblue\", size = 1.2) +\r\n",
" xlab(\"package\")\r\n"
],
"outputs": [],
"metadata": {
"id": "A83U16frxdF1"
}
},
{
"cell_type": "markdown",
"source": [
"You can see a curved line that fits your data better! 🤩\n",
"\n",
"You can make this more smoother by passing a polynomial formula to `geom_smooth` like this:"
],
"metadata": {
"id": "4U-7aHOVxlGU"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Make a scatter plot\r\n",
"poly_results %>% \r\n",
" ggplot(mapping = aes(x = package_integer, y = price)) +\r\n",
" geom_point(size = 1.6) +\r\n",
" # Overlay a line of best fit\r\n",
" geom_smooth(method = lm, formula = y ~ poly(x, degree = 4), color = \"midnightblue\", size = 1.2, se = FALSE) +\r\n",
" xlab(\"package\")"
],
"outputs": [],
"metadata": {
"id": "5vzNT0Uexm-w"
}
},
{
"cell_type": "markdown",
"source": [
"Much like a smooth curve!🤩\n",
"\n",
"Here's how you would make a new prediction:"
],
"metadata": {
"id": "v9u-wwyLxq4G"
}
},
{
"cell_type": "code",
"execution_count": null,
"source": [
"# Make a hypothetical data frame\r\n",
"hypo_tibble <- tibble(package = \"bushel baskets\")\r\n",
"\r\n",
"# Make predictions using linear model\r\n",
"lm_pred <- lm_wf_fit %>% predict(new_data = hypo_tibble)\r\n",
"\r\n",
"# Make predictions using polynomial model\r\n",
"poly_pred <- poly_wf_fit %>% predict(new_data = hypo_tibble)\r\n",
"\r\n",
"# Return predictions in a list\r\n",
"list(\"linear model prediction\" = lm_pred, \r\n",
" \"polynomial model prediction\" = poly_pred)\r\n"
],
"outputs": [],
"metadata": {
"id": "jRPSyfQGxuQv"
}
},
{
"cell_type": "markdown",
"source": [
"The `polynomial model` prediction does make sense, given the scatter plots of `price` and `package`! And, if this is a better model than the previous one, looking at the same data, you need to budget for these more expensive pumpkins!\n",
"\n",
"🏆 Well done! You created two regression models in one lesson. In the final section on regression, you will learn about logistic regression to determine categories.\n",
"\n",
"## **🚀Challenge**\n",
"\n",
"Test several different variables in this notebook to see how correlation corresponds to model accuracy.\n",
"\n",
"## [**Post-lecture quiz**](https://jolly-sea-0a877260f.azurestaticapps.net/quiz/14/)\n",
"\n",
"## **Review & Self Study**\n",
"\n",
"In this lesson we learned about Linear Regression. There are other important types of Regression. Read about Stepwise, Ridge, Lasso and Elasticnet techniques. A good course to study to learn more is the [Stanford Statistical Learning course](https://online.stanford.edu/courses/sohs-ystatslearning-statistical-learning)\n",
"\n",
"If you want to learn more about how to use the amazing Tidymodels framework, please check out the following resources:\n",
"\n",
"- Tidymodels website: [Get started with Tidymodels](https://www.tidymodels.org/start/)\n",
"\n",
"- Max Kuhn and Julia Silge, [*Tidy Modeling with R*](https://www.tmwr.org/)*.*\n",
"\n",
"###### **THANK YOU TO:**\n",
"\n",
"[Allison Horst](https://twitter.com/allison_horst?lang=en) for creating the amazing illustrations that make R more welcoming and engaging. Find more illustrations at her [gallery](https://www.google.com/url?q=https://github.com/allisonhorst/stats-illustrations&sa=D&source=editors&ust=1626380772530000&usg=AOvVaw3zcfyCizFQZpkSLzxiiQEM).\n"
],
"metadata": {
"id": "8zOLOWqMxzk5"
}
}
]
}
 \r\n",
"
\r\n",
"  \r\n",
"
\r\n",
"  \r\n",
"
\r\n",
"