# Construir uma Aplicação Web de Recomendação de Culinária
Nesta lição, vais construir um modelo de classificação utilizando algumas das técnicas que aprendeste em lições anteriores e com o delicioso conjunto de dados de culinária usado ao longo desta série. Além disso, vais criar uma pequena aplicação web para usar um modelo guardado, aproveitando o runtime web do Onnx.
Uma das utilizações mais práticas da aprendizagem automática é a construção de sistemas de recomendação, e hoje podes dar o primeiro passo nessa direção!
[](https://youtu.be/17wdM9AHMfg "ML Aplicada")
> 🎥 Clica na imagem acima para ver um vídeo: Jen Looper constrói uma aplicação web usando dados de culinária classificados
## [Questionário pré-aula](https://ff-quizzes.netlify.app/en/ml/)
Nesta lição vais aprender:
- Como construir um modelo e guardá-lo como um modelo Onnx
- Como usar o Netron para inspecionar o modelo
- Como usar o teu modelo numa aplicação web para inferência
## Construir o teu modelo
Construir sistemas de ML aplicados é uma parte importante para aproveitar estas tecnologias nos sistemas empresariais. Podes usar modelos dentro das tuas aplicações web (e assim utilizá-los num contexto offline, se necessário) ao usar Onnx.
Numa [lição anterior](../../3-Web-App/1-Web-App/README.md), construíste um modelo de regressão sobre avistamentos de OVNIs, "pickled" o modelo e usaste-o numa aplicação Flask. Embora esta arquitetura seja muito útil, trata-se de uma aplicação Python full-stack, e os teus requisitos podem incluir o uso de uma aplicação JavaScript.
Nesta lição, podes construir um sistema básico baseado em JavaScript para inferência. Primeiro, no entanto, precisas de treinar um modelo e convertê-lo para uso com Onnx.
## Exercício - treinar modelo de classificação
Primeiro, treina um modelo de classificação usando o conjunto de dados de culinária limpo que utilizámos.
1. Começa por importar bibliotecas úteis:
```python
!pip install skl2onnx
import pandas as pd
```
Vais precisar de '[skl2onnx](https://onnx.ai/sklearn-onnx/)' para ajudar a converter o teu modelo Scikit-learn para o formato Onnx.
1. Depois, trabalha com os teus dados da mesma forma que fizeste em lições anteriores, lendo um ficheiro CSV usando `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. Remove as duas primeiras colunas desnecessárias e guarda os dados restantes como 'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. Guarda os rótulos como 'y':
```python
y = data[['cuisine']]
y.head()
```
### Iniciar a rotina de treino
Vamos usar a biblioteca 'SVC', que tem boa precisão.
1. Importa as bibliotecas apropriadas do Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. Separa os conjuntos de treino e teste:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. Constrói um modelo de classificação SVC como fizeste na lição anterior:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. Agora, testa o teu modelo, chamando `predict()`:
```python
y_pred = model.predict(X_test)
```
1. Imprime um relatório de classificação para verificar a qualidade do modelo:
```python
print(classification_report(y_test,y_pred))
```
Como vimos antes, a precisão é boa:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### Converter o teu modelo para Onnx
Certifica-te de fazer a conversão com o número correto de tensores. Este conjunto de dados tem 380 ingredientes listados, por isso precisas de indicar esse número em `FloatTensorType`:
1. Converte usando um número de tensor de 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. Cria o ficheiro onx e guarda-o como **model.onnx**:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> Nota, podes passar [opções](https://onnx.ai/sklearn-onnx/parameterized.html) no teu script de conversão. Neste caso, passámos 'nocl' como True e 'zipmap' como False. Como este é um modelo de classificação, tens a opção de remover ZipMap, que produz uma lista de dicionários (não necessário). `nocl` refere-se à inclusão de informações de classe no modelo. Reduz o tamanho do teu modelo ao definir `nocl` como 'True'.
Executar o notebook completo agora irá construir um modelo Onnx e guardá-lo nesta pasta.
## Visualizar o teu modelo
Os modelos Onnx não são muito visíveis no Visual Studio Code, mas há um software gratuito muito bom que muitos investigadores utilizam para visualizar o modelo e garantir que foi construído corretamente. Faz o download do [Netron](https://github.com/lutzroeder/Netron) e abre o ficheiro model.onnx. Podes ver o teu modelo simples visualizado, com os seus 380 inputs e o classificador listado:
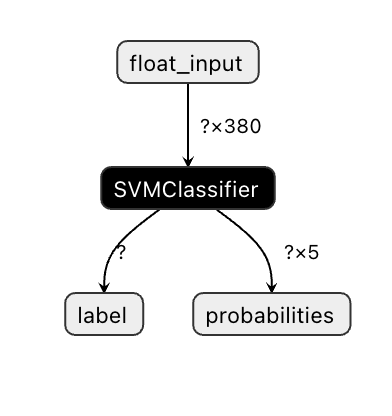
Netron é uma ferramenta útil para visualizar os teus modelos.
Agora estás pronto para usar este modelo interessante numa aplicação web. Vamos construir uma aplicação que será útil quando olhares para o teu frigorífico e tentares descobrir qual combinação de ingredientes sobrantes podes usar para cozinhar um prato específico, conforme determinado pelo teu modelo.
## Construir uma aplicação web de recomendação
Podes usar o teu modelo diretamente numa aplicação web. Esta arquitetura também permite que o modelo seja executado localmente e até offline, se necessário. Começa por criar um ficheiro `index.html` na mesma pasta onde guardaste o teu ficheiro `model.onnx`.
1. Neste ficheiro _index.html_, adiciona a seguinte marcação:
```html
Cuisine Matcher
...
```
1. Agora, dentro das tags `body`, adiciona uma pequena marcação para mostrar uma lista de caixas de seleção que refletem alguns ingredientes:
```html
Check your refrigerator. What can you create?
```
Repara que cada caixa de seleção tem um valor. Este valor reflete o índice onde o ingrediente é encontrado de acordo com o conjunto de dados. A maçã, por exemplo, nesta lista alfabética, ocupa a quinta coluna, por isso o seu valor é '4', já que começamos a contar a partir de 0. Podes consultar a [folha de cálculo de ingredientes](../../../../4-Classification/data/ingredient_indexes.csv) para descobrir o índice de um determinado ingrediente.
Continuando o teu trabalho no ficheiro index.html, adiciona um bloco de script onde o modelo é chamado após o último ``.
1. Primeiro, importa o [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> O Onnx Runtime é usado para permitir a execução dos teus modelos Onnx em uma ampla gama de plataformas de hardware, incluindo otimizações e uma API para uso.
1. Uma vez que o Runtime esteja em funcionamento, podes chamá-lo:
```html
```
Neste código, várias coisas estão a acontecer:
1. Criaste um array de 380 valores possíveis (1 ou 0) para serem definidos e enviados ao modelo para inferência, dependendo de se uma caixa de seleção de ingrediente está marcada.
2. Criaste um array de caixas de seleção e uma forma de determinar se foram marcadas numa função `init` que é chamada quando a aplicação começa. Quando uma caixa de seleção é marcada, o array `ingredients` é alterado para refletir o ingrediente escolhido.
3. Criaste uma função `testCheckboxes` que verifica se alguma caixa de seleção foi marcada.
4. Usas a função `startInference` quando o botão é pressionado e, se alguma caixa de seleção estiver marcada, inicias a inferência.
5. A rotina de inferência inclui:
1. Configurar um carregamento assíncrono do modelo
2. Criar uma estrutura Tensor para enviar ao modelo
3. Criar 'feeds' que refletem o input `float_input` que criaste ao treinar o teu modelo (podes usar o Netron para verificar esse nome)
4. Enviar esses 'feeds' ao modelo e aguardar uma resposta
## Testar a tua aplicação
Abre uma sessão de terminal no Visual Studio Code na pasta onde o teu ficheiro index.html está localizado. Certifica-te de que tens [http-server](https://www.npmjs.com/package/http-server) instalado globalmente e escreve `http-server` no prompt. Um localhost deve abrir e podes visualizar a tua aplicação web. Verifica qual culinária é recomendada com base em vários ingredientes:

Parabéns, criaste uma aplicação web de 'recomendação' com alguns campos. Dedica algum tempo a expandir este sistema!
## 🚀Desafio
A tua aplicação web é muito minimalista, por isso continua a expandi-la usando ingredientes e os seus índices a partir dos dados [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv). Quais combinações de sabores funcionam para criar um prato nacional específico?
## [Questionário pós-aula](https://ff-quizzes.netlify.app/en/ml/)
## Revisão & Autoestudo
Embora esta lição tenha apenas tocado na utilidade de criar um sistema de recomendação para ingredientes alimentares, esta área de aplicações de ML é muito rica em exemplos. Lê mais sobre como estes sistemas são construídos:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## Tarefa
[Constrói um novo sistema de recomendação](assignment.md)
---
**Aviso Legal**:
Este documento foi traduzido utilizando o serviço de tradução por IA [Co-op Translator](https://github.com/Azure/co-op-translator). Embora nos esforcemos para garantir a precisão, é importante notar que traduções automáticas podem conter erros ou imprecisões. O documento original na sua língua nativa deve ser considerado a fonte autoritária. Para informações críticas, recomenda-se uma tradução profissional realizada por humanos. Não nos responsabilizamos por quaisquer mal-entendidos ou interpretações incorretas decorrentes da utilização desta tradução.