# Створення веб-додатку для рекомендацій кухні
У цьому уроці ви створите модель класифікації, використовуючи деякі техніки, які ви вивчили в попередніх уроках, а також смачний набір даних про кухні, який використовувався протягом цієї серії. Крім того, ви створите невеликий веб-додаток для використання збереженої моделі, використовуючи веб-рантайм Onnx.
Одним із найкорисніших практичних застосувань машинного навчання є створення систем рекомендацій, і сьогодні ви можете зробити перший крок у цьому напрямку!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 Натисніть на зображення вище, щоб переглянути відео: Джен Лупер створює веб-додаток, використовуючи дані класифікованих кухонь
## [Тест перед лекцією](https://ff-quizzes.netlify.app/en/ml/)
У цьому уроці ви дізнаєтеся:
- Як створити модель та зберегти її у форматі Onnx
- Як використовувати Netron для перевірки моделі
- Як використовувати вашу модель у веб-додатку для інференсу
## Створення вашої моделі
Створення прикладних систем машинного навчання є важливою частиною використання цих технологій для ваших бізнес-систем. Ви можете використовувати моделі у своїх веб-додатках (а отже, використовувати їх в офлайн-режимі, якщо це необхідно), використовуючи Onnx.
У [попередньому уроці](../../3-Web-App/1-Web-App/README.md) ви створили модель регресії про спостереження НЛО, "запакували" її та використали у додатку Flask. Хоча ця архітектура дуже корисна, це повноцінний Python-додаток, і ваші вимоги можуть включати використання JavaScript-додатку.
У цьому уроці ви можете створити базову систему на основі JavaScript для інференсу. Спочатку, однак, вам потрібно навчити модель і конвертувати її для використання з Onnx.
## Вправа - навчання моделі класифікації
Спочатку навчіть модель класифікації, використовуючи очищений набір даних про кухні, який ми використовували.
1. Почніть з імпорту корисних бібліотек:
```python
!pip install skl2onnx
import pandas as pd
```
Вам потрібен '[skl2onnx](https://onnx.ai/sklearn-onnx/)', щоб допомогти конвертувати вашу модель Scikit-learn у формат Onnx.
1. Потім працюйте з вашими даними так само, як ви робили в попередніх уроках, читаючи CSV-файл за допомогою `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. Видаліть перші два непотрібні стовпці та збережіть решту даних як 'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. Збережіть мітки як 'y':
```python
y = data[['cuisine']]
y.head()
```
### Початок процедури навчання
Ми будемо використовувати бібліотеку 'SVC', яка має хорошу точність.
1. Імпортуйте відповідні бібліотеки з Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. Розділіть дані на навчальний та тестовий набори:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. Створіть модель класифікації SVC, як ви робили в попередньому уроці:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. Тепер протестуйте вашу модель, викликавши `predict()`:
```python
y_pred = model.predict(X_test)
```
1. Виведіть звіт про класифікацію, щоб перевірити якість моделі:
```python
print(classification_report(y_test,y_pred))
```
Як ми бачили раніше, точність хороша:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### Конвертуйте вашу модель у формат Onnx
Переконайтеся, що конвертація виконується з правильним числом тензорів. У цьому наборі даних є 380 інгредієнтів, тому вам потрібно зазначити це число у `FloatTensorType`:
1. Конвертуйте, використовуючи число тензорів 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. Створіть файл **model.onnx**:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> Зверніть увагу, що ви можете передати [опції](https://onnx.ai/sklearn-onnx/parameterized.html) у вашому скрипті конвертації. У цьому випадку ми передали 'nocl', щоб він був True, і 'zipmap', щоб він був False. Оскільки це модель класифікації, у вас є опція видалити ZipMap, який створює список словників (необов'язково). `nocl` стосується включення інформації про класи у модель. Зменшіть розмір вашої моделі, встановивши `nocl` на 'True'.
Запуск всього ноутбука тепер створить модель Onnx і збереже її у цій папці.
## Перегляд вашої моделі
Моделі Onnx не дуже зручні для перегляду у Visual Studio Code, але є дуже хороше безкоштовне програмне забезпечення, яке багато дослідників використовують для візуалізації моделі, щоб переконатися, що вона правильно побудована. Завантажте [Netron](https://github.com/lutzroeder/Netron) і відкрийте ваш файл model.onnx. Ви можете побачити вашу просту модель, візуалізовану з її 380 входами та класифікатором:

Netron — це корисний інструмент для перегляду ваших моделей.
Тепер ви готові використовувати цю чудову модель у веб-додатку. Давайте створимо додаток, який стане в нагоді, коли ви заглянете у свій холодильник і спробуєте визначити, яку комбінацію залишків інгредієнтів ви можете використати для приготування певної кухні, як визначено вашою моделлю.
## Створення веб-додатку для рекомендацій
Ви можете використовувати вашу модель безпосередньо у веб-додатку. Ця архітектура також дозволяє запускати її локально і навіть офлайн, якщо це необхідно. Почніть зі створення файлу `index.html` у тій самій папці, де ви зберегли ваш файл `model.onnx`.
1. У цьому файлі _index.html_ додайте наступну розмітку:
```html
Cuisine Matcher
...
```
1. Тепер, працюючи всередині тегів `body`, додайте трохи розмітки, щоб показати список чекбоксів, що відображають деякі інгредієнти:
```html
Check your refrigerator. What can you create?
```
Зверніть увагу, що кожному чекбоксу присвоєно значення. Це відображає індекс, де інгредієнт знаходиться відповідно до набору даних. Наприклад, яблуко у цьому алфавітному списку займає п'ятий стовпець, тому його значення — '4', оскільки ми починаємо рахувати з 0. Ви можете звернутися до [електронної таблиці інгредієнтів](../../../../4-Classification/data/ingredient_indexes.csv), щоб дізнатися індекс певного інгредієнта.
Продовжуючи роботу у файлі index.html, додайте блок скрипту, де модель викликається після останнього закриваючого ``.
1. Спочатку імпортуйте [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> Onnx Runtime використовується для запуску ваших моделей Onnx на широкому спектрі апаратних платформ, включаючи оптимізації та API для використання.
1. Як тільки Runtime встановлено, ви можете викликати його:
```html
```
У цьому коді відбувається кілька речей:
1. Ви створили масив із 380 можливих значень (1 або 0), які будуть встановлені та відправлені до моделі для інференсу залежно від того, чи вибрано чекбокс.
2. Ви створили масив чекбоксів і спосіб визначити, чи вони були вибрані, у функції `init`, яка викликається при запуску додатку. Коли чекбокс вибрано, масив `ingredients` змінюється, щоб відобразити вибраний інгредієнт.
3. Ви створили функцію `testCheckboxes`, яка перевіряє, чи вибрано будь-який чекбокс.
4. Ви використовуєте функцію `startInference`, коли натискається кнопка, і якщо вибрано будь-який чекбокс, ви починаєте інференс.
5. Рутинна процедура інференсу включає:
1. Налаштування асинхронного завантаження моделі
2. Створення структури Tensor для відправки до моделі
3. Створення 'feeds', які відображають вхідний `float_input`, створений вами при навчанні моделі (ви можете використовувати Netron, щоб перевірити цю назву)
4. Відправлення цих 'feeds' до моделі та очікування відповіді
## Тестування вашого додатку
Відкрийте термінал у Visual Studio Code у папці, де знаходиться ваш файл index.html. Переконайтеся, що у вас встановлено [http-server](https://www.npmjs.com/package/http-server) глобально, і введіть `http-server` у командному рядку. Локальний хост має відкритися, і ви можете переглянути ваш веб-додаток. Перевірте, яку кухню рекомендують на основі різних інгредієнтів:
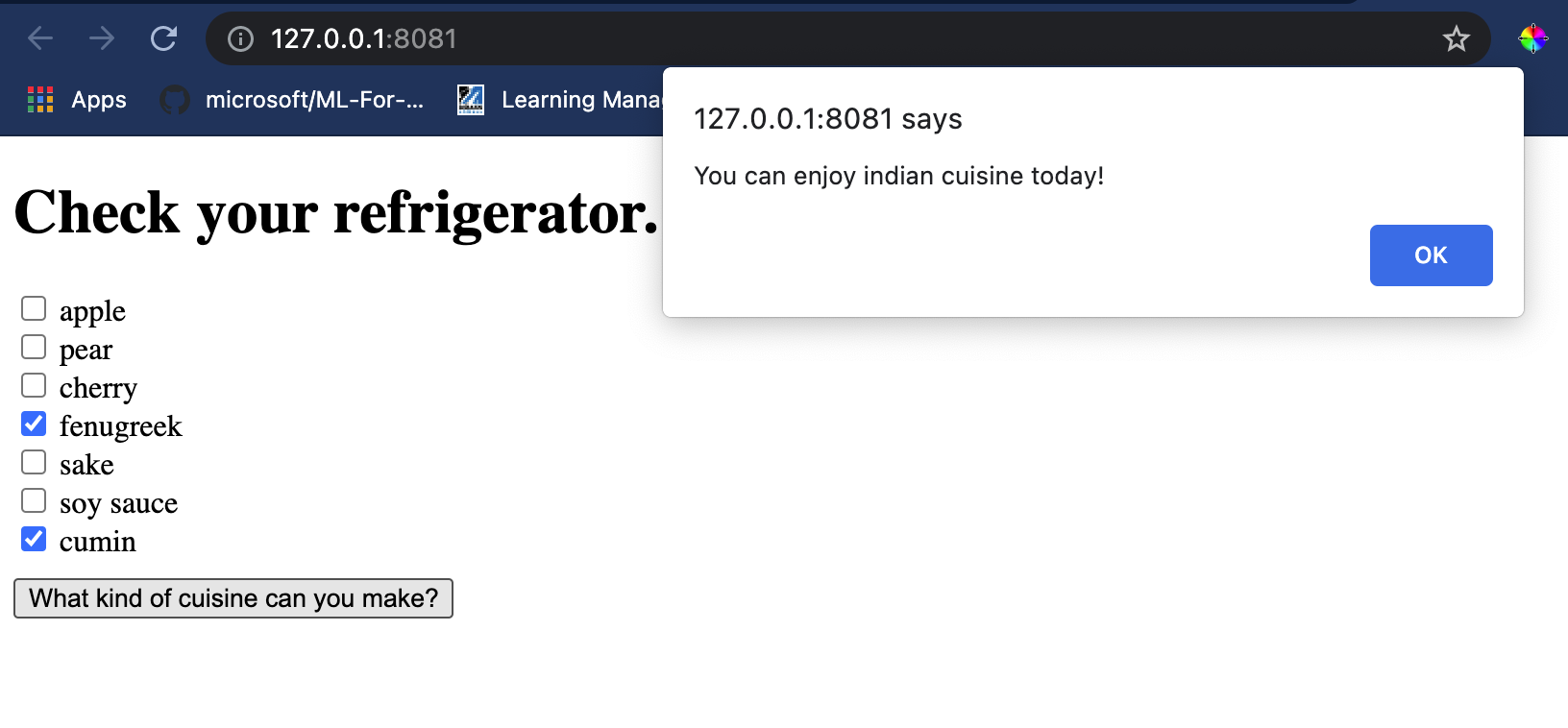
Вітаємо, ви створили веб-додаток для рекомендацій із кількома полями. Приділіть трохи часу, щоб розширити цю систему!
## 🚀Завдання
Ваш веб-додаток дуже мінімальний, тому продовжуйте розширювати його, використовуючи інгредієнти та їх індекси з даних [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv). Які комбінації смаків працюють для створення певної національної страви?
## [Тест після лекції](https://ff-quizzes.netlify.app/en/ml/)
## Огляд і самостійне навчання
Хоча цей урок лише торкнувся корисності створення системи рекомендацій для інгредієнтів їжі, ця область застосування ML дуже багата на приклади. Прочитайте більше про те, як створюються ці системи:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## Завдання
[Створіть нову систему рекомендацій](assignment.md)
---
**Відмова від відповідальності**:
Цей документ було перекладено за допомогою сервісу автоматичного перекладу [Co-op Translator](https://github.com/Azure/co-op-translator). Хоча ми прагнемо до точності, зверніть увагу, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ мовою оригіналу слід вважати авторитетним джерелом. Для критично важливої інформації рекомендується професійний людський переклад. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникли внаслідок використання цього перекладу.