# Doğal Dil İşleme Görevleri ve Teknikleri
Çoğu *doğal dil işleme* görevi için işlenecek metin parçalanmalı, incelenmeli ve sonuçlar kurallar ve veri setleriyle saklanmalı veya çapraz referans yapılmalıdır. Bu görevler, programcının bir metindeki _anlamı_, _niyeti_ veya yalnızca _terimlerin ve kelimelerin sıklığını_ çıkarmasına olanak tanır.
## [Ders Öncesi Test](https://ff-quizzes.netlify.app/en/ml/)
Metin işleme sırasında kullanılan yaygın teknikleri keşfedelim. Makine öğrenimi ile birleştirildiğinde, bu teknikler büyük miktarda metni verimli bir şekilde analiz etmenize yardımcı olur. Ancak, bu görevlerde ML uygulamadan önce, bir NLP uzmanının karşılaştığı sorunları anlamamız gerekiyor.
## NLP'ye Özgü Görevler
Üzerinde çalıştığınız bir metni analiz etmenin farklı yolları vardır. Gerçekleştirebileceğiniz görevler vardır ve bu görevler aracılığıyla metni anlamaya yönelik bir fikir edinebilir ve sonuçlar çıkarabilirsiniz. Genellikle bu görevleri bir sırayla gerçekleştirirsiniz.
### Tokenizasyon
Muhtemelen çoğu NLP algoritmasının yapması gereken ilk şey, metni tokenlara veya kelimelere ayırmaktır. Bu basit gibi görünse de, noktalama işaretleri ve farklı dillerin kelime ve cümle sınırlarını hesaba katmak işleri zorlaştırabilir. Sınırları belirlemek için çeşitli yöntemler kullanmanız gerekebilir.
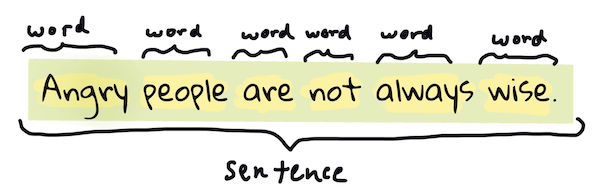
> **Pride and Prejudice** kitabından bir cümleyi tokenlere ayırma. [Jen Looper](https://twitter.com/jenlooper) tarafından hazırlanan infografik.
### Gömülü Temsiller
[Kelime gömülü temsilleri](https://wikipedia.org/wiki/Word_embedding), metin verilerinizi sayısal olarak dönüştürmenin bir yoludur. Gömülü temsiller, benzer anlamlara sahip kelimelerin veya birlikte kullanılan kelimelerin bir arada kümelenmesi şeklinde yapılır.

> "I have the highest respect for your nerves, they are my old friends." - **Pride and Prejudice** kitabından bir cümle için kelime gömülü temsilleri. [Jen Looper](https://twitter.com/jenlooper) tarafından hazırlanan infografik.
✅ [Bu ilginç aracı](https://projector.tensorflow.org/) deneyerek kelime gömülü temsilleriyle deney yapabilirsiniz. Bir kelimeye tıklamak, 'toy' kelimesinin 'disney', 'lego', 'playstation' ve 'console' ile kümelendiği gibi benzer kelimelerin kümelerini gösterir.
### Ayrıştırma ve Sözcük Türü Etiketleme
Tokenize edilmiş her kelime, bir isim, fiil veya sıfat gibi bir sözcük türü olarak etiketlenebilir. `the quick red fox jumped over the lazy brown dog` cümlesi POS olarak şu şekilde etiketlenebilir: fox = isim, jumped = fiil.

> **Pride and Prejudice** kitabından bir cümleyi ayrıştırma. [Jen Looper](https://twitter.com/jenlooper) tarafından hazırlanan infografik.
Ayrıştırma, bir cümledeki kelimelerin birbirleriyle nasıl ilişkili olduğunu tanımaktır - örneğin `the quick red fox jumped` sıfat-isim-fiil dizisi, `lazy brown dog` dizisinden ayrı bir dizidir.
### Kelime ve İfade Sıklıkları
Büyük bir metin gövdesini analiz ederken yararlı bir prosedür, ilgi çekici her kelime veya ifadenin bir sözlüğünü oluşturmak ve ne sıklıkla göründüğünü belirlemektir. `the quick red fox jumped over the lazy brown dog` ifadesi için "the" kelimesinin sıklığı 2'dir.
Kelime sıklıklarını saydığımız bir örnek metne bakalım. Rudyard Kipling'in The Winners adlı şiiri şu dizeyi içerir:
```output
What the moral? Who rides may read.
When the night is thick and the tracks are blind
A friend at a pinch is a friend, indeed,
But a fool to wait for the laggard behind.
Down to Gehenna or up to the Throne,
He travels the fastest who travels alone.
```
İfade sıklıkları gerektiğinde büyük/küçük harf duyarlı veya duyarsız olabilir. Örneğin, `a friend` ifadesinin sıklığı 2, `the` ifadesinin sıklığı 6 ve `travels` ifadesinin sıklığı 2'dir.
### N-gramlar
Bir metin, belirli bir uzunlukta kelime dizilerine bölünebilir: tek kelime (unigram), iki kelime (bigram), üç kelime (trigram) veya herhangi bir kelime sayısı (n-gram).
Örneğin, `the quick red fox jumped over the lazy brown dog` cümlesi için n-gram skoru 2 olduğunda şu n-gramlar üretilir:
1. the quick
2. quick red
3. red fox
4. fox jumped
5. jumped over
6. over the
7. the lazy
8. lazy brown
9. brown dog
Bunu bir cümle üzerinde kayan bir kutu olarak görselleştirmek daha kolay olabilir. İşte 3 kelimelik n-gramlar için bir örnek, her cümlede n-gram kalın olarak gösterilmiştir:
1. **the quick red** fox jumped over the lazy brown dog
2. the **quick red fox** jumped over the lazy brown dog
3. the quick **red fox jumped** over the lazy brown dog
4. the quick red **fox jumped over** the lazy brown dog
5. the quick red fox **jumped over the** lazy brown dog
6. the quick red fox jumped **over the lazy** brown dog
7. the quick red fox jumped over **the lazy brown** dog
8. the quick red fox jumped over the **lazy brown dog**

> N-gram değeri 3: [Jen Looper](https://twitter.com/jenlooper) tarafından hazırlanan infografik.
### İsim İfadesi Çıkarımı
Çoğu cümlede, cümlenin öznesi veya nesnesi olan bir isim vardır. İngilizcede genellikle 'a', 'an' veya 'the' ile tanımlanabilir. Bir cümlenin anlamını anlamaya çalışırken 'isim ifadesini çıkarmak', NLP'de yaygın bir görevdir.
✅ "I cannot fix on the hour, or the spot, or the look or the words, which laid the foundation. It is too long ago. I was in the middle before I knew that I had begun." cümlesinde isim ifadelerini belirleyebilir misiniz?
`the quick red fox jumped over the lazy brown dog` cümlesinde 2 isim ifadesi vardır: **quick red fox** ve **lazy brown dog**.
### Duygu Analizi
Bir cümle veya metin, ne kadar *pozitif* veya *negatif* olduğu açısından analiz edilebilir. Duygu, *kutupluluk* ve *nesnellik/öznelik* açısından ölçülür. Kutupluluk -1.0 ile 1.0 arasında (negatiften pozitife) ve 0.0 ile 1.0 arasında (en nesnelden en öznel) ölçülür.
✅ Daha sonra makine öğrenimi kullanarak duygu belirlemenin farklı yollarını öğreneceksiniz, ancak bir yol, bir insan uzman tarafından pozitif veya negatif olarak kategorize edilen kelime ve ifadelerden oluşan bir listeye sahip olmak ve bu modeli metne uygulayarak bir kutupluluk skoru hesaplamaktır. Bunun bazı durumlarda nasıl işe yarayacağını ve diğer durumlarda neden daha az etkili olacağını görebiliyor musunuz?
### Çekim
Çekim, bir kelimeyi alıp kelimenin tekil veya çoğul halini elde etmenizi sağlar.
### Lemmatizasyon
Bir *lemma*, bir kelime grubunun kökü veya ana kelimesidir. Örneğin, *flew*, *flies*, *flying* kelimelerinin lemması fiil olan *fly*dır.
NLP araştırmacıları için kullanışlı veritabanları da mevcuttur, özellikle:
### WordNet
[WordNet](https://wordnet.princeton.edu/), birçok farklı dildeki her kelime için eş anlamlılar, zıt anlamlılar ve diğer birçok ayrıntıyı içeren bir kelime veritabanıdır. Çeviriler, yazım denetleyiciler veya herhangi bir türde dil araçları oluştururken son derece kullanışlıdır.
## NLP Kütüphaneleri
Neyse ki, bu tekniklerin hepsini kendiniz oluşturmanız gerekmiyor, çünkü doğal dil işleme veya makine öğrenimi konusunda uzman olmayan geliştiriciler için çok daha erişilebilir hale getiren mükemmel Python kütüphaneleri mevcut. Bir sonraki derslerde bunların daha fazla örneğini göreceksiniz, ancak burada bir sonraki görevinizde size yardımcı olacak bazı kullanışlı örnekler öğreneceksiniz.
### Egzersiz - `TextBlob` kütüphanesini kullanma
TextBlob adlı bir kütüphaneyi kullanalım çünkü bu tür görevlerle başa çıkmak için kullanışlı API'ler içeriyor. TextBlob "[NLTK](https://nltk.org) ve [pattern](https://github.com/clips/pattern) gibi devlerin omuzlarında durur ve her ikisiyle de uyumlu çalışır." API'sinde önemli miktarda ML gömülüdür.
> Not: Deneyimli Python geliştiricileri için önerilen bir [Hızlı Başlangıç](https://textblob.readthedocs.io/en/dev/quickstart.html#quickstart) kılavuzu TextBlob için mevcuttur.
*İsim ifadelerini* tanımlamaya çalışırken, TextBlob isim ifadelerini bulmak için birkaç çıkarıcı seçeneği sunar.
1. `ConllExtractor`'a bir göz atın.
```python
from textblob import TextBlob
from textblob.np_extractors import ConllExtractor
# import and create a Conll extractor to use later
extractor = ConllExtractor()
# later when you need a noun phrase extractor:
user_input = input("> ")
user_input_blob = TextBlob(user_input, np_extractor=extractor) # note non-default extractor specified
np = user_input_blob.noun_phrases
```
> Burada neler oluyor? [ConllExtractor](https://textblob.readthedocs.io/en/dev/api_reference.html?highlight=Conll#textblob.en.np_extractors.ConllExtractor), "ConLL-2000 eğitim veri kümesiyle eğitilmiş chunk parsing kullanan bir isim ifade çıkarıcıdır." ConLL-2000, 2000 yılında düzenlenen Hesaplamalı Doğal Dil Öğrenme Konferansı'na atıfta bulunur. Her yıl konferans, zorlu bir NLP sorununu ele almak için bir atölye çalışması düzenledi ve 2000 yılında bu sorun isim chunking idi. Bir model Wall Street Journal üzerinde eğitildi, "15-18 bölümleri eğitim verisi (211727 token) ve 20. bölüm test verisi (47377 token) olarak kullanıldı". Kullanılan prosedürlere [buradan](https://www.clips.uantwerpen.be/conll2000/chunking/) ve [sonuçlara](https://ifarm.nl/erikt/research/np-chunking.html) göz atabilirsiniz.
### Zorluk - NLP ile botunuzu geliştirme
Önceki derste çok basit bir Soru-Cevap botu oluşturmuştunuz. Şimdi, Marvin'i biraz daha sempatik hale getirerek girdinizi analiz edip duyguya uygun bir yanıt yazdırmasını sağlayacaksınız. Ayrıca bir `noun_phrase` tespit edip onun hakkında soru sormanız gerekecek.
Daha iyi bir konuşma botu oluştururken adımlarınız:
1. Kullanıcıya botla nasıl etkileşim kuracağına dair talimatları yazdırın
2. Döngüyü başlatın
1. Kullanıcı girdisini kabul edin
2. Kullanıcı çıkmak istediğini belirtirse çıkın
3. Kullanıcı girdisini işleyin ve uygun duygu yanıtını belirleyin
4. Eğer duygu içinde bir isim ifadesi tespit edilirse, bunu çoğullaştırın ve o konu hakkında daha fazla girdi isteyin
5. Yanıtı yazdırın
3. 2. adıma geri dönün
TextBlob kullanarak duygu belirlemek için kod snippet'i aşağıdadır. Duygu yanıtlarının yalnızca dört *gradyanı* vardır (isterseniz daha fazla ekleyebilirsiniz):
```python
if user_input_blob.polarity <= -0.5:
response = "Oh dear, that sounds bad. "
elif user_input_blob.polarity <= 0:
response = "Hmm, that's not great. "
elif user_input_blob.polarity <= 0.5:
response = "Well, that sounds positive. "
elif user_input_blob.polarity <= 1:
response = "Wow, that sounds great. "
```
İşte size rehberlik edecek örnek bir çıktı (kullanıcı girdisi > ile başlayan satırlarda):
```output
Hello, I am Marvin, the friendly robot.
You can end this conversation at any time by typing 'bye'
After typing each answer, press 'enter'
How are you today?
> I am ok
Well, that sounds positive. Can you tell me more?
> I went for a walk and saw a lovely cat
Well, that sounds positive. Can you tell me more about lovely cats?
> cats are the best. But I also have a cool dog
Wow, that sounds great. Can you tell me more about cool dogs?
> I have an old hounddog but he is sick
Hmm, that's not great. Can you tell me more about old hounddogs?
> bye
It was nice talking to you, goodbye!
```
Görev için olası bir çözüm [burada](https://github.com/microsoft/ML-For-Beginners/blob/main/6-NLP/2-Tasks/solution/bot.py)
✅ Bilgi Kontrolü
1. Sempatik yanıtların birinin botun gerçekten kendisini anladığını düşünmesini sağlayabileceğini düşünüyor musunuz?
2. İsim ifadesini belirlemek botu daha 'inandırıcı' hale getiriyor mu?
3. Bir cümleden 'isim ifadesi' çıkarmak neden yararlı bir şey olabilir?
---
Önceki bilgi kontrolündeki botu uygulayın ve bir arkadaşınız üzerinde test edin. Bot onları kandırabilir mi? Botunuzu daha 'inandırıcı' hale getirebilir misiniz?
## 🚀Zorluk
Önceki bilgi kontrolündeki bir görevi alın ve uygulamaya çalışın. Botu bir arkadaşınız üzerinde test edin. Bot onları kandırabilir mi? Botunuzu daha 'inandırıcı' hale getirebilir misiniz?
## [Ders Sonrası Test](https://ff-quizzes.netlify.app/en/ml/)
## Gözden Geçirme ve Kendi Kendine Çalışma
Sonraki birkaç derste duygu analizi hakkında daha fazla bilgi edineceksiniz. [KDNuggets](https://www.kdnuggets.com/tag/nlp) gibi makalelerde bu ilginç tekniği araştırın.
## Ödev
[Botun Konuşmasını Sağla](assignment.md)
---
**Feragatname**:
Bu belge, AI çeviri hizmeti [Co-op Translator](https://github.com/Azure/co-op-translator) kullanılarak çevrilmiştir. Doğruluk için çaba göstersek de, otomatik çevirilerin hata veya yanlışlıklar içerebileceğini lütfen unutmayın. Belgenin orijinal dili, yetkili kaynak olarak kabul edilmelidir. Kritik bilgiler için profesyonel insan çevirisi önerilir. Bu çevirinin kullanımından kaynaklanan yanlış anlamalar veya yanlış yorumlamalar için sorumluluk kabul etmiyoruz.