# Jenga Programu ya Wavuti ya Mapendekezo ya Vyakula
Katika somo hili, utajenga mfano wa uainishaji kwa kutumia baadhi ya mbinu ulizojifunza katika masomo ya awali na kwa kutumia seti ya data ya vyakula vitamu iliyotumika katika mfululizo huu. Zaidi ya hayo, utajenga programu ndogo ya wavuti kutumia mfano uliosajiliwa, ukitumia Onnx's web runtime.
Moja ya matumizi muhimu ya kujifunza kwa mashine ni kujenga mifumo ya mapendekezo, na leo unaweza kuchukua hatua ya kwanza kuelekea mwelekeo huo!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 Bofya picha hapo juu kwa video: Jen Looper anajenga programu ya wavuti kwa kutumia data ya vyakula vilivyowekwa daraja
## [Jaribio la kabla ya somo](https://ff-quizzes.netlify.app/en/ml/)
Katika somo hili utajifunza:
- Jinsi ya kujenga mfano na kuuhifadhi kama mfano wa Onnx
- Jinsi ya kutumia Netron kukagua mfano
- Jinsi ya kutumia mfano wako katika programu ya wavuti kwa ajili ya utabiri
## Jenga mfano wako
Kujenga mifumo ya ML inayotumika ni sehemu muhimu ya kutumia teknolojia hizi katika mifumo ya biashara yako. Unaweza kutumia mifano ndani ya programu zako za wavuti (na hivyo kuitumia katika muktadha wa nje ya mtandao ikiwa inahitajika) kwa kutumia Onnx.
Katika [somo la awali](../../3-Web-App/1-Web-App/README.md), ulijenga mfano wa Regression kuhusu matukio ya UFO, "ukapickle" na kuutumia katika programu ya Flask. Ingawa usanifu huu ni muhimu kujua, ni programu kamili ya Python, na mahitaji yako yanaweza kujumuisha matumizi ya programu ya JavaScript.
Katika somo hili, unaweza kujenga mfumo wa msingi wa JavaScript kwa ajili ya utabiri. Kwanza, hata hivyo, unahitaji kufundisha mfano na kuubadilisha kwa matumizi na Onnx.
## Zoezi - fundisha mfano wa uainishaji
Kwanza, fundisha mfano wa uainishaji kwa kutumia seti ya data ya vyakula vilivyotakaswa tuliyotumia.
1. Anza kwa kuingiza maktaba muhimu:
```python
!pip install skl2onnx
import pandas as pd
```
Unahitaji '[skl2onnx](https://onnx.ai/sklearn-onnx/)' kusaidia kubadilisha mfano wako wa Scikit-learn kuwa muundo wa Onnx.
1. Kisha, fanya kazi na data yako kwa njia ile ile ulivyofanya katika masomo ya awali, kwa kusoma faili ya CSV kwa kutumia `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. Ondoa safu mbili za kwanza zisizo za lazima na uhifadhi data iliyobaki kama 'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. Hifadhi lebo kama 'y':
```python
y = data[['cuisine']]
y.head()
```
### Anza utaratibu wa mafunzo
Tutatumia maktaba ya 'SVC' ambayo ina usahihi mzuri.
1. Ingiza maktaba zinazofaa kutoka Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. Tenganisha seti za mafunzo na majaribio:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. Jenga mfano wa Uainishaji wa SVC kama ulivyofanya katika somo la awali:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. Sasa, jaribu mfano wako, ukitumia `predict()`:
```python
y_pred = model.predict(X_test)
```
1. Chapisha ripoti ya uainishaji ili kukagua ubora wa mfano:
```python
print(classification_report(y_test,y_pred))
```
Kama tulivyoona awali, usahihi ni mzuri:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### Badilisha mfano wako kuwa Onnx
Hakikisha kufanya ubadilishaji kwa idadi sahihi ya Tensor. Seti hii ya data ina viungo 380 vilivyoorodheshwa, kwa hivyo unahitaji kuandika idadi hiyo katika `FloatTensorType`:
1. Badilisha kwa kutumia idadi ya tensor ya 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. Unda onx na uhifadhi kama faili **model.onnx**:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> Kumbuka, unaweza kupitisha [chaguzi](https://onnx.ai/sklearn-onnx/parameterized.html) katika script yako ya ubadilishaji. Katika kesi hii, tulipitisha 'nocl' kuwa True na 'zipmap' kuwa False. Kwa kuwa huu ni mfano wa uainishaji, una chaguo la kuondoa ZipMap ambayo inazalisha orodha ya kamusi (sio lazima). `nocl` inahusu taarifa za darasa kujumuishwa katika mfano. Punguza ukubwa wa mfano wako kwa kuweka `nocl` kuwa 'True'.
Kuendesha daftari nzima sasa kutajenga mfano wa Onnx na kuuhifadhi kwenye folda hii.
## Tazama mfano wako
Mifano ya Onnx si rahisi kuonekana katika Visual Studio Code, lakini kuna programu nzuri ya bure ambayo watafiti wengi hutumia kuona mfano ili kuhakikisha kuwa umejengwa vizuri. Pakua [Netron](https://github.com/lutzroeder/Netron) na fungua faili yako ya model.onnx. Unaweza kuona mfano wako rahisi ukiwa umeonyeshwa, na viingizo vyake 380 na uainishaji vilivyoorodheshwa:

Netron ni zana muhimu ya kutazama mifano yako.
Sasa uko tayari kutumia mfano huu mzuri katika programu ya wavuti. Hebu tujenge programu ambayo itakuwa muhimu unapochunguza jokofu lako na kujaribu kugundua mchanganyiko wa viungo vilivyobaki ambavyo unaweza kutumia kupika chakula fulani, kama ilivyoamuliwa na mfano wako.
## Jenga programu ya wavuti ya mapendekezo
Unaweza kutumia mfano wako moja kwa moja katika programu ya wavuti. Usanifu huu pia hukuruhusu kuendesha programu hiyo kwa ndani na hata nje ya mtandao ikiwa inahitajika. Anza kwa kuunda faili `index.html` katika folda ile ile ambapo ulihifadhi faili yako ya `model.onnx`.
1. Katika faili hii _index.html_, ongeza markup ifuatayo:
```html
Cuisine Matcher
...
```
1. Sasa, ukifanya kazi ndani ya vitambulisho vya `body`, ongeza markup kidogo kuonyesha orodha ya visanduku vya kuangalia vinavyoonyesha baadhi ya viungo:
```html
Check your refrigerator. What can you create?
```
Kumbuka kwamba kila kisanduku cha kuangalia kimepewa thamani. Hii inaonyesha index ambapo kiungo kinapatikana kulingana na seti ya data. Apple, kwa mfano, katika orodha hii ya alfabeti, inachukua safu ya tano, kwa hivyo thamani yake ni '4' kwa kuwa tunaanza kuhesabu kutoka 0. Unaweza kushauriana na [spreadsheet ya viungo](../../../../4-Classification/data/ingredient_indexes.csv) kugundua index ya kiungo fulani.
Ukiendelea kufanya kazi katika faili ya index.html, ongeza block ya script ambapo mfano unaitwa baada ya kufunga mwisho ``.
1. Kwanza, ingiza [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> Onnx Runtime hutumika kuwezesha kuendesha mifano yako ya Onnx kwenye anuwai ya majukwaa ya vifaa, ikiwa ni pamoja na uboreshaji na API ya kutumia.
1. Mara Runtime iko mahali, unaweza kuuita:
```html
```
Katika msimbo huu, kuna mambo kadhaa yanayotokea:
1. Uliunda safu ya thamani 380 zinazowezekana (1 au 0) kuwekwa na kutumwa kwa mfano kwa utabiri, kulingana na kama kisanduku cha kuangalia kimechaguliwa.
2. Uliunda safu ya visanduku vya kuangalia na njia ya kuamua kama vilichaguliwa katika kazi ya `init` ambayo inaitwa wakati programu inaanza. Wakati kisanduku cha kuangalia kinachaguliwa, safu ya `ingredients` hubadilishwa kuonyesha kiungo kilichochaguliwa.
3. Uliunda kazi ya `testCheckboxes` ambayo hukagua kama kisanduku chochote cha kuangalia kilichaguliwa.
4. Unatumia kazi ya `startInference` wakati kitufe kinapobanwa, na, ikiwa kisanduku chochote cha kuangalia kimechaguliwa, unaanza utabiri.
5. Utaratibu wa utabiri unajumuisha:
1. Kuweka upakiaji wa mfano kwa njia ya asynchronous
2. Kuunda muundo wa Tensor kutumwa kwa mfano
3. Kuunda 'feeds' zinazoonyesha `float_input` uliounda wakati wa kufundisha mfano wako (unaweza kutumia Netron kuthibitisha jina hilo)
4. Kutuma 'feeds' hizi kwa mfano na kusubiri majibu
## Jaribu programu yako
Fungua kikao cha terminal katika Visual Studio Code kwenye folda ambapo faili yako ya index.html iko. Hakikisha kuwa una [http-server](https://www.npmjs.com/package/http-server) imewekwa kimataifa, na andika `http-server` kwenye prompt. Seva ya localhost inapaswa kufunguka na unaweza kuona programu yako ya wavuti. Angalia ni chakula gani kinapendekezwa kulingana na viungo mbalimbali:
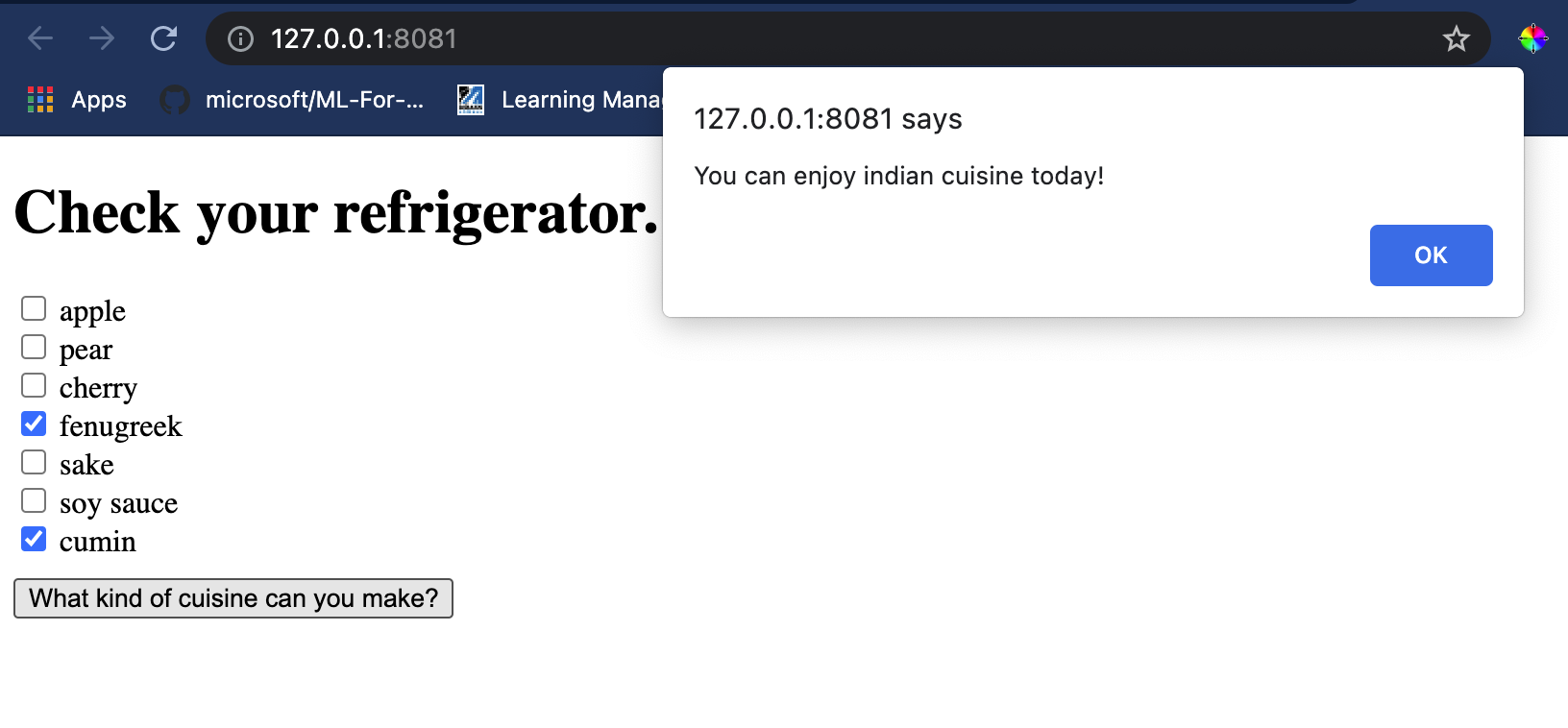
Hongera, umeunda programu ya wavuti ya 'mapendekezo' yenye sehemu chache. Chukua muda kujenga mfumo huu zaidi!
## 🚀Changamoto
Programu yako ya wavuti ni ya msingi sana, kwa hivyo endelea kuijenga kwa kutumia viungo na index zao kutoka data ya [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv). Ni mchanganyiko gani wa ladha unafanya kazi kuunda chakula cha kitaifa fulani?
## [Jaribio la baada ya somo](https://ff-quizzes.netlify.app/en/ml/)
## Mapitio na Kujisomea
Ingawa somo hili limegusia tu matumizi ya kujenga mfumo wa mapendekezo kwa viungo vya chakula, eneo hili la matumizi ya ML lina mifano mingi tajiri. Soma zaidi kuhusu jinsi mifumo hii inavyojengwa:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## Kazi
[Jenga mfumo mpya wa mapendekezo](assignment.md)
---
**Kanusho**:
Hati hii imetafsiriwa kwa kutumia huduma ya tafsiri ya AI [Co-op Translator](https://github.com/Azure/co-op-translator). Ingawa tunajitahidi kuhakikisha usahihi, tafsiri za kiotomatiki zinaweza kuwa na makosa au kutokuwa sahihi. Hati ya asili katika lugha yake ya awali inapaswa kuzingatiwa kama chanzo cha mamlaka. Kwa taarifa muhimu, tafsiri ya kitaalamu ya binadamu inapendekezwa. Hatutawajibika kwa kutoelewana au tafsiri zisizo sahihi zinazotokana na matumizi ya tafsiri hii.