# Bežné úlohy a techniky spracovania prirodzeného jazyka
Pri väčšine úloh *spracovania prirodzeného jazyka* je potrebné text rozložiť, analyzovať a výsledky uložiť alebo porovnať s pravidlami a dátovými súbormi. Tieto úlohy umožňujú programátorovi odvodiť _význam_, _zámer_ alebo len _frekvenciu_ termínov a slov v texte.
## [Kvíz pred prednáškou](https://ff-quizzes.netlify.app/en/ml/)
Poďme objaviť bežné techniky používané pri spracovaní textu. V kombinácii so strojovým učením vám tieto techniky pomôžu efektívne analyzovať veľké množstvo textu. Pred aplikáciou ML na tieto úlohy je však dôležité pochopiť problémy, s ktorými sa špecialista na NLP stretáva.
## Bežné úlohy v NLP
Existuje mnoho spôsobov, ako analyzovať text, na ktorom pracujete. Sú tu úlohy, ktoré môžete vykonávať, a prostredníctvom nich dokážete pochopiť text a vyvodiť závery. Tieto úlohy sa zvyčajne vykonávajú v sekvencii.
### Tokenizácia
Pravdepodobne prvou vecou, ktorú väčšina algoritmov NLP musí urobiť, je rozdelenie textu na tokeny alebo slová. Aj keď to znie jednoducho, zohľadnenie interpunkcie a rôznych jazykových oddelovačov slov a viet môže byť zložité. Môžete potrebovať rôzne metódy na určenie hraníc.
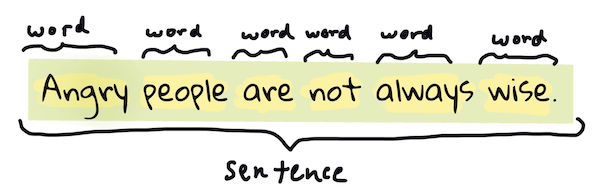
> Tokenizácia vety z **Pýchy a predsudku**. Infografika od [Jen Looper](https://twitter.com/jenlooper)
### Vstupy (Embeddings)
[Vstupy slov](https://wikipedia.org/wiki/Word_embedding) sú spôsob, ako numericky konvertovať vaše textové dáta. Vstupy sú vytvorené tak, aby slová s podobným významom alebo slová používané spolu vytvárali zhluky.

> "Mám najväčší rešpekt k vašim nervom, sú to moji starí priatelia." - Vstupy slov pre vetu z **Pýchy a predsudku**. Infografika od [Jen Looper](https://twitter.com/jenlooper)
✅ Vyskúšajte [tento zaujímavý nástroj](https://projector.tensorflow.org/) na experimentovanie s vstupmi slov. Kliknutím na jedno slovo sa zobrazia zhluky podobných slov: 'hračka' sa zhlukuje s 'disney', 'lego', 'playstation' a 'konzola'.
### Parsovanie a označovanie častí reči
Každé slovo, ktoré bolo tokenizované, môže byť označené ako časť reči - podstatné meno, sloveso alebo prídavné meno. Veta `rýchly červený líška preskočil cez lenivého hnedého psa` môže byť označená ako líška = podstatné meno, preskočil = sloveso.

> Parsovanie vety z **Pýchy a predsudku**. Infografika od [Jen Looper](https://twitter.com/jenlooper)
Parsovanie znamená rozpoznanie, ktoré slová sú vo vete navzájom prepojené - napríklad `rýchly červený líška preskočil` je sekvencia prídavné meno-podstatné meno-sloveso, ktorá je oddelená od sekvencie `lenivý hnedý pes`.
### Frekvencie slov a fráz
Užitočným postupom pri analýze veľkého množstva textu je vytvorenie slovníka každého slova alebo frázy, ktoré vás zaujímajú, a ich frekvencie výskytu. Fráza `rýchly červený líška preskočil cez lenivého hnedého psa` má frekvenciu slova 2 pre slovo "cez".
Pozrime sa na príklad textu, kde počítame frekvenciu slov. Báseň Rudyard Kiplinga Víťazi obsahuje nasledujúci verš:
```output
What the moral? Who rides may read.
When the night is thick and the tracks are blind
A friend at a pinch is a friend, indeed,
But a fool to wait for the laggard behind.
Down to Gehenna or up to the Throne,
He travels the fastest who travels alone.
```
Keďže frekvencie fráz môžu byť citlivé na veľkosť písmen alebo nie, fráza `priateľ` má frekvenciu 2, `cez` má frekvenciu 6 a `cestuje` má frekvenciu 2.
### N-gramy
Text môže byť rozdelený na sekvencie slov určitej dĺžky, jedno slovo (unigram), dve slová (bigramy), tri slová (trigramy) alebo akýkoľvek počet slov (n-gramy).
Napríklad `rýchly červený líška preskočil cez lenivého hnedého psa` s hodnotou n-gramu 2 vytvára nasledujúce n-gramy:
1. rýchly červený
2. červený líška
3. líška preskočil
4. preskočil cez
5. cez lenivého
6. lenivého hnedého
7. hnedého psa
Je jednoduchšie si to predstaviť ako posuvné okno nad vetou. Tu je to pre n-gramy s 3 slovami, n-gram je zvýraznený v každej vete:
1. **rýchly červený líška** preskočil cez lenivého hnedého psa
2. rýchly **červený líška preskočil** cez lenivého hnedého psa
3. rýchly červený **líška preskočil cez** lenivého hnedého psa
4. rýchly červený líška **preskočil cez lenivého** hnedého psa
5. rýchly červený líška preskočil **cez lenivého hnedého** psa
6. rýchly červený líška preskočil cez **lenivého hnedého psa**

> Hodnota n-gramu 3: Infografika od [Jen Looper](https://twitter.com/jenlooper)
### Extrakcia podstatných fráz
Väčšina viet obsahuje podstatné meno, ktoré je predmetom alebo objektom vety. V angličtine je často identifikovateľné tým, že pred ním stojí 'a', 'an' alebo 'the'. Identifikácia predmetu alebo objektu vety prostredníctvom 'extrakcie podstatnej frázy' je bežnou úlohou v NLP pri pokuse o pochopenie významu vety.
✅ Vo vete "Nemôžem si spomenúť na hodinu, miesto, pohľad alebo slová, ktoré položili základy. Je to príliš dávno. Bol som uprostred, než som si uvedomil, že som začal." dokážete identifikovať podstatné frázy?
Vo vete `rýchly červený líška preskočil cez lenivého hnedého psa` sú 2 podstatné frázy: **rýchly červený líška** a **lenivý hnedý pes**.
### Analýza sentimentu
Veta alebo text môže byť analyzovaný na sentiment, teda ako *pozitívny* alebo *negatívny* je. Sentiment sa meria v *polarite* a *objektivite/subjektivite*. Polarita sa meria od -1.0 do 1.0 (negatívna až pozitívna) a od 0.0 do 1.0 (najviac objektívna až najviac subjektívna).
✅ Neskôr sa naučíte, že existujú rôzne spôsoby určovania sentimentu pomocou strojového učenia, ale jedným zo spôsobov je mať zoznam slov a fráz, ktoré sú kategorizované ako pozitívne alebo negatívne ľudským expertom, a aplikovať tento model na text na výpočet skóre polarity. Vidíte, ako by to mohlo fungovať v niektorých prípadoch a menej dobre v iných?
### Inflekcia
Inflekcia vám umožňuje vziať slovo a získať jeho jednotné alebo množné číslo.
### Lemmatizácia
*Lema* je koreňové alebo základné slovo pre množinu slov, napríklad *letel*, *lietajú*, *lietanie* majú lemu slovesa *lietanie*.
Existujú aj užitočné databázy dostupné pre výskumníka NLP, najmä:
### WordNet
[WordNet](https://wordnet.princeton.edu/) je databáza slov, synonym, antonym a mnohých ďalších detailov pre každé slovo v mnohých rôznych jazykoch. Je neuveriteľne užitočná pri pokuse o vytváranie prekladov, kontrolu pravopisu alebo jazykových nástrojov akéhokoľvek typu.
## Knižnice NLP
Našťastie, nemusíte všetky tieto techniky vytvárať sami, pretože existujú vynikajúce knižnice v Pythone, ktoré ich sprístupňujú vývojárom, ktorí nie sú špecializovaní na spracovanie prirodzeného jazyka alebo strojové učenie. V nasledujúcich lekciách nájdete viac príkladov, ale tu sa naučíte niekoľko užitočných príkladov, ktoré vám pomôžu s ďalšou úlohou.
### Cvičenie - použitie knižnice `TextBlob`
Použime knižnicu TextBlob, ktorá obsahuje užitočné API na riešenie týchto typov úloh. TextBlob "stojí na obrovských pleciach [NLTK](https://nltk.org) a [pattern](https://github.com/clips/pattern) a dobre spolupracuje s oboma." Má značné množstvo ML zabudované vo svojom API.
> Poznámka: Užitočný [Rýchly štart](https://textblob.readthedocs.io/en/dev/quickstart.html#quickstart) sprievodca je dostupný pre TextBlob a odporúča sa skúseným vývojárom v Pythone.
Pri pokuse o identifikáciu *podstatných fráz* ponúka TextBlob niekoľko možností extraktorov na nájdenie podstatných fráz.
1. Pozrite sa na `ConllExtractor`.
```python
from textblob import TextBlob
from textblob.np_extractors import ConllExtractor
# import and create a Conll extractor to use later
extractor = ConllExtractor()
# later when you need a noun phrase extractor:
user_input = input("> ")
user_input_blob = TextBlob(user_input, np_extractor=extractor) # note non-default extractor specified
np = user_input_blob.noun_phrases
```
> Čo sa tu deje? [ConllExtractor](https://textblob.readthedocs.io/en/dev/api_reference.html?highlight=Conll#textblob.en.np_extractors.ConllExtractor) je "Extraktor podstatných fráz, ktorý používa chunk parsing trénovaný na korpuse ConLL-2000." ConLL-2000 odkazuje na konferenciu o výpočtovom učení prirodzeného jazyka z roku 2000. Každý rok konferencia hostila workshop na riešenie zložitého problému NLP, a v roku 2000 to bolo chunkovanie podstatných fráz. Model bol trénovaný na Wall Street Journal, s "sekciami 15-18 ako tréningové dáta (211727 tokenov) a sekciou 20 ako testovacie dáta (47377 tokenov)". Môžete si pozrieť použité postupy [tu](https://www.clips.uantwerpen.be/conll2000/chunking/) a [výsledky](https://ifarm.nl/erikt/research/np-chunking.html).
### Výzva - zlepšenie vášho bota pomocou NLP
V predchádzajúcej lekcii ste vytvorili veľmi jednoduchého Q&A bota. Teraz urobíte Marvina trochu sympatickejším tým, že analyzujete váš vstup na sentiment a vytlačíte odpoveď, ktorá zodpovedá sentimentu. Budete tiež musieť identifikovať `noun_phrase` a opýtať sa na ňu.
Vaše kroky pri vytváraní lepšieho konverzačného bota:
1. Vytlačte pokyny, ktoré používateľovi poradia, ako komunikovať s botom
2. Spustite slučku
1. Prijmite vstup od používateľa
2. Ak používateľ požiadal o ukončenie, ukončite
3. Spracujte vstup používateľa a určte vhodnú odpoveď na sentiment
4. Ak je v sentimentu detekovaná podstatná fráza, zmeňte ju na množné číslo a opýtajte sa na túto tému
5. Vytlačte odpoveď
3. Vráťte sa späť na krok 2
Tu je úryvok kódu na určenie sentimentu pomocou TextBlob. Všimnite si, že existujú iba štyri *stupne* odpovede na sentiment (môžete ich mať viac, ak chcete):
```python
if user_input_blob.polarity <= -0.5:
response = "Oh dear, that sounds bad. "
elif user_input_blob.polarity <= 0:
response = "Hmm, that's not great. "
elif user_input_blob.polarity <= 0.5:
response = "Well, that sounds positive. "
elif user_input_blob.polarity <= 1:
response = "Wow, that sounds great. "
```
Tu je ukážka výstupu na usmernenie (vstup používateľa je na riadkoch začínajúcich >):
```output
Hello, I am Marvin, the friendly robot.
You can end this conversation at any time by typing 'bye'
After typing each answer, press 'enter'
How are you today?
> I am ok
Well, that sounds positive. Can you tell me more?
> I went for a walk and saw a lovely cat
Well, that sounds positive. Can you tell me more about lovely cats?
> cats are the best. But I also have a cool dog
Wow, that sounds great. Can you tell me more about cool dogs?
> I have an old hounddog but he is sick
Hmm, that's not great. Can you tell me more about old hounddogs?
> bye
It was nice talking to you, goodbye!
```
Jedno možné riešenie úlohy je [tu](https://github.com/microsoft/ML-For-Beginners/blob/main/6-NLP/2-Tasks/solution/bot.py)
✅ Kontrola vedomostí
1. Myslíte si, že sympatické odpovede by 'oklamali' niekoho, aby si myslel, že bot ich skutočne rozumie?
2. Robí identifikácia podstatnej frázy bota viac 'uveriteľným'?
3. Prečo by extrakcia 'podstatnej frázy' z vety bola užitočná vec na vykonanie?
---
Implementujte bota v predchádzajúcej kontrole vedomostí a otestujte ho na priateľovi. Dokáže ich oklamať? Dokážete urobiť vášho bota viac 'uveriteľným'?
## 🚀Výzva
Vezmite úlohu z predchádzajúcej kontroly vedomostí a skúste ju implementovať. Otestujte bota na priateľovi. Dokáže ich oklamať? Dokážete urobiť vášho bota viac 'uveriteľným'?
## [Kvíz po prednáške](https://ff-quizzes.netlify.app/en/ml/)
## Prehľad a samostatné štúdium
V nasledujúcich lekciách sa dozviete viac o analýze sentimentu. Preskúmajte túto zaujímavú techniku v článkoch, ako sú tieto na [KDNuggets](https://www.kdnuggets.com/tag/nlp)
## Zadanie
[Urobte bota, ktorý odpovedá](assignment.md)
---
**Upozornenie**:
Tento dokument bol preložený pomocou služby AI prekladu [Co-op Translator](https://github.com/Azure/co-op-translator). Hoci sa snažíme o presnosť, prosím, berte na vedomie, že automatizované preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho rodnom jazyku by mal byť považovaný za autoritatívny zdroj. Pre kritické informácie sa odporúča profesionálny ľudský preklad. Nie sme zodpovední za akékoľvek nedorozumenia alebo nesprávne interpretácie vyplývajúce z použitia tohto prekladu.