# Vytvorenie webovej aplikácie na odporúčanie kuchyne
V tejto lekcii si vytvoríte klasifikačný model pomocou techník, ktoré ste sa naučili v predchádzajúcich lekciách, a s použitím datasetu chutných kuchýň, ktorý sa používal v celej tejto sérii. Okrem toho si vytvoríte malú webovú aplikáciu na použitie uloženého modelu, využívajúc webový runtime Onnx.
Jedným z najpraktickejších využití strojového učenia je vytváranie odporúčacích systémov, a dnes môžete urobiť prvý krok týmto smerom!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 Kliknite na obrázok vyššie pre video: Jen Looper vytvára webovú aplikáciu pomocou klasifikovaných údajov o kuchyniach
## [Kvíz pred lekciou](https://ff-quizzes.netlify.app/en/ml/)
V tejto lekcii sa naučíte:
- Ako vytvoriť model a uložiť ho ako Onnx model
- Ako použiť Netron na kontrolu modelu
- Ako použiť váš model vo webovej aplikácii na inferenciu
## Vytvorenie modelu
Vytváranie aplikovaných ML systémov je dôležitou súčasťou využívania týchto technológií pre vaše obchodné systémy. Modely môžete používať vo svojich webových aplikáciách (a teda ich používať v offline režime, ak je to potrebné) pomocou Onnx.
V [predchádzajúcej lekcii](../../3-Web-App/1-Web-App/README.md) ste vytvorili regresný model o pozorovaniach UFO, "picklovali" ho a použili ho vo Flask aplikácii. Aj keď je táto architektúra veľmi užitočná, ide o plnohodnotnú Python aplikáciu, a vaše požiadavky môžu zahŕňať použitie JavaScript aplikácie.
V tejto lekcii si môžete vytvoriť základný systém na inferenciu založený na JavaScripte. Najprv však musíte vytrénovať model a konvertovať ho na použitie s Onnx.
## Cvičenie - trénovanie klasifikačného modelu
Najprv vytrénujte klasifikačný model pomocou vyčisteného datasetu kuchýň, ktorý sme použili.
1. Začnite importovaním užitočných knižníc:
```python
!pip install skl2onnx
import pandas as pd
```
Potrebujete '[skl2onnx](https://onnx.ai/sklearn-onnx/)', aby ste mohli konvertovať váš Scikit-learn model do Onnx formátu.
1. Potom pracujte s vašimi údajmi rovnakým spôsobom ako v predchádzajúcich lekciách, čítaním CSV súboru pomocou `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. Odstráňte prvé dva nepotrebné stĺpce a uložte zostávajúce údaje ako 'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. Uložte štítky ako 'y':
```python
y = data[['cuisine']]
y.head()
```
### Spustenie tréningovej rutiny
Použijeme knižnicu 'SVC', ktorá má dobrú presnosť.
1. Importujte príslušné knižnice zo Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. Rozdeľte tréningové a testovacie sady:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. Vytvorte klasifikačný model SVC, ako ste to urobili v predchádzajúcej lekcii:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. Teraz otestujte váš model, zavolaním `predict()`:
```python
y_pred = model.predict(X_test)
```
1. Vytlačte klasifikačnú správu na kontrolu kvality modelu:
```python
print(classification_report(y_test,y_pred))
```
Ako sme videli predtým, presnosť je dobrá:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### Konverzia modelu na Onnx
Uistite sa, že konverziu vykonávate s správnym počtom tensorov. Tento dataset má 380 uvedených ingrediencií, takže musíte uviesť toto číslo v `FloatTensorType`:
1. Konvertujte s tensorovým číslom 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. Vytvorte onx a uložte ako súbor **model.onnx**:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> Poznámka: Môžete zadať [možnosti](https://onnx.ai/sklearn-onnx/parameterized.html) vo vašom konverznom skripte. V tomto prípade sme nastavili 'nocl' na True a 'zipmap' na False. Keďže ide o klasifikačný model, máte možnosť odstrániť ZipMap, ktorý produkuje zoznam slovníkov (nie je potrebné). `nocl` sa týka informácií o triedach zahrnutých v modeli. Zmenšite veľkosť vášho modelu nastavením `nocl` na 'True'.
Spustením celého notebooku teraz vytvoríte Onnx model a uložíte ho do tejto zložky.
## Zobrazenie modelu
Onnx modely nie sú veľmi viditeľné vo Visual Studio Code, ale existuje veľmi dobrý bezplatný softvér, ktorý mnohí výskumníci používajú na vizualizáciu modelu, aby sa uistili, že je správne vytvorený. Stiahnite si [Netron](https://github.com/lutzroeder/Netron) a otvorte váš súbor model.onnx. Môžete vidieť váš jednoduchý model vizualizovaný, s jeho 380 vstupmi a klasifikátorom uvedeným:

Netron je užitočný nástroj na zobrazenie vašich modelov.
Teraz ste pripravení použiť tento šikovný model vo webovej aplikácii. Vytvorme aplikáciu, ktorá bude užitočná, keď sa pozriete do vašej chladničky a pokúsite sa zistiť, akú kombináciu vašich zvyšných ingrediencií môžete použiť na prípravu určitej kuchyne, ako určí váš model.
## Vytvorenie webovej aplikácie na odporúčanie
Môžete použiť váš model priamo vo webovej aplikácii. Táto architektúra tiež umožňuje jeho spustenie lokálne a dokonca offline, ak je to potrebné. Začnite vytvorením súboru `index.html` v tej istej zložke, kde ste uložili váš súbor `model.onnx`.
1. V tomto súbore _index.html_ pridajte nasledujúci markup:
```html
Cuisine Matcher
...
```
1. Teraz, pracujúc v rámci značiek `body`, pridajte trochu markupu na zobrazenie zoznamu zaškrtávacích políčok odrážajúcich niektoré ingrediencie:
```html
Check your refrigerator. What can you create?
```
Všimnite si, že každé zaškrtávacie políčko má hodnotu. Táto hodnota odráža index, kde sa ingrediencia nachádza podľa datasetu. Jablko, napríklad, v tomto abecednom zozname, zaberá piaty stĺpec, takže jeho hodnota je '4', keďže začíname počítať od 0. Môžete si pozrieť [spreadsheet ingrediencií](../../../../4-Classification/data/ingredient_indexes.csv), aby ste zistili index danej ingrediencie.
Pokračujúc vo vašej práci v súbore index.html, pridajte blok skriptu, kde je model volaný po poslednom uzatváracom ``.
1. Najprv importujte [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> Onnx Runtime sa používa na umožnenie spustenia vašich Onnx modelov na širokej škále hardvérových platforiem, vrátane optimalizácií a API na použitie.
1. Keď je Runtime na mieste, môžete ho zavolať:
```html
```
V tomto kóde sa deje niekoľko vecí:
1. Vytvorili ste pole 380 možných hodnôt (1 alebo 0), ktoré sa nastavujú a posielajú modelu na inferenciu, v závislosti od toho, či je zaškrtávacie políčko zaškrtnuté.
2. Vytvorili ste pole zaškrtávacích políčok a spôsob, ako určiť, či boli zaškrtnuté, vo funkcii `init`, ktorá sa volá pri spustení aplikácie. Keď je zaškrtávacie políčko zaškrtnuté, pole `ingredients` sa upraví tak, aby odrážalo zvolenú ingredienciu.
3. Vytvorili ste funkciu `testCheckboxes`, ktorá kontroluje, či bolo zaškrtnuté nejaké políčko.
4. Používate funkciu `startInference`, keď je stlačené tlačidlo, a ak je zaškrtnuté nejaké políčko, začnete inferenciu.
5. Rutina inferencie zahŕňa:
1. Nastavenie asynchrónneho načítania modelu
2. Vytvorenie Tensor štruktúry na odoslanie modelu
3. Vytvorenie 'feeds', ktoré odrážajú vstup `float_input`, ktorý ste vytvorili pri trénovaní vášho modelu (môžete použiť Netron na overenie názvu)
4. Odoslanie týchto 'feeds' modelu a čakanie na odpoveď
## Testovanie aplikácie
Otvorte terminálovú reláciu vo Visual Studio Code v zložke, kde sa nachádza váš súbor index.html. Uistite sa, že máte [http-server](https://www.npmjs.com/package/http-server) nainštalovaný globálne, a zadajte `http-server` na výzvu. Lokálny hostiteľ by sa mal otvoriť a môžete si prezrieť vašu webovú aplikáciu. Skontrolujte, aká kuchyňa je odporúčaná na základe rôznych ingrediencií:
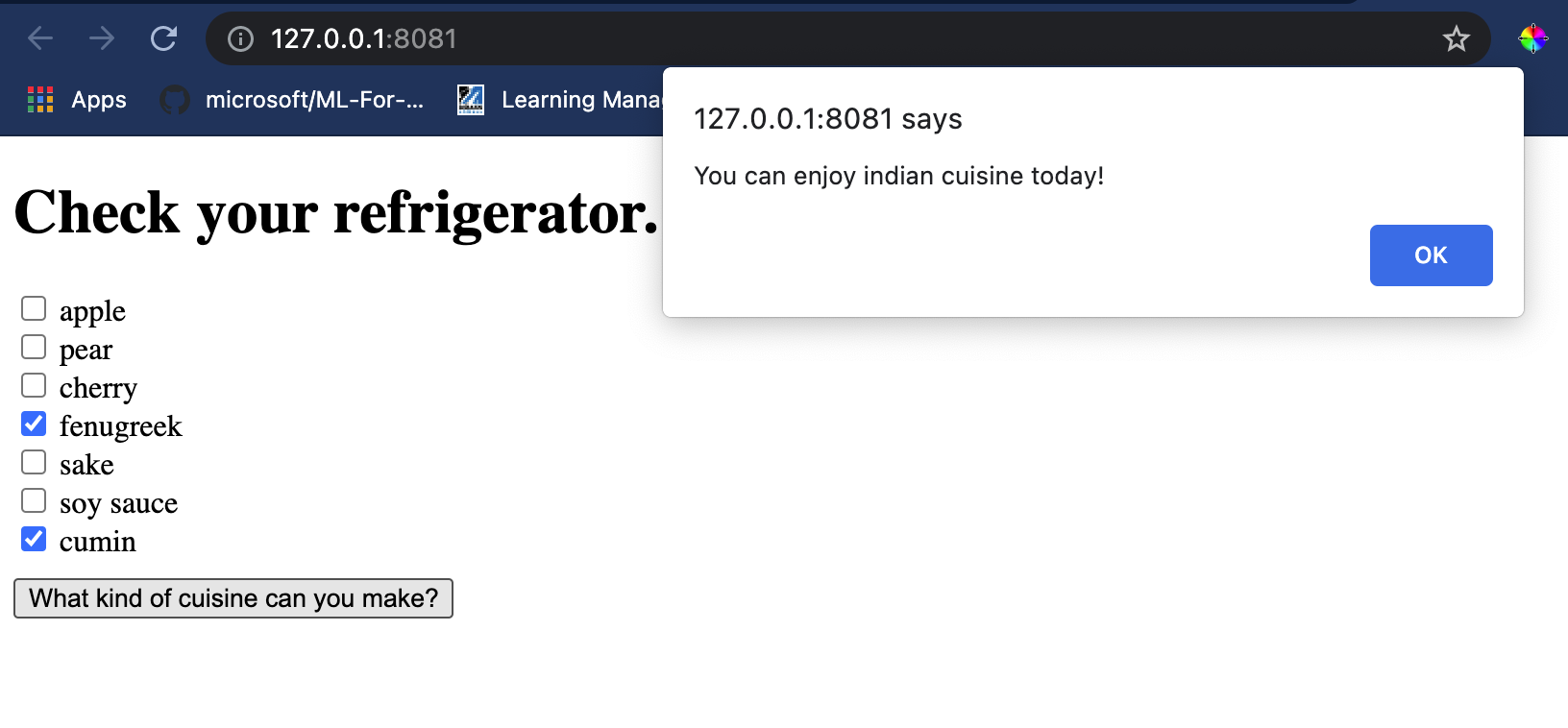
Gratulujeme, vytvorili ste webovú aplikáciu na odporúčanie s niekoľkými poliami. Venujte nejaký čas rozšíreniu tohto systému!
## 🚀Výzva
Vaša webová aplikácia je veľmi jednoduchá, takže pokračujte v jej rozširovaní pomocou ingrediencií a ich indexov z údajov [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv). Aké kombinácie chutí fungujú na vytvorenie určitého národného jedla?
## [Kvíz po lekcii](https://ff-quizzes.netlify.app/en/ml/)
## Prehľad a samostatné štúdium
Aj keď sa táto lekcia len dotkla užitočnosti vytvárania odporúčacieho systému pre ingrediencie, táto oblasť aplikácií ML je veľmi bohatá na príklady. Prečítajte si viac o tom, ako sa tieto systémy vytvárajú:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## Zadanie
[Vytvorte nový odporúčací systém](assignment.md)
---
**Upozornenie**:
Tento dokument bol preložený pomocou služby AI prekladu [Co-op Translator](https://github.com/Azure/co-op-translator). Hoci sa snažíme o presnosť, prosím, berte na vedomie, že automatizované preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho rodnom jazyku by mal byť považovaný za autoritatívny zdroj. Pre kritické informácie sa odporúča profesionálny ľudský preklad. Nie sme zodpovední za akékoľvek nedorozumenia alebo nesprávne interpretácie vyplývajúce z použitia tohto prekladu.