# Создание веб-приложения для рекомендаций по кухне
В этом уроке вы создадите модель классификации, используя некоторые из техник, изученных в предыдущих уроках, а также вкусный набор данных о кухнях, который использовался на протяжении всей серии. Кроме того, вы создадите небольшое веб-приложение для использования сохраненной модели, используя веб-рантайм Onnx.
Одно из самых полезных практических применений машинного обучения — это создание систем рекомендаций, и сегодня вы можете сделать первый шаг в этом направлении!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 Нажмите на изображение выше, чтобы посмотреть видео: Джен Лупер создает веб-приложение, используя классифицированные данные о кухнях.
## [Тест перед лекцией](https://ff-quizzes.netlify.app/en/ml/)
В этом уроке вы узнаете:
- Как создать модель и сохранить ее в формате Onnx
- Как использовать Netron для анализа модели
- Как использовать вашу модель в веб-приложении для выполнения предсказаний
## Создание модели
Создание прикладных систем машинного обучения — важная часть использования этих технологий в бизнесе. Вы можете использовать модели в своих веб-приложениях (а значит, использовать их в офлайн-режиме, если это необходимо) с помощью Onnx.
В [предыдущем уроке](../../3-Web-App/1-Web-App/README.md) вы создали модель регрессии на основе данных о наблюдениях НЛО, "запаковали" ее и использовали в приложении Flask. Хотя эта архитектура очень полезна, это полнофункциональное приложение на Python, а ваши требования могут включать использование JavaScript-приложения.
В этом уроке вы создадите базовую систему на JavaScript для выполнения предсказаний. Но сначала вам нужно обучить модель и преобразовать ее для использования с Onnx.
## Упражнение — обучение модели классификации
Сначала обучите модель классификации, используя очищенный набор данных о кухнях, который мы использовали ранее.
1. Начните с импорта полезных библиотек:
```python
!pip install skl2onnx
import pandas as pd
```
Вам понадобится '[skl2onnx](https://onnx.ai/sklearn-onnx/)', чтобы помочь преобразовать вашу модель Scikit-learn в формат Onnx.
1. Затем работайте с данными так же, как вы делали в предыдущих уроках, считывая CSV-файл с помощью `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. Удалите первые два ненужных столбца и сохраните оставшиеся данные как 'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. Сохраните метки как 'y':
```python
y = data[['cuisine']]
y.head()
```
### Начало процесса обучения
Мы будем использовать библиотеку 'SVC', которая обеспечивает хорошую точность.
1. Импортируйте соответствующие библиотеки из Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. Разделите данные на обучающую и тестовую выборки:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. Создайте модель классификации SVC, как вы делали в предыдущем уроке:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. Теперь протестируйте вашу модель, вызвав `predict()`:
```python
y_pred = model.predict(X_test)
```
1. Выведите отчет о классификации, чтобы проверить качество модели:
```python
print(classification_report(y_test,y_pred))
```
Как мы видели ранее, точность хорошая:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### Преобразование модели в Onnx
Убедитесь, что преобразование выполнено с правильным числом тензоров. В этом наборе данных указано 380 ингредиентов, поэтому вам нужно указать это число в `FloatTensorType`:
1. Преобразуйте, используя число тензоров 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. Создайте файл **model.onnx** и сохраните его:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> Обратите внимание, что вы можете передать [опции](https://onnx.ai/sklearn-onnx/parameterized.html) в вашем скрипте преобразования. В данном случае мы передали 'nocl' как True и 'zipmap' как False. Поскольку это модель классификации, у вас есть возможность удалить ZipMap, который создает список словарей (не обязательно). `nocl` относится к включению информации о классах в модель. Уменьшите размер вашей модели, установив `nocl` в 'True'.
Запуск всего ноутбука теперь создаст модель Onnx и сохранит ее в этой папке.
## Просмотр модели
Модели Onnx не очень удобно просматривать в Visual Studio Code, но есть очень хорошее бесплатное программное обеспечение, которое многие исследователи используют для визуализации модели, чтобы убедиться, что она построена правильно. Скачайте [Netron](https://github.com/lutzroeder/Netron) и откройте файл model.onnx. Вы увидите визуализацию вашей простой модели с 380 входами и классификатором:

Netron — полезный инструмент для просмотра моделей.
Теперь вы готовы использовать эту модель в веб-приложении. Давайте создадим приложение, которое будет полезно, когда вы заглянете в свой холодильник и попробуете определить, какие комбинации оставшихся ингредиентов можно использовать для приготовления блюда определенной кухни, как это определено вашей моделью.
## Создание веб-приложения для рекомендаций
Вы можете использовать вашу модель непосредственно в веб-приложении. Эта архитектура также позволяет запускать его локально и даже офлайн, если это необходимо. Начните с создания файла `index.html` в той же папке, где вы сохранили файл `model.onnx`.
1. В этом файле _index.html_ добавьте следующий разметку:
```html
Cuisine Matcher
...
```
1. Теперь, работая внутри тегов `body`, добавьте небольшую разметку для отображения списка чекбоксов, отражающих некоторые ингредиенты:
```html
Check your refrigerator. What can you create?
```
Обратите внимание, что каждому чекбоксу присвоено значение. Оно отражает индекс, где ингредиент находится в наборе данных. Например, яблоко в этом алфавитном списке занимает пятый столбец, поэтому его значение — '4', так как мы начинаем считать с 0. Вы можете обратиться к [таблице ингредиентов](../../../../4-Classification/data/ingredient_indexes.csv), чтобы узнать индекс конкретного ингредиента.
Продолжая работу в файле index.html, добавьте блок скрипта, где модель вызывается после закрывающего тега ``.
1. Сначала импортируйте [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> Onnx Runtime используется для запуска моделей Onnx на широком спектре аппаратных платформ, включая оптимизации и API для использования.
1. После установки Runtime вы можете его вызвать:
```html
```
В этом коде происходит несколько вещей:
1. Вы создали массив из 380 возможных значений (1 или 0), которые будут установлены и отправлены в модель для предсказания, в зависимости от того, отмечен ли чекбокс ингредиента.
2. Вы создали массив чекбоксов и способ определить, были ли они отмечены, в функции `init`, которая вызывается при запуске приложения. Когда чекбокс отмечен, массив `ingredients` изменяется, чтобы отразить выбранный ингредиент.
3. Вы создали функцию `testCheckboxes`, которая проверяет, был ли отмечен какой-либо чекбокс.
4. Вы используете функцию `startInference`, когда нажимается кнопка, и если какой-либо чекбокс отмечен, начинается процесс предсказания.
5. Процедура предсказания включает:
1. Настройку асинхронной загрузки модели
2. Создание структуры Tensor для отправки в модель
3. Создание 'feeds', которые отражают вход `float_input`, созданный при обучении модели (вы можете использовать Netron для проверки имени)
4. Отправку этих 'feeds' в модель и ожидание ответа
## Тестирование приложения
Откройте терминал в Visual Studio Code в папке, где находится ваш файл index.html. Убедитесь, что у вас установлен [http-server](https://www.npmjs.com/package/http-server) глобально, и введите `http-server` в командной строке. Должен открыться localhost, и вы сможете просмотреть ваше веб-приложение. Проверьте, какая кухня рекомендуется на основе различных ингредиентов:
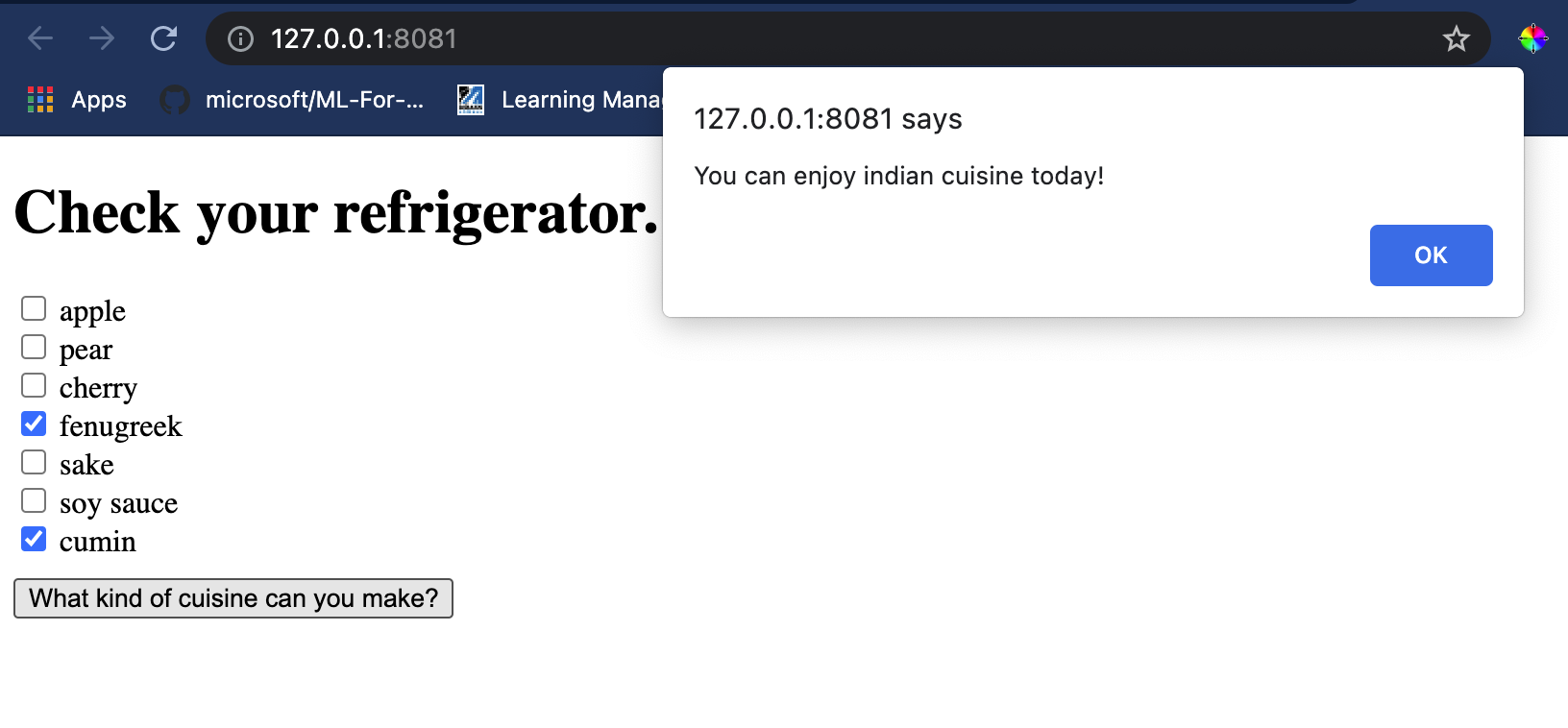
Поздравляем, вы создали веб-приложение для рекомендаций с несколькими полями. Потратьте время на развитие этой системы!
## 🚀Задание
Ваше веб-приложение очень минималистично, поэтому продолжайте его развивать, используя ингредиенты и их индексы из данных [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv). Какие комбинации вкусов подходят для создания национального блюда?
## [Тест после лекции](https://ff-quizzes.netlify.app/en/ml/)
## Обзор и самостоятельное изучение
Хотя в этом уроке мы лишь коснулись полезности создания системы рекомендаций для ингредиентов, эта область приложений машинного обучения очень богата примерами. Прочитайте больше о том, как создаются такие системы:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## Задание
[Создайте новую систему рекомендаций](assignment.md)
---
**Отказ от ответственности**:
Этот документ был переведен с помощью сервиса автоматического перевода [Co-op Translator](https://github.com/Azure/co-op-translator). Хотя мы стремимся к точности, пожалуйста, учитывайте, что автоматические переводы могут содержать ошибки или неточности. Оригинальный документ на его родном языке следует считать авторитетным источником. Для получения критически важной информации рекомендуется профессиональный перевод человеком. Мы не несем ответственности за любые недоразумения или неправильные интерпретации, возникшие в результате использования данного перевода.