# Vanlige oppgaver og teknikker innen naturlig språkprosessering
For de fleste oppgaver innen *naturlig språkprosessering* må teksten som skal behandles brytes ned, analyseres, og resultatene lagres eller kryssrefereres med regler og datasett. Disse oppgavene lar programmereren utlede _meningen_, _intensjonen_ eller bare _frekvensen_ av termer og ord i en tekst.
## [Quiz før forelesning](https://ff-quizzes.netlify.app/en/ml/)
La oss utforske vanlige teknikker som brukes i tekstbehandling. Kombinert med maskinlæring hjelper disse teknikkene deg med å analysere store mengder tekst effektivt. Før du bruker ML på disse oppgavene, la oss forstå problemene en NLP-spesialist møter.
## Vanlige oppgaver innen NLP
Det finnes ulike måter å analysere en tekst på. Det er oppgaver du kan utføre, og gjennom disse oppgavene kan du få en forståelse av teksten og trekke konklusjoner. Disse oppgavene utføres vanligvis i en sekvens.
### Tokenisering
Det første de fleste NLP-algoritmer må gjøre, er sannsynligvis å dele opp teksten i tokens, eller ord. Selv om dette høres enkelt ut, kan det være utfordrende å ta hensyn til tegnsetting og ulike språks ord- og setningsavgrensninger. Du må kanskje bruke ulike metoder for å bestemme hvor grensene går.
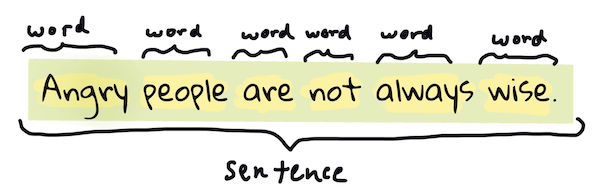
> Tokenisering av en setning fra **Pride and Prejudice**. Infografikk av [Jen Looper](https://twitter.com/jenlooper)
### Embeddings
[Ord-embeddings](https://wikipedia.org/wiki/Word_embedding) er en måte å konvertere tekstdata til numeriske verdier. Embeddings gjøres slik at ord med lignende betydning eller ord som ofte brukes sammen, grupperes sammen.

> "I have the highest respect for your nerves, they are my old friends." - Ord-embeddings for en setning i **Pride and Prejudice**. Infografikk av [Jen Looper](https://twitter.com/jenlooper)
✅ Prøv [dette interessante verktøyet](https://projector.tensorflow.org/) for å eksperimentere med ord-embeddings. Ved å klikke på ett ord vises klynger av lignende ord: 'toy' grupperes med 'disney', 'lego', 'playstation' og 'console'.
### Parsing og ordklassemerking
Hvert ord som er tokenisert, kan merkes som en ordklasse – et substantiv, verb eller adjektiv. Setningen `the quick red fox jumped over the lazy brown dog` kan for eksempel merkes som fox = substantiv, jumped = verb.

> Parsing av en setning fra **Pride and Prejudice**. Infografikk av [Jen Looper](https://twitter.com/jenlooper)
Parsing innebærer å gjenkjenne hvilke ord som er relatert til hverandre i en setning – for eksempel `the quick red fox jumped` er en adjektiv-substantiv-verb-sekvens som er separat fra sekvensen `lazy brown dog`.
### Ord- og frasefrekvenser
En nyttig prosedyre når man analyserer en stor tekstmengde, er å bygge en ordbok over hvert ord eller hver frase av interesse og hvor ofte de forekommer. Frasen `the quick red fox jumped over the lazy brown dog` har en ord-frekvens på 2 for "the".
La oss se på et eksempel der vi teller frekvensen av ord. Rudyard Kiplings dikt "The Winners" inneholder følgende vers:
```output
What the moral? Who rides may read.
When the night is thick and the tracks are blind
A friend at a pinch is a friend, indeed,
But a fool to wait for the laggard behind.
Down to Gehenna or up to the Throne,
He travels the fastest who travels alone.
```
Siden frasefrekvenser kan være enten store- og småbokstavsfølsomme eller ikke, har frasen `a friend` en frekvens på 2, `the` har en frekvens på 6, og `travels` har en frekvens på 2.
### N-grammer
En tekst kan deles opp i sekvenser av ord med en bestemt lengde: ett ord (unigram), to ord (bigram), tre ord (trigram) eller et hvilket som helst antall ord (n-grammer).
For eksempel gir `the quick red fox jumped over the lazy brown dog` med en n-gram-verdi på 2 følgende n-grammer:
1. the quick
2. quick red
3. red fox
4. fox jumped
5. jumped over
6. over the
7. the lazy
8. lazy brown
9. brown dog
Det kan være lettere å visualisere det som en glidende boks over setningen. Her er det for n-grammer med 3 ord, der n-grammet er uthevet i hver setning:
1. **the quick red** fox jumped over the lazy brown dog
2. the **quick red fox** jumped over the lazy brown dog
3. the quick **red fox jumped** over the lazy brown dog
4. the quick red **fox jumped over** the lazy brown dog
5. the quick red fox **jumped over the** lazy brown dog
6. the quick red fox jumped **over the lazy** brown dog
7. the quick red fox jumped over **the lazy brown** dog
8. the quick red fox jumped over the **lazy brown dog**

> N-gram-verdi på 3: Infografikk av [Jen Looper](https://twitter.com/jenlooper)
### Substantivfrase-ekstraksjon
I de fleste setninger finnes det et substantiv som er subjektet eller objektet i setningen. På engelsk kan det ofte identifiseres ved at det har 'a', 'an' eller 'the' foran seg. Å identifisere subjektet eller objektet i en setning ved å 'ekstrahere substantivfrasen' er en vanlig oppgave i NLP når man forsøker å forstå meningen med en setning.
✅ I setningen "I cannot fix on the hour, or the spot, or the look or the words, which laid the foundation. It is too long ago. I was in the middle before I knew that I had begun.", kan du identifisere substantivfrasene?
I setningen `the quick red fox jumped over the lazy brown dog` er det 2 substantivfraser: **quick red fox** og **lazy brown dog**.
### Sentimentanalyse
En setning eller tekst kan analyseres for sentiment, eller hvor *positiv* eller *negativ* den er. Sentiment måles i *polarisering* og *objektivitet/subjektivitet*. Polarisering måles fra -1,0 til 1,0 (negativ til positiv) og 0,0 til 1,0 (mest objektiv til mest subjektiv).
✅ Senere vil du lære at det finnes ulike måter å bestemme sentiment på ved hjelp av maskinlæring, men én måte er å ha en liste over ord og fraser som er kategorisert som positive eller negative av en menneskelig ekspert, og bruke den modellen på tekst for å beregne en polarisering. Kan du se hvordan dette kan fungere i noen tilfeller og mindre godt i andre?
### Bøyning
Bøyning lar deg ta et ord og finne entalls- eller flertallsformen av ordet.
### Lemmatization
En *lemma* er roten eller grunnordet for en gruppe ord, for eksempel har *flew*, *flies*, *flying* en lemma av verbet *fly*.
Det finnes også nyttige databaser tilgjengelige for NLP-forskere, spesielt:
### WordNet
[WordNet](https://wordnet.princeton.edu/) er en database over ord, synonymer, antonymer og mange andre detaljer for hvert ord på mange forskjellige språk. Den er utrolig nyttig når man forsøker å bygge oversettelser, stavekontroller eller språklige verktøy av alle slag.
## NLP-biblioteker
Heldigvis trenger du ikke bygge alle disse teknikkene selv, da det finnes utmerkede Python-biblioteker som gjør det mye mer tilgjengelig for utviklere som ikke er spesialister på naturlig språkprosessering eller maskinlæring. De neste leksjonene inkluderer flere eksempler på disse, men her vil du lære noen nyttige eksempler som hjelper deg med neste oppgave.
### Øvelse – bruk av `TextBlob`-biblioteket
La oss bruke et bibliotek kalt TextBlob, da det inneholder nyttige API-er for å håndtere denne typen oppgaver. TextBlob "står på skuldrene til giganter som [NLTK](https://nltk.org) og [pattern](https://github.com/clips/pattern), og fungerer godt med begge." Det har en betydelig mengde ML innebygd i sitt API.
> Merk: En nyttig [Quick Start](https://textblob.readthedocs.io/en/dev/quickstart.html#quickstart)-guide er tilgjengelig for TextBlob og anbefales for erfarne Python-utviklere.
Når du forsøker å identifisere *substantivfraser*, tilbyr TextBlob flere alternativer for å finne substantivfraser.
1. Ta en titt på `ConllExtractor`.
```python
from textblob import TextBlob
from textblob.np_extractors import ConllExtractor
# import and create a Conll extractor to use later
extractor = ConllExtractor()
# later when you need a noun phrase extractor:
user_input = input("> ")
user_input_blob = TextBlob(user_input, np_extractor=extractor) # note non-default extractor specified
np = user_input_blob.noun_phrases
```
> Hva skjer her? [ConllExtractor](https://textblob.readthedocs.io/en/dev/api_reference.html?highlight=Conll#textblob.en.np_extractors.ConllExtractor) er "En substantivfrase-ekstraktor som bruker chunk parsing trent med ConLL-2000 treningskorpus." ConLL-2000 refererer til 2000-konferansen om Computational Natural Language Learning. Hvert år arrangerte konferansen en workshop for å takle et vanskelig NLP-problem, og i 2000 var det substantivchunking. En modell ble trent på Wall Street Journal, med "seksjoner 15-18 som treningsdata (211727 tokens) og seksjon 20 som testdata (47377 tokens)". Du kan se prosedyrene som ble brukt [her](https://www.clips.uantwerpen.be/conll2000/chunking/) og [resultatene](https://ifarm.nl/erikt/research/np-chunking.html).
### Utfordring – forbedre boten din med NLP
I forrige leksjon bygde du en veldig enkel Q&A-bot. Nå skal du gjøre Marvin litt mer sympatisk ved å analysere innspillene dine for sentiment og skrive ut et svar som matcher sentimentet. Du må også identifisere en `noun_phrase` og spørre om den.
Stegene dine når du bygger en bedre samtalebot:
1. Skriv ut instruksjoner som forklarer brukeren hvordan de kan samhandle med boten.
2. Start en løkke:
1. Godta brukerens input.
2. Hvis brukeren har bedt om å avslutte, avslutt.
3. Behandle brukerens input og bestem passende sentimentrespons.
4. Hvis en substantivfrase oppdages i sentimentet, gjør den til flertall og spør om mer input om det emnet.
5. Skriv ut respons.
3. Gå tilbake til steg 2.
Her er kodeeksempelet for å bestemme sentiment ved hjelp av TextBlob. Merk at det kun er fire *graderinger* av sentimentrespons (du kan ha flere hvis du ønsker):
```python
if user_input_blob.polarity <= -0.5:
response = "Oh dear, that sounds bad. "
elif user_input_blob.polarity <= 0:
response = "Hmm, that's not great. "
elif user_input_blob.polarity <= 0.5:
response = "Well, that sounds positive. "
elif user_input_blob.polarity <= 1:
response = "Wow, that sounds great. "
```
Her er et eksempel på utdata for å veilede deg (brukerinput er på linjer som starter med >):
```output
Hello, I am Marvin, the friendly robot.
You can end this conversation at any time by typing 'bye'
After typing each answer, press 'enter'
How are you today?
> I am ok
Well, that sounds positive. Can you tell me more?
> I went for a walk and saw a lovely cat
Well, that sounds positive. Can you tell me more about lovely cats?
> cats are the best. But I also have a cool dog
Wow, that sounds great. Can you tell me more about cool dogs?
> I have an old hounddog but he is sick
Hmm, that's not great. Can you tell me more about old hounddogs?
> bye
It was nice talking to you, goodbye!
```
En mulig løsning på oppgaven finner du [her](https://github.com/microsoft/ML-For-Beginners/blob/main/6-NLP/2-Tasks/solution/bot.py).
✅ Kunnskapssjekk
1. Tror du de sympatiske responsene ville 'lure' noen til å tro at boten faktisk forsto dem?
2. Gjør identifiseringen av substantivfrasen boten mer 'troverdig'?
3. Hvorfor kan det være nyttig å trekke ut en 'substantivfrase' fra en setning?
---
Implementer boten i kunnskapssjekken ovenfor og test den på en venn. Kan den lure dem? Kan du gjøre boten din mer 'troverdig'?
## 🚀Utfordring
Ta en oppgave fra kunnskapssjekken ovenfor og prøv å implementere den. Test boten på en venn. Kan den lure dem? Kan du gjøre boten din mer 'troverdig'?
## [Quiz etter forelesning](https://ff-quizzes.netlify.app/en/ml/)
## Gjennomgang og selvstudium
I de neste leksjonene vil du lære mer om sentimentanalyse. Undersøk denne interessante teknikken i artikler som disse på [KDNuggets](https://www.kdnuggets.com/tag/nlp).
## Oppgave
[Få en bot til å svare](assignment.md)
---
**Ansvarsfraskrivelse**:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten [Co-op Translator](https://github.com/Azure/co-op-translator). Selv om vi streber etter nøyaktighet, vær oppmerksom på at automatiske oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.