# Bouw een Webapplicatie voor Cuisines Aanbevelingen
In deze les ga je een classificatiemodel bouwen met behulp van enkele technieken die je in eerdere lessen hebt geleerd, en met de dataset van heerlijke gerechten die in deze serie wordt gebruikt. Daarnaast bouw je een kleine webapplicatie om een opgeslagen model te gebruiken, waarbij je gebruik maakt van Onnx's web runtime.
Een van de meest praktische toepassingen van machine learning is het bouwen van aanbevelingssystemen, en vandaag kun je de eerste stap in die richting zetten!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 Klik op de afbeelding hierboven voor een video: Jen Looper bouwt een webapp met geclassificeerde gerechten data
## [Pre-lecture quiz](https://ff-quizzes.netlify.app/en/ml/)
In deze les leer je:
- Hoe je een model bouwt en opslaat als een Onnx-model
- Hoe je Netron gebruikt om het model te inspecteren
- Hoe je je model gebruikt in een webapplicatie voor inferentie
## Bouw je model
Het bouwen van toegepaste ML-systemen is een belangrijk onderdeel van het benutten van deze technologieën voor je bedrijfsprocessen. Je kunt modellen gebruiken binnen je webapplicaties (en dus ook offline indien nodig) door gebruik te maken van Onnx.
In een [vorige les](../../3-Web-App/1-Web-App/README.md) heb je een regressiemodel gebouwd over UFO-waarnemingen, het "gepickled" en gebruikt in een Flask-app. Hoewel deze architectuur erg nuttig is om te kennen, is het een full-stack Python-app, en je vereisten kunnen het gebruik van een JavaScript-applicatie omvatten.
In deze les kun je een eenvoudig JavaScript-gebaseerd systeem bouwen voor inferentie. Maar eerst moet je een model trainen en converteren voor gebruik met Onnx.
## Oefening - train classificatiemodel
Train eerst een classificatiemodel met behulp van de opgeschoonde gerechten dataset die we hebben gebruikt.
1. Begin met het importeren van nuttige bibliotheken:
```python
!pip install skl2onnx
import pandas as pd
```
Je hebt '[skl2onnx](https://onnx.ai/sklearn-onnx/)' nodig om je Scikit-learn model te converteren naar Onnx-formaat.
1. Werk vervolgens met je data op dezelfde manier als in eerdere lessen, door een CSV-bestand te lezen met `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. Verwijder de eerste twee onnodige kolommen en sla de resterende data op als 'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. Sla de labels op als 'y':
```python
y = data[['cuisine']]
y.head()
```
### Start de trainingsroutine
We gebruiken de 'SVC'-bibliotheek die een goede nauwkeurigheid heeft.
1. Importeer de juiste bibliotheken van Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. Splits de trainings- en testsets:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. Bouw een SVC-classificatiemodel zoals je deed in de vorige les:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. Test nu je model door `predict()` aan te roepen:
```python
y_pred = model.predict(X_test)
```
1. Print een classificatierapport om de kwaliteit van het model te controleren:
```python
print(classification_report(y_test,y_pred))
```
Zoals we eerder zagen, is de nauwkeurigheid goed:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### Converteer je model naar Onnx
Zorg ervoor dat je de conversie uitvoert met het juiste aantal tensors. Deze dataset heeft 380 ingrediënten vermeld, dus je moet dat aantal noteren in `FloatTensorType`:
1. Converteer met een tensor aantal van 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. Maak de onx en sla op als een bestand **model.onnx**:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> Let op, je kunt [opties](https://onnx.ai/sklearn-onnx/parameterized.html) doorgeven in je conversiescript. In dit geval hebben we 'nocl' ingesteld op True en 'zipmap' op False. Omdat dit een classificatiemodel is, heb je de optie om ZipMap te verwijderen, wat een lijst van woordenboeken produceert (niet nodig). `nocl` verwijst naar klasse-informatie die in het model wordt opgenomen. Verminder de grootte van je model door `nocl` op 'True' te zetten.
Door het hele notebook uit te voeren, wordt nu een Onnx-model gebouwd en opgeslagen in deze map.
## Bekijk je model
Onnx-modellen zijn niet erg zichtbaar in Visual Studio Code, maar er is een zeer goede gratis software die veel onderzoekers gebruiken om het model te visualiseren en te controleren of het correct is gebouwd. Download [Netron](https://github.com/lutzroeder/Netron) en open je model.onnx-bestand. Je kunt je eenvoudige model visualiseren, met zijn 380 inputs en classifier vermeld:

Netron is een handig hulpmiddel om je modellen te bekijken.
Nu ben je klaar om dit handige model te gebruiken in een webapplicatie. Laten we een app bouwen die van pas komt wanneer je in je koelkast kijkt en probeert te bepalen welke combinatie van je overgebleven ingrediënten je kunt gebruiken om een bepaald gerecht te koken, zoals bepaald door je model.
## Bouw een aanbevelingswebapplicatie
Je kunt je model direct gebruiken in een webapplicatie. Deze architectuur stelt je ook in staat om het lokaal en zelfs offline te draaien indien nodig. Begin met het maken van een `index.html`-bestand in dezelfde map waar je je `model.onnx`-bestand hebt opgeslagen.
1. Voeg in dit bestand _index.html_ de volgende markup toe:
```html
Cuisine Matcher
...
```
1. Voeg nu binnen de `body`-tags een beetje markup toe om een lijst met selectievakjes weer te geven die enkele ingrediënten weerspiegelen:
```html
Check your refrigerator. What can you create?
```
Merk op dat elk selectievakje een waarde heeft. Dit weerspiegelt de index waar het ingrediënt wordt gevonden volgens de dataset. Appel, bijvoorbeeld, in deze alfabetische lijst, bezet de vijfde kolom, dus de waarde is '4' omdat we beginnen met tellen vanaf 0. Je kunt de [ingrediënten spreadsheet](../../../../4-Classification/data/ingredient_indexes.csv) raadplegen om de index van een bepaald ingrediënt te ontdekken.
Ga verder met je werk in het index.html-bestand en voeg een scriptblok toe waar het model wordt aangeroepen na de laatste sluitende ``.
1. Importeer eerst de [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> Onnx Runtime wordt gebruikt om je Onnx-modellen te laten draaien op een breed scala aan hardwareplatforms, inclusief optimalisaties en een API om te gebruiken.
1. Zodra de Runtime is geïnstalleerd, kun je deze aanroepen:
```html
```
In deze code gebeuren er verschillende dingen:
1. Je hebt een array van 380 mogelijke waarden (1 of 0) gemaakt die worden ingesteld en naar het model worden gestuurd voor inferentie, afhankelijk van of een ingrediënt selectievakje is aangevinkt.
2. Je hebt een array van selectievakjes gemaakt en een manier om te bepalen of ze zijn aangevinkt in een `init`-functie die wordt aangeroepen wanneer de applicatie start. Wanneer een selectievakje is aangevinkt, wordt de `ingredients`-array aangepast om het gekozen ingrediënt weer te geven.
3. Je hebt een `testCheckboxes`-functie gemaakt die controleert of een selectievakje is aangevinkt.
4. Je gebruikt de `startInference`-functie wanneer de knop wordt ingedrukt en, als een selectievakje is aangevinkt, start je inferentie.
5. De inferentieroutine omvat:
1. Het instellen van een asynchrone laadactie van het model
2. Het maken van een Tensor-structuur om naar het model te sturen
3. Het maken van 'feeds' die de `float_input` input weerspiegelt die je hebt gemaakt bij het trainen van je model (je kunt Netron gebruiken om die naam te verifiëren)
4. Het sturen van deze 'feeds' naar het model en wachten op een reactie
## Test je applicatie
Open een terminalsessie in Visual Studio Code in de map waar je index.html-bestand zich bevindt. Zorg ervoor dat je [http-server](https://www.npmjs.com/package/http-server) globaal hebt geïnstalleerd en typ `http-server` bij de prompt. Er zou een localhost moeten openen en je kunt je webapp bekijken. Controleer welk gerecht wordt aanbevolen op basis van verschillende ingrediënten:
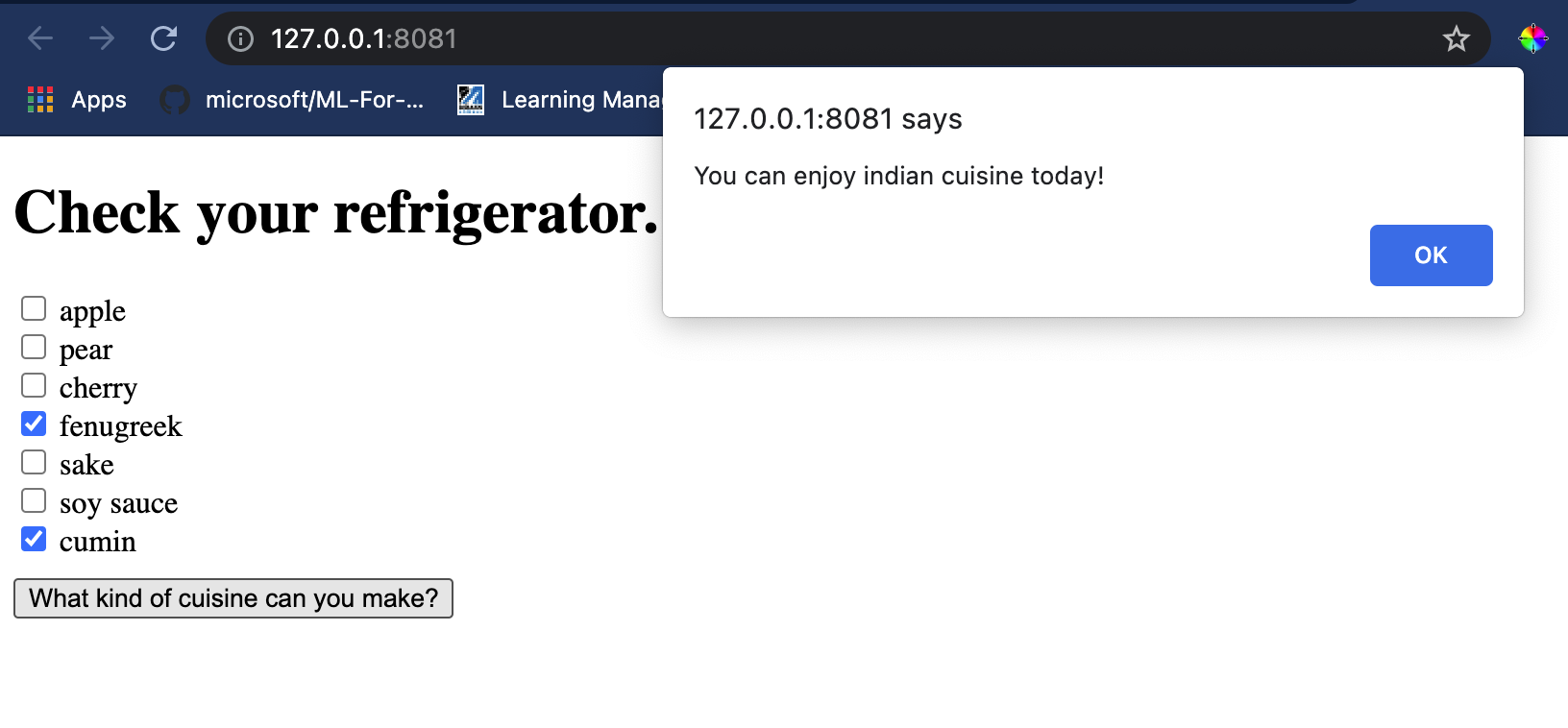
Gefeliciteerd, je hebt een 'aanbevelings'-webapp gemaakt met een paar velden. Neem de tijd om dit systeem verder uit te bouwen!
## 🚀Uitdaging
Je webapp is erg minimaal, dus blijf deze uitbreiden met ingrediënten en hun indexen uit de [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv) data. Welke smaakcombinaties werken om een bepaald nationaal gerecht te creëren?
## [Post-lecture quiz](https://ff-quizzes.netlify.app/en/ml/)
## Review & Zelfstudie
Hoewel deze les slechts kort ingaat op het nut van het creëren van een aanbevelingssysteem voor voedselingrediënten, is dit gebied van ML-toepassingen zeer rijk aan voorbeelden. Lees meer over hoe deze systemen worden gebouwd:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## Opdracht
[Maak een nieuwe aanbeveling](assignment.md)
---
**Disclaimer**:
Dit document is vertaald met behulp van de AI-vertalingsservice [Co-op Translator](https://github.com/Azure/co-op-translator). Hoewel we streven naar nauwkeurigheid, dient u zich ervan bewust te zijn dat geautomatiseerde vertalingen fouten of onnauwkeurigheden kunnen bevatten. Het originele document in zijn oorspronkelijke taal moet worden beschouwd als de gezaghebbende bron. Voor cruciale informatie wordt professionele menselijke vertaling aanbevolen. Wij zijn niet aansprakelijk voor eventuele misverstanden of verkeerde interpretaties die voortvloeien uit het gebruik van deze vertaling.