# Compiti e tecniche comuni di elaborazione del linguaggio naturale
Per la maggior parte dei compiti di *elaborazione del linguaggio naturale*, il testo da elaborare deve essere suddiviso, esaminato e i risultati devono essere archiviati o confrontati con regole e set di dati. Questi compiti permettono al programmatore di derivare il _significato_ o l'_intento_ o solo la _frequenza_ dei termini e delle parole in un testo.
## [Quiz pre-lezione](https://ff-quizzes.netlify.app/en/ml/)
Scopriamo le tecniche comuni utilizzate nell'elaborazione del testo. Combinate con il machine learning, queste tecniche ti aiutano ad analizzare grandi quantità di testo in modo efficiente. Prima di applicare il ML a questi compiti, però, cerchiamo di comprendere i problemi che un esperto di NLP potrebbe incontrare.
## Compiti comuni nell'NLP
Esistono diversi modi per analizzare un testo su cui stai lavorando. Ci sono compiti che puoi svolgere e, attraverso questi, puoi ottenere una comprensione del testo e trarre conclusioni. Di solito, questi compiti vengono eseguiti in sequenza.
### Tokenizzazione
Probabilmente la prima cosa che la maggior parte degli algoritmi di NLP deve fare è suddividere il testo in token, o parole. Sebbene possa sembrare semplice, tenere conto della punteggiatura e dei delimitatori di parole e frasi di lingue diverse può renderlo complicato. Potresti dover utilizzare vari metodi per determinare le demarcazioni.
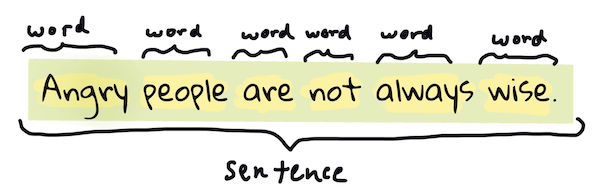
> Tokenizzazione di una frase da **Orgoglio e Pregiudizio**. Infografica di [Jen Looper](https://twitter.com/jenlooper)
### Embeddings
[Word embeddings](https://wikipedia.org/wiki/Word_embedding) sono un modo per convertire i dati testuali in numeri. Gli embeddings vengono effettuati in modo tale che parole con significati simili o parole utilizzate insieme si raggruppino.

> "Ho il massimo rispetto per i tuoi nervi, sono miei vecchi amici." - Word embeddings per una frase in **Orgoglio e Pregiudizio**. Infografica di [Jen Looper](https://twitter.com/jenlooper)
✅ Prova [questo strumento interessante](https://projector.tensorflow.org/) per sperimentare con i word embeddings. Cliccando su una parola mostra cluster di parole simili: 'giocattolo' si raggruppa con 'disney', 'lego', 'playstation' e 'console'.
### Parsing e Tagging delle Parti del Discorso
Ogni parola che è stata tokenizzata può essere etichettata come parte del discorso - un sostantivo, verbo o aggettivo. La frase `la veloce volpe rossa saltò sopra il cane marrone pigro` potrebbe essere etichettata come fox = sostantivo, jumped = verbo.

> Parsing di una frase da **Orgoglio e Pregiudizio**. Infografica di [Jen Looper](https://twitter.com/jenlooper)
Il parsing consiste nel riconoscere quali parole sono correlate tra loro in una frase - ad esempio `la veloce volpe rossa saltò` è una sequenza aggettivo-sostantivo-verbo che è separata dalla sequenza `il cane marrone pigro`.
### Frequenze di Parole e Frasi
Una procedura utile quando si analizza un grande corpo di testo è costruire un dizionario di ogni parola o frase di interesse e quante volte appare. La frase `la veloce volpe rossa saltò sopra il cane marrone pigro` ha una frequenza di 2 per la parola "il".
Vediamo un esempio di testo in cui contiamo la frequenza delle parole. La poesia The Winners di Rudyard Kipling contiene il seguente verso:
```output
What the moral? Who rides may read.
When the night is thick and the tracks are blind
A friend at a pinch is a friend, indeed,
But a fool to wait for the laggard behind.
Down to Gehenna or up to the Throne,
He travels the fastest who travels alone.
```
Poiché le frequenze delle frasi possono essere sensibili o insensibili alle maiuscole, la frase `un amico` ha una frequenza di 2, `il` ha una frequenza di 6 e `viaggia` è 2.
### N-grams
Un testo può essere suddiviso in sequenze di parole di una lunghezza prestabilita: una singola parola (unigram), due parole (bigram), tre parole (trigram) o qualsiasi numero di parole (n-grams).
Ad esempio, `la veloce volpe rossa saltò sopra il cane marrone pigro` con un punteggio n-gram di 2 produce i seguenti n-grams:
1. la veloce
2. veloce volpe
3. volpe rossa
4. rossa saltò
5. saltò sopra
6. sopra il
7. il cane
8. cane marrone
9. marrone pigro
Potrebbe essere più facile visualizzarlo come una finestra scorrevole sulla frase. Ecco un esempio per n-grams di 3 parole, l'n-gram è in grassetto in ogni frase:
1. **la veloce volpe** rossa saltò sopra il cane marrone pigro
2. la **veloce volpe rossa** saltò sopra il cane marrone pigro
3. la veloce **volpe rossa saltò** sopra il cane marrone pigro
4. la veloce volpe **rossa saltò sopra** il cane marrone pigro
5. la veloce volpe rossa **saltò sopra il** cane marrone pigro
6. la veloce volpe rossa saltò **sopra il cane** marrone pigro
7. la veloce volpe rossa saltò sopra **il cane marrone** pigro
8. la veloce volpe rossa saltò sopra il **cane marrone pigro**

> Valore N-gram di 3: Infografica di [Jen Looper](https://twitter.com/jenlooper)
### Estrazione di Frasi Nominali
Nella maggior parte delle frasi, c'è un sostantivo che è il soggetto o l'oggetto della frase. In inglese, spesso è identificabile perché preceduto da 'a', 'an' o 'the'. Identificare il soggetto o l'oggetto di una frase attraverso l'estrazione della frase nominale è un compito comune nell'NLP quando si cerca di comprendere il significato di una frase.
✅ Nella frase "Non riesco a fissare l'ora, o il luogo, o lo sguardo o le parole, che hanno posto le basi. È troppo tempo fa. Ero nel mezzo prima di rendermi conto che avevo iniziato.", riesci a identificare le frasi nominali?
Nella frase `la veloce volpe rossa saltò sopra il cane marrone pigro` ci sono 2 frasi nominali: **veloce volpe rossa** e **cane marrone pigro**.
### Analisi del Sentimento
Una frase o un testo possono essere analizzati per il sentimento, ovvero quanto è *positivo* o *negativo*. Il sentimento viene misurato in *polarità* e *oggettività/soggettività*. La polarità è misurata da -1.0 a 1.0 (negativo a positivo) e da 0.0 a 1.0 (più oggettivo a più soggettivo).
✅ Più avanti imparerai che ci sono diversi modi per determinare il sentimento utilizzando il machine learning, ma un modo è avere un elenco di parole e frasi categorizzate come positive o negative da un esperto umano e applicare quel modello al testo per calcolare un punteggio di polarità. Riesci a vedere come questo funzionerebbe in alcune circostanze e meno bene in altre?
### Inflessione
L'inflessione ti permette di prendere una parola e ottenere il singolare o il plurale della parola.
### Lemmatizzazione
Un *lemma* è la radice o la parola principale per un insieme di parole, ad esempio *volò*, *vola*, *volando* hanno come lemma il verbo *volare*.
Sono disponibili anche database utili per i ricercatori NLP, in particolare:
### WordNet
[WordNet](https://wordnet.princeton.edu/) è un database di parole, sinonimi, contrari e molti altri dettagli per ogni parola in molte lingue diverse. È incredibilmente utile quando si cerca di costruire traduzioni, correttori ortografici o strumenti linguistici di qualsiasi tipo.
## Librerie NLP
Fortunatamente, non devi costruire tutte queste tecniche da solo, poiché ci sono eccellenti librerie Python disponibili che rendono l'NLP molto più accessibile agli sviluppatori che non sono specializzati in elaborazione del linguaggio naturale o machine learning. Le prossime lezioni includono più esempi di queste librerie, ma qui imparerai alcuni esempi utili per aiutarti con il prossimo compito.
### Esercizio - utilizzo della libreria `TextBlob`
Usiamo una libreria chiamata TextBlob poiché contiene API utili per affrontare questi tipi di compiti. TextBlob "si basa sulle solide fondamenta di [NLTK](https://nltk.org) e [pattern](https://github.com/clips/pattern), e funziona bene con entrambi." Ha una quantità considerevole di ML integrata nella sua API.
> Nota: È disponibile una [Guida Rapida](https://textblob.readthedocs.io/en/dev/quickstart.html#quickstart) utile per TextBlob, consigliata agli sviluppatori Python esperti.
Quando si cerca di identificare *frasi nominali*, TextBlob offre diverse opzioni di estrattori per trovarle.
1. Dai un'occhiata a `ConllExtractor`.
```python
from textblob import TextBlob
from textblob.np_extractors import ConllExtractor
# import and create a Conll extractor to use later
extractor = ConllExtractor()
# later when you need a noun phrase extractor:
user_input = input("> ")
user_input_blob = TextBlob(user_input, np_extractor=extractor) # note non-default extractor specified
np = user_input_blob.noun_phrases
```
> Cosa sta succedendo qui? [ConllExtractor](https://textblob.readthedocs.io/en/dev/api_reference.html?highlight=Conll#textblob.en.np_extractors.ConllExtractor) è "Un estrattore di frasi nominali che utilizza il chunk parsing addestrato con il corpus di addestramento ConLL-2000." ConLL-2000 si riferisce alla Conferenza del 2000 sull'Apprendimento Computazionale del Linguaggio Naturale. Ogni anno la conferenza ospitava un workshop per affrontare un problema spinoso dell'NLP, e nel 2000 si trattava del chunking delle frasi nominali. Un modello è stato addestrato sul Wall Street Journal, con "le sezioni 15-18 come dati di addestramento (211727 token) e la sezione 20 come dati di test (47377 token)". Puoi consultare le procedure utilizzate [qui](https://www.clips.uantwerpen.be/conll2000/chunking/) e i [risultati](https://ifarm.nl/erikt/research/np-chunking.html).
### Sfida - migliorare il tuo bot con l'NLP
Nella lezione precedente hai costruito un bot di domande e risposte molto semplice. Ora, renderai Marvin un po' più empatico analizzando il tuo input per il sentimento e stampando una risposta che corrisponda al sentimento. Dovrai anche identificare una `noun_phrase` e chiedere ulteriori informazioni su di essa.
I tuoi passaggi per costruire un bot conversazionale migliore:
1. Stampa istruzioni che consigliano all'utente come interagire con il bot
2. Avvia il ciclo
1. Accetta l'input dell'utente
2. Se l'utente ha chiesto di uscire, allora esci
3. Elabora l'input dell'utente e determina una risposta appropriata basata sul sentimento
4. Se viene rilevata una frase nominale nel sentimento, pluralizzala e chiedi ulteriori informazioni su quell'argomento
5. Stampa la risposta
3. Torna al passaggio 2
Ecco il frammento di codice per determinare il sentimento utilizzando TextBlob. Nota che ci sono solo quattro *gradazioni* di risposta al sentimento (puoi aggiungerne di più se lo desideri):
```python
if user_input_blob.polarity <= -0.5:
response = "Oh dear, that sounds bad. "
elif user_input_blob.polarity <= 0:
response = "Hmm, that's not great. "
elif user_input_blob.polarity <= 0.5:
response = "Well, that sounds positive. "
elif user_input_blob.polarity <= 1:
response = "Wow, that sounds great. "
```
Ecco un esempio di output per guidarti (l'input dell'utente è sulle righe che iniziano con >):
```output
Hello, I am Marvin, the friendly robot.
You can end this conversation at any time by typing 'bye'
After typing each answer, press 'enter'
How are you today?
> I am ok
Well, that sounds positive. Can you tell me more?
> I went for a walk and saw a lovely cat
Well, that sounds positive. Can you tell me more about lovely cats?
> cats are the best. But I also have a cool dog
Wow, that sounds great. Can you tell me more about cool dogs?
> I have an old hounddog but he is sick
Hmm, that's not great. Can you tell me more about old hounddogs?
> bye
It was nice talking to you, goodbye!
```
Una possibile soluzione al compito è [qui](https://github.com/microsoft/ML-For-Beginners/blob/main/6-NLP/2-Tasks/solution/bot.py)
✅ Verifica della Conoscenza
1. Pensi che le risposte empatiche potrebbero 'ingannare' qualcuno facendogli credere che il bot li capisca realmente?
2. Identificare la frase nominale rende il bot più 'credibile'?
3. Perché estrarre una 'frase nominale' da una frase è una cosa utile da fare?
---
Implementa il bot nella verifica della conoscenza precedente e testalo su un amico. Può ingannarli? Puoi rendere il tuo bot più 'credibile'?
## 🚀Sfida
Prendi un compito nella verifica della conoscenza precedente e prova a implementarlo. Testa il bot su un amico. Può ingannarli? Puoi rendere il tuo bot più 'credibile'?
## [Quiz post-lezione](https://ff-quizzes.netlify.app/en/ml/)
## Revisione e Studio Autonomo
Nelle prossime lezioni imparerai di più sull'analisi del sentimento. Ricerca questa tecnica interessante in articoli come questi su [KDNuggets](https://www.kdnuggets.com/tag/nlp)
## Compito
[Fai parlare un bot](assignment.md)
---
**Disclaimer**:
Questo documento è stato tradotto utilizzando il servizio di traduzione automatica [Co-op Translator](https://github.com/Azure/co-op-translator). Sebbene ci impegniamo per garantire l'accuratezza, si prega di notare che le traduzioni automatiche possono contenere errori o imprecisioni. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale effettuata da un traduttore umano. Non siamo responsabili per eventuali incomprensioni o interpretazioni errate derivanti dall'uso di questa traduzione.