# Costruire un modello di regressione con Scikit-learn: quattro approcci alla regressione
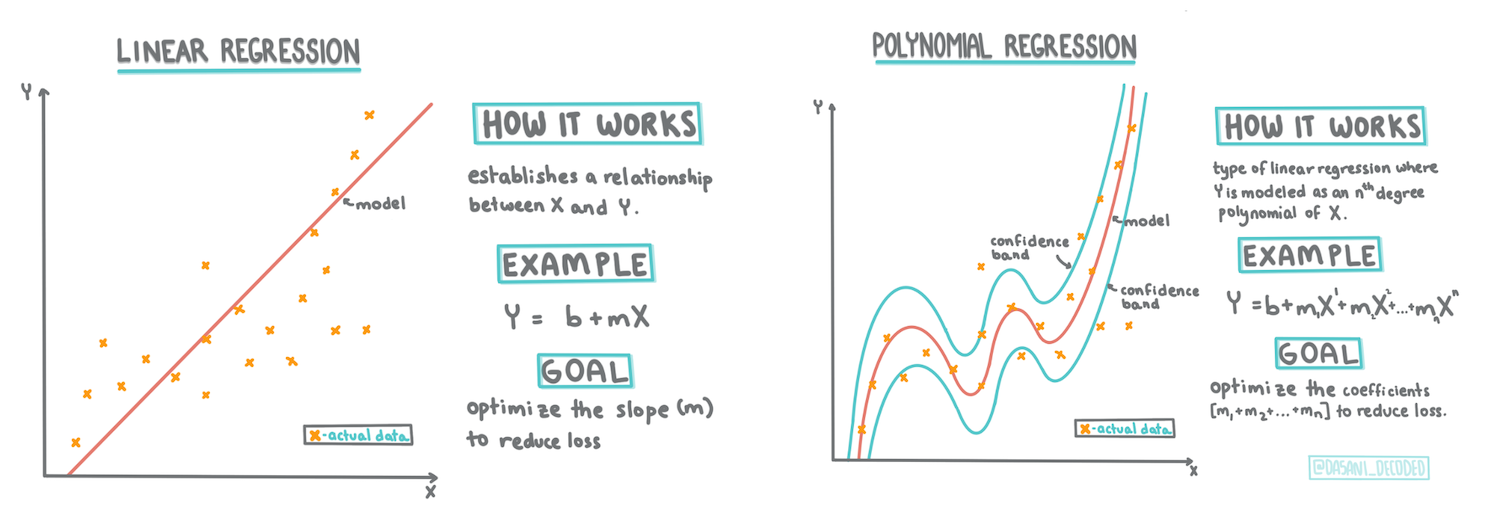
> Infografica di [Dasani Madipalli](https://twitter.com/dasani_decoded)
## [Quiz pre-lezione](https://ff-quizzes.netlify.app/en/ml/)
> ### [Questa lezione è disponibile in R!](../../../../2-Regression/3-Linear/solution/R/lesson_3.html)
### Introduzione
Finora hai esplorato cosa sia la regressione utilizzando dati di esempio raccolti dal dataset sui prezzi delle zucche che useremo per tutta questa lezione. Hai anche visualizzato i dati utilizzando Matplotlib.
Ora sei pronto per approfondire la regressione per il Machine Learning. Sebbene la visualizzazione ti permetta di comprendere i dati, il vero potere del Machine Learning risiede nell'_addestramento dei modelli_. I modelli vengono addestrati su dati storici per catturare automaticamente le dipendenze nei dati e consentono di prevedere risultati per nuovi dati che il modello non ha mai visto prima.
In questa lezione, imparerai di più su due tipi di regressione: _regressione lineare di base_ e _regressione polinomiale_, insieme ad alcune delle basi matematiche di queste tecniche. Questi modelli ci permetteranno di prevedere i prezzi delle zucche in base a diversi dati di input.
[](https://youtu.be/CRxFT8oTDMg "ML per principianti - Comprendere la regressione lineare")
> 🎥 Clicca sull'immagine sopra per una breve panoramica video sulla regressione lineare.
> In tutto questo corso, assumiamo una conoscenza minima della matematica e cerchiamo di renderla accessibile agli studenti provenienti da altri campi. Fai attenzione a note, 🧮 richiami, diagrammi e altri strumenti di apprendimento per facilitare la comprensione.
### Prerequisiti
A questo punto dovresti avere familiarità con la struttura dei dati sulle zucche che stiamo esaminando. Puoi trovarli pre-caricati e pre-puliti nel file _notebook.ipynb_ di questa lezione. Nel file, il prezzo delle zucche è mostrato per bushel in un nuovo data frame. Assicurati di poter eseguire questi notebook nei kernel di Visual Studio Code.
### Preparazione
Come promemoria, stai caricando questi dati per porre domande su di essi.
- Qual è il momento migliore per acquistare le zucche?
- Quale prezzo posso aspettarmi per una cassa di zucche in miniatura?
- Dovrei acquistarle in cesti da mezzo bushel o in scatole da 1 1/9 bushel?
Continuiamo a scavare in questi dati.
Nella lezione precedente, hai creato un data frame Pandas e lo hai popolato con una parte del dataset originale, standardizzando i prezzi per bushel. Facendo ciò, tuttavia, sei riuscito a raccogliere solo circa 400 punti dati e solo per i mesi autunnali.
Dai un'occhiata ai dati pre-caricati nel notebook associato a questa lezione. I dati sono pre-caricati e un primo scatterplot è stato tracciato per mostrare i dati mensili. Forse possiamo ottenere un po' più di dettagli sulla natura dei dati pulendoli ulteriormente.
## Una linea di regressione lineare
Come hai appreso nella Lezione 1, l'obiettivo di un esercizio di regressione lineare è tracciare una linea per:
- **Mostrare le relazioni tra variabili**. Mostrare la relazione tra le variabili
- **Fare previsioni**. Fare previsioni accurate su dove un nuovo punto dati si posizionerebbe rispetto a quella linea.
È tipico della **Regressione dei Minimi Quadrati** tracciare questo tipo di linea. Il termine 'minimi quadrati' significa che tutti i punti dati intorno alla linea di regressione vengono elevati al quadrato e poi sommati. Idealmente, quella somma finale è il più piccola possibile, perché vogliamo un numero basso di errori, o `minimi quadrati`.
Facciamo ciò perché vogliamo modellare una linea che abbia la minima distanza cumulativa da tutti i nostri punti dati. Inoltre, eleviamo al quadrato i termini prima di sommarli poiché ci interessa la loro magnitudine piuttosto che la loro direzione.
> **🧮 Mostrami la matematica**
>
> Questa linea, chiamata _linea di miglior adattamento_, può essere espressa da [un'equazione](https://en.wikipedia.org/wiki/Simple_linear_regression):
>
> ```
> Y = a + bX
> ```
>
> `X` è la 'variabile esplicativa'. `Y` è la 'variabile dipendente'. La pendenza della linea è `b` e `a` è l'intercetta sull'asse y, che si riferisce al valore di `Y` quando `X = 0`.
>
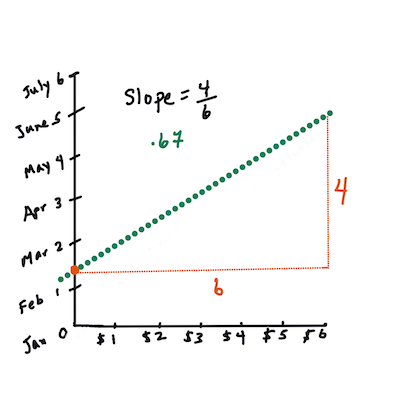
>
>
> Per prima cosa, calcola la pendenza `b`. Infografica di [Jen Looper](https://twitter.com/jenlooper)
>
> In altre parole, riferendoci alla domanda originale sui dati delle zucche: "prevedere il prezzo di una zucca per bushel in base al mese", `X` si riferirebbe al prezzo e `Y` al mese di vendita.
>
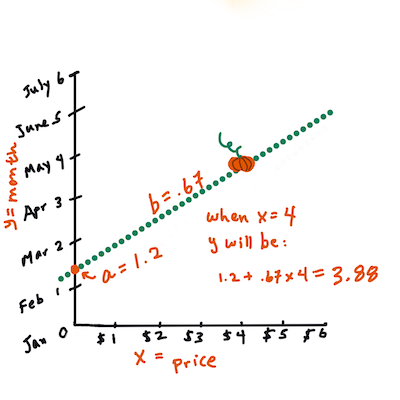
>
>
> Calcola il valore di Y. Se stai pagando circa $4, deve essere aprile! Infografica di [Jen Looper](https://twitter.com/jenlooper)
>
> La matematica che calcola la linea deve dimostrare la pendenza della linea, che dipende anche dall'intercetta, ovvero dove si trova `Y` quando `X = 0`.
>
> Puoi osservare il metodo di calcolo di questi valori sul sito [Math is Fun](https://www.mathsisfun.com/data/least-squares-regression.html). Visita anche [questo calcolatore dei minimi quadrati](https://www.mathsisfun.com/data/least-squares-calculator.html) per vedere come i valori numerici influenzano la linea.
## Correlazione
Un altro termine da comprendere è il **Coefficiente di Correlazione** tra le variabili X e Y date. Utilizzando uno scatterplot, puoi visualizzare rapidamente questo coefficiente. Un grafico con punti dati distribuiti in una linea ordinata ha un'alta correlazione, mentre un grafico con punti dati sparsi ovunque tra X e Y ha una bassa correlazione.
Un buon modello di regressione lineare sarà uno che ha un alto Coefficiente di Correlazione (più vicino a 1 che a 0) utilizzando il metodo dei Minimi Quadrati con una linea di regressione.
✅ Esegui il notebook associato a questa lezione e osserva lo scatterplot Mese-Prezzo. Secondo la tua interpretazione visiva dello scatterplot, i dati che associano il Mese al Prezzo delle vendite di zucche sembrano avere un'alta o bassa correlazione? Questo cambia se utilizzi una misura più dettagliata invece di `Mese`, ad esempio il *giorno dell'anno* (cioè il numero di giorni dall'inizio dell'anno)?
Nel codice seguente, supponiamo di aver pulito i dati e ottenuto un data frame chiamato `new_pumpkins`, simile al seguente:
ID | Mese | GiornoDellAnno | Varietà | Città | Confezione | Prezzo Basso | Prezzo Alto | Prezzo
---|-------|----------------|---------|-------|------------|--------------|-------------|-------
70 | 9 | 267 | TIPO TORTA | BALTIMORA | cartoni da 1 1/9 bushel | 15.0 | 15.0 | 13.636364
71 | 9 | 267 | TIPO TORTA | BALTIMORA | cartoni da 1 1/9 bushel | 18.0 | 18.0 | 16.363636
72 | 10 | 274 | TIPO TORTA | BALTIMORA | cartoni da 1 1/9 bushel | 18.0 | 18.0 | 16.363636
73 | 10 | 274 | TIPO TORTA | BALTIMORA | cartoni da 1 1/9 bushel | 17.0 | 17.0 | 15.454545
74 | 10 | 281 | TIPO TORTA | BALTIMORA | cartoni da 1 1/9 bushel | 15.0 | 15.0 | 13.636364
> Il codice per pulire i dati è disponibile in [`notebook.ipynb`](../../../../2-Regression/3-Linear/notebook.ipynb). Abbiamo eseguito gli stessi passaggi di pulizia della lezione precedente e calcolato la colonna `GiornoDellAnno` utilizzando la seguente espressione:
```python
day_of_year = pd.to_datetime(pumpkins['Date']).apply(lambda dt: (dt-datetime(dt.year,1,1)).days)
```
Ora che hai compreso la matematica alla base della regressione lineare, creiamo un modello di Regressione per vedere se possiamo prevedere quale confezione di zucche avrà i prezzi migliori. Qualcuno che acquista zucche per un campo di zucche per le festività potrebbe voler ottimizzare i propri acquisti di confezioni di zucche per il campo.
## Cercare la Correlazione
[](https://youtu.be/uoRq-lW2eQo "ML per principianti - Cercare la Correlazione: La Chiave della Regressione Lineare")
> 🎥 Clicca sull'immagine sopra per una breve panoramica video sulla correlazione.
Dalla lezione precedente probabilmente hai visto che il prezzo medio per i diversi mesi appare così:
 Questo suggerisce che dovrebbe esserci una certa correlazione, e possiamo provare ad addestrare un modello di regressione lineare per prevedere la relazione tra `Mese` e `Prezzo`, o tra `GiornoDellAnno` e `Prezzo`. Ecco lo scatterplot che mostra quest'ultima relazione:
Questo suggerisce che dovrebbe esserci una certa correlazione, e possiamo provare ad addestrare un modello di regressione lineare per prevedere la relazione tra `Mese` e `Prezzo`, o tra `GiornoDellAnno` e `Prezzo`. Ecco lo scatterplot che mostra quest'ultima relazione:
 Vediamo se c'è una correlazione utilizzando la funzione `corr`:
```python
print(new_pumpkins['Month'].corr(new_pumpkins['Price']))
print(new_pumpkins['DayOfYear'].corr(new_pumpkins['Price']))
```
Sembra che la correlazione sia piuttosto bassa, -0.15 per `Mese` e -0.17 per `GiornoDellAnno`, ma potrebbe esserci un'altra relazione importante. Sembra che ci siano diversi cluster di prezzi corrispondenti a diverse varietà di zucche. Per confermare questa ipotesi, tracciamo ogni categoria di zucca utilizzando un colore diverso. Passando un parametro `ax` alla funzione di tracciamento dello scatter possiamo tracciare tutti i punti sullo stesso grafico:
```python
ax=None
colors = ['red','blue','green','yellow']
for i,var in enumerate(new_pumpkins['Variety'].unique()):
df = new_pumpkins[new_pumpkins['Variety']==var]
ax = df.plot.scatter('DayOfYear','Price',ax=ax,c=colors[i],label=var)
```
Vediamo se c'è una correlazione utilizzando la funzione `corr`:
```python
print(new_pumpkins['Month'].corr(new_pumpkins['Price']))
print(new_pumpkins['DayOfYear'].corr(new_pumpkins['Price']))
```
Sembra che la correlazione sia piuttosto bassa, -0.15 per `Mese` e -0.17 per `GiornoDellAnno`, ma potrebbe esserci un'altra relazione importante. Sembra che ci siano diversi cluster di prezzi corrispondenti a diverse varietà di zucche. Per confermare questa ipotesi, tracciamo ogni categoria di zucca utilizzando un colore diverso. Passando un parametro `ax` alla funzione di tracciamento dello scatter possiamo tracciare tutti i punti sullo stesso grafico:
```python
ax=None
colors = ['red','blue','green','yellow']
for i,var in enumerate(new_pumpkins['Variety'].unique()):
df = new_pumpkins[new_pumpkins['Variety']==var]
ax = df.plot.scatter('DayOfYear','Price',ax=ax,c=colors[i],label=var)
```
 La nostra indagine suggerisce che la varietà ha un effetto maggiore sul prezzo complessivo rispetto alla data effettiva di vendita. Possiamo vedere questo con un grafico a barre:
```python
new_pumpkins.groupby('Variety')['Price'].mean().plot(kind='bar')
```
La nostra indagine suggerisce che la varietà ha un effetto maggiore sul prezzo complessivo rispetto alla data effettiva di vendita. Possiamo vedere questo con un grafico a barre:
```python
new_pumpkins.groupby('Variety')['Price'].mean().plot(kind='bar')
```
 Concentriamoci per il momento solo su una varietà di zucche, il 'tipo torta', e vediamo quale effetto ha la data sul prezzo:
```python
pie_pumpkins = new_pumpkins[new_pumpkins['Variety']=='PIE TYPE']
pie_pumpkins.plot.scatter('DayOfYear','Price')
```
Concentriamoci per il momento solo su una varietà di zucche, il 'tipo torta', e vediamo quale effetto ha la data sul prezzo:
```python
pie_pumpkins = new_pumpkins[new_pumpkins['Variety']=='PIE TYPE']
pie_pumpkins.plot.scatter('DayOfYear','Price')
```
 Se ora calcoliamo la correlazione tra `Prezzo` e `GiornoDellAnno` utilizzando la funzione `corr`, otterremo qualcosa come `-0.27` - il che significa che addestrare un modello predittivo ha senso.
> Prima di addestrare un modello di regressione lineare, è importante assicurarsi che i dati siano puliti. La regressione lineare non funziona bene con valori mancanti, quindi ha senso eliminare tutte le celle vuote:
```python
pie_pumpkins.dropna(inplace=True)
pie_pumpkins.info()
```
Un altro approccio sarebbe riempire quei valori vuoti con i valori medi della colonna corrispondente.
## Regressione Lineare Semplice
[](https://youtu.be/e4c_UP2fSjg "ML per principianti - Regressione Lineare e Polinomiale con Scikit-learn")
> 🎥 Clicca sull'immagine sopra per una breve panoramica video sulla regressione lineare e polinomiale.
Per addestrare il nostro modello di Regressione Lineare, utilizzeremo la libreria **Scikit-learn**.
```python
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
```
Iniziamo separando i valori di input (caratteristiche) e l'output atteso (etichetta) in array numpy separati:
```python
X = pie_pumpkins['DayOfYear'].to_numpy().reshape(-1,1)
y = pie_pumpkins['Price']
```
> Nota che abbiamo dovuto eseguire `reshape` sui dati di input affinché il pacchetto di Regressione Lineare li comprenda correttamente. La Regressione Lineare si aspetta un array 2D come input, dove ogni riga dell'array corrisponde a un vettore di caratteristiche di input. Nel nostro caso, poiché abbiamo solo un input, abbiamo bisogno di un array con forma N×1, dove N è la dimensione del dataset.
Poi, dobbiamo dividere i dati in dataset di addestramento e di test, in modo da poter validare il nostro modello dopo l'addestramento:
```python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
```
Infine, addestrare il modello di Regressione Lineare effettivo richiede solo due righe di codice. Definiamo l'oggetto `LinearRegression` e lo adattiamo ai nostri dati utilizzando il metodo `fit`:
```python
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)
```
L'oggetto `LinearRegression` dopo il `fit` contiene tutti i coefficienti della regressione, che possono essere accessibili utilizzando la proprietà `.coef_`. Nel nostro caso, c'è solo un coefficiente, che dovrebbe essere circa `-0.017`. Ciò significa che i prezzi sembrano diminuire leggermente nel tempo, ma non troppo, circa 2 centesimi al giorno. Possiamo anche accedere al punto di intersezione della regressione con l'asse Y utilizzando `lin_reg.intercept_` - sarà circa `21` nel nostro caso, indicando il prezzo all'inizio dell'anno.
Per vedere quanto è accurato il nostro modello, possiamo prevedere i prezzi su un dataset di test e poi misurare quanto le nostre previsioni siano vicine ai valori attesi. Questo può essere fatto utilizzando la metrica dell'errore quadratico medio (MSE), che è la media di tutte le differenze al quadrato tra il valore atteso e quello previsto.
```python
pred = lin_reg.predict(X_test)
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
```
Il nostro errore sembra concentrarsi su 2 punti, che corrispondono a circa il 17%. Non troppo buono. Un altro indicatore della qualità del modello è il **coefficiente di determinazione**, che può essere ottenuto in questo modo:
```python
score = lin_reg.score(X_train,y_train)
print('Model determination: ', score)
```
Se il valore è 0, significa che il modello non tiene conto dei dati di input e agisce come il *peggior predittore lineare*, che è semplicemente il valore medio del risultato. Il valore di 1 significa che possiamo prevedere perfettamente tutti i risultati attesi. Nel nostro caso, il coefficiente è circa 0.06, che è piuttosto basso.
Possiamo anche tracciare i dati di test insieme alla linea di regressione per vedere meglio come funziona la regressione nel nostro caso:
```python
plt.scatter(X_test,y_test)
plt.plot(X_test,pred)
```
Se ora calcoliamo la correlazione tra `Prezzo` e `GiornoDellAnno` utilizzando la funzione `corr`, otterremo qualcosa come `-0.27` - il che significa che addestrare un modello predittivo ha senso.
> Prima di addestrare un modello di regressione lineare, è importante assicurarsi che i dati siano puliti. La regressione lineare non funziona bene con valori mancanti, quindi ha senso eliminare tutte le celle vuote:
```python
pie_pumpkins.dropna(inplace=True)
pie_pumpkins.info()
```
Un altro approccio sarebbe riempire quei valori vuoti con i valori medi della colonna corrispondente.
## Regressione Lineare Semplice
[](https://youtu.be/e4c_UP2fSjg "ML per principianti - Regressione Lineare e Polinomiale con Scikit-learn")
> 🎥 Clicca sull'immagine sopra per una breve panoramica video sulla regressione lineare e polinomiale.
Per addestrare il nostro modello di Regressione Lineare, utilizzeremo la libreria **Scikit-learn**.
```python
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
```
Iniziamo separando i valori di input (caratteristiche) e l'output atteso (etichetta) in array numpy separati:
```python
X = pie_pumpkins['DayOfYear'].to_numpy().reshape(-1,1)
y = pie_pumpkins['Price']
```
> Nota che abbiamo dovuto eseguire `reshape` sui dati di input affinché il pacchetto di Regressione Lineare li comprenda correttamente. La Regressione Lineare si aspetta un array 2D come input, dove ogni riga dell'array corrisponde a un vettore di caratteristiche di input. Nel nostro caso, poiché abbiamo solo un input, abbiamo bisogno di un array con forma N×1, dove N è la dimensione del dataset.
Poi, dobbiamo dividere i dati in dataset di addestramento e di test, in modo da poter validare il nostro modello dopo l'addestramento:
```python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
```
Infine, addestrare il modello di Regressione Lineare effettivo richiede solo due righe di codice. Definiamo l'oggetto `LinearRegression` e lo adattiamo ai nostri dati utilizzando il metodo `fit`:
```python
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)
```
L'oggetto `LinearRegression` dopo il `fit` contiene tutti i coefficienti della regressione, che possono essere accessibili utilizzando la proprietà `.coef_`. Nel nostro caso, c'è solo un coefficiente, che dovrebbe essere circa `-0.017`. Ciò significa che i prezzi sembrano diminuire leggermente nel tempo, ma non troppo, circa 2 centesimi al giorno. Possiamo anche accedere al punto di intersezione della regressione con l'asse Y utilizzando `lin_reg.intercept_` - sarà circa `21` nel nostro caso, indicando il prezzo all'inizio dell'anno.
Per vedere quanto è accurato il nostro modello, possiamo prevedere i prezzi su un dataset di test e poi misurare quanto le nostre previsioni siano vicine ai valori attesi. Questo può essere fatto utilizzando la metrica dell'errore quadratico medio (MSE), che è la media di tutte le differenze al quadrato tra il valore atteso e quello previsto.
```python
pred = lin_reg.predict(X_test)
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
```
Il nostro errore sembra concentrarsi su 2 punti, che corrispondono a circa il 17%. Non troppo buono. Un altro indicatore della qualità del modello è il **coefficiente di determinazione**, che può essere ottenuto in questo modo:
```python
score = lin_reg.score(X_train,y_train)
print('Model determination: ', score)
```
Se il valore è 0, significa che il modello non tiene conto dei dati di input e agisce come il *peggior predittore lineare*, che è semplicemente il valore medio del risultato. Il valore di 1 significa che possiamo prevedere perfettamente tutti i risultati attesi. Nel nostro caso, il coefficiente è circa 0.06, che è piuttosto basso.
Possiamo anche tracciare i dati di test insieme alla linea di regressione per vedere meglio come funziona la regressione nel nostro caso:
```python
plt.scatter(X_test,y_test)
plt.plot(X_test,pred)
```
 ## Regressione Polinomiale
Un altro tipo di Regressione Lineare è la Regressione Polinomiale. Sebbene a volte ci sia una relazione lineare tra le variabili - più grande è il volume della zucca, più alto è il prezzo - a volte queste relazioni non possono essere rappresentate come un piano o una linea retta.
✅ Ecco [alcuni esempi](https://online.stat.psu.edu/stat501/lesson/9/9.8) di dati che potrebbero utilizzare la Regressione Polinomiale.
Osserva di nuovo la relazione tra Data e Prezzo. Questo scatterplot sembra necessariamente analizzabile con una linea retta? I prezzi non possono fluttuare? In questo caso, puoi provare la regressione polinomiale.
✅ I polinomi sono espressioni matematiche che possono consistere in una o più variabili e coefficienti.
La regressione polinomiale crea una linea curva per adattarsi meglio ai dati non lineari. Nel nostro caso, se includiamo una variabile `DayOfYear` al quadrato nei dati di input, dovremmo essere in grado di adattare i nostri dati con una curva parabolica, che avrà un minimo in un certo punto dell'anno.
Scikit-learn include una comoda [API pipeline](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.make_pipeline.html?highlight=pipeline#sklearn.pipeline.make_pipeline) per combinare insieme diversi passaggi di elaborazione dei dati. Una **pipeline** è una catena di **stimatori**. Nel nostro caso, creeremo una pipeline che prima aggiunge caratteristiche polinomiali al nostro modello e poi addestra la regressione:
```python
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
```
Usare `PolynomialFeatures(2)` significa che includeremo tutti i polinomi di secondo grado dai dati di input. Nel nostro caso, significherà semplicemente `DayOfYear`2, ma dato due variabili di input X e Y, questo aggiungerà X2, XY e Y2. Possiamo anche utilizzare polinomi di grado superiore se lo desideriamo.
Le pipeline possono essere utilizzate nello stesso modo dell'oggetto originale `LinearRegression`, ovvero possiamo `fit` la pipeline e poi usare `predict` per ottenere i risultati della previsione. Ecco il grafico che mostra i dati di test e la curva di approssimazione:
## Regressione Polinomiale
Un altro tipo di Regressione Lineare è la Regressione Polinomiale. Sebbene a volte ci sia una relazione lineare tra le variabili - più grande è il volume della zucca, più alto è il prezzo - a volte queste relazioni non possono essere rappresentate come un piano o una linea retta.
✅ Ecco [alcuni esempi](https://online.stat.psu.edu/stat501/lesson/9/9.8) di dati che potrebbero utilizzare la Regressione Polinomiale.
Osserva di nuovo la relazione tra Data e Prezzo. Questo scatterplot sembra necessariamente analizzabile con una linea retta? I prezzi non possono fluttuare? In questo caso, puoi provare la regressione polinomiale.
✅ I polinomi sono espressioni matematiche che possono consistere in una o più variabili e coefficienti.
La regressione polinomiale crea una linea curva per adattarsi meglio ai dati non lineari. Nel nostro caso, se includiamo una variabile `DayOfYear` al quadrato nei dati di input, dovremmo essere in grado di adattare i nostri dati con una curva parabolica, che avrà un minimo in un certo punto dell'anno.
Scikit-learn include una comoda [API pipeline](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.make_pipeline.html?highlight=pipeline#sklearn.pipeline.make_pipeline) per combinare insieme diversi passaggi di elaborazione dei dati. Una **pipeline** è una catena di **stimatori**. Nel nostro caso, creeremo una pipeline che prima aggiunge caratteristiche polinomiali al nostro modello e poi addestra la regressione:
```python
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
```
Usare `PolynomialFeatures(2)` significa che includeremo tutti i polinomi di secondo grado dai dati di input. Nel nostro caso, significherà semplicemente `DayOfYear`2, ma dato due variabili di input X e Y, questo aggiungerà X2, XY e Y2. Possiamo anche utilizzare polinomi di grado superiore se lo desideriamo.
Le pipeline possono essere utilizzate nello stesso modo dell'oggetto originale `LinearRegression`, ovvero possiamo `fit` la pipeline e poi usare `predict` per ottenere i risultati della previsione. Ecco il grafico che mostra i dati di test e la curva di approssimazione:
 Usando la Regressione Polinomiale, possiamo ottenere un MSE leggermente più basso e un coefficiente di determinazione più alto, ma non significativamente. Dobbiamo tenere conto di altre caratteristiche!
> Puoi vedere che i prezzi minimi delle zucche si osservano intorno a Halloween. Come puoi spiegare questo?
🎃 Congratulazioni, hai appena creato un modello che può aiutare a prevedere il prezzo delle zucche per torte. Probabilmente puoi ripetere la stessa procedura per tutti i tipi di zucche, ma sarebbe noioso. Ora impariamo come tenere conto della varietà di zucche nel nostro modello!
## Caratteristiche Categoriali
In un mondo ideale, vogliamo essere in grado di prevedere i prezzi per diverse varietà di zucche utilizzando lo stesso modello. Tuttavia, la colonna `Variety` è un po' diversa dalle colonne come `Month`, perché contiene valori non numerici. Queste colonne sono chiamate **categoriali**.
[](https://youtu.be/DYGliioIAE0 "ML per principianti - Previsioni con caratteristiche categoriali usando la Regressione Lineare")
> 🎥 Clicca sull'immagine sopra per una breve panoramica video sull'uso delle caratteristiche categoriali.
Qui puoi vedere come il prezzo medio dipende dalla varietà:
Per tenere conto della varietà, dobbiamo prima convertirla in forma numerica, o **codificarla**. Ci sono diversi modi per farlo:
* La **codifica numerica semplice** costruirà una tabella delle diverse varietà e sostituirà il nome della varietà con un indice in quella tabella. Questo non è l'ideale per la regressione lineare, perché la regressione lineare prende il valore numerico effettivo dell'indice e lo aggiunge al risultato, moltiplicandolo per un coefficiente. Nel nostro caso, la relazione tra il numero dell'indice e il prezzo è chiaramente non lineare, anche se ci assicuriamo che gli indici siano ordinati in un modo specifico.
* La **codifica one-hot** sostituirà la colonna `Variety` con 4 colonne diverse, una per ogni varietà. Ogni colonna conterrà `1` se la riga corrispondente appartiene a una data varietà, e `0` altrimenti. Questo significa che ci saranno quattro coefficienti nella regressione lineare, uno per ogni varietà di zucca, responsabile del "prezzo iniziale" (o piuttosto "prezzo aggiuntivo") per quella particolare varietà.
Il codice seguente mostra come possiamo codificare una varietà con il metodo one-hot:
```python
pd.get_dummies(new_pumpkins['Variety'])
```
ID | FAIRYTALE | MINIATURE | MIXED HEIRLOOM VARIETIES | PIE TYPE
----|-----------|-----------|--------------------------|----------
70 | 0 | 0 | 0 | 1
71 | 0 | 0 | 0 | 1
... | ... | ... | ... | ...
1738 | 0 | 1 | 0 | 0
1739 | 0 | 1 | 0 | 0
1740 | 0 | 1 | 0 | 0
1741 | 0 | 1 | 0 | 0
1742 | 0 | 1 | 0 | 0
Per addestrare la regressione lineare utilizzando la varietà codificata one-hot come input, dobbiamo solo inizializzare correttamente i dati `X` e `y`:
```python
X = pd.get_dummies(new_pumpkins['Variety'])
y = new_pumpkins['Price']
```
Il resto del codice è lo stesso di quello che abbiamo usato sopra per addestrare la Regressione Lineare. Se lo provi, vedrai che l'errore quadratico medio è più o meno lo stesso, ma otteniamo un coefficiente di determinazione molto più alto (~77%). Per ottenere previsioni ancora più accurate, possiamo tenere conto di più caratteristiche categoriali, così come di caratteristiche numeriche, come `Month` o `DayOfYear`. Per ottenere un grande array di caratteristiche, possiamo usare `join`:
```python
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
```
Qui teniamo conto anche di `City` e del tipo di `Package`, il che ci dà un MSE di 2.84 (10%) e un coefficiente di determinazione di 0.94!
## Mettere tutto insieme
Per creare il miglior modello, possiamo utilizzare dati combinati (categoriali codificati one-hot + numerici) dall'esempio sopra insieme alla Regressione Polinomiale. Ecco il codice completo per tua comodità:
```python
# set up training data
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
# make train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# setup and train the pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
# predict results for test data
pred = pipeline.predict(X_test)
# calculate MSE and determination
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
score = pipeline.score(X_train,y_train)
print('Model determination: ', score)
```
Questo dovrebbe darci il miglior coefficiente di determinazione di quasi 97% e MSE=2.23 (~8% di errore di previsione).
| Modello | MSE | Determinazione |
|---------|-----|----------------|
| `DayOfYear` Lineare | 2.77 (17.2%) | 0.07 |
| `DayOfYear` Polinomiale | 2.73 (17.0%) | 0.08 |
| `Variety` Lineare | 5.24 (19.7%) | 0.77 |
| Tutte le caratteristiche Lineare | 2.84 (10.5%) | 0.94 |
| Tutte le caratteristiche Polinomiale | 2.23 (8.25%) | 0.97 |
🏆 Ben fatto! Hai creato quattro modelli di Regressione in una lezione e migliorato la qualità del modello fino al 97%. Nella sezione finale sulla Regressione, imparerai la Regressione Logistica per determinare le categorie.
---
## 🚀Sfida
Testa diverse variabili in questo notebook per vedere come la correlazione corrisponde alla precisione del modello.
## [Quiz post-lezione](https://ff-quizzes.netlify.app/en/ml/)
## Revisione & Studio Autonomo
In questa lezione abbiamo imparato la Regressione Lineare. Esistono altri tipi importanti di Regressione. Leggi le tecniche Stepwise, Ridge, Lasso ed Elasticnet. Un buon corso per approfondire è il [corso di Stanford Statistical Learning](https://online.stanford.edu/courses/sohs-ystatslearning-statistical-learning).
## Compito
[Costruisci un Modello](assignment.md)
---
**Disclaimer**:
Questo documento è stato tradotto utilizzando il servizio di traduzione automatica [Co-op Translator](https://github.com/Azure/co-op-translator). Sebbene ci impegniamo per garantire l'accuratezza, si prega di notare che le traduzioni automatiche possono contenere errori o imprecisioni. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale effettuata da un traduttore umano. Non siamo responsabili per eventuali fraintendimenti o interpretazioni errate derivanti dall'uso di questa traduzione.
Usando la Regressione Polinomiale, possiamo ottenere un MSE leggermente più basso e un coefficiente di determinazione più alto, ma non significativamente. Dobbiamo tenere conto di altre caratteristiche!
> Puoi vedere che i prezzi minimi delle zucche si osservano intorno a Halloween. Come puoi spiegare questo?
🎃 Congratulazioni, hai appena creato un modello che può aiutare a prevedere il prezzo delle zucche per torte. Probabilmente puoi ripetere la stessa procedura per tutti i tipi di zucche, ma sarebbe noioso. Ora impariamo come tenere conto della varietà di zucche nel nostro modello!
## Caratteristiche Categoriali
In un mondo ideale, vogliamo essere in grado di prevedere i prezzi per diverse varietà di zucche utilizzando lo stesso modello. Tuttavia, la colonna `Variety` è un po' diversa dalle colonne come `Month`, perché contiene valori non numerici. Queste colonne sono chiamate **categoriali**.
[](https://youtu.be/DYGliioIAE0 "ML per principianti - Previsioni con caratteristiche categoriali usando la Regressione Lineare")
> 🎥 Clicca sull'immagine sopra per una breve panoramica video sull'uso delle caratteristiche categoriali.
Qui puoi vedere come il prezzo medio dipende dalla varietà:
Per tenere conto della varietà, dobbiamo prima convertirla in forma numerica, o **codificarla**. Ci sono diversi modi per farlo:
* La **codifica numerica semplice** costruirà una tabella delle diverse varietà e sostituirà il nome della varietà con un indice in quella tabella. Questo non è l'ideale per la regressione lineare, perché la regressione lineare prende il valore numerico effettivo dell'indice e lo aggiunge al risultato, moltiplicandolo per un coefficiente. Nel nostro caso, la relazione tra il numero dell'indice e il prezzo è chiaramente non lineare, anche se ci assicuriamo che gli indici siano ordinati in un modo specifico.
* La **codifica one-hot** sostituirà la colonna `Variety` con 4 colonne diverse, una per ogni varietà. Ogni colonna conterrà `1` se la riga corrispondente appartiene a una data varietà, e `0` altrimenti. Questo significa che ci saranno quattro coefficienti nella regressione lineare, uno per ogni varietà di zucca, responsabile del "prezzo iniziale" (o piuttosto "prezzo aggiuntivo") per quella particolare varietà.
Il codice seguente mostra come possiamo codificare una varietà con il metodo one-hot:
```python
pd.get_dummies(new_pumpkins['Variety'])
```
ID | FAIRYTALE | MINIATURE | MIXED HEIRLOOM VARIETIES | PIE TYPE
----|-----------|-----------|--------------------------|----------
70 | 0 | 0 | 0 | 1
71 | 0 | 0 | 0 | 1
... | ... | ... | ... | ...
1738 | 0 | 1 | 0 | 0
1739 | 0 | 1 | 0 | 0
1740 | 0 | 1 | 0 | 0
1741 | 0 | 1 | 0 | 0
1742 | 0 | 1 | 0 | 0
Per addestrare la regressione lineare utilizzando la varietà codificata one-hot come input, dobbiamo solo inizializzare correttamente i dati `X` e `y`:
```python
X = pd.get_dummies(new_pumpkins['Variety'])
y = new_pumpkins['Price']
```
Il resto del codice è lo stesso di quello che abbiamo usato sopra per addestrare la Regressione Lineare. Se lo provi, vedrai che l'errore quadratico medio è più o meno lo stesso, ma otteniamo un coefficiente di determinazione molto più alto (~77%). Per ottenere previsioni ancora più accurate, possiamo tenere conto di più caratteristiche categoriali, così come di caratteristiche numeriche, come `Month` o `DayOfYear`. Per ottenere un grande array di caratteristiche, possiamo usare `join`:
```python
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
```
Qui teniamo conto anche di `City` e del tipo di `Package`, il che ci dà un MSE di 2.84 (10%) e un coefficiente di determinazione di 0.94!
## Mettere tutto insieme
Per creare il miglior modello, possiamo utilizzare dati combinati (categoriali codificati one-hot + numerici) dall'esempio sopra insieme alla Regressione Polinomiale. Ecco il codice completo per tua comodità:
```python
# set up training data
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
# make train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# setup and train the pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
# predict results for test data
pred = pipeline.predict(X_test)
# calculate MSE and determination
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
score = pipeline.score(X_train,y_train)
print('Model determination: ', score)
```
Questo dovrebbe darci il miglior coefficiente di determinazione di quasi 97% e MSE=2.23 (~8% di errore di previsione).
| Modello | MSE | Determinazione |
|---------|-----|----------------|
| `DayOfYear` Lineare | 2.77 (17.2%) | 0.07 |
| `DayOfYear` Polinomiale | 2.73 (17.0%) | 0.08 |
| `Variety` Lineare | 5.24 (19.7%) | 0.77 |
| Tutte le caratteristiche Lineare | 2.84 (10.5%) | 0.94 |
| Tutte le caratteristiche Polinomiale | 2.23 (8.25%) | 0.97 |
🏆 Ben fatto! Hai creato quattro modelli di Regressione in una lezione e migliorato la qualità del modello fino al 97%. Nella sezione finale sulla Regressione, imparerai la Regressione Logistica per determinare le categorie.
---
## 🚀Sfida
Testa diverse variabili in questo notebook per vedere come la correlazione corrisponde alla precisione del modello.
## [Quiz post-lezione](https://ff-quizzes.netlify.app/en/ml/)
## Revisione & Studio Autonomo
In questa lezione abbiamo imparato la Regressione Lineare. Esistono altri tipi importanti di Regressione. Leggi le tecniche Stepwise, Ridge, Lasso ed Elasticnet. Un buon corso per approfondire è il [corso di Stanford Statistical Learning](https://online.stanford.edu/courses/sohs-ystatslearning-statistical-learning).
## Compito
[Costruisci un Modello](assignment.md)
---
**Disclaimer**:
Questo documento è stato tradotto utilizzando il servizio di traduzione automatica [Co-op Translator](https://github.com/Azure/co-op-translator). Sebbene ci impegniamo per garantire l'accuratezza, si prega di notare che le traduzioni automatiche possono contenere errori o imprecisioni. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale effettuata da un traduttore umano. Non siamo responsabili per eventuali fraintendimenti o interpretazioni errate derivanti dall'uso di questa traduzione.