# क्यूज़ीन रिकमेंडर वेब ऐप बनाएं
इस पाठ में, आप पिछले पाठों में सीखी गई तकनीकों का उपयोग करके एक वर्गीकरण मॉडल बनाएंगे और इस श्रृंखला में उपयोग किए गए स्वादिष्ट क्यूज़ीन डेटासेट के साथ काम करेंगे। इसके अलावा, आप एक छोटा वेब ऐप बनाएंगे जो सेव किए गए मॉडल का उपयोग करेगा, और Onnx के वेब रनटाइम का लाभ उठाएगा।
मशीन लर्निंग का एक सबसे उपयोगी व्यावहारिक उपयोग रिकमेंडेशन सिस्टम बनाना है, और आप आज उस दिशा में पहला कदम उठा सकते हैं!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 ऊपर दी गई छवि पर क्लिक करें वीडियो के लिए: जेन लूपर वर्गीकृत क्यूज़ीन डेटा का उपयोग करके एक वेब ऐप बनाती हैं
## [प्री-लेक्चर क्विज़](https://ff-quizzes.netlify.app/en/ml/)
इस पाठ में आप सीखेंगे:
- कैसे एक मॉडल बनाएं और उसे Onnx मॉडल के रूप में सेव करें
- कैसे Netron का उपयोग करके मॉडल का निरीक्षण करें
- कैसे अपने मॉडल को वेब ऐप में उपयोग करें
## अपना मॉडल बनाएं
व्यावसायिक सिस्टम के लिए इन तकनीकों का लाभ उठाने के लिए एप्लाइड ML सिस्टम बनाना एक महत्वपूर्ण हिस्सा है। आप अपने वेब एप्लिकेशन में मॉडल का उपयोग कर सकते हैं (और यदि आवश्यक हो तो ऑफलाइन संदर्भ में भी उपयोग कर सकते हैं) Onnx का उपयोग करके।
एक [पिछले पाठ](../../3-Web-App/1-Web-App/README.md) में, आपने UFO sightings पर एक रिग्रेशन मॉडल बनाया था, उसे "पिकल्ड" किया था, और फ्लास्क ऐप में उपयोग किया था। जबकि यह आर्किटेक्चर जानने के लिए बहुत उपयोगी है, यह एक फुल-स्टैक पायथन ऐप है, और आपकी आवश्यकताओं में जावास्क्रिप्ट एप्लिकेशन का उपयोग शामिल हो सकता है।
इस पाठ में, आप इन्फरेंस के लिए एक बुनियादी जावास्क्रिप्ट-आधारित सिस्टम बना सकते हैं। लेकिन पहले, आपको एक मॉडल को प्रशिक्षित करना होगा और उसे Onnx के साथ उपयोग के लिए कनवर्ट करना होगा।
## अभ्यास - वर्गीकरण मॉडल को प्रशिक्षित करें
सबसे पहले, उस साफ किए गए क्यूज़ीन डेटासेट का उपयोग करके एक वर्गीकरण मॉडल को प्रशिक्षित करें जिसे हमने उपयोग किया था।
1. उपयोगी लाइब्रेरीज़ को इम्पोर्ट करके शुरू करें:
```python
!pip install skl2onnx
import pandas as pd
```
आपको '[skl2onnx](https://onnx.ai/sklearn-onnx/)' की आवश्यकता होगी ताकि आप अपने Scikit-learn मॉडल को Onnx फॉर्मेट में कनवर्ट कर सकें।
1. फिर, अपने डेटा के साथ उसी तरह काम करें जैसे आपने पिछले पाठों में किया था, `read_csv()` का उपयोग करके एक CSV फ़ाइल पढ़ें:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. पहले दो अनावश्यक कॉलम को हटा दें और शेष डेटा को 'X' के रूप में सेव करें:
```python
X = data.iloc[:,2:]
X.head()
```
1. लेबल्स को 'y' के रूप में सेव करें:
```python
y = data[['cuisine']]
y.head()
```
### प्रशिक्षण प्रक्रिया शुरू करें
हम 'SVC' लाइब्रेरी का उपयोग करेंगे जिसमें अच्छी सटीकता है।
1. Scikit-learn से उपयुक्त लाइब्रेरीज़ को इम्पोर्ट करें:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. प्रशिक्षण और परीक्षण सेट को अलग करें:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. पिछले पाठ में किए गए तरीके से एक SVC वर्गीकरण मॉडल बनाएं:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. अब, अपने मॉडल का परीक्षण करें, `predict()` को कॉल करें:
```python
y_pred = model.predict(X_test)
```
1. मॉडल की गुणवत्ता की जांच करने के लिए एक वर्गीकरण रिपोर्ट प्रिंट करें:
```python
print(classification_report(y_test,y_pred))
```
जैसा कि हमने पहले देखा, सटीकता अच्छी है:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### अपने मॉडल को Onnx में कनवर्ट करें
सुनिश्चित करें कि कनवर्ज़न सही टेंसर नंबर के साथ किया गया है। इस डेटासेट में 380 सामग्री सूचीबद्ध हैं, इसलिए आपको `FloatTensorType` में उस नंबर को नोट करना होगा:
1. 380 टेंसर नंबर का उपयोग करके कनवर्ट करें।
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. onx बनाएं और इसे **model.onnx** फ़ाइल के रूप में सेव करें:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> ध्यान दें, आप अपने कनवर्ज़न स्क्रिप्ट में [विकल्प](https://onnx.ai/sklearn-onnx/parameterized.html) पास कर सकते हैं। इस मामले में, हमने 'nocl' को True और 'zipmap' को False सेट किया। चूंकि यह एक वर्गीकरण मॉडल है, आपके पास ZipMap को हटाने का विकल्प है जो डिक्शनरी की सूची बनाता है (आवश्यक नहीं)। `nocl` का मतलब है कि मॉडल में क्लास जानकारी शामिल है। `nocl` को 'True' सेट करके अपने मॉडल का आकार कम करें।
पूरे नोटबुक को चलाने से अब एक Onnx मॉडल बनेगा और इसे इस फ़ोल्डर में सेव किया जाएगा।
## अपने मॉडल को देखें
Onnx मॉडल Visual Studio Code में बहुत स्पष्ट नहीं होते हैं, लेकिन एक बहुत अच्छा मुफ्त सॉफ़्टवेयर है जिसे कई शोधकर्ता अपने मॉडल को देखने के लिए उपयोग करते हैं ताकि यह सुनिश्चित किया जा सके कि यह सही तरीके से बना है। [Netron](https://github.com/lutzroeder/Netron) डाउनलोड करें और अपनी model.onnx फ़ाइल खोलें। आप अपने सरल मॉडल को विज़ुअलाइज़ कर सकते हैं, जिसमें इसके 380 इनपुट और वर्गीकर्ता सूचीबद्ध हैं:

Netron आपके मॉडल को देखने के लिए एक उपयोगी टूल है।
अब आप इस शानदार मॉडल को एक वेब ऐप में उपयोग करने के लिए तैयार हैं। चलिए एक ऐसा ऐप बनाते हैं जो आपके फ्रिज में देखे गए सामग्री के संयोजन को निर्धारित करने में मदद करता है कि कौन सा क्यूज़ीन आपके मॉडल द्वारा सुझाया गया है।
## रिकमेंडर वेब एप्लिकेशन बनाएं
आप अपने मॉडल को सीधे एक वेब ऐप में उपयोग कर सकते हैं। यह आर्किटेक्चर आपको इसे लोकल और यहां तक कि ऑफलाइन भी चलाने की अनुमति देता है। उस फ़ोल्डर में एक `index.html` फ़ाइल बनाकर शुरू करें जहां आपने अपनी `model.onnx` फ़ाइल सेव की है।
1. इस फ़ाइल _index.html_ में निम्न मार्कअप जोड़ें:
```html
Cuisine Matcher
...
```
1. अब, `body` टैग के भीतर काम करते हुए, कुछ सामग्री को दिखाने के लिए चेकबॉक्स की एक सूची जोड़ें:
```html
Check your refrigerator. What can you create?
```
ध्यान दें कि प्रत्येक चेकबॉक्स को एक वैल्यू दी गई है। यह उस इंडेक्स को दर्शाता है जहां सामग्री डेटासेट के अनुसार पाई जाती है। उदाहरण के लिए, Apple इस अल्फाबेटिक सूची में पांचवें कॉलम पर है, इसलिए इसकी वैल्यू '4' है क्योंकि हम 0 से गिनती शुरू करते हैं। आप [ingredients spreadsheet](../../../../4-Classification/data/ingredient_indexes.csv) को देखकर किसी सामग्री का इंडेक्स पता कर सकते हैं।
अपने काम को index.html फ़ाइल में जारी रखते हुए, एक स्क्रिप्ट ब्लॉक जोड़ें जहां मॉडल को अंतिम बंद `` के बाद कॉल किया जाता है।
1. सबसे पहले, [Onnx Runtime](https://www.onnxruntime.ai/) को इम्पोर्ट करें:
```html
```
> Onnx Runtime का उपयोग आपके Onnx मॉडल को विभिन्न हार्डवेयर प्लेटफॉर्म पर चलाने के लिए किया जाता है, जिसमें ऑप्टिमाइज़ेशन और उपयोग के लिए API शामिल है।
1. एक बार Runtime सेट हो जाने के बाद, आप इसे कॉल कर सकते हैं:
```html
```
इस कोड में, कई चीजें हो रही हैं:
1. आपने 380 संभावित वैल्यूज़ (1 या 0) का एक ऐरे बनाया जिसे इन्फरेंस के लिए मॉडल को भेजा जाएगा, यह इस बात पर निर्भर करता है कि सामग्री का चेकबॉक्स चेक किया गया है या नहीं।
2. आपने चेकबॉक्स का एक ऐरे बनाया और एक तरीका जिससे यह पता लगाया जा सके कि वे चेक किए गए हैं या नहीं, एक `init` फ़ंक्शन में जिसे एप्लिकेशन शुरू होने पर कॉल किया जाता है। जब कोई चेकबॉक्स चेक किया जाता है, तो `ingredients` ऐरे को चुनी गई सामग्री को दर्शाने के लिए बदला जाता है।
3. आपने एक `testCheckboxes` फ़ंक्शन बनाया जो जांचता है कि कोई चेकबॉक्स चेक किया गया है या नहीं।
4. आप `startInference` फ़ंक्शन का उपयोग करते हैं जब बटन दबाया जाता है और, यदि कोई चेकबॉक्स चेक किया गया है, तो आप इन्फरेंस शुरू करते हैं।
5. इन्फरेंस प्रक्रिया में शामिल हैं:
1. मॉडल को असिंक्रोनस रूप से लोड करना
2. मॉडल को भेजने के लिए एक टेंसर संरचना बनाना
3. 'feeds' बनाना जो उस `float_input` इनपुट को दर्शाता है जिसे आपने अपने मॉडल को प्रशिक्षित करते समय बनाया था (आप Netron का उपयोग करके उस नाम को सत्यापित कर सकते हैं)
4. इन 'feeds' को मॉडल में भेजना और प्रतिक्रिया की प्रतीक्षा करना
## अपने एप्लिकेशन का परीक्षण करें
Visual Studio Code में उस फ़ोल्डर में एक टर्मिनल सत्र खोलें जहां आपकी index.html फ़ाइल स्थित है। सुनिश्चित करें कि आपने [http-server](https://www.npmjs.com/package/http-server) को ग्लोबली इंस्टॉल किया है, और प्रॉम्प्ट पर `http-server` टाइप करें। एक लोकलहोस्ट खुलना चाहिए और आप अपने वेब ऐप को देख सकते हैं। विभिन्न सामग्री के आधार पर कौन सा क्यूज़ीन सुझाया गया है, यह जांचें:
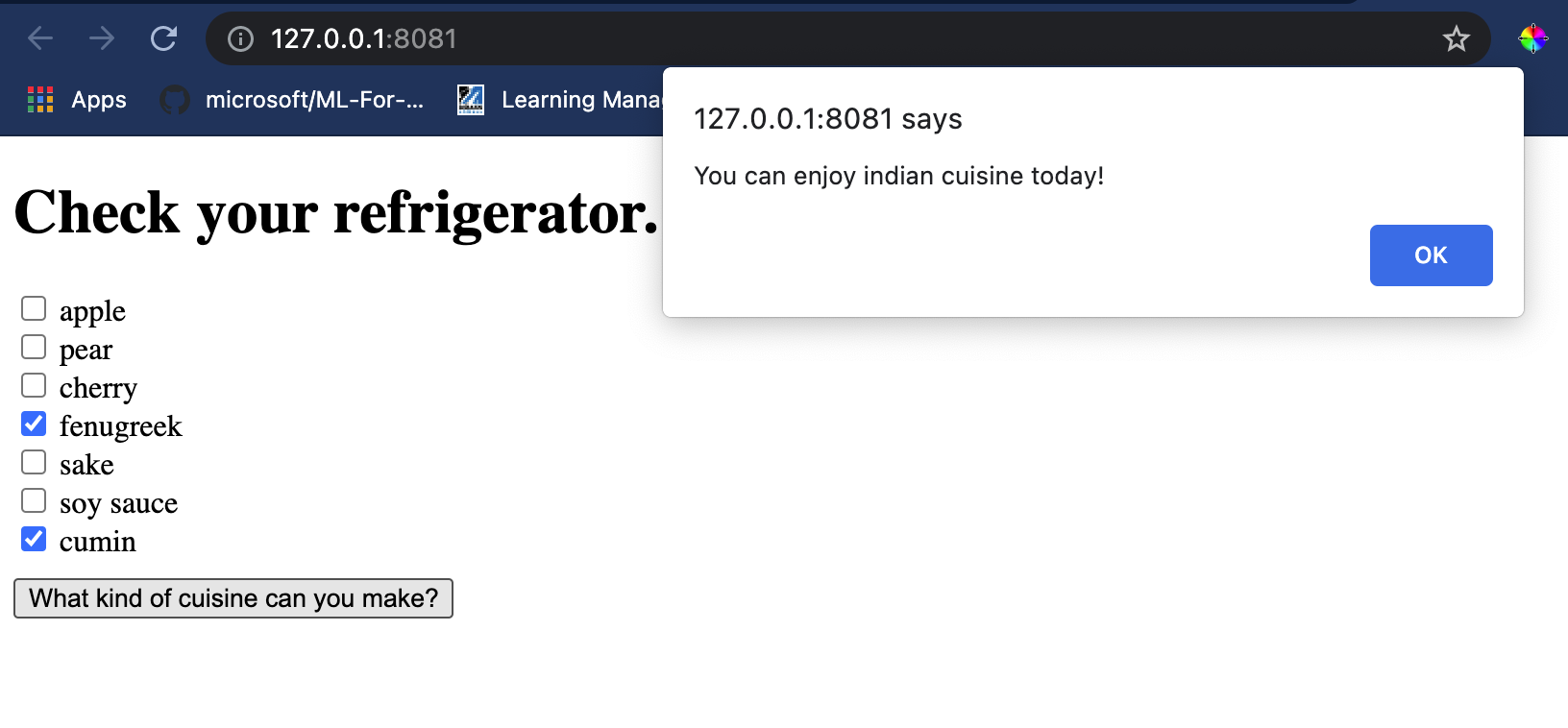
बधाई हो, आपने कुछ फ़ील्ड्स के साथ एक 'रिकमेंडेशन' वेब ऐप बनाया है। इस सिस्टम को बनाने में कुछ समय लगाएं!
## 🚀चुनौती
आपका वेब ऐप बहुत साधारण है, इसलिए इसे [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv) डेटा से सामग्री और उनके इंडेक्स का उपयोग करके और विकसित करें। कौन से फ्लेवर संयोजन एक दिए गए राष्ट्रीय व्यंजन को बनाने के लिए काम करते हैं?
## [पोस्ट-लेक्चर क्विज़](https://ff-quizzes.netlify.app/en/ml/)
## समीक्षा और स्व-अध्ययन
हालांकि इस पाठ ने खाद्य सामग्री के लिए एक रिकमेंडेशन सिस्टम बनाने की उपयोगिता को केवल छुआ है, इस क्षेत्र में ML एप्लिकेशन के उदाहरण बहुत समृद्ध हैं। पढ़ें कि ये सिस्टम कैसे बनाए जाते हैं:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## असाइनमेंट
[एक नया रिकमेंडर बनाएं](assignment.md)
---
**अस्वीकरण**:
यह दस्तावेज़ AI अनुवाद सेवा [Co-op Translator](https://github.com/Azure/co-op-translator) का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता के लिए प्रयासरत हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।