# Scikit-learn का उपयोग करके एक रिग्रेशन मॉडल बनाएं: चार तरीकों से रिग्रेशन
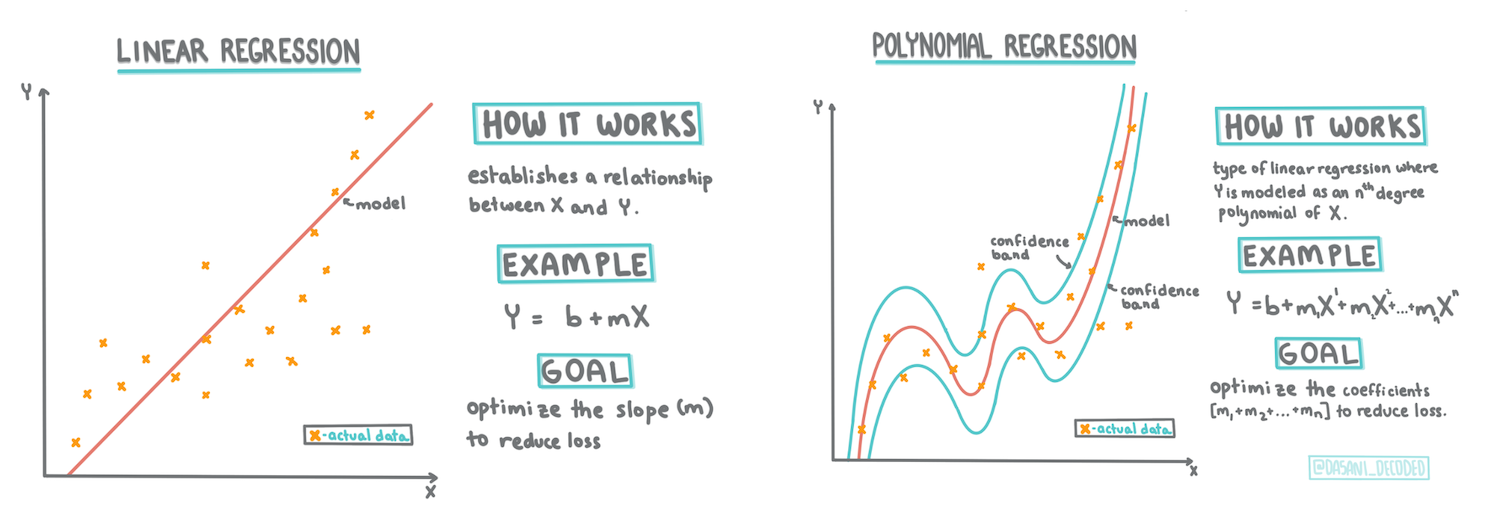
> इन्फोग्राफिक: [दसानी मडिपल्ली](https://twitter.com/dasani_decoded)
## [प्री-लेक्चर क्विज़](https://ff-quizzes.netlify.app/en/ml/)
> ### [यह पाठ R में भी उपलब्ध है!](../../../../2-Regression/3-Linear/solution/R/lesson_3.html)
### परिचय
अब तक आपने कद्दू की कीमतों के डेटा का उपयोग करके रिग्रेशन के बारे में जाना और इसे Matplotlib का उपयोग करके विज़ुअलाइज़ किया।
अब आप मशीन लर्निंग के लिए रिग्रेशन को गहराई से समझने के लिए तैयार हैं। जबकि विज़ुअलाइज़ेशन डेटा को समझने में मदद करता है, मशीन लर्निंग की असली ताकत _मॉडल को ट्रेन करने_ में है। मॉडल ऐतिहासिक डेटा पर प्रशिक्षित होते हैं ताकि डेटा की निर्भरताओं को स्वचालित रूप से कैप्चर किया जा सके, और वे नए डेटा के लिए परिणामों की भविष्यवाणी करने की अनुमति देते हैं, जिसे मॉडल ने पहले नहीं देखा है।
इस पाठ में, आप रिग्रेशन के दो प्रकारों के बारे में जानेंगे: _बेसिक लिनियर रिग्रेशन_ और _पॉलिनोमियल रिग्रेशन_, साथ ही इन तकनीकों के पीछे की गणितीय अवधारणाओं को भी समझेंगे। ये मॉडल हमें विभिन्न इनपुट डेटा के आधार पर कद्दू की कीमतों की भविष्यवाणी करने में मदद करेंगे।
[](https://youtu.be/CRxFT8oTDMg "शुरुआती के लिए मशीन लर्निंग - लिनियर रिग्रेशन को समझना")
> 🎥 ऊपर दी गई छवि पर क्लिक करें और लिनियर रिग्रेशन का एक छोटा वीडियो देखें।
> इस पाठ्यक्रम में, हम गणित का न्यूनतम ज्ञान मानते हैं और इसे अन्य क्षेत्रों से आने वाले छात्रों के लिए सुलभ बनाने का प्रयास करते हैं। इसलिए, नोट्स, 🧮 गणना, आरेख और अन्य शिक्षण उपकरणों पर ध्यान दें जो समझने में मदद करेंगे।
### पूर्वापेक्षा
अब तक आपको उस कद्दू डेटा की संरचना से परिचित होना चाहिए जिसे हम जांच रहे हैं। यह डेटा इस पाठ के _notebook.ipynb_ फ़ाइल में पहले से लोड और साफ किया गया है। इस फ़ाइल में, कद्दू की कीमत प्रति बुशल एक नए डेटा फ्रेम में प्रदर्शित की गई है। सुनिश्चित करें कि आप इन नोटबुक्स को Visual Studio Code के कर्नल्स में चला सकते हैं।
### तैयारी
याद दिलाने के लिए, आप इस डेटा को लोड कर रहे हैं ताकि आप इससे सवाल पूछ सकें।
- कद्दू खरीदने का सबसे अच्छा समय कब है?
- मिनिएचर कद्दुओं के एक केस की कीमत क्या हो सकती है?
- क्या मुझे उन्हें आधे-बुशल की टोकरी में खरीदना चाहिए या 1 1/9 बुशल बॉक्स में?
आइए इस डेटा में और गहराई से खुदाई करें।
पिछले पाठ में, आपने एक Pandas डेटा फ्रेम बनाया और इसे मूल डेटा सेट के एक हिस्से से भरा, बुशल द्वारा कीमतों को मानकीकृत किया। ऐसा करने पर, हालांकि, आप केवल लगभग 400 डेटा पॉइंट्स और केवल पतझड़ के महीनों के लिए डेटा एकत्र कर सके।
इस पाठ के साथ आने वाले नोटबुक में पहले से लोड किए गए डेटा पर एक नज़र डालें। डेटा पहले से लोड है और एक प्रारंभिक स्कैटरप्लॉट महीने के डेटा को दिखाने के लिए चार्ट किया गया है। शायद हम इसे और साफ करके डेटा की प्रकृति के बारे में अधिक जानकारी प्राप्त कर सकते हैं।
## एक लिनियर रिग्रेशन लाइन
जैसा कि आपने पाठ 1 में सीखा, लिनियर रिग्रेशन अभ्यास का लक्ष्य एक रेखा खींचना है ताकि:
- **चर के संबंध दिखाए जा सकें**। चर के बीच संबंध दिखाएं
- **भविष्यवाणियां करें**। यह सटीक भविष्यवाणी करें कि एक नया डेटा पॉइंट उस रेखा के संबंध में कहां गिरेगा।
**लीस्ट-स्क्वेयर्स रिग्रेशन** का उपयोग इस प्रकार की रेखा खींचने के लिए किया जाता है। 'लीस्ट-स्क्वेयर्स' शब्द का मतलब है कि रिग्रेशन लाइन के चारों ओर के सभी डेटा पॉइंट्स को वर्गाकार किया जाता है और फिर जोड़ा जाता है। आदर्श रूप से, वह अंतिम योग जितना संभव हो उतना छोटा होना चाहिए, क्योंकि हम त्रुटियों की कम संख्या चाहते हैं, या `लीस्ट-स्क्वेयर्स`।
हम ऐसा इसलिए करते हैं क्योंकि हम एक ऐसी रेखा का मॉडल बनाना चाहते हैं जो हमारे सभी डेटा पॉइंट्स से न्यूनतम संचयी दूरी रखती हो। हम इन शब्दों को जोड़ने से पहले वर्गाकार करते हैं क्योंकि हमें इसकी दिशा की बजाय इसकी परिमाण की परवाह है।
> **🧮 मुझे गणित दिखाएं**
>
> इस रेखा, जिसे _सर्वश्रेष्ठ फिट की रेखा_ कहा जाता है, को [एक समीकरण](https://en.wikipedia.org/wiki/Simple_linear_regression) द्वारा व्यक्त किया जा सकता है:
>
> ```
> Y = a + bX
> ```
>
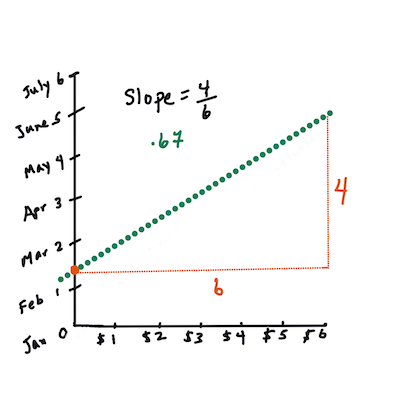
> `X` 'स्पष्टीकरण चर' है। `Y` 'निर्भर चर' है। रेखा का ढलान `b` है और `a` वाई-अवरोध है, जो उस समय `Y` का मान दर्शाता है जब `X = 0` होता है।
>
>
>
> पहले, ढलान `b` की गणना करें। इन्फोग्राफिक: [जेन लूपर](https://twitter.com/jenlooper)
>
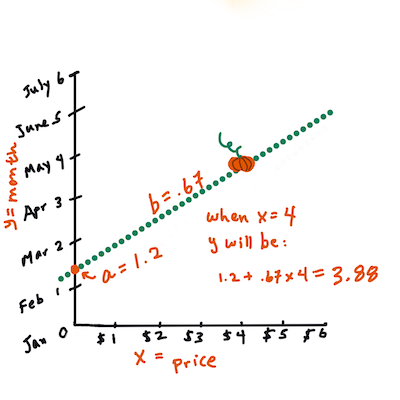
> दूसरे शब्दों में, और हमारे कद्दू डेटा के मूल प्रश्न का संदर्भ देते हुए: "महीने के अनुसार प्रति बुशल कद्दू की कीमत की भविष्यवाणी करें", `X` कीमत को संदर्भित करेगा और `Y` बिक्री के महीने को।
>
>
>
> `Y` का मान निकालें। यदि आप लगभग $4 का भुगतान कर रहे हैं, तो यह अप्रैल होना चाहिए! इन्फोग्राफिक: [जेन लूपर](https://twitter.com/jenlooper)
>
> इस रेखा की गणना करने वाला गणित रेखा के ढलान को प्रदर्शित करना चाहिए, जो अवरोध पर भी निर्भर करता है, या जहां `Y` स्थित है जब `X = 0`।
>
> आप इन मूल्यों की गणना की विधि को [Math is Fun](https://www.mathsisfun.com/data/least-squares-regression.html) वेबसाइट पर देख सकते हैं। साथ ही, [इस लीस्ट-स्क्वेयर्स कैलकुलेटर](https://www.mathsisfun.com/data/least-squares-calculator.html) पर जाएं और देखें कि संख्याओं के मान रेखा को कैसे प्रभावित करते हैं।
## सहसंबंध (Correlation)
एक और शब्द जिसे समझना महत्वपूर्ण है वह है **सहसंबंध गुणांक** (Correlation Coefficient) जो दिए गए X और Y चर के बीच होता है। स्कैटरप्लॉट का उपयोग करके, आप इस गुणांक को जल्दी से विज़ुअलाइज़ कर सकते हैं। यदि डेटा पॉइंट्स एक सीधी रेखा में व्यवस्थित हैं, तो सहसंबंध उच्च होता है, लेकिन यदि डेटा पॉइंट्स X और Y के बीच हर जगह बिखरे हुए हैं, तो सहसंबंध कम होता है।
एक अच्छा लिनियर रिग्रेशन मॉडल वह होगा जिसका सहसंबंध गुणांक उच्च (1 के करीब) हो, न कि 0 के करीब, और जो लीस्ट-स्क्वेयर्स रिग्रेशन विधि का उपयोग करके रिग्रेशन की रेखा के साथ मेल खाता हो।
✅ इस पाठ के साथ आने वाले नोटबुक को चलाएं और महीने से कीमत के स्कैटरप्लॉट को देखें। क्या कद्दू की बिक्री के लिए महीने और कीमत के बीच डेटा का सहसंबंध उच्च या निम्न लगता है, आपकी दृश्य व्याख्या के अनुसार? क्या यह बदलता है यदि आप `महीने` के बजाय अधिक सूक्ष्म माप, जैसे *साल का दिन* (यानी साल की शुरुआत से दिनों की संख्या) का उपयोग करते हैं?
नीचे दिए गए कोड में, हम मानते हैं कि हमने डेटा को साफ कर लिया है और `new_pumpkins` नामक एक डेटा फ्रेम प्राप्त किया है, जो निम्नलिखित के समान है:
ID | Month | DayOfYear | Variety | City | Package | Low Price | High Price | Price
---|-------|-----------|---------|------|---------|-----------|------------|-------
70 | 9 | 267 | PIE TYPE | BALTIMORE | 1 1/9 bushel cartons | 15.0 | 15.0 | 13.636364
71 | 9 | 267 | PIE TYPE | BALTIMORE | 1 1/9 bushel cartons | 18.0 | 18.0 | 16.363636
72 | 10 | 274 | PIE TYPE | BALTIMORE | 1 1/9 bushel cartons | 18.0 | 18.0 | 16.363636
73 | 10 | 274 | PIE TYPE | BALTIMORE | 1 1/9 bushel cartons | 17.0 | 17.0 | 15.454545
74 | 10 | 281 | PIE TYPE | BALTIMORE | 1 1/9 bushel cartons | 15.0 | 15.0 | 13.636364
> डेटा को साफ करने का कोड [`notebook.ipynb`](../../../../2-Regression/3-Linear/notebook.ipynb) में उपलब्ध है। हमने पिछले पाठ में समान सफाई चरणों का पालन किया है और `DayOfYear` कॉलम की गणना निम्नलिखित अभिव्यक्ति का उपयोग करके की है:
```python
day_of_year = pd.to_datetime(pumpkins['Date']).apply(lambda dt: (dt-datetime(dt.year,1,1)).days)
```
अब जब आपको लिनियर रिग्रेशन के पीछे के गणित की समझ हो गई है, तो आइए एक रिग्रेशन मॉडल बनाएं और देखें कि क्या हम यह भविष्यवाणी कर सकते हैं कि कद्दू के किस पैकेज की कीमत सबसे अच्छी होगी। कोई व्यक्ति जो छुट्टी के लिए कद्दू का पैच खरीद रहा है, वह इस जानकारी का उपयोग कद्दू के पैकेजों की खरीद को अनुकूलित करने के लिए कर सकता है।
## सहसंबंध की तलाश
[](https://youtu.be/uoRq-lW2eQo "शुरुआती के लिए मशीन लर्निंग - सहसंबंध की तलाश: लिनियर रिग्रेशन की कुंजी")
> 🎥 ऊपर दी गई छवि पर क्लिक करें और सहसंबंध का एक छोटा वीडियो देखें।
पिछले पाठ से आपने शायद देखा होगा कि विभिन्न महीनों के लिए औसत कीमत इस प्रकार दिखती है:
 यह सुझाव देता है कि कुछ सहसंबंध हो सकता है, और हम `Month` और `Price` के बीच, या `DayOfYear` और `Price` के बीच संबंध की भविष्यवाणी करने के लिए एक लिनियर रिग्रेशन मॉडल को प्रशिक्षित करने का प्रयास कर सकते हैं। यहाँ एक स्कैटरप्लॉट है जो बाद के संबंध को दिखाता है:
यह सुझाव देता है कि कुछ सहसंबंध हो सकता है, और हम `Month` और `Price` के बीच, या `DayOfYear` और `Price` के बीच संबंध की भविष्यवाणी करने के लिए एक लिनियर रिग्रेशन मॉडल को प्रशिक्षित करने का प्रयास कर सकते हैं। यहाँ एक स्कैटरप्लॉट है जो बाद के संबंध को दिखाता है:
 आइए `corr` फ़ंक्शन का उपयोग करके देखें कि क्या कोई सहसंबंध है:
```python
print(new_pumpkins['Month'].corr(new_pumpkins['Price']))
print(new_pumpkins['DayOfYear'].corr(new_pumpkins['Price']))
```
ऐसा लगता है कि सहसंबंध बहुत छोटा है, `Month` के लिए -0.15 और `DayOfMonth` के लिए -0.17, लेकिन एक और महत्वपूर्ण संबंध हो सकता है। ऐसा लगता है कि विभिन्न कद्दू की किस्मों के लिए कीमतों के अलग-अलग समूह हैं। इस परिकल्पना की पुष्टि करने के लिए, आइए प्रत्येक कद्दू श्रेणी को एक अलग रंग का उपयोग करके प्लॉट करें। `scatter` प्लॉटिंग फ़ंक्शन में `ax` पैरामीटर पास करके हम सभी बिंदुओं को एक ही ग्राफ़ पर प्लॉट कर सकते हैं:
```python
ax=None
colors = ['red','blue','green','yellow']
for i,var in enumerate(new_pumpkins['Variety'].unique()):
df = new_pumpkins[new_pumpkins['Variety']==var]
ax = df.plot.scatter('DayOfYear','Price',ax=ax,c=colors[i],label=var)
```
आइए `corr` फ़ंक्शन का उपयोग करके देखें कि क्या कोई सहसंबंध है:
```python
print(new_pumpkins['Month'].corr(new_pumpkins['Price']))
print(new_pumpkins['DayOfYear'].corr(new_pumpkins['Price']))
```
ऐसा लगता है कि सहसंबंध बहुत छोटा है, `Month` के लिए -0.15 और `DayOfMonth` के लिए -0.17, लेकिन एक और महत्वपूर्ण संबंध हो सकता है। ऐसा लगता है कि विभिन्न कद्दू की किस्मों के लिए कीमतों के अलग-अलग समूह हैं। इस परिकल्पना की पुष्टि करने के लिए, आइए प्रत्येक कद्दू श्रेणी को एक अलग रंग का उपयोग करके प्लॉट करें। `scatter` प्लॉटिंग फ़ंक्शन में `ax` पैरामीटर पास करके हम सभी बिंदुओं को एक ही ग्राफ़ पर प्लॉट कर सकते हैं:
```python
ax=None
colors = ['red','blue','green','yellow']
for i,var in enumerate(new_pumpkins['Variety'].unique()):
df = new_pumpkins[new_pumpkins['Variety']==var]
ax = df.plot.scatter('DayOfYear','Price',ax=ax,c=colors[i],label=var)
```
 हमारी जांच से पता चलता है कि किस्म का समग्र कीमत पर तारीख की तुलना में अधिक प्रभाव है। हम इसे बार ग्राफ़ के साथ देख सकते हैं:
```python
new_pumpkins.groupby('Variety')['Price'].mean().plot(kind='bar')
```
हमारी जांच से पता चलता है कि किस्म का समग्र कीमत पर तारीख की तुलना में अधिक प्रभाव है। हम इसे बार ग्राफ़ के साथ देख सकते हैं:
```python
new_pumpkins.groupby('Variety')['Price'].mean().plot(kind='bar')
```
 आइए फिलहाल केवल एक कद्दू की किस्म, 'पाई टाइप', पर ध्यान केंद्रित करें और देखें कि तारीख का कीमत पर क्या प्रभाव पड़ता है:
```python
pie_pumpkins = new_pumpkins[new_pumpkins['Variety']=='PIE TYPE']
pie_pumpkins.plot.scatter('DayOfYear','Price')
```
आइए फिलहाल केवल एक कद्दू की किस्म, 'पाई टाइप', पर ध्यान केंद्रित करें और देखें कि तारीख का कीमत पर क्या प्रभाव पड़ता है:
```python
pie_pumpkins = new_pumpkins[new_pumpkins['Variety']=='PIE TYPE']
pie_pumpkins.plot.scatter('DayOfYear','Price')
```
 यदि हम अब `corr` फ़ंक्शन का उपयोग करके `Price` और `DayOfYear` के बीच सहसंबंध की गणना करते हैं, तो हमें कुछ `-0.27` जैसा मिलेगा - जिसका अर्थ है कि एक भविष्यवाणी मॉडल को प्रशिक्षित करना समझ में आता है।
> एक लिनियर रिग्रेशन मॉडल को प्रशिक्षित करने से पहले, यह सुनिश्चित करना महत्वपूर्ण है कि हमारा डेटा साफ है। लिनियर रिग्रेशन खाली मानों के साथ अच्छा काम नहीं करता है, इसलिए सभी खाली कोशिकाओं से छुटकारा पाना समझदारी है:
```python
pie_pumpkins.dropna(inplace=True)
pie_pumpkins.info()
```
एक और दृष्टिकोण यह होगा कि उन खाली मानों को संबंधित कॉलम के औसत मानों से भर दिया जाए।
## सरल लिनियर रिग्रेशन
[](https://youtu.be/e4c_UP2fSjg "शुरुआती के लिए मशीन लर्निंग - Scikit-learn का उपयोग करके लिनियर और पॉलिनोमियल रिग्रेशन")
> 🎥 ऊपर दी गई छवि पर क्लिक करें और लिनियर और पॉलिनोमियल रिग्रेशन का एक छोटा वीडियो देखें।
हमारे लिनियर रिग्रेशन मॉडल को प्रशिक्षित करने के लिए, हम **Scikit-learn** लाइब्रेरी का उपयोग करेंगे।
```python
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
```
हम इनपुट मानों (विशेषताएं) और अपेक्षित आउटपुट (लेबल) को अलग-अलग numpy arrays में विभाजित करके शुरू करते हैं:
```python
X = pie_pumpkins['DayOfYear'].to_numpy().reshape(-1,1)
y = pie_pumpkins['Price']
```
> ध्यान दें कि हमें इनपुट डेटा पर `reshape` करना पड़ा ताकि लिनियर रिग्रेशन पैकेज इसे सही ढंग से समझ सके। लिनियर रिग्रेशन एक 2D-array को इनपुट के रूप में अपेक्षा करता है, जहां array की प्रत्येक पंक्ति इनपुट विशेषताओं के वेक्टर से मेल खाती है। हमारे मामले में, चूंकि हमारे पास केवल एक इनपुट है - हमें आकार N×1 के साथ एक array की आवश्यकता है, जहां N डेटा सेट का आकार है।
फिर, हमें डेटा को ट्रेन और टेस्ट डेटा सेट में विभाजित करने की आवश्यकता है, ताकि हम प्रशिक्षण के बाद अपने मॉडल को मान्य कर सकें:
```python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
```
अंत में, वास्तविक लिनियर रिग्रेशन मॉडल को प्रशिक्षित करना केवल दो पंक्तियों का काम है। हम `LinearRegression` ऑब्जेक्ट को परिभाषित करते हैं, और इसे `fit` विधि का उपयोग करके हमारे डेटा पर फिट करते हैं:
```python
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)
```
`LinearRegression` ऑब्जेक्ट में `fit`-टिंग के बाद रिग्रेशन के सभी गुणांक होते हैं, जिन्हें `.coef_` प्रॉपर्टी का उपयोग करके एक्सेस किया जा सकता है। हमारे मामले में, केवल एक गुणांक है, जो लगभग `-0.017` होना चाहिए। इसका मतलब है कि समय के साथ कीमतें थोड़ी गिरती दिखती हैं, लेकिन ज्यादा नहीं, लगभग 2 सेंट प्रति दिन। हम रिग्रेशन के Y-अक्ष के साथ इंटरसेक्शन पॉइंट को `lin_reg.intercept_` का उपयोग करके भी एक्सेस कर सकते हैं - यह हमारे मामले में लगभग `21` होगा, जो साल की शुरुआत में कीमत को इंगित करता है।
यह देखने के लिए कि हमारा मॉडल कितना सटीक है, हम टेस्ट डेटा सेट पर कीमतों की भविष्यवाणी कर सकते हैं, और फिर यह माप सकते हैं कि हमारी भविष्यवाणियां अपेक्षित मानों के कितनी करीब हैं। यह औसत वर्ग त्रुटि (MSE) मेट्रिक्स का उपयोग करके किया जा सकता है, जो अपेक्षित और भविष्यवाणी किए गए मान के बीच सभी वर्गीय अंतर का औसत है।
```python
pred = lin_reg.predict(X_test)
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
```
हमारी त्रुटि लगभग 2 बिंदुओं के आसपास है, जो ~17% है। यह बहुत अच्छा नहीं है। मॉडल की गुणवत्ता का एक और संकेतक **निर्धारण गुणांक** है, जिसे इस तरह प्राप्त किया जा सकता है:
```python
score = lin_reg.score(X_train,y_train)
print('Model determination: ', score)
```
यदि मान 0 है, तो इसका मतलब है कि मॉडल इनपुट डेटा को ध्यान में नहीं रखता है और *सबसे खराब रैखिक भविष्यवक्ता* के रूप में कार्य करता है, जो केवल परिणाम का औसत मान है। मान 1 का मतलब है कि हम सभी अपेक्षित आउटपुट को पूरी तरह से भविष्यवाणी कर सकते हैं। हमारे मामले में, निर्धारण गुणांक लगभग 0.06 है, जो काफी कम है।
हम परीक्षण डेटा को रिग्रेशन लाइन के साथ भी प्लॉट कर सकते हैं ताकि यह बेहतर तरीके से समझ सकें कि हमारे मामले में रिग्रेशन कैसे काम करता है:
```python
plt.scatter(X_test,y_test)
plt.plot(X_test,pred)
```
यदि हम अब `corr` फ़ंक्शन का उपयोग करके `Price` और `DayOfYear` के बीच सहसंबंध की गणना करते हैं, तो हमें कुछ `-0.27` जैसा मिलेगा - जिसका अर्थ है कि एक भविष्यवाणी मॉडल को प्रशिक्षित करना समझ में आता है।
> एक लिनियर रिग्रेशन मॉडल को प्रशिक्षित करने से पहले, यह सुनिश्चित करना महत्वपूर्ण है कि हमारा डेटा साफ है। लिनियर रिग्रेशन खाली मानों के साथ अच्छा काम नहीं करता है, इसलिए सभी खाली कोशिकाओं से छुटकारा पाना समझदारी है:
```python
pie_pumpkins.dropna(inplace=True)
pie_pumpkins.info()
```
एक और दृष्टिकोण यह होगा कि उन खाली मानों को संबंधित कॉलम के औसत मानों से भर दिया जाए।
## सरल लिनियर रिग्रेशन
[](https://youtu.be/e4c_UP2fSjg "शुरुआती के लिए मशीन लर्निंग - Scikit-learn का उपयोग करके लिनियर और पॉलिनोमियल रिग्रेशन")
> 🎥 ऊपर दी गई छवि पर क्लिक करें और लिनियर और पॉलिनोमियल रिग्रेशन का एक छोटा वीडियो देखें।
हमारे लिनियर रिग्रेशन मॉडल को प्रशिक्षित करने के लिए, हम **Scikit-learn** लाइब्रेरी का उपयोग करेंगे।
```python
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
```
हम इनपुट मानों (विशेषताएं) और अपेक्षित आउटपुट (लेबल) को अलग-अलग numpy arrays में विभाजित करके शुरू करते हैं:
```python
X = pie_pumpkins['DayOfYear'].to_numpy().reshape(-1,1)
y = pie_pumpkins['Price']
```
> ध्यान दें कि हमें इनपुट डेटा पर `reshape` करना पड़ा ताकि लिनियर रिग्रेशन पैकेज इसे सही ढंग से समझ सके। लिनियर रिग्रेशन एक 2D-array को इनपुट के रूप में अपेक्षा करता है, जहां array की प्रत्येक पंक्ति इनपुट विशेषताओं के वेक्टर से मेल खाती है। हमारे मामले में, चूंकि हमारे पास केवल एक इनपुट है - हमें आकार N×1 के साथ एक array की आवश्यकता है, जहां N डेटा सेट का आकार है।
फिर, हमें डेटा को ट्रेन और टेस्ट डेटा सेट में विभाजित करने की आवश्यकता है, ताकि हम प्रशिक्षण के बाद अपने मॉडल को मान्य कर सकें:
```python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
```
अंत में, वास्तविक लिनियर रिग्रेशन मॉडल को प्रशिक्षित करना केवल दो पंक्तियों का काम है। हम `LinearRegression` ऑब्जेक्ट को परिभाषित करते हैं, और इसे `fit` विधि का उपयोग करके हमारे डेटा पर फिट करते हैं:
```python
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)
```
`LinearRegression` ऑब्जेक्ट में `fit`-टिंग के बाद रिग्रेशन के सभी गुणांक होते हैं, जिन्हें `.coef_` प्रॉपर्टी का उपयोग करके एक्सेस किया जा सकता है। हमारे मामले में, केवल एक गुणांक है, जो लगभग `-0.017` होना चाहिए। इसका मतलब है कि समय के साथ कीमतें थोड़ी गिरती दिखती हैं, लेकिन ज्यादा नहीं, लगभग 2 सेंट प्रति दिन। हम रिग्रेशन के Y-अक्ष के साथ इंटरसेक्शन पॉइंट को `lin_reg.intercept_` का उपयोग करके भी एक्सेस कर सकते हैं - यह हमारे मामले में लगभग `21` होगा, जो साल की शुरुआत में कीमत को इंगित करता है।
यह देखने के लिए कि हमारा मॉडल कितना सटीक है, हम टेस्ट डेटा सेट पर कीमतों की भविष्यवाणी कर सकते हैं, और फिर यह माप सकते हैं कि हमारी भविष्यवाणियां अपेक्षित मानों के कितनी करीब हैं। यह औसत वर्ग त्रुटि (MSE) मेट्रिक्स का उपयोग करके किया जा सकता है, जो अपेक्षित और भविष्यवाणी किए गए मान के बीच सभी वर्गीय अंतर का औसत है।
```python
pred = lin_reg.predict(X_test)
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
```
हमारी त्रुटि लगभग 2 बिंदुओं के आसपास है, जो ~17% है। यह बहुत अच्छा नहीं है। मॉडल की गुणवत्ता का एक और संकेतक **निर्धारण गुणांक** है, जिसे इस तरह प्राप्त किया जा सकता है:
```python
score = lin_reg.score(X_train,y_train)
print('Model determination: ', score)
```
यदि मान 0 है, तो इसका मतलब है कि मॉडल इनपुट डेटा को ध्यान में नहीं रखता है और *सबसे खराब रैखिक भविष्यवक्ता* के रूप में कार्य करता है, जो केवल परिणाम का औसत मान है। मान 1 का मतलब है कि हम सभी अपेक्षित आउटपुट को पूरी तरह से भविष्यवाणी कर सकते हैं। हमारे मामले में, निर्धारण गुणांक लगभग 0.06 है, जो काफी कम है।
हम परीक्षण डेटा को रिग्रेशन लाइन के साथ भी प्लॉट कर सकते हैं ताकि यह बेहतर तरीके से समझ सकें कि हमारे मामले में रिग्रेशन कैसे काम करता है:
```python
plt.scatter(X_test,y_test)
plt.plot(X_test,pred)
```
 ## बहुपद रिग्रेशन
रैखिक रिग्रेशन का एक अन्य प्रकार बहुपद रिग्रेशन है। कभी-कभी चर के बीच रैखिक संबंध होता है - जैसे कि कद्दू का आकार बढ़ने पर उसकी कीमत बढ़ती है - लेकिन कभी-कभी इन संबंधों को एक समतल या सीधी रेखा के रूप में प्लॉट नहीं किया जा सकता।
✅ यहां [कुछ और उदाहरण](https://online.stat.psu.edu/stat501/lesson/9/9.8) हैं जो बहुपद रिग्रेशन का उपयोग कर सकते हैं।
Date और Price के बीच संबंध पर फिर से नज़र डालें। क्या यह स्कैटरप्लॉट ऐसा लगता है कि इसे सीधी रेखा से विश्लेषण किया जाना चाहिए? क्या कीमतें बदल नहीं सकतीं? इस मामले में, आप बहुपद रिग्रेशन आज़मा सकते हैं।
✅ बहुपद गणितीय अभिव्यक्तियाँ हैं जो एक या अधिक चर और गुणांक से बनी हो सकती हैं।
बहुपद रिग्रेशन एक घुमावदार रेखा बनाता है जो गैर-रैखिक डेटा को बेहतर तरीके से फिट करता है। हमारे मामले में, यदि हम इनपुट डेटा में `DayOfYear` चर का वर्ग शामिल करते हैं, तो हम अपने डेटा को एक परवलयिक वक्र के साथ फिट कर सकते हैं, जिसका न्यूनतम वर्ष के भीतर किसी निश्चित बिंदु पर होगा।
Scikit-learn में एक उपयोगी [पाइपलाइन API](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.make_pipeline.html?highlight=pipeline#sklearn.pipeline.make_pipeline) शामिल है जो डेटा प्रोसेसिंग के विभिन्न चरणों को एक साथ जोड़ने में मदद करता है। एक **पाइपलाइन** **अनुमानकर्ताओं** की एक श्रृंखला है। हमारे मामले में, हम एक पाइपलाइन बनाएंगे जो पहले हमारे मॉडल में बहुपद विशेषताएँ जोड़ती है और फिर रिग्रेशन को प्रशिक्षित करती है:
```python
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
```
`PolynomialFeatures(2)` का उपयोग करने का मतलब है कि हम इनपुट डेटा से सभी दूसरे-डिग्री बहुपद शामिल करेंगे। हमारे मामले में इसका मतलब केवल `DayOfYear`2 होगा, लेकिन यदि दो इनपुट चर X और Y दिए गए हैं, तो यह X2, XY और Y2 जोड़ देगा। यदि हम चाहें तो उच्च डिग्री बहुपद का उपयोग भी कर सकते हैं।
पाइपलाइन का उपयोग उसी तरह किया जा सकता है जैसे मूल `LinearRegression` ऑब्जेक्ट का उपयोग किया जाता है, यानी हम पाइपलाइन को `fit` कर सकते हैं और फिर `predict` का उपयोग करके भविष्यवाणी परिणाम प्राप्त कर सकते हैं। यहां परीक्षण डेटा और अनुमानित वक्र दिखाने वाला ग्राफ है:
## बहुपद रिग्रेशन
रैखिक रिग्रेशन का एक अन्य प्रकार बहुपद रिग्रेशन है। कभी-कभी चर के बीच रैखिक संबंध होता है - जैसे कि कद्दू का आकार बढ़ने पर उसकी कीमत बढ़ती है - लेकिन कभी-कभी इन संबंधों को एक समतल या सीधी रेखा के रूप में प्लॉट नहीं किया जा सकता।
✅ यहां [कुछ और उदाहरण](https://online.stat.psu.edu/stat501/lesson/9/9.8) हैं जो बहुपद रिग्रेशन का उपयोग कर सकते हैं।
Date और Price के बीच संबंध पर फिर से नज़र डालें। क्या यह स्कैटरप्लॉट ऐसा लगता है कि इसे सीधी रेखा से विश्लेषण किया जाना चाहिए? क्या कीमतें बदल नहीं सकतीं? इस मामले में, आप बहुपद रिग्रेशन आज़मा सकते हैं।
✅ बहुपद गणितीय अभिव्यक्तियाँ हैं जो एक या अधिक चर और गुणांक से बनी हो सकती हैं।
बहुपद रिग्रेशन एक घुमावदार रेखा बनाता है जो गैर-रैखिक डेटा को बेहतर तरीके से फिट करता है। हमारे मामले में, यदि हम इनपुट डेटा में `DayOfYear` चर का वर्ग शामिल करते हैं, तो हम अपने डेटा को एक परवलयिक वक्र के साथ फिट कर सकते हैं, जिसका न्यूनतम वर्ष के भीतर किसी निश्चित बिंदु पर होगा।
Scikit-learn में एक उपयोगी [पाइपलाइन API](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.make_pipeline.html?highlight=pipeline#sklearn.pipeline.make_pipeline) शामिल है जो डेटा प्रोसेसिंग के विभिन्न चरणों को एक साथ जोड़ने में मदद करता है। एक **पाइपलाइन** **अनुमानकर्ताओं** की एक श्रृंखला है। हमारे मामले में, हम एक पाइपलाइन बनाएंगे जो पहले हमारे मॉडल में बहुपद विशेषताएँ जोड़ती है और फिर रिग्रेशन को प्रशिक्षित करती है:
```python
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
```
`PolynomialFeatures(2)` का उपयोग करने का मतलब है कि हम इनपुट डेटा से सभी दूसरे-डिग्री बहुपद शामिल करेंगे। हमारे मामले में इसका मतलब केवल `DayOfYear`2 होगा, लेकिन यदि दो इनपुट चर X और Y दिए गए हैं, तो यह X2, XY और Y2 जोड़ देगा। यदि हम चाहें तो उच्च डिग्री बहुपद का उपयोग भी कर सकते हैं।
पाइपलाइन का उपयोग उसी तरह किया जा सकता है जैसे मूल `LinearRegression` ऑब्जेक्ट का उपयोग किया जाता है, यानी हम पाइपलाइन को `fit` कर सकते हैं और फिर `predict` का उपयोग करके भविष्यवाणी परिणाम प्राप्त कर सकते हैं। यहां परीक्षण डेटा और अनुमानित वक्र दिखाने वाला ग्राफ है:
 बहुपद रिग्रेशन का उपयोग करके, हम थोड़ा कम MSE और थोड़ा अधिक निर्धारण प्राप्त कर सकते हैं, लेकिन यह बहुत महत्वपूर्ण नहीं है। हमें अन्य विशेषताओं को ध्यान में रखना होगा!
> आप देख सकते हैं कि न्यूनतम कद्दू की कीमतें कहीं हैलोवीन के आसपास देखी जाती हैं। आप इसे कैसे समझाएंगे?
🎃 बधाई हो, आपने एक ऐसा मॉडल बनाया है जो पाई कद्दू की कीमत का अनुमान लगाने में मदद कर सकता है। आप शायद सभी प्रकार के कद्दू के लिए वही प्रक्रिया दोहरा सकते हैं, लेकिन यह थोड़ा थकाऊ होगा। अब चलिए सीखते हैं कि अपने मॉडल में कद्दू की विविधता को कैसे ध्यान में रखा जाए!
## श्रेणीबद्ध विशेषताएँ
आदर्श दुनिया में, हम एक ही मॉडल का उपयोग करके विभिन्न कद्दू की किस्मों के लिए कीमतों का अनुमान लगाना चाहते हैं। हालांकि, `Variety` कॉलम `Month` जैसे कॉलम से थोड़ा अलग है, क्योंकि इसमें गैर-संख्या मान होते हैं। ऐसे कॉलम को **श्रेणीबद्ध** कहा जाता है।
[](https://youtu.be/DYGliioIAE0 "ML for beginners - Categorical Feature Predictions with Linear Regression")
> 🎥 ऊपर दी गई छवि पर क्लिक करें श्रेणीबद्ध विशेषताओं का उपयोग करने का एक छोटा वीडियो देखने के लिए।
यहां आप देख सकते हैं कि किस्म के आधार पर औसत कीमत कैसे बदलती है:
किस्म को ध्यान में रखने के लिए, हमें पहले इसे संख्यात्मक रूप में बदलना होगा, या **एन्कोड** करना होगा। इसे करने के कई तरीके हैं:
* सरल **संख्यात्मक एन्कोडिंग** विभिन्न किस्मों की एक तालिका बनाएगी और फिर किस्म के नाम को उस तालिका में एक इंडेक्स से बदल देगी। यह रैखिक रिग्रेशन के लिए सबसे अच्छा विचार नहीं है, क्योंकि रैखिक रिग्रेशन इंडेक्स के वास्तविक संख्यात्मक मान को लेता है और इसे परिणाम में जोड़ता है, गुणांक से गुणा करता है। हमारे मामले में, इंडेक्स नंबर और कीमत के बीच संबंध स्पष्ट रूप से गैर-रैखिक है, भले ही हम सुनिश्चित करें कि इंडेक्स किसी विशिष्ट तरीके से क्रमबद्ध हैं।
* **वन-हॉट एन्कोडिंग** `Variety` कॉलम को 4 अलग-अलग कॉलम से बदल देगा, प्रत्येक किस्म के लिए एक। प्रत्येक कॉलम में `1` होगा यदि संबंधित पंक्ति दी गई किस्म की है, और अन्यथा `0`। इसका मतलब है कि रैखिक रिग्रेशन में चार गुणांक होंगे, प्रत्येक कद्दू की किस्म के लिए एक, जो उस विशेष किस्म के लिए "शुरुआती कीमत" (या "अतिरिक्त कीमत") के लिए जिम्मेदार होगा।
नीचे दिया गया कोड दिखाता है कि हम किस्म को वन-हॉट एन्कोड कैसे कर सकते हैं:
```python
pd.get_dummies(new_pumpkins['Variety'])
```
ID | FAIRYTALE | MINIATURE | MIXED HEIRLOOM VARIETIES | PIE TYPE
----|-----------|-----------|--------------------------|----------
70 | 0 | 0 | 0 | 1
71 | 0 | 0 | 0 | 1
... | ... | ... | ... | ...
1738 | 0 | 1 | 0 | 0
1739 | 0 | 1 | 0 | 0
1740 | 0 | 1 | 0 | 0
1741 | 0 | 1 | 0 | 0
1742 | 0 | 1 | 0 | 0
वन-हॉट एन्कोडेड किस्म का उपयोग करके रैखिक रिग्रेशन को प्रशिक्षित करने के लिए, हमें केवल `X` और `y` डेटा को सही तरीके से प्रारंभ करना होगा:
```python
X = pd.get_dummies(new_pumpkins['Variety'])
y = new_pumpkins['Price']
```
बाकी कोड वही है जो हमने ऊपर रैखिक रिग्रेशन को प्रशिक्षित करने के लिए उपयोग किया था। यदि आप इसे आज़माते हैं, तो आप देखेंगे कि औसत वर्ग त्रुटि लगभग समान है, लेकिन हमें बहुत अधिक निर्धारण गुणांक (~77%) मिलता है। अधिक सटीक भविष्यवाणियां प्राप्त करने के लिए, हम अधिक श्रेणीबद्ध विशेषताओं को ध्यान में रख सकते हैं, साथ ही संख्यात्मक विशेषताओं जैसे `Month` या `DayOfYear`। एक बड़ी विशेषता सरणी प्राप्त करने के लिए, हम `join` का उपयोग कर सकते हैं:
```python
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
```
यहां हम `City` और `Package` प्रकार को भी ध्यान में रखते हैं, जो हमें MSE 2.84 (10%) और निर्धारण 0.94 देता है!
## सब कुछ एक साथ रखना
सबसे अच्छा मॉडल बनाने के लिए, हम ऊपर दिए गए उदाहरण से संयुक्त (वन-हॉट एन्कोडेड श्रेणीबद्ध + संख्यात्मक) डेटा का उपयोग बहुपद रिग्रेशन के साथ कर सकते हैं। आपकी सुविधा के लिए यहां पूरा कोड दिया गया है:
```python
# set up training data
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
# make train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# setup and train the pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
# predict results for test data
pred = pipeline.predict(X_test)
# calculate MSE and determination
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
score = pipeline.score(X_train,y_train)
print('Model determination: ', score)
```
यह हमें लगभग 97% का सर्वोत्तम निर्धारण गुणांक और MSE=2.23 (~8% भविष्यवाणी त्रुटि) देना चाहिए।
| मॉडल | MSE | निर्धारण |
|-------|-----|---------------|
| `DayOfYear` रैखिक | 2.77 (17.2%) | 0.07 |
| `DayOfYear` बहुपद | 2.73 (17.0%) | 0.08 |
| `Variety` रैखिक | 5.24 (19.7%) | 0.77 |
| सभी विशेषताएँ रैखिक | 2.84 (10.5%) | 0.94 |
| सभी विशेषताएँ बहुपद | 2.23 (8.25%) | 0.97 |
🏆 बहुत अच्छा! आपने एक ही पाठ में चार रिग्रेशन मॉडल बनाए और मॉडल की गुणवत्ता को 97% तक सुधार दिया। रिग्रेशन पर अंतिम अनुभाग में, आप श्रेणियों को निर्धारित करने के लिए लॉजिस्टिक रिग्रेशन के बारे में जानेंगे।
---
## 🚀चुनौती
इस नोटबुक में कई अलग-अलग चर का परीक्षण करें और देखें कि सहसंबंध मॉडल की सटीकता से कैसे मेल खाता है।
## [पाठ के बाद क्विज़](https://ff-quizzes.netlify.app/en/ml/)
## समीक्षा और स्व-अध्ययन
इस पाठ में हमने रैखिक रिग्रेशन के बारे में सीखा। रिग्रेशन के अन्य महत्वपूर्ण प्रकार भी हैं। Stepwise, Ridge, Lasso और Elasticnet तकनीकों के बारे में पढ़ें। अधिक सीखने के लिए एक अच्छा कोर्स [स्टैनफोर्ड स्टैटिस्टिकल लर्निंग कोर्स](https://online.stanford.edu/courses/sohs-ystatslearning-statistical-learning) है।
## असाइनमेंट
[मॉडल बनाएं](assignment.md)
---
**अस्वीकरण**:
यह दस्तावेज़ AI अनुवाद सेवा [Co-op Translator](https://github.com/Azure/co-op-translator) का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता के लिए प्रयासरत हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।
बहुपद रिग्रेशन का उपयोग करके, हम थोड़ा कम MSE और थोड़ा अधिक निर्धारण प्राप्त कर सकते हैं, लेकिन यह बहुत महत्वपूर्ण नहीं है। हमें अन्य विशेषताओं को ध्यान में रखना होगा!
> आप देख सकते हैं कि न्यूनतम कद्दू की कीमतें कहीं हैलोवीन के आसपास देखी जाती हैं। आप इसे कैसे समझाएंगे?
🎃 बधाई हो, आपने एक ऐसा मॉडल बनाया है जो पाई कद्दू की कीमत का अनुमान लगाने में मदद कर सकता है। आप शायद सभी प्रकार के कद्दू के लिए वही प्रक्रिया दोहरा सकते हैं, लेकिन यह थोड़ा थकाऊ होगा। अब चलिए सीखते हैं कि अपने मॉडल में कद्दू की विविधता को कैसे ध्यान में रखा जाए!
## श्रेणीबद्ध विशेषताएँ
आदर्श दुनिया में, हम एक ही मॉडल का उपयोग करके विभिन्न कद्दू की किस्मों के लिए कीमतों का अनुमान लगाना चाहते हैं। हालांकि, `Variety` कॉलम `Month` जैसे कॉलम से थोड़ा अलग है, क्योंकि इसमें गैर-संख्या मान होते हैं। ऐसे कॉलम को **श्रेणीबद्ध** कहा जाता है।
[](https://youtu.be/DYGliioIAE0 "ML for beginners - Categorical Feature Predictions with Linear Regression")
> 🎥 ऊपर दी गई छवि पर क्लिक करें श्रेणीबद्ध विशेषताओं का उपयोग करने का एक छोटा वीडियो देखने के लिए।
यहां आप देख सकते हैं कि किस्म के आधार पर औसत कीमत कैसे बदलती है:
किस्म को ध्यान में रखने के लिए, हमें पहले इसे संख्यात्मक रूप में बदलना होगा, या **एन्कोड** करना होगा। इसे करने के कई तरीके हैं:
* सरल **संख्यात्मक एन्कोडिंग** विभिन्न किस्मों की एक तालिका बनाएगी और फिर किस्म के नाम को उस तालिका में एक इंडेक्स से बदल देगी। यह रैखिक रिग्रेशन के लिए सबसे अच्छा विचार नहीं है, क्योंकि रैखिक रिग्रेशन इंडेक्स के वास्तविक संख्यात्मक मान को लेता है और इसे परिणाम में जोड़ता है, गुणांक से गुणा करता है। हमारे मामले में, इंडेक्स नंबर और कीमत के बीच संबंध स्पष्ट रूप से गैर-रैखिक है, भले ही हम सुनिश्चित करें कि इंडेक्स किसी विशिष्ट तरीके से क्रमबद्ध हैं।
* **वन-हॉट एन्कोडिंग** `Variety` कॉलम को 4 अलग-अलग कॉलम से बदल देगा, प्रत्येक किस्म के लिए एक। प्रत्येक कॉलम में `1` होगा यदि संबंधित पंक्ति दी गई किस्म की है, और अन्यथा `0`। इसका मतलब है कि रैखिक रिग्रेशन में चार गुणांक होंगे, प्रत्येक कद्दू की किस्म के लिए एक, जो उस विशेष किस्म के लिए "शुरुआती कीमत" (या "अतिरिक्त कीमत") के लिए जिम्मेदार होगा।
नीचे दिया गया कोड दिखाता है कि हम किस्म को वन-हॉट एन्कोड कैसे कर सकते हैं:
```python
pd.get_dummies(new_pumpkins['Variety'])
```
ID | FAIRYTALE | MINIATURE | MIXED HEIRLOOM VARIETIES | PIE TYPE
----|-----------|-----------|--------------------------|----------
70 | 0 | 0 | 0 | 1
71 | 0 | 0 | 0 | 1
... | ... | ... | ... | ...
1738 | 0 | 1 | 0 | 0
1739 | 0 | 1 | 0 | 0
1740 | 0 | 1 | 0 | 0
1741 | 0 | 1 | 0 | 0
1742 | 0 | 1 | 0 | 0
वन-हॉट एन्कोडेड किस्म का उपयोग करके रैखिक रिग्रेशन को प्रशिक्षित करने के लिए, हमें केवल `X` और `y` डेटा को सही तरीके से प्रारंभ करना होगा:
```python
X = pd.get_dummies(new_pumpkins['Variety'])
y = new_pumpkins['Price']
```
बाकी कोड वही है जो हमने ऊपर रैखिक रिग्रेशन को प्रशिक्षित करने के लिए उपयोग किया था। यदि आप इसे आज़माते हैं, तो आप देखेंगे कि औसत वर्ग त्रुटि लगभग समान है, लेकिन हमें बहुत अधिक निर्धारण गुणांक (~77%) मिलता है। अधिक सटीक भविष्यवाणियां प्राप्त करने के लिए, हम अधिक श्रेणीबद्ध विशेषताओं को ध्यान में रख सकते हैं, साथ ही संख्यात्मक विशेषताओं जैसे `Month` या `DayOfYear`। एक बड़ी विशेषता सरणी प्राप्त करने के लिए, हम `join` का उपयोग कर सकते हैं:
```python
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
```
यहां हम `City` और `Package` प्रकार को भी ध्यान में रखते हैं, जो हमें MSE 2.84 (10%) और निर्धारण 0.94 देता है!
## सब कुछ एक साथ रखना
सबसे अच्छा मॉडल बनाने के लिए, हम ऊपर दिए गए उदाहरण से संयुक्त (वन-हॉट एन्कोडेड श्रेणीबद्ध + संख्यात्मक) डेटा का उपयोग बहुपद रिग्रेशन के साथ कर सकते हैं। आपकी सुविधा के लिए यहां पूरा कोड दिया गया है:
```python
# set up training data
X = pd.get_dummies(new_pumpkins['Variety']) \
.join(new_pumpkins['Month']) \
.join(pd.get_dummies(new_pumpkins['City'])) \
.join(pd.get_dummies(new_pumpkins['Package']))
y = new_pumpkins['Price']
# make train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# setup and train the pipeline
pipeline = make_pipeline(PolynomialFeatures(2), LinearRegression())
pipeline.fit(X_train,y_train)
# predict results for test data
pred = pipeline.predict(X_test)
# calculate MSE and determination
mse = np.sqrt(mean_squared_error(y_test,pred))
print(f'Mean error: {mse:3.3} ({mse/np.mean(pred)*100:3.3}%)')
score = pipeline.score(X_train,y_train)
print('Model determination: ', score)
```
यह हमें लगभग 97% का सर्वोत्तम निर्धारण गुणांक और MSE=2.23 (~8% भविष्यवाणी त्रुटि) देना चाहिए।
| मॉडल | MSE | निर्धारण |
|-------|-----|---------------|
| `DayOfYear` रैखिक | 2.77 (17.2%) | 0.07 |
| `DayOfYear` बहुपद | 2.73 (17.0%) | 0.08 |
| `Variety` रैखिक | 5.24 (19.7%) | 0.77 |
| सभी विशेषताएँ रैखिक | 2.84 (10.5%) | 0.94 |
| सभी विशेषताएँ बहुपद | 2.23 (8.25%) | 0.97 |
🏆 बहुत अच्छा! आपने एक ही पाठ में चार रिग्रेशन मॉडल बनाए और मॉडल की गुणवत्ता को 97% तक सुधार दिया। रिग्रेशन पर अंतिम अनुभाग में, आप श्रेणियों को निर्धारित करने के लिए लॉजिस्टिक रिग्रेशन के बारे में जानेंगे।
---
## 🚀चुनौती
इस नोटबुक में कई अलग-अलग चर का परीक्षण करें और देखें कि सहसंबंध मॉडल की सटीकता से कैसे मेल खाता है।
## [पाठ के बाद क्विज़](https://ff-quizzes.netlify.app/en/ml/)
## समीक्षा और स्व-अध्ययन
इस पाठ में हमने रैखिक रिग्रेशन के बारे में सीखा। रिग्रेशन के अन्य महत्वपूर्ण प्रकार भी हैं। Stepwise, Ridge, Lasso और Elasticnet तकनीकों के बारे में पढ़ें। अधिक सीखने के लिए एक अच्छा कोर्स [स्टैनफोर्ड स्टैटिस्टिकल लर्निंग कोर्स](https://online.stanford.edu/courses/sohs-ystatslearning-statistical-learning) है।
## असाइनमेंट
[मॉडल बनाएं](assignment.md)
---
**अस्वीकरण**:
यह दस्तावेज़ AI अनुवाद सेवा [Co-op Translator](https://github.com/Azure/co-op-translator) का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता के लिए प्रयासरत हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।