# בניית אפליקציית המלצות למטבח
בשיעור זה תבנו מודל סיווג באמצעות כמה מהטכניקות שלמדתם בשיעורים קודמים, ותשתמשו במאגר הנתונים הטעים של מטבחים שהשתמשנו בו לאורך הסדרה. בנוסף, תבנו אפליקציית אינטרנט קטנה שתשתמש במודל שמור, תוך שימוש ב-Onnx Web Runtime.
אחת השימושים הפרקטיים המועילים ביותר של למידת מכונה היא בניית מערכות המלצה, ואתם יכולים לעשות את הצעד הראשון בכיוון הזה כבר היום!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 לחצו על התמונה למעלה לצפייה בסרטון: ג'ן לופר בונה אפליקציית אינטרנט באמצעות נתוני מטבחים מסווגים
## [שאלון לפני השיעור](https://ff-quizzes.netlify.app/en/ml/)
בשיעור זה תלמדו:
- כיצד לבנות מודל ולשמור אותו כמודל Onnx
- כיצד להשתמש ב-Netron כדי לבדוק את המודל
- כיצד להשתמש במודל שלכם באפליקציית אינטרנט לצורך הסקה
## בניית המודל שלכם
בניית מערכות למידת מכונה יישומיות היא חלק חשוב בשימוש בטכנולוגיות אלו עבור מערכות עסקיות. ניתן להשתמש במודלים בתוך אפליקציות אינטרנט (וכך גם להשתמש בהם במצב לא מקוון אם יש צורך) באמצעות Onnx.
בשיעור [קודם](../../3-Web-App/1-Web-App/README.md), בניתם מודל רגרסיה על תצפיות עב"מים, "כבשתם" אותו, והשתמשתם בו באפליקציית Flask. בעוד שהארכיטקטורה הזו מאוד שימושית, היא אפליקציית Python מלאה, וייתכן שהדרישות שלכם כוללות שימוש באפליקציית JavaScript.
בשיעור זה, תוכלו לבנות מערכת בסיסית מבוססת JavaScript לצורך הסקה. אך קודם לכן, עליכם לאמן מודל ולהמיר אותו לשימוש עם Onnx.
## תרגיל - אימון מודל סיווג
ראשית, אימנו מודל סיווג באמצעות מאגר הנתונים הנקי של מטבחים שהשתמשנו בו.
1. התחילו בייבוא ספריות שימושיות:
```python
!pip install skl2onnx
import pandas as pd
```
תזדקקו ל-[skl2onnx](https://onnx.ai/sklearn-onnx/) כדי לעזור להמיר את מודל Scikit-learn שלכם לפורמט Onnx.
1. לאחר מכן, עבדו עם הנתונים שלכם באותו אופן שעשיתם בשיעורים קודמים, על ידי קריאת קובץ CSV באמצעות `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. הסירו את שני העמודות הראשונות שאינן נחוצות ושמרו את הנתונים הנותרים כ-'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. שמרו את התוויות כ-'y':
```python
y = data[['cuisine']]
y.head()
```
### התחלת שגרת האימון
נשתמש בספריית 'SVC' שמספקת דיוק טוב.
1. ייבאו את הספריות המתאימות מ-Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. הפרידו בין קבוצות האימון והבדיקה:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. בנו מודל סיווג SVC כפי שעשיתם בשיעור הקודם:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. כעת, בדקו את המודל שלכם על ידי קריאה ל-`predict()`:
```python
y_pred = model.predict(X_test)
```
1. הדפיסו דוח סיווג כדי לבדוק את איכות המודל:
```python
print(classification_report(y_test,y_pred))
```
כפי שראינו קודם, הדיוק טוב:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### המרת המודל שלכם ל-Onnx
וודאו שההמרה מתבצעת עם מספר הטנזור המתאים. מאגר הנתונים הזה כולל 380 מרכיבים, ולכן עליכם לציין את המספר הזה ב-`FloatTensorType`:
1. המירו באמצעות מספר טנזור של 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. צרו את הקובץ onx ושמרו אותו כקובץ **model.onnx**:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> שימו לב, ניתן להעביר [אפשרויות](https://onnx.ai/sklearn-onnx/parameterized.html) בתסריט ההמרה שלכם. במקרה זה, העברנו 'nocl' כ-True ו-'zipmap' כ-False. מכיוון שמדובר במודל סיווג, יש לכם אפשרות להסיר את ZipMap שמייצר רשימת מילונים (לא נחוץ). `nocl` מתייחס למידע על מחלקות שנכלל במודל. ניתן להקטין את גודל המודל שלכם על ידי הגדרת `nocl` כ-'True'.
הרצת המחברת כולה תבנה כעת מודל Onnx ותשמור אותו בתיקייה זו.
## צפייה במודל שלכם
מודלים של Onnx אינם נראים היטב ב-Visual Studio Code, אך יש תוכנה חינמית טובה מאוד שרבים מהחוקרים משתמשים בה כדי להציג את המודל ולוודא שהוא נבנה כראוי. הורידו את [Netron](https://github.com/lutzroeder/Netron) ופתחו את קובץ model.onnx שלכם. תוכלו לראות את המודל הפשוט שלכם מוצג, עם 380 הקלטים והמסווג המופיעים:

Netron הוא כלי מועיל לצפייה במודלים שלכם.
כעת אתם מוכנים להשתמש במודל המגניב הזה באפליקציית אינטרנט. בואו נבנה אפליקציה שתהיה שימושית כאשר תביטו במקרר שלכם ותנסו להבין אילו שילובי מרכיבים שנותרו לכם יכולים לשמש להכנת מטבח מסוים, כפי שנקבע על ידי המודל שלכם.
## בניית אפליקציית אינטרנט להמלצות
ניתן להשתמש במודל שלכם ישירות באפליקציית אינטרנט. ארכיטקטורה זו גם מאפשרת לכם להריץ אותה באופן מקומי ואפילו לא מקוון אם יש צורך. התחילו ביצירת קובץ `index.html` באותה תיקייה שבה שמרתם את קובץ `model.onnx`.
1. בקובץ זה _index.html_, הוסיפו את הסימון הבא:
```html
Cuisine Matcher
...
```
1. כעת, בתוך תגי `body`, הוסיפו מעט סימון כדי להציג רשימת תיבות סימון המשקפות כמה מרכיבים:
```html
Check your refrigerator. What can you create?
```
שימו לב שכל תיבת סימון מקבלת ערך. ערך זה משקף את האינדקס שבו המרכיב נמצא לפי מאגר הנתונים. תפוח, למשל, ברשימה האלפביתית הזו, תופס את העמודה החמישית, ולכן הערך שלו הוא '4' מכיוון שאנחנו מתחילים לספור מ-0. תוכלו להתייעץ עם [גיליון המרכיבים](../../../../4-Classification/data/ingredient_indexes.csv) כדי לגלות את האינדקס של מרכיב מסוים.
המשיכו לעבוד בקובץ index.html, והוסיפו בלוק סקריפט שבו המודל נקרא לאחר סגירת `` הסופית.
1. ראשית, ייבאו את [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> Onnx Runtime משמש כדי לאפשר הרצת מודלים של Onnx על פני מגוון רחב של פלטפורמות חומרה, כולל אופטימיזציות ו-API לשימוש.
1. לאחר שה-runtime במקום, תוכלו לקרוא לו:
```html
```
בקוד זה, מתרחשים כמה דברים:
1. יצרתם מערך של 380 ערכים אפשריים (1 או 0) שיוגדרו וישלחו למודל לצורך הסקה, בהתאם לשאלה האם תיבת סימון מסומנת.
2. יצרתם מערך של תיבות סימון ודרך לקבוע האם הן סומנו בפונקציית `init` שנקראת כאשר האפליקציה מתחילה. כאשר תיבת סימון מסומנת, מערך `ingredients` משתנה כדי לשקף את המרכיב שנבחר.
3. יצרתם פונקציית `testCheckboxes` שבודקת האם תיבת סימון כלשהי סומנה.
4. אתם משתמשים בפונקציית `startInference` כאשר הכפתור נלחץ, ואם תיבת סימון כלשהי סומנה, אתם מתחילים הסקה.
5. שגרת ההסקה כוללת:
1. הגדרת טעינה אסינכרונית של המודל
2. יצירת מבנה טנזור לשליחה למודל
3. יצירת 'feeds' שמשקפים את הקלט `float_input` שיצרתם כאשר אימנתם את המודל שלכם (ניתן להשתמש ב-Netron כדי לאמת את השם)
4. שליחת 'feeds' אלו למודל והמתנה לתגובה
## בדיקת האפליקציה שלכם
פתחו סשן טרמינל ב-Visual Studio Code בתיקייה שבה נמצא קובץ index.html שלכם. ודאו שיש לכם [http-server](https://www.npmjs.com/package/http-server) מותקן גלובלית, והקלידו `http-server` בשורת הפקודה. localhost אמור להיפתח ותוכלו לצפות באפליקציית האינטרנט שלכם. בדקו איזה מטבח מומלץ בהתבסס על מרכיבים שונים:
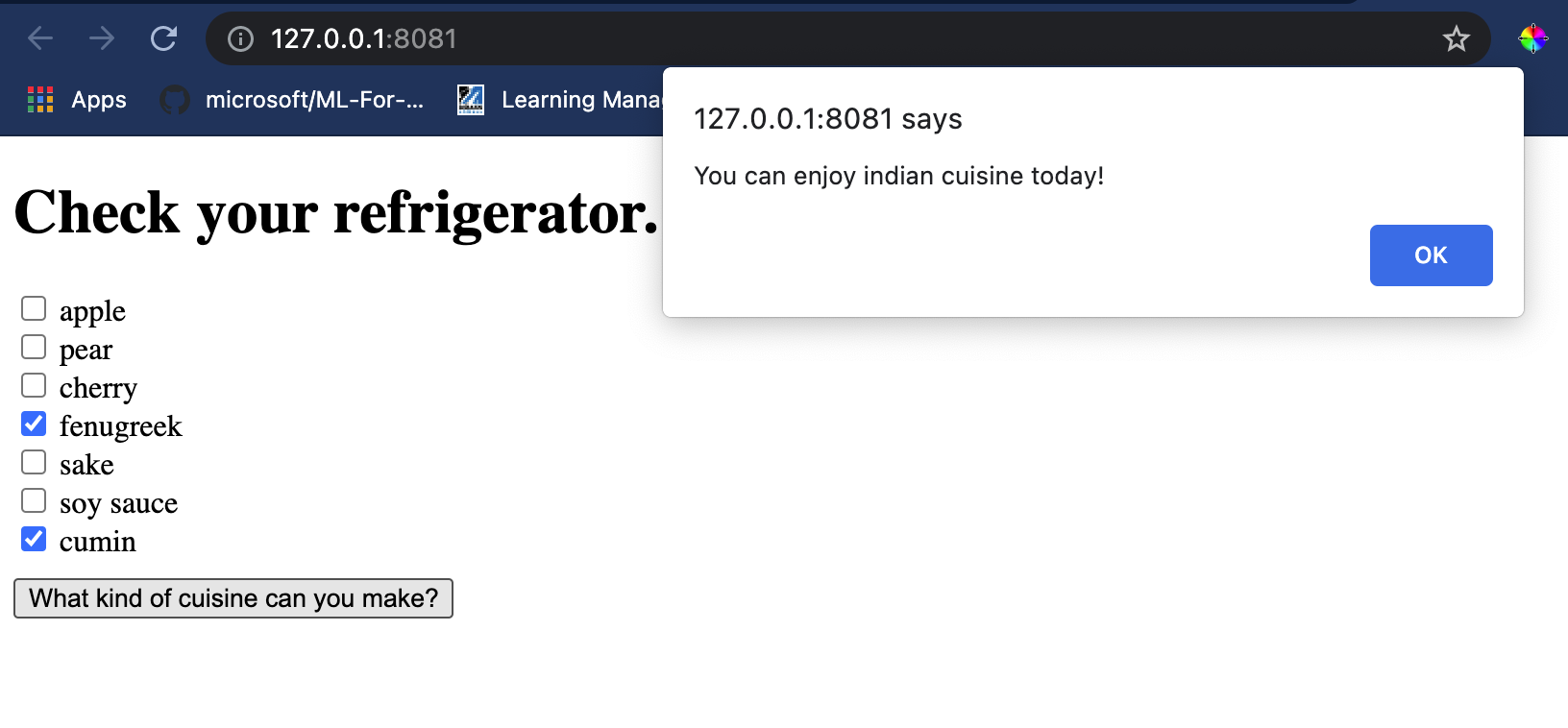
מזל טוב, יצרתם אפליקציית אינטרנט להמלצות עם כמה שדות. הקדישו זמן לבניית המערכת הזו!
## 🚀אתגר
אפליקציית האינטרנט שלכם מאוד מינימלית, אז המשיכו לבנות אותה באמצעות מרכיבים והאינדקסים שלהם מתוך נתוני [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv). אילו שילובי טעמים עובדים כדי ליצור מנה לאומית מסוימת?
## [שאלון לאחר השיעור](https://ff-quizzes.netlify.app/en/ml/)
## סקירה ולימוד עצמי
בעוד שהשיעור הזה רק נגע בשימושיות של יצירת מערכת המלצות למרכיבי מזון, תחום יישומי למידת מכונה זה עשיר בדוגמאות. קראו עוד על איך מערכות אלו נבנות:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## משימה
[בנו מערכת המלצות חדשה](assignment.md)
---
**כתב ויתור**:
מסמך זה תורגם באמצעות שירות תרגום מבוסס בינה מלאכותית [Co-op Translator](https://github.com/Azure/co-op-translator). למרות שאנו שואפים לדיוק, יש לקחת בחשבון שתרגומים אוטומטיים עשויים להכיל שגיאות או אי דיוקים. המסמך המקורי בשפתו המקורית צריך להיחשב כמקור סמכותי. עבור מידע קריטי, מומלץ להשתמש בתרגום מקצועי על ידי אדם. איננו נושאים באחריות לאי הבנות או לפרשנויות שגויות הנובעות משימוש בתרגום זה.