# Vytvořte webovou aplikaci pro doporučování kuchyní
V této lekci vytvoříte klasifikační model pomocí některých technik, které jste se naučili v předchozích lekcích, a s využitím datasetu lahodných kuchyní, který byl použit v celém tomto seriálu. Navíc vytvoříte malou webovou aplikaci, která bude používat uložený model, využívající webový runtime Onnx.
Jedním z nejpraktičtějších využití strojového učení je vytváření doporučovacích systémů, a dnes můžete udělat první krok tímto směrem!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 Klikněte na obrázek výše pro video: Jen Looper vytváří webovou aplikaci s klasifikovanými daty o kuchyních
## [Kvíz před lekcí](https://ff-quizzes.netlify.app/en/ml/)
V této lekci se naučíte:
- Jak vytvořit model a uložit ho jako Onnx model
- Jak použít Netron k inspekci modelu
- Jak použít váš model ve webové aplikaci pro inference
## Vytvořte svůj model
Vytváření aplikovaných systémů strojového učení je důležitou součástí využívání těchto technologií pro vaše obchodní systémy. Modely můžete použít ve svých webových aplikacích (a tím je použít v offline režimu, pokud je to potřeba) pomocí Onnx.
V [předchozí lekci](../../3-Web-App/1-Web-App/README.md) jste vytvořili regresní model o pozorování UFO, "picklovali" ho a použili ho v aplikaci Flask. Zatímco tato architektura je velmi užitečná, jedná se o full-stack Python aplikaci, a vaše požadavky mohou zahrnovat použití JavaScriptové aplikace.
V této lekci můžete vytvořit základní systém založený na JavaScriptu pro inference. Nejprve však musíte natrénovat model a převést ho pro použití s Onnx.
## Cvičení - natrénujte klasifikační model
Nejprve natrénujte klasifikační model pomocí vyčištěného datasetu kuchyní, který jsme použili.
1. Začněte importem užitečných knihoven:
```python
!pip install skl2onnx
import pandas as pd
```
Potřebujete '[skl2onnx](https://onnx.ai/sklearn-onnx/)', aby vám pomohl převést váš Scikit-learn model do formátu Onnx.
1. Poté pracujte s daty stejným způsobem jako v předchozích lekcích, načtením CSV souboru pomocí `read_csv()`:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. Odstraňte první dva nepotřebné sloupce a uložte zbývající data jako 'X':
```python
X = data.iloc[:,2:]
X.head()
```
1. Uložte štítky jako 'y':
```python
y = data[['cuisine']]
y.head()
```
### Zahajte tréninkovou rutinu
Použijeme knihovnu 'SVC', která má dobrou přesnost.
1. Importujte příslušné knihovny ze Scikit-learn:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. Oddělte trénovací a testovací sady:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. Vytvořte klasifikační model SVC, jak jste to udělali v předchozí lekci:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. Nyní otestujte svůj model, zavolejte `predict()`:
```python
y_pred = model.predict(X_test)
```
1. Vytiskněte klasifikační zprávu, abyste zkontrolovali kvalitu modelu:
```python
print(classification_report(y_test,y_pred))
```
Jak jsme viděli dříve, přesnost je dobrá:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### Převod modelu na Onnx
Ujistěte se, že převod provádíte s odpovídajícím počtem tensorů. Tento dataset má 380 uvedených ingrediencí, takže musíte tento počet uvést v `FloatTensorType`:
1. Proveďte převod s tensorovým číslem 380.
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. Vytvořte onx a uložte jako soubor **model.onnx**:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> Poznámka: Můžete předat [možnosti](https://onnx.ai/sklearn-onnx/parameterized.html) ve vašem skriptu pro převod. V tomto případě jsme nastavili 'nocl' na True a 'zipmap' na False. Protože se jedná o klasifikační model, máte možnost odstranit ZipMap, který produkuje seznam slovníků (není nutné). `nocl` se týká informací o třídách zahrnutých v modelu. Zmenšete velikost svého modelu nastavením `nocl` na 'True'.
Spuštěním celého notebooku nyní vytvoříte Onnx model a uložíte ho do této složky.
## Zobrazte svůj model
Onnx modely nejsou příliš viditelné ve Visual Studio Code, ale existuje velmi dobrý bezplatný software, který mnoho výzkumníků používá k vizualizaci modelu, aby se ujistili, že je správně vytvořen. Stáhněte si [Netron](https://github.com/lutzroeder/Netron) a otevřete svůj soubor model.onnx. Můžete vidět svůj jednoduchý model vizualizovaný, s jeho 380 vstupy a klasifikátorem uvedeným:

Netron je užitečný nástroj pro zobrazení vašich modelů.
Nyní jste připraveni použít tento šikovný model ve webové aplikaci. Vytvořme aplikaci, která se bude hodit, když se podíváte do své lednice a snažíte se zjistit, jakou kombinaci zbylých ingrediencí můžete použít k přípravě dané kuchyně, jak určí váš model.
## Vytvořte webovou aplikaci pro doporučování
Svůj model můžete použít přímo ve webové aplikaci. Tato architektura také umožňuje její lokální provoz a dokonce i offline, pokud je to potřeba. Začněte vytvořením souboru `index.html` ve stejné složce, kde jste uložili svůj soubor `model.onnx`.
1. V tomto souboru _index.html_ přidejte následující značky:
```html
Cuisine Matcher
...
```
1. Nyní, v rámci značek `body`, přidejte trochu značek pro zobrazení seznamu zaškrtávacích políček odrážejících některé ingredience:
```html
Check your refrigerator. What can you create?
```
Všimněte si, že každé zaškrtávací políčko má hodnotu. To odráží index, kde se ingredience nachází podle datasetu. Jablko, například, v tomto abecedním seznamu, zabírá pátý sloupec, takže jeho hodnota je '4', protože začínáme počítat od 0. Můžete se podívat na [tabulku ingrediencí](../../../../4-Classification/data/ingredient_indexes.csv), abyste zjistili index dané ingredience.
Pokračujte v práci v souboru index.html, přidejte blok skriptu, kde je model volán po závěrečném uzavíracím ``.
1. Nejprve importujte [Onnx Runtime](https://www.onnxruntime.ai/):
```html
```
> Onnx Runtime se používá k umožnění spuštění vašich Onnx modelů na široké škále hardwarových platforem, včetně optimalizací a API pro použití.
1. Jakmile je Runtime na místě, můžete ho zavolat:
```html
```
V tomto kódu se děje několik věcí:
1. Vytvořili jste pole 380 možných hodnot (1 nebo 0), které budou nastaveny a odeslány modelu pro inference, v závislosti na tom, zda je zaškrtávací políčko zaškrtnuto.
2. Vytvořili jste pole zaškrtávacích políček a způsob, jak zjistit, zda byla zaškrtnuta, ve funkci `init`, která je volána při spuštění aplikace. Když je zaškrtávací políčko zaškrtnuto, pole `ingredients` se změní tak, aby odráželo vybranou ingredienci.
3. Vytvořili jste funkci `testCheckboxes`, která kontroluje, zda bylo zaškrtnuto nějaké zaškrtávací políčko.
4. Používáte funkci `startInference`, když je stisknuto tlačítko, a pokud je zaškrtnuto nějaké zaškrtávací políčko, zahájíte inference.
5. Rutina inference zahrnuje:
1. Nastavení asynchronního načítání modelu
2. Vytvoření struktury Tensor pro odeslání modelu
3. Vytvoření 'feeds', které odráží vstup `float_input`, který jste vytvořili při trénování modelu (můžete použít Netron k ověření tohoto názvu)
4. Odeslání těchto 'feeds' modelu a čekání na odpověď
## Otestujte svou aplikaci
Otevřete terminálovou relaci ve Visual Studio Code ve složce, kde se nachází váš soubor index.html. Ujistěte se, že máte [http-server](https://www.npmjs.com/package/http-server) nainstalovaný globálně, a napište `http-server` na výzvu. Měl by se otevřít localhost a můžete si prohlédnout svou webovou aplikaci. Zkontrolujte, jaká kuchyně je doporučena na základě různých ingrediencí:
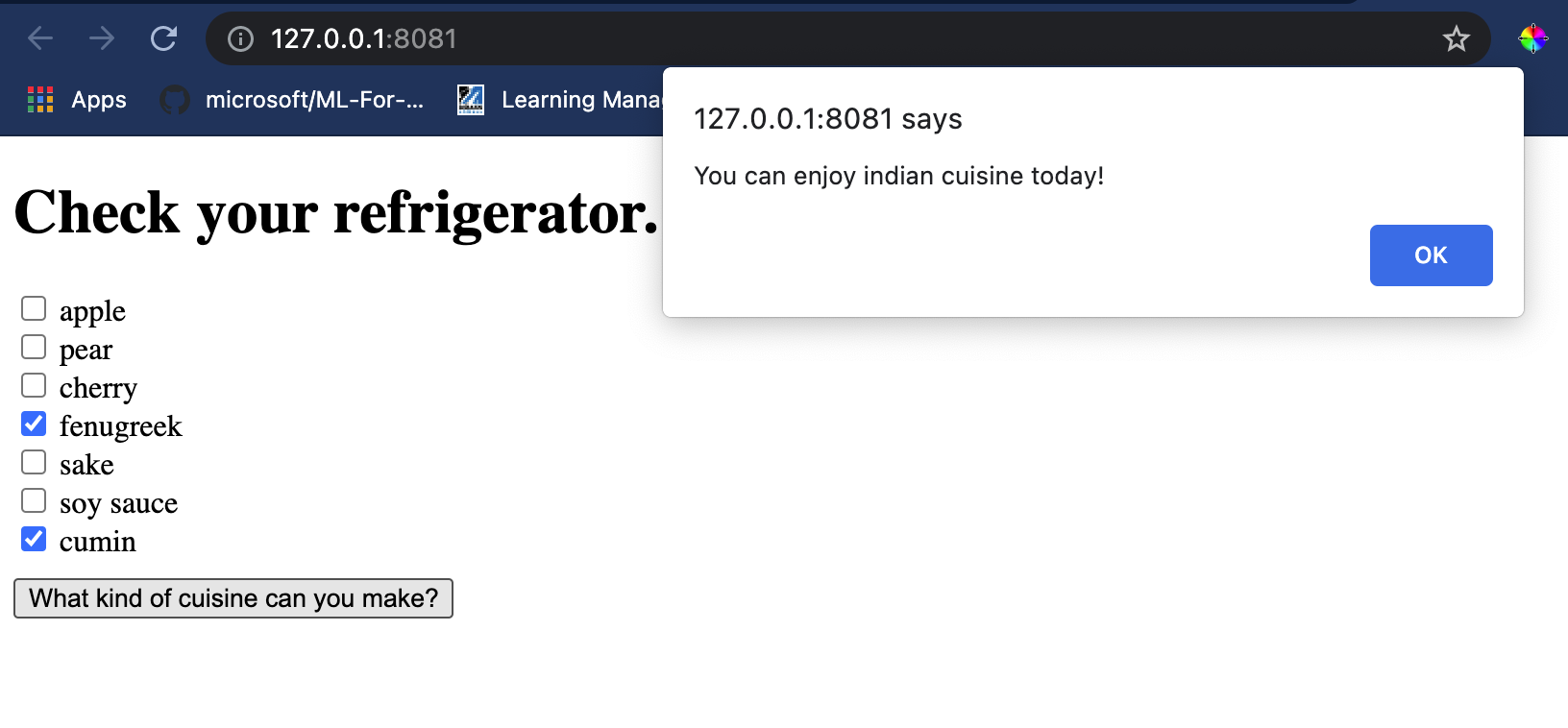
Gratulujeme, vytvořili jste webovou aplikaci pro 'doporučování' s několika poli. Věnujte nějaký čas rozšíření tohoto systému!
## 🚀Výzva
Vaše webová aplikace je velmi jednoduchá, takže ji pokračujte rozšiřovat pomocí ingrediencí a jejich indexů z dat [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv). Jaké kombinace chutí fungují pro vytvoření daného národního jídla?
## [Kvíz po lekci](https://ff-quizzes.netlify.app/en/ml/)
## Přehled & Samostudium
Zatímco tato lekce se jen dotkla užitečnosti vytváření doporučovacího systému pro ingredience, tato oblast aplikací strojového učení je velmi bohatá na příklady. Přečtěte si více o tom, jak jsou tyto systémy vytvářeny:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## Úkol
[Vytvořte nový doporučovací systém](assignment.md)
---
**Prohlášení**:
Tento dokument byl přeložen pomocí služby pro automatický překlad [Co-op Translator](https://github.com/Azure/co-op-translator). I když se snažíme o přesnost, mějte prosím na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Původní dokument v jeho původním jazyce by měl být považován za autoritativní zdroj. Pro důležité informace se doporučuje profesionální lidský překlad. Neodpovídáme za žádné nedorozumění nebo nesprávné interpretace vyplývající z použití tohoto překladu.