# একটি কুইজিন রিকমেন্ডার ওয়েব অ্যাপ তৈরি করুন
এই পাঠে, আপনি পূর্ববর্তী পাঠে শেখা কিছু কৌশল ব্যবহার করে একটি ক্লাসিফিকেশন মডেল তৈরি করবেন এবং এই সিরিজে ব্যবহৃত সুস্বাদু কুইজিন ডেটাসেট ব্যবহার করবেন। এছাড়াও, আপনি একটি ছোট ওয়েব অ্যাপ তৈরি করবেন যা একটি সংরক্ষিত মডেল ব্যবহার করবে, Onnx-এর ওয়েব রানটাইম ব্যবহার করে।
মেশিন লার্নিংয়ের অন্যতম কার্যকর ব্যবহার হল রিকমেন্ডেশন সিস্টেম তৈরি করা, এবং আপনি আজ সেই দিকে প্রথম পদক্ষেপ নিতে পারেন!
[](https://youtu.be/17wdM9AHMfg "Applied ML")
> 🎥 উপরের ছবিতে ক্লিক করুন একটি ভিডিওর জন্য: জেন লুপার ক্লাসিফাইড কুইজিন ডেটা ব্যবহার করে একটি ওয়েব অ্যাপ তৈরি করছেন
## [পাঠের পূর্ববর্তী কুইজ](https://ff-quizzes.netlify.app/en/ml/)
এই পাঠে আপনি শিখবেন:
- কীভাবে একটি মডেল তৈরি করে সেটিকে Onnx মডেল হিসেবে সংরক্ষণ করবেন
- কীভাবে Netron ব্যবহার করে মডেলটি পরিদর্শন করবেন
- কীভাবে আপনার মডেলটি একটি ওয়েব অ্যাপে ব্যবহার করবেন ইনফারেন্সের জন্য
## আপনার মডেল তৈরি করুন
প্রয়োগকৃত মেশিন লার্নিং সিস্টেম তৈরি করা আপনার ব্যবসায়িক সিস্টেমে এই প্রযুক্তিগুলি ব্যবহার করার একটি গুরুত্বপূর্ণ অংশ। আপনি আপনার ওয়েব অ্যাপ্লিকেশনের মধ্যে মডেল ব্যবহার করতে পারেন (এবং প্রয়োজনে অফলাইন প্রসঙ্গে ব্যবহার করতে পারেন) Onnx ব্যবহার করে।
একটি [পূর্ববর্তী পাঠে](../../3-Web-App/1-Web-App/README.md), আপনি UFO দর্শন সম্পর্কিত একটি রিগ্রেশন মডেল তৈরি করেছিলেন, সেটিকে "পিকল" করেছিলেন এবং একটি Flask অ্যাপে ব্যবহার করেছিলেন। যদিও এই আর্কিটেকচারটি জানা খুবই দরকারি, এটি একটি ফুল-স্ট্যাক পাইথন অ্যাপ, এবং আপনার প্রয়োজনীয়তাগুলি একটি জাভাস্ক্রিপ্ট অ্যাপ্লিকেশন ব্যবহার করার অন্তর্ভুক্ত হতে পারে।
এই পাঠে, আপনি ইনফারেন্সের জন্য একটি বেসিক জাভাস্ক্রিপ্ট-ভিত্তিক সিস্টেম তৈরি করতে পারেন। তবে প্রথমে, আপনাকে একটি মডেল প্রশিক্ষণ দিতে হবে এবং সেটিকে Onnx-এ রূপান্তর করতে হবে।
## অনুশীলন - ক্লাসিফিকেশন মডেল প্রশিক্ষণ দিন
প্রথমে, পূর্বে ব্যবহৃত পরিষ্কার করা কুইজিন ডেটাসেট ব্যবহার করে একটি ক্লাসিফিকেশন মডেল প্রশিক্ষণ দিন।
1. দরকারী লাইব্রেরি আমদানি করে শুরু করুন:
```python
!pip install skl2onnx
import pandas as pd
```
আপনাকে '[skl2onnx](https://onnx.ai/sklearn-onnx/)' প্রয়োজন হবে যা আপনার Scikit-learn মডেলকে Onnx ফরম্যাটে রূপান্তর করতে সাহায্য করবে।
1. তারপর, পূর্ববর্তী পাঠে যেমন করেছিলেন, `read_csv()` ব্যবহার করে একটি CSV ফাইল নিয়ে কাজ করুন:
```python
data = pd.read_csv('../data/cleaned_cuisines.csv')
data.head()
```
1. প্রথম দুটি অপ্রয়োজনীয় কলাম সরিয়ে ফেলুন এবং অবশিষ্ট ডেটা 'X' হিসেবে সংরক্ষণ করুন:
```python
X = data.iloc[:,2:]
X.head()
```
1. লেবেলগুলো 'y' হিসেবে সংরক্ষণ করুন:
```python
y = data[['cuisine']]
y.head()
```
### প্রশিক্ষণ রুটিন শুরু করুন
আমরা 'SVC' লাইব্রেরি ব্যবহার করব যা ভালো সঠিকতা প্রদান করে।
1. Scikit-learn থেকে প্রাসঙ্গিক লাইব্রেরি আমদানি করুন:
```python
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
```
1. প্রশিক্ষণ এবং টেস্ট সেট আলাদা করুন:
```python
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
```
1. পূর্ববর্তী পাঠে যেমন করেছিলেন, একটি SVC ক্লাসিফিকেশন মডেল তৈরি করুন:
```python
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
```
1. এখন, আপনার মডেল পরীক্ষা করুন, `predict()` কল করে:
```python
y_pred = model.predict(X_test)
```
1. মডেলের গুণমান পরীক্ষা করতে একটি ক্লাসিফিকেশন রিপোর্ট প্রিন্ট করুন:
```python
print(classification_report(y_test,y_pred))
```
পূর্বে যেমন দেখেছি, সঠিকতা ভালো:
```output
precision recall f1-score support
chinese 0.72 0.69 0.70 257
indian 0.91 0.87 0.89 243
japanese 0.79 0.77 0.78 239
korean 0.83 0.79 0.81 236
thai 0.72 0.84 0.78 224
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.79 0.79 0.79 1199
```
### আপনার মডেলকে Onnx-এ রূপান্তর করুন
সঠিক টেনসর সংখ্যা দিয়ে রূপান্তর নিশ্চিত করুন। এই ডেটাসেটে ৩৮০টি উপাদান তালিকাভুক্ত রয়েছে, তাই আপনাকে `FloatTensorType`-এ সেই সংখ্যা উল্লেখ করতে হবে:
1. ৩৮০ টেনসর সংখ্যা ব্যবহার করে রূপান্তর করুন।
```python
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
```
1. একটি onx তৈরি করুন এবং **model.onnx** নামে একটি ফাইল হিসেবে সংরক্ষণ করুন:
```python
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())
```
> লক্ষ্য করুন, আপনি আপনার রূপান্তর স্ক্রিপ্টে [options](https://onnx.ai/sklearn-onnx/parameterized.html) পাস করতে পারেন। এই ক্ষেত্রে, আমরা 'nocl' কে True এবং 'zipmap' কে False পাস করেছি। যেহেতু এটি একটি ক্লাসিফিকেশন মডেল, আপনি ZipMap সরানোর বিকল্পটি ব্যবহার করতে পারেন যা একটি ডিকশনারির তালিকা তৈরি করে (প্রয়োজনীয় নয়)। `nocl` মডেলে ক্লাস তথ্য অন্তর্ভুক্ত হওয়ার বিষয়টি নির্দেশ করে। `nocl` কে 'True' সেট করে আপনার মডেলের আকার কমান।
পুরো নোটবুক চালানো এখন একটি Onnx মডেল তৈরি করবে এবং এটি এই ফোল্ডারে সংরক্ষণ করবে।
## আপনার মডেল দেখুন
Onnx মডেলগুলি Visual Studio কোডে খুব বেশি দৃশ্যমান নয়, তবে একটি খুব ভালো ফ্রি সফটওয়্যার রয়েছে যা অনেক গবেষক মডেলটি সঠিকভাবে তৈরি হয়েছে কিনা তা নিশ্চিত করতে ব্যবহার করেন। [Netron](https://github.com/lutzroeder/Netron) ডাউনলোড করুন এবং আপনার model.onnx ফাইলটি খুলুন। আপনি আপনার সহজ মডেলটি দেখতে পাবেন, এর ৩৮০টি ইনপুট এবং ক্লাসিফায়ার তালিকাভুক্ত:

Netron আপনার মডেলগুলি দেখার জন্য একটি সহায়ক টুল।
এখন আপনি এই চমৎকার মডেলটি একটি ওয়েব অ্যাপে ব্যবহার করতে প্রস্তুত। আসুন একটি অ্যাপ তৈরি করি যা আপনার ফ্রিজে থাকা উপাদানগুলির সংমিশ্রণ দেখে নির্ধারণ করবে কোন কুইজিন তৈরি করা যেতে পারে, আপনার মডেল দ্বারা নির্ধারিত।
## একটি রিকমেন্ডার ওয়েব অ্যাপ্লিকেশন তৈরি করুন
আপনি আপনার মডেলটি সরাসরি একটি ওয়েব অ্যাপে ব্যবহার করতে পারেন। এই আর্কিটেকচারটি আপনাকে এটি স্থানীয়ভাবে এবং এমনকি প্রয়োজনে অফলাইনে চালানোর অনুমতি দেয়। `index.html` নামে একটি ফাইল তৈরি করে শুরু করুন যেখানে আপনি আপনার `model.onnx` ফাইল সংরক্ষণ করেছেন।
1. এই ফাইল _index.html_-এ নিম্নলিখিত মার্কআপ যোগ করুন:
```html
Cuisine Matcher
...
```
1. এখন, `body` ট্যাগের মধ্যে কাজ করে, কিছু উপাদান দেখানোর জন্য একটি চেকবক্সের তালিকা যোগ করুন:
```html
Check your refrigerator. What can you create?
```
লক্ষ্য করুন যে প্রতিটি চেকবক্সকে একটি মান দেওয়া হয়েছে। এটি ডেটাসেট অনুযায়ী উপাদানটি যেখানে পাওয়া যায় সেই সূচকটি প্রতিফলিত করে। উদাহরণস্বরূপ, আপেল এই বর্ণানুক্রমিক তালিকায় পঞ্চম কলামে রয়েছে, তাই এর মান '4' কারণ আমরা 0 থেকে গণনা শুরু করি। আপনি [উপাদান স্প্রেডশিট](../../../../4-Classification/data/ingredient_indexes.csv) পরামর্শ করতে পারেন একটি নির্দিষ্ট উপাদানের সূচক আবিষ্কার করতে।
আপনার কাজ index.html ফাইলে চালিয়ে যান, একটি স্ক্রিপ্ট ব্লক যোগ করুন যেখানে মডেলটি চূড়ান্ত বন্ধ `` এর পরে কল করা হয়।
1. প্রথমে, [Onnx Runtime](https://www.onnxruntime.ai/) আমদানি করুন:
```html
```
> Onnx Runtime ব্যবহার করা হয় আপনার Onnx মডেলগুলি বিভিন্ন হার্ডওয়্যার প্ল্যাটফর্মে চালানোর জন্য, অপ্টিমাইজেশন এবং একটি API সহ।
1. Runtime ইনপ্লেস করার পরে, আপনি এটি কল করতে পারেন:
```html
```
এই কোডে, কয়েকটি জিনিস ঘটছে:
1. আপনি ৩৮০ সম্ভাব্য মানের একটি অ্যারে তৈরি করেছেন (1 বা 0) যা সেট করা হবে এবং ইনফারেন্সের জন্য মডেলে পাঠানো হবে, নির্ভর করে একটি উপাদান চেকবক্স চেক করা হয়েছে কিনা।
2. আপনি একটি চেকবক্সের অ্যারে তৈরি করেছেন এবং একটি `init` ফাংশন তৈরি করেছেন যা অ্যাপ্লিকেশন শুরু হলে কল করা হয়। যখন একটি চেকবক্স চেক করা হয়, তখন `ingredients` অ্যারে সংশোধিত হয় নির্বাচিত উপাদানটি প্রতিফলিত করতে।
3. আপনি একটি `testCheckboxes` ফাংশন তৈরি করেছেন যা পরীক্ষা করে কোনো চেকবক্স চেক করা হয়েছে কিনা।
4. আপনি `startInference` ফাংশন ব্যবহার করেন যখন বোতামটি চাপা হয় এবং যদি কোনো চেকবক্স চেক করা হয়, আপনি ইনফারেন্স শুরু করেন।
5. ইনফারেন্স রুটিন অন্তর্ভুক্ত:
1. মডেলের একটি অ্যাসিঙ্ক্রোনাস লোড সেটআপ করা
2. মডেলে পাঠানোর জন্য একটি টেনসর স্ট্রাকচার তৈরি করা
3. 'feeds' তৈরি করা যা `float_input` ইনপুট প্রতিফলিত করে যা আপনি আপনার মডেল প্রশিক্ষণ দেওয়ার সময় তৈরি করেছিলেন (আপনি Netron ব্যবহার করে সেই নামটি যাচাই করতে পারেন)
4. এই 'feeds' মডেলে পাঠানো এবং একটি প্রতিক্রিয়ার জন্য অপেক্ষা করা
## আপনার অ্যাপ্লিকেশন পরীক্ষা করুন
Visual Studio Code-এ একটি টার্মিনাল সেশন খুলুন যেখানে আপনার index.html ফাইল রয়েছে। নিশ্চিত করুন যে আপনার [http-server](https://www.npmjs.com/package/http-server) গ্লোবালি ইনস্টল করা আছে এবং প্রম্পটে `http-server` টাইপ করুন। একটি লোকালহোস্ট খুলবে এবং আপনি আপনার ওয়েব অ্যাপ দেখতে পারবেন। বিভিন্ন উপাদানের উপর ভিত্তি করে কোন কুইজিন সুপারিশ করা হয়েছে তা পরীক্ষা করুন:
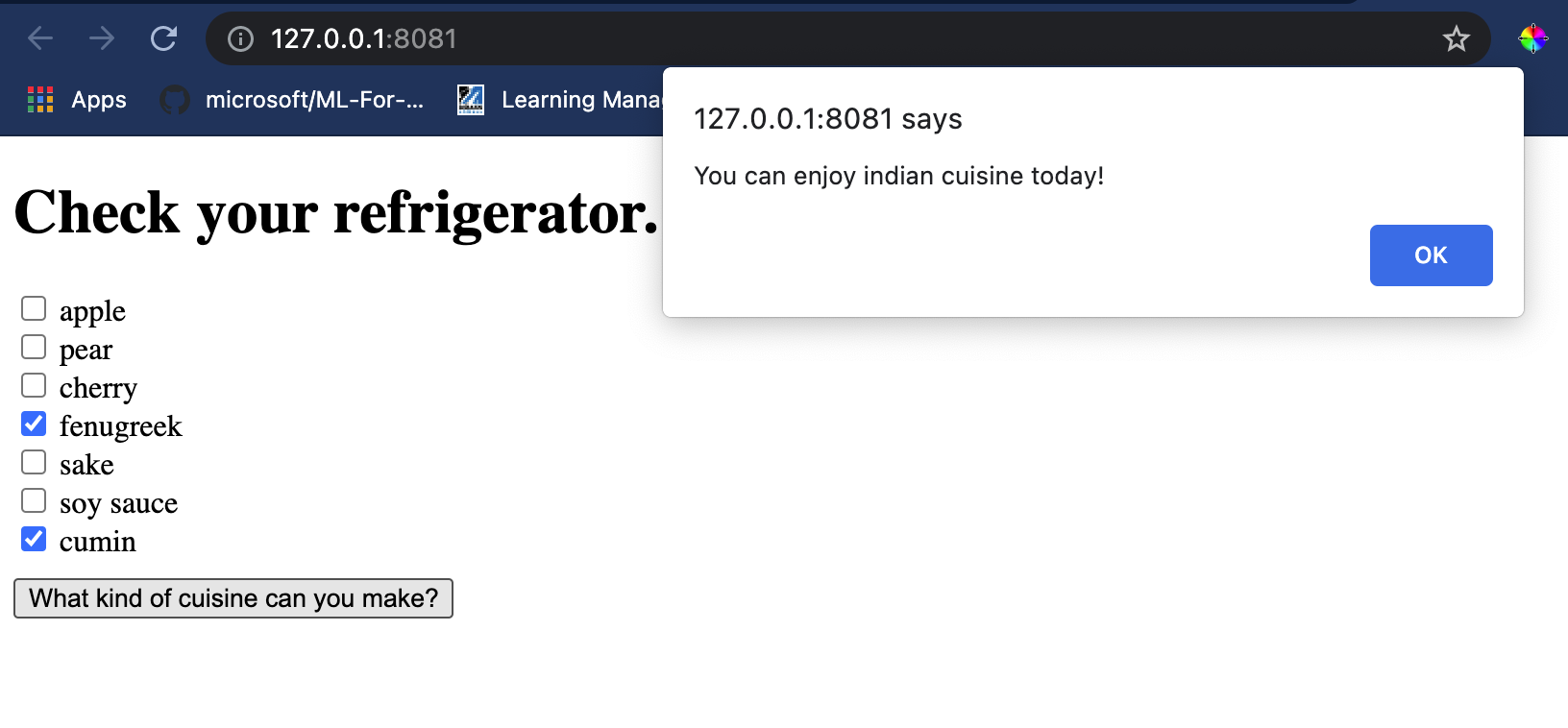
অভিনন্দন, আপনি কয়েকটি ক্ষেত্র সহ একটি 'রিকমেন্ডেশন' ওয়েব অ্যাপ তৈরি করেছেন। এই সিস্টেমটি তৈরি করতে কিছু সময় নিন!
## 🚀চ্যালেঞ্জ
আপনার ওয়েব অ্যাপটি খুবই সাধারণ, তাই [ingredient_indexes](../../../../4-Classification/data/ingredient_indexes.csv) ডেটা থেকে উপাদান এবং তাদের সূচক ব্যবহার করে এটি তৈরি করতে থাকুন। কোন স্বাদ সংমিশ্রণ একটি নির্দিষ্ট জাতীয় খাবার তৈরি করতে কাজ করে?
## [পাঠের পরবর্তী কুইজ](https://ff-quizzes.netlify.app/en/ml/)
## পর্যালোচনা এবং স্ব-অধ্যয়ন
যদিও এই পাঠটি খাদ্য উপাদানগুলির জন্য একটি রিকমেন্ডেশন সিস্টেম তৈরির উপযোগিতা নিয়ে সংক্ষিপ্ত আলোচনা করেছে, এই মেশিন লার্নিং অ্যাপ্লিকেশনের ক্ষেত্রটি উদাহরণে খুবই সমৃদ্ধ। এই সিস্টেমগুলি কীভাবে তৈরি হয় সে সম্পর্কে আরও পড়ুন:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
## অ্যাসাইনমেন্ট
[নতুন একটি রিকমেন্ডার তৈরি করুন](assignment.md)
---
**অস্বীকৃতি**:
এই নথিটি AI অনুবাদ পরিষেবা [Co-op Translator](https://github.com/Azure/co-op-translator) ব্যবহার করে অনুবাদ করা হয়েছে। আমরা যথাসাধ্য সঠিকতার জন্য চেষ্টা করি, তবে অনুগ্রহ করে মনে রাখবেন যে স্বয়ংক্রিয় অনুবাদে ত্রুটি বা অসঙ্গতি থাকতে পারে। মূল ভাষায় থাকা নথিটিকে প্রামাণিক উৎস হিসেবে বিবেচনা করা উচিত। গুরুত্বপূর্ণ তথ্যের জন্য, পেশাদার মানব অনুবাদ সুপারিশ করা হয়। এই অনুবাদ ব্যবহারের ফলে কোনো ভুল বোঝাবুঝি বা ভুল ব্যাখ্যা হলে আমরা দায়বদ্ধ থাকব না।