[](https://youtu.be/lTd9RSxS9ZE "ML, AI, deep learning - What's the difference?")
> 🎥 Click the image above for a video discussing the difference between machine learning, AI, and deep learning.
[](https://youtu.be/6mSx_KJxcHI "ML for beginners - Introduction to Machine Learning for Beginners")
> 🎥 Click the image above for a short video working through this lesson.
Welcome to this course on classical machine learning for beginners! Whether you're completely new to this topic, or an experienced ML practitioner looking to brush up on an area, we're happy to have you join us! We want to create a friendly launching spot for your ML study and would be happy to evaluate, respond to, and incorporate your [feedback](https://github.com/microsoft/ML-For-Beginners/discussions).
[](https://youtu.be/h0e2HAPTGF4 "Introduction to ML")
[](https://youtu.be/N6wxM4wZ7V0 "ML for beginners - History of Machine Learning")
> 🎥 Click the image above for a short video working through this lesson.
In this lesson, we will walk through the major milestones in the history of machine learning and artificial intelligence.
The history of artificial intelligence (AI) as a field is intertwined with the history of machine learning, as the algorithms and computational advances that underpin ML fed into the development of AI. It is useful to remember that, while these fields as distinct areas of inquiry began to crystallize in the 1950s, important [algorithmic, statistical, mathematical, computational and technical discoveries](https://wikipedia.org/wiki/Timeline_of_machine_learning) predated and overlapped this era. In fact, people have been thinking about these questions for [hundreds of years](https://wikipedia.org/wiki/History_of_artificial_intelligence): this article discusses the historical intellectual underpinnings of the idea of a 'thinking machine.'
In this curriculum, you will start to discover how machine learning can and is impacting our everyday lives. Even now, systems and models are involved in daily decision-making tasks, such as health care diagnoses or detecting fraud. So it is important that these models work well in order to provide fair outcomes for everyone.
In this curriculum, you will start to discover how machine learning can and is impacting our everyday lives. Even now, systems and models are involved in daily decision-making tasks, such as health care diagnoses, loan approvals or detecting fraud. So, it is important that these models work well to provide outcomes that are trustworthy. Just as any software application, AI systems are going to miss expectations or have an undesirable outcome. That is why it is essential to be about to understand and explain the behavior of an AI model.
Imagine what can happen when the data you are using to build these models lacks certain demographics, such as race, gender, political view, religion, or disproportionally represents such demographics. What about when the model's output is interpreted to favor some demographic? What is the consequence for the application?
Imagine what can happen when the data you are using to build these models lacks certain demographics, such as race, gender, political view, religion, or disproportionally represents such demographics. What about when the model’s output is interpreted to favor some demographic? What is the consequence for the application? In addition, what happens when the model has an adverse outcome and is harmful to people? Who is accountable for the AI systems behavior? These are some questions we will explore in this curriculum.
In this lesson, you will:
In this lesson, you will:
- Raise your awareness of the importance of fairness in machine learning.
- Learn about fairness-related harms.
@ -27,19 +27,11 @@ Learn more about Responsible AI by following this [Learning Path](https://docs.m
> 🎥 Click the image above for a video: Microsoft's Approach to Responsible AI
## Unfairness in data and algorithms
## Fairness
> "If you torture the data long enough, it will confess to anything" - Ronald Coase
AI systems should treat everyone fairly and avoid affecting similar groups of people in different ways. For example, when AI systems provide guidance on medical treatment, loan applications, or employment, they should make the same recommendations to everyone with similar symptoms, financial circumstances, or professional qualifications. Each of us as humans carries around inherited biases that affect our decisions and actions. These biases can be evident in the data that we use to train AI systems. Such manipulation can sometimes happen unintentionally. It is often difficult to consciously know when you are introducing bias in data.
This statement sounds extreme, but it is true that data can be manipulated to support any conclusion. Such manipulation can sometimes happen unintentionally. As humans, we all have bias, and it's often difficult to consciously know when you are introducing bias in data.
Guaranteeing fairness in AI and machine learning remains a complex sociotechnical challenge. Meaning that it cannot be addressed from either purely social or technical perspectives.
### Fairness-related harms
What do you mean by unfairness? "Unfairness" encompasses negative impacts, or "harms", for a group of people, such as those defined in terms of race, gender, age, or disability status.
The main fairness-related harms can be classified as:
**“Unfairness”** encompasses negative impacts, or “harms”, for a group of people, such as those defined in terms of race, gender, age, or disability status. The main fairness-related harms can be classified as:
- **Allocation**, if a gender or ethnicity for example is favored over another.
- **Quality of service**. If you train the data for one specific scenario but reality is much more complex, it leads to a poor performing service.
@ -47,46 +39,94 @@ The main fairness-related harms can be classified as:
- **Denigration**. To unfairly criticize and label something or someone.
- **Over- or under- representation**. The idea is that a certain group is not seen in a certain profession, and any service or function that keeps promoting that is contributing to harm.
Let’s take a look at the examples.
When designing and testing AI systems, we need to ensure that AI is fair and not programmed to make biased or discriminatory decisions, which human beings are also prohibited from making. Guaranteeing fairness in AI and machine learning remains a complex sociotechnical challenge.
### Allocation
### Reliability and safety
Consider a hypothetical system for screening loan applications. The system tends to pick white men as better candidates over other groups. As a result, loans are withheld from certain applicants.
To build trust, AI systems need to be reliable, safe, and consistent under normal and unexpected conditions. It is important to know how AI systems will behavior in a variety of situations, especially when they are outliers. When building AI solutions, there needs to be a substantial amount of focus on how to handle a wide variety of circumstances that the AI solutions would encounter.
Another example would be an experimental hiring tool developed by a large corporation to screen candidates. The tool systemically discriminated against one gender by using the models were trained to prefer words associated with another. It resulted in penalizing candidates whose resumes contain words such as "women’s rugby team".
For example, a self-driving car needs to put people's safety as a top priority. As a result, the AI powering the car need to consider all the possible scenarios that the car could come across such as night, thunderstorms or blizzards, kids running across the street, pets, road constructions etc. How well an AI system can handle a wild range of conditions reliably and safely reflects the level of anticipation the data scientist or AI developer considered during the design or testing of the system.
✅ Do a little research to find a real-world example of something like this
<!-- [](https://youtu.be/dnC8-uUZXSc "Microsoft's Approach to Responsible AI")
### Quality of Service
> 🎥 Click the image above for a video: Ensure reliability and safety in AI -->
Researchers found that several commercial gender classifiers had higher error rates around images of women with darker skin tones as opposed to images of men with lighter skin tones. [Reference](https://www.media.mit.edu/publications/gender-shades-intersectional-accuracy-disparities-in-commercial-gender-classification/)
### Inclusiveness
AI systems should be designed to engage and empower everyone. When designing and implementing AI systems data scientists and AI developers identify and address potential barriers in the system that could unintentionally exclude people. For example, there are 1 billion people with disabilities around the world. With the advancement of AI, they can access a wide range of information and opportunities more easily in their daily lives. By addressing the barriers, it creates opportunities to innovate and develop AI products with better experiences that benefit everyone.

> Inclusive systems for accessibility
### Security and privacy
Another infamous example is a hand soap dispenser that could not seem to be able to sense people with dark skin. [Reference](https://gizmodo.com/why-cant-this-soap-dispenser-identify-dark-skin-1797931773)
AI systems should be safe and respect people’s privacy. People have less trust in systems that put their privacy, information, or lives at risk. When training machine learning models, we rely on data to produce the best results. In doing so, the origin of the data and integrity must be considered. For example, was the data user submitted or publicly available?
### Stereotyping
Next, while working with the data, it is crucial to develop AI systems that can protect confidential information and resist attacks. As AI becomes more prevalent, protecting privacy and securing important personal and business information is becoming more critical and complex. Privacy and data security issues require especially close attention for AI because access to data is essential for AI systems to make accurate and informed predictions and decisions about people.
- As an industry we have made significant advancements in Privacy & security, fueled significantly by regulations like the GDPR (General Data Protection Regulation).
- Yet with AI systems we must acknowledge the tension between the need for more personal data to make systems more personal and effective – and privacy.
- Just like with the birth of connected computers with the internet, we are also seeing a huge uptick in the number of security issues related to AI.
- At the same time, we have seen AI being used to improve security. As an example, most modern anti-virus scanners are driven by AI heuristics today.
- We need to ensure that our Data Science processes blend harmoniously with the latest privacy and security practices.
### Transparency
AI systems should be understandable. A crucial part of transparency is explaining the behavior of AI systems and their components. Improving the understanding of AI systems requires that stakeholders comprehend how and why they function so that they can identify potential performance issues, safety and privacy concerns, biases, exclusionary practices, or unintended outcomes. We also believe that those who use AI systems should be honest and forthcoming about when, why, and how they choose to deploy them. As well as the limitations of the systems they use.
For example, if a bank uses an AI system to support its consumer lending decisions, it is important to examine the outcomes and understand which data influences the system’s recommendations. Governments are starting to regulate AI across industries, so data scientists and organizations must explain if an AI system meets regulatory requirements, especially when there is an undesirable outcome.
- Because AI systems are so complex, it is hard to understand how they work and interpret the results.
- This lack of understanding affects the way these systems are managed, operationalized, and documented.
- This lack of understanding more importantly affects the decisions made using the results these systems produce.
### Accountability
The people who design and deploy AI systems must be accountable for how their systems operate. The need for accountability is particularly crucial with sensitive use technologies like facial recognition. Recently, there has been a growing demand for facial recognition technology, especially from law enforcement organizations who see the potential of the technology in uses like finding missing children. However, these technologies could potentially be used by a government to put their citizens’ fundamental freedoms at risk by, for example, enabling continuous surveillance of specific individuals. Hence, data scientists and organizations need to be responsible for how their AI system impacts individuals or society.
Stereotypical gender view was found in machine translation. When translating “he is a nurse and she is a doctor” into Turkish, problems were encountered. Turkish is a genderless language which has one pronoun, “o” to convey a singular third person, but translating the sentence back from Turkish to English yields the stereotypical and incorrect as “she is a nurse and he is a doctor”.
[](https://www.youtube.com/watch?v=Wldt8P5V6D0 "Microsoft's Approach to Responsible AI")
> 🎥 Click the image above for a video: Warnings of Mass Surveillance Through Facial Recognition
One of the biggest questions for our generation, as the first generation that is bringing AI to society, is how to ensure that computers will remain accountable to people and how to ensure that the people that design computers remain accountable to everyone else.
Let us look at the examples.
#### Allocation
Consider a hypothetical system for screening loan applications. The system tends to pick white men as better candidates over other groups. As a result, loans are withheld from certain applicants.
Another example would be an experimental hiring tool developed by a large corporation to screen candidates. The tool systemically discriminated against one gender by using the models were trained to prefer words associated with another. It resulted in penalizing candidates whose resumes contain words such as “women’s rugby team”.
✅ Do a little research to find a real-world example of something like this.
#### Quality of Service
Researchers found that several commercial gender classifiers had higher error rates around images of women with darker skin tones as opposed to images of men with lighter skin tones. [Reference](https://www.media.mit.edu/publications/gender-shades-intersectional-accuracy-disparities-in-commercial-gender-classification/)
Another infamous example is a hand soap dispenser that could not seem to be able to sense people with dark skin. [Reference](https://gizmodo.com/why-cant-this-soap-dispenser-identify-dark-skin-1797931773)
#### Stereotyping
A stereotypical gender view was found in machine translation. When translating “he is a nurse and she is a doctor” into Turkish, problems were encountered. Turkish is a genderless language which has one pronoun, “o” to convey a singular third person, but translating the sentence back from Turkish to English yields the stereotypical and incorrect as “she is a nurse, and he is a doctor.”

> translation to Turkish

> translation back to English
### Denigration
An image labeling technology infamously mislabeled images of dark-skinned people as gorillas. Mislabeling is harmful not just because the system made a mistake because it specifically applied a label that has a long history of being purposefully used to denigrate Black people.
#### Denigration
An image labeling technology infamously mislabeled images of dark-skinned people as gorillas. Mislabeling is harmful not just because the system made a mistake because it specifically applied a label that has a long history of being purposefully used to denigrate Black people.
[](https://www.youtube.com/watch?v=QxuyfWoVV98 "AI, Ain't I a Woman?")
[](https://www.youtube.com/watch?v=QxuyfWoVV98 "AI, Ain't I a Woman?")
> 🎥 Click the image above for a video: AI, Ain't I a Woman - a performance showing the harm caused by racist denigration by AI
### Over- or under- representation
Skewed image search results can be a good example of this harm. When searching images of professions with an equal or higher percentage of men than women, such as engineering, or CEO, watch for results that are more heavily skewed towards a given gender.
#### Over-representation or under-representation
Skewed image search results can be a good example of this harm. When searching images of professions with an equal or higher percentage of men than women, such as engineering, or CEO, watch for results that are more heavily skewed towards a given gender.

> This search on Bing for 'CEO' produces pretty inclusive results

> This search on Bing for ‘CEO’ produces inclusive results
These five main types of harm are not mutually exclusive, and a single system can exhibit more than one type of harm. In addition, each case varies in its severity. For instance, unfairly labeling someone as a criminal is a much more severe harm than mislabeling an image. It is important, however, to remember that even relatively non-severe harms can make people feel alienated or singled out and the cumulative impact can be extremely oppressive.
These five main types of harms are not mutually exclusive, and a single system can exhibit more than one type of harm. In addition, each case varies in its severity. For instance, unfairly labeling someone as a criminal is a much more severe harm than mislabeling an image. It's important, however, to remember that even relatively non-severe harms can make people feel alienated or singled out and the cumulative impact can be extremely oppressive.
✅ **Discussion**: Revisit some of the examples and see if they show different harms.
| | Allocation | Quality of service | Stereotyping | Denigration | Over- or under- representation |
@ -98,11 +138,11 @@ These five main types of harms are not mutually exclusive, and a single system c
## Detecting unfairness
There are many reasons why a given system behaves unfairly. Social biases, for example, might be reflected in the datasets used to train them. For example, hiring unfairness might have been exacerbated by over reliance on historical data. By using the patterns in resumes submitted to the company over a 10-year period, the model determined that men were more qualified because the majority of resumes came from men, a reflection of past male dominance across the tech industry.
There are many reasons why a given system behaves unfairly. Social biases, for example, might be reflected in the datasets used to train them. For example, hiring unfairness might have been exacerbated by over reliance on historical data. By using the patterns in resumes submitted to the company over a 10-year period, the model determined that men were more qualified because many resumes came from men, a reflection of past male dominance across the tech industry.
Inadequate data about a certain group of people can be the reason for unfairness. For example, image classifiers a have higher rate of error for images of dark-skinned people because darker skin tones were underrepresented in the data.
Inadequate data about a certain group of people can be the reason for unfairness. For example, image classifiers have a higher rate of error for images of dark-skinned people because darker skin tones were underrepresented in the data.
Wrong assumptions made during development cause unfairness too. For example, a facial analysis system intended to predict who is going to commit a crime based on images of people’s faces can lead to damaging assumptions. This could lead to substantial harms for people who are misclassified.
Wrong assumptions made during development cause unfairness too. For example, a facial analysis system intended to predict who is going to commit a crime based on images of people’s faces can lead to damaging assumptions. This could lead to substantial harm for people who are misclassified.
In this lesson you learned about Fairlearn, an "open-source, community-driven project to help data scientists improve fairness of AI systems." For this assignment, explore one of Fairlearn's [notebooks](https://fairlearn.org/v0.6.2/auto_examples/index.html) and report your findings in a paper or presentation.
In this lesson you learned about the Responsible AI Toolbox, an "open-source, community-driven project to help data scientists to analyze and improve AI systems." For this assignment, explore one of RAI Toolbox's [notebooks](https://github.com/microsoft/responsible-ai-toolbox/blob/main/notebooks/responsibleaidashboard/getting-started.ipynb) and report your findings in a paper or presentation.
[](https://youtu.be/4NGM0U2ZSHU "ML for beginners - Techniques of Machine Learning")
> 🎥 Click the image above for a short video working through this lesson.
## Introduction
On a high level, the craft of creating machine learning (ML) processes is comprised of a number of steps:
@ -21,9 +21,9 @@ In this lesson, you will learn how to:
## Installations and configurations
[](https://youtu.be/yyQM70vi7V8 "Setup Python with Visual Studio Code")
[](https://youtu.be/-DfeD2k2Kj0 "ML for beginners -Setup your tools ready to build Machine Learning models")
> 🎥 Click the image above for a video: using Python within VS Code.
> 🎥 Click the image above for a short video working through configuring your computer for ML.
1. **Install Python**. Ensure that [Python](https://www.python.org/downloads/) is installed on your computer. You will use Python for many data science and machine learning tasks. Most computer systems already include a Python installation. There are useful [Python Coding Packs](https://code.visualstudio.com/learn/educators/installers?WT.mc_id=academic-77952-leestott) available as well, to ease the setup for some users.
@ -32,6 +32,10 @@ In this lesson, you will learn how to:
2. **Install Visual Studio Code**. Make sure you have Visual Studio Code installed on your computer. Follow these instructions to [install Visual Studio Code](https://code.visualstudio.com/) for the basic installation. You are going to use Python in Visual Studio Code in this course, so you might want to brush up on how to [configure Visual Studio Code](https://docs.microsoft.com/learn/modules/python-install-vscode?WT.mc_id=academic-77952-leestott) for Python development.
> Get comfortable with Python by working through this collection of [Learn modules](https://docs.microsoft.com/users/jenlooper-2911/collections/mp1pagggd5qrq7?WT.mc_id=academic-77952-leestott)
>
> [](https://youtu.be/yyQM70vi7V8 "Setup Python with Visual Studio Code")
>
> 🎥 Click the image above for a video: using Python within VS Code.
3. **Install Scikit-learn**, by following [these instructions](https://scikit-learn.org/stable/install.html). Since you need to ensure that you use Python 3, it's recommended that you use a virtual environment. Note, if you are installing this library on a M1 Mac, there are special instructions on the page linked above.
@ -43,6 +47,10 @@ You are going to use **notebooks** to develop your Python code and create machin
Notebooks are an interactive environment that allow the developer to both code and add notes and write documentation around the code which is quite helpful for experimental or research-oriented projects.
[](https://youtu.be/7E-jC8FLA2E "ML for beginners - Set up Jupyter Notebooks to start building regression models")
> 🎥 Click the image above for a short video working through this exercise.
### Exercise - work with a notebook
In this folder, you will find the file _notebook.ipynb_.
@ -84,6 +92,11 @@ Scikit-learn makes it straightforward to build models and evaluate them for use.
> This tutorial was inspired by the [linear regression example](https://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html#sphx-glr-auto-examples-linear-model-plot-ols-py) on Scikit-learn's web site.
[](https://youtu.be/2xkXL5EUpS0 "ML for beginners - Your First Linear Regression Project in Python")
> 🎥 Click the image above for a short video working through this exercise.
In the _notebook.ipynb_ file associated to this lesson, clear out all the cells by pressing the 'trash can' icon.
In this section, you will work with a small dataset about diabetes that is built into Scikit-learn for learning purposes. Imagine that you wanted to test a treatment for diabetic patients. Machine Learning models might help you determine which patients would respond better to the treatment, based on combinations of variables. Even a very basic regression model, when visualized, might show information about variables that would help you organize your theoretical clinical trials.
@ -149,10 +162,11 @@ In a new code cell, load the diabetes dataset by calling `load_diabetes()`. The
✅ Think a bit about the relationship between the data and the regression target. Linear regression predicts relationships between feature X and target variable y. Can you find the [target](https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset) for the diabetes dataset in the documentation? What is this dataset demonstrating, given that target?
2. Next, select a portion of this dataset to plot by arranging it into a new array using numpy's `newaxis` function. We are going to use linear regression to generate a line between values in this data, according to a pattern it determines.
2. Next, select a portion of this dataset to plot by selecting the 3rd column of the dataset. You can do this by using the `:` operator to select all rows, and then selecting the 3rd column using the index (2). You can also reshape the data to be a 2D array - as required for plotting - by using `reshape(n_rows, n_columns)`. If one of the parameter is -1, the corresponding dimension is calculated automatically.
```python
X = X[:, np.newaxis, 2]
X = X[:, 2]
X = X.reshape((-1,1))
```
✅ At any time, print out the data to check its shape.
@ -198,7 +212,7 @@ Congratulations, you built your first linear regression model, created a predict
---
## 🚀Challenge
Plot a different variable from this dataset. Hint: edit this line: `X = X[:, np.newaxis, 2]`. Given this dataset's target, what are you able to discover about the progression of diabetes as a disease?
Plot a different variable from this dataset. Hint: edit this line: `X = X[:,2]`. Given this dataset's target, what are you able to discover about the progression of diabetes as a disease?
@ -17,16 +17,16 @@ In this lesson, you will learn:
- How to prepare your data for model-building.
- How to use Matplotlib for data visualization.
[](https://youtu.be/11AnOn_OAcE "Preparing and Visualizing data video - Click to Watch!")
> 🎥 Click the image above for a video covering key aspects of this lesson
## Asking the right question of your data
The question you need answered will determine what type of ML algorithms you will leverage. And the quality of the answer you get back will be heavily dependent on the nature of your data.
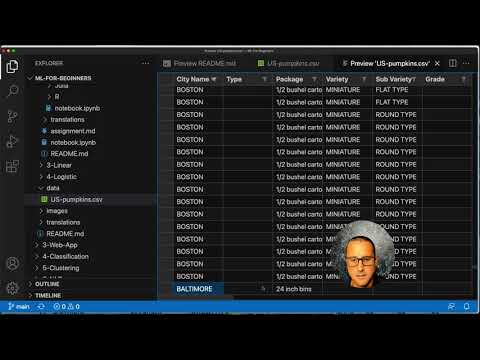
Take a look at the [data](https://github.com/microsoft/ML-For-Beginners/blob/main/2-Regression/data/US-pumpkins.csv) provided for this lesson. You can open this .csv file in VS Code. A quick skim immediately shows that there are blanks and a mix of strings and numeric data. There's also a strange column called 'Package' where the data is a mix between 'sacks', 'bins' and other values. The data, in fact, is a bit of a mess.
[](https://youtu.be/5qGjczWTrDQ "ML for beginners - How to Analyze and Clean a Dataset")
> 🎥 Click the image above for a short video working through preparing the data for this lesson.
In fact, it is not very common to be gifted a dataset that is completely ready to use to create a ML model out of the box. In this lesson, you will learn how to prepare a raw dataset using standard Python libraries. You will also learn various techniques to visualize the data.
## Case study: 'the pumpkin market'
@ -73,11 +73,11 @@ Open the _notebook.ipynb_ file in Visual Studio Code and import the spreadsheet
There is missing data, but maybe it won't matter for the task at hand.
1. To make your dataframe easier to work with, drop several of its columns, using `drop()`, keeping only the columns you need:
1. To make your dataframe easier to work with, select only the columns you need, using the `loc` function which extracts from the original dataframe a group of rows (passed as first parameter) and columns (passed as second parameter). The expression `:` in the case below means "all rows".
@ -143,6 +143,10 @@ Now, you can analyze the pricing per unit based on their bushel measurement. If
Part of the data scientist's role is to demonstrate the quality and nature of the data they are working with. To do this, they often create interesting visualizations, or plots, graphs, and charts, showing different aspects of data. In this way, they are able to visually show relationships and gaps that are otherwise hard to uncover.
[](https://youtu.be/SbUkxH6IJo0 "ML for beginners - How to Visualize Data with Matplotlib")
> 🎥 Click the image above for a short video working through visualizing the data for this lesson.
Visualizations can also help determine the machine learning technique most appropriate for the data. A scatterplot that seems to follow a line, for example, indicates that the data is a good candidate for a linear regression exercise.
One data visualization library that works well in Jupyter notebooks is [Matplotlib](https://matplotlib.org/) (which you also saw in the previous lesson).
@ -13,6 +13,10 @@ Now you are ready to dive deeper into regression for ML. While visualization all
In this lesson, you will learn more about two types of regression: _basic linear regression_ and _polynomial regression_, along with some of the math underlying these techniques. Those models will allow us to predict pumpkin prices depending on different input data.
[](https://youtu.be/CRxFT8oTDMg "ML for beginners - Understanding Linear Regression")
> 🎥 Click the image above for a short video overview of linear regression.
> Throughout this curriculum, we assume minimal knowledge of math, and seek to make it accessible for students coming from other fields, so watch for notes, 🧮 callouts, diagrams, and other learning tools to aid in comprehension.
### Prerequisite
@ -95,6 +99,10 @@ Now that you have an understanding of the math behind linear regression, let's c
## Looking for Correlation
[](https://youtu.be/uoRq-lW2eQo "ML for beginners - Looking for Correlation: The Key to Linear Regression")
> 🎥 Click the image above for a short video overview of correlation.
From the previous lesson you have probably seen that the average price for different months looks like this:
<imgalt="Average price by month"src="../2-Data/images/barchart.png"width="50%"/>
@ -151,6 +159,10 @@ Another approach would be to fill those empty values with mean values from the c
## Simple Linear Regression
[](https://youtu.be/e4c_UP2fSjg "ML for beginners - Linear and Polynomial Regression using Scikit-learn")
> 🎥 Click the image above for a short video overview of linear and polynomial regression.
To train our Linear Regression model, we will use the **Scikit-learn** library.
Another type of Linear Regression is Polynomial Regression. While sometimes there's a linear relationship between variables - the bigger the pumpkin in volume, the higher the price - sometimes these relationships can't be plotted as a plane or straight line.
@ -236,7 +247,7 @@ pipeline.fit(X_train,y_train)
Using `PolynomialFeatures(2)` means that we will include all second-degree polynomials from the input data. In our case it will just mean `DayOfYear`<sup>2</sup>, but given two input variables X and Y, this will add X<sup>2</sup>, XY and Y<sup>2</sup>. We may also use higher degree polynomials if we want.
Pipelines can be used in the same manner as the original `LinearRegression` object, i.e. we can `fit` the pipeline, and then use `predict` to get the prediction results. Here is the graph showing test data, and the approximation curve:
Using Polynomial Regression, we can get slightly lower MSE and higher determination, but not significantly. We need to take into account other features!
@ -249,6 +260,10 @@ Using Polynomial Regression, we can get slightly lower MSE and higher determinat
In the ideal world, we want to be able to predict prices for different pumpkin varieties using the same model. However, the `Variety` column is somewhat different from columns like `Month`, because it contains non-numeric values. Such columns are called **categorical**.
[](https://youtu.be/DYGliioIAE0 "ML for beginners - Categorical Feature Predictions with Linear Regression")
> 🎥 Click the image above for a short video overview of using categorical features.
Here you can see how average price depends on variety:
<imgalt="Average price by variety"src="images/price-by-variety.png"width="50%"/>
> ### [This lesson is available in R!](./solution/R/lesson_4-R.ipynb)
@ -16,6 +16,7 @@ In this lesson, you will learn:
- Techniques for logistic regression
✅ Deepen your understanding of working with this type of regression in this [Learn module](https://docs.microsoft.com/learn/modules/train-evaluate-classification-models?WT.mc_id=academic-77952-leestott)
## Prerequisite
Having worked with the pumpkin data, we are now familiar enough with it to realize that there's one binary category that we can work with: `Color`.
@ -26,20 +27,25 @@ Let's build a logistic regression model to predict that, given some variables, _
## Define the question
For our purposes, we will express this as a binary: 'Orange' or 'Not Orange'. There is also a 'striped' category in our dataset but there are few instances of it, so we will not use it. It disappears once we remove null values from the dataset, anyway.
For our purposes, we will express this as a binary: 'White' or 'Not White'. There is also a 'striped' category in our dataset but there are few instances of it, so we will not use it. It disappears once we remove null values from the dataset, anyway.
> 🎃 Fun fact, we sometimes call white pumpkins 'ghost' pumpkins. They aren't very easy to carve, so they aren't as popular as the orange ones but they are cool looking!
> 🎃 Fun fact, we sometimes call white pumpkins 'ghost' pumpkins. They aren't very easy to carve, so they aren't as popular as the orange ones but they are cool looking! So we could also reformulate our question as: 'Ghost' or 'Not Ghost'. 👻
## About logistic regression
Logistic regression differs from linear regression, which you learned about previously, in a few important ways.
[](https://youtu.be/MmZS2otPrQ8 "ML for beginners - Logistic Regression for classification of data")
> 🎥 Click the image above for a short video overview of logistic regression.
### Binary classification
Logistic regression does not offer the same features as linear regression. The former offers a prediction about a binary category ("orange or not orange") whereas the latter is capable of predicting continual values, for example given the origin of a pumpkin and the time of harvest, _how much its price will rise_.
> Infographic by [Dasani Madipalli](https://twitter.com/dasani_decoded)
### Other classifications
There are other types of logistic regression, including multinomial and ordinal:
@ -47,12 +53,7 @@ There are other types of logistic regression, including multinomial and ordinal:
- **Multinomial**, which involves having more than one category - "Orange, White, and Striped".
- **Ordinal**, which involves ordered categories, useful if we wanted to order our outcomes logically, like our pumpkins that are ordered by a finite number of sizes (mini,sm,med,lg,xl,xxl).

> Infographic by [Dasani Madipalli](https://twitter.com/dasani_decoded)
### It's still linear
Even though this type of Regression is all about 'category predictions', it still works best when there is a clear linear relationship between the dependent variable (color) and the other independent variables (the rest of the dataset, like city name and size). It's good to get an idea of whether there is any linearity dividing these variables or not.

### Variables DO NOT have to correlate
@ -62,6 +63,10 @@ Remember how linear regression worked better with more correlated variables? Log
Logistic regression will give more accurate results if you use more data; our small dataset is not optimal for this task, so keep that in mind.
[](https://youtu.be/B2X4H9vcXTs "ML for beginners - Data Analysis and Preparation for Logistic Regression")
> 🎥 Click the image above for a short video overview of preparing data for linear regression
✅ Think about the types of data that would lend themselves well to logistic regression
## Exercise - tidy the data
@ -71,78 +76,146 @@ First, clean the data a bit, dropping null values and selecting only some of the
By now you have loaded up the [starter notebook](./notebook.ipynb) with pumpkin data once again and cleaned it so as to preserve a dataset containing a few variables, including `Color`. Let's visualize the dataframe in the notebook using a different library: [Seaborn](https://seaborn.pydata.org/index.html), which is built on Matplotlib which we used earlier.
Seaborn offers some neat ways to visualize your data. For example, you can compare distributions of the data for each point in a side-by-side grid.
Seaborn offers some neat ways to visualize your data. For example, you can compare distributions of the data for each `Variety` and `Color` in a categorical plot.
1. Create such a grid by instantiating a `PairGrid`, using our pumpkin data `new_pumpkins`, followed by calling `map()`:
1. Create such a plot by using the `catplot` function, using our pumpkin data `pumpkins`, and specifying a color mapping for each pumpkin category (orange or white):

By observing data side-by-side, you can see how the Color data relates to the other columns.
By observing the data, you can see how the Color data relates to Variety.
✅ Given this scatterplot grid, what are some interesting explorations you can envision?
✅ Given this categorical plot, what are some interesting explorations you can envision?
### Use a swarm plot
### Data pre-processing: feature and label encoding
Our pumpkins dataset contains string values for all its columns. Working with categorical data is intuitive for humans but not for machines. Machine learning algorithms work well with numbers. That's why encoding is a very important step in the data pre-processing phase, since it enables us to turn categorical data into numerical data, without losing any information. Good encoding leads to building a good model.
Since Color is a binary category (Orange or Not), it's called 'categorical data' and needs 'a more [specialized approach](https://seaborn.pydata.org/tutorial/categorical.html?highlight=bar) to visualization'. There are other ways to visualize the relationship of this category with other variables.
For feature encoding there are two main types of encoders:
You can visualize variables side-by-side with Seaborn plots.
1. Ordinal encoder: it suits well for ordinal variables, which are categorical variables where their data follows a logical ordering, like the `Item Size` column in our dataset. It creates a mapping such that each category is represented by a number, which is the order of the category in the column.
1. Try a 'swarm' plot to show the distribution of values:
2. Categorical encoder: it suits well for nominal variables, which are categorical variables where their data does not follow a logical ordering, like all the features different from `Item Size` in our dataset. It is a one-hot encoding, which means that each category is represented by a binary column: the encoded variable is equal to 1 if the pumpkin belongs to that Variety and 0 otherwise.
On the other hand, to encode the label, we use the scikit-learn `LabelEncoder` class, which is a utility class to help normalize labels such that they contain only values between 0 and n_classes-1 (here, 0 and 1).
✅ What are the advantages of using an ordinal encoder for the `Item Size` column?
A 'violin' type plot is useful as you can easily visualize the way that data in the two categories is distributed. Violin plots don't work so well with smaller datasets as the distribution is displayed more 'smoothly'.
### Analyse relationships between variables
1. As parameters `x=Color`, `kind="violin"` and call `catplot()`:
Now that we have pre-processed our data, we can analyse the relationships between the features and the label to grasp an idea of how well the model will be able to predict the label given the features.
The best way to perform this kind of analysis is plotting the data. We'll be using again the Seaborn `catplot` function, to visualize the relationships between `Item Size`, `Variety` and `Color` in a categorical plot. To better plot the data we'll be using the encoded `Item Size` column and the unencoded `Variety` column.

### Use a swarm plot
Since Color is a binary category (White or Not), it needs 'a [specialized approach](https://seaborn.pydata.org/tutorial/categorical.html?highlight=bar) to visualization'. There are other ways to visualize the relationship of this category with other variables.
You can visualize variables side-by-side with Seaborn plots.
1. Try a 'swarm' plot to show the distribution of values:
✅ Try creating this plot, and other Seaborn plots, using other variables.
**Watch Out**: the code above might generate a warning, since seaborn fails to represent such amount of datapoints into a swam plot. A possible solution is decreasing the size of the marker, by using the 'size' parameter. However, be aware that this affects the readability of the plot.
Now that we have an idea of the relationship between the binary categories of color and the larger group of sizes, let's explore logistic regression to determine a given pumpkin's likely color.
> **🧮 Show Me The Math**
>
> Remember how linear regression often used ordinary least squares to arrive at a value? Logistic regression relies on the concept of 'maximum likelihood' using [sigmoid functions](https://wikipedia.org/wiki/Sigmoid_function). A 'Sigmoid Function' on a plot looks like an 'S' shape. It takes a value and maps it to somewhere between 0 and 1. Its curve is also called a 'logistic curve'. Its formula looks like this:
> Logistic regression relies on the concept of 'maximum likelihood' using [sigmoid functions](https://wikipedia.org/wiki/Sigmoid_function). A 'Sigmoid Function' on a plot looks like an 'S' shape. It takes a value and maps it to somewhere between 0 and 1. Its curve is also called a 'logistic curve'. Its formula looks like this:
>
> 
>
@ -152,54 +225,56 @@ Now that we have an idea of the relationship between the binary categories of co
Building a model to find these binary classification is surprisingly straightforward in Scikit-learn.
[](https://youtu.be/MmZS2otPrQ8 "ML for beginners - Logistic Regression for classification of data")
> 🎥 Click the image above for a short video overview of building a linear regression model
1. Select the variables you want to use in your classification model and split the training and test sets calling `train_test_split()`:
```python
from sklearn.model_selection import train_test_split
@ -219,7 +294,7 @@ While you can get a scoreboard report [terms](https://scikit-learn.org/stable/mo
```output
array([[162, 4],
[ 33, 0]])
[ 11, 22]])
```
In Scikit-learn, confusion matrices Rows (axis 0) are actual labels and columns (axis 1) are predicted labels.
@ -229,22 +304,22 @@ In Scikit-learn, confusion matrices Rows (axis 0) are actual labels and columns
| 0 | TN | FP |
| 1 | FN | TP |
What's going on here? Let's say our model is asked to classify pumpkins between two binary categories, category 'orange' and category 'not-orange'.
What's going on here? Let's say our model is asked to classify pumpkins between two binary categories, category 'white' and category 'not-white'.
- If your model predicts a pumpkin as not orange and it belongs to category 'not-orange' in reality we call it a true negative, shown by the top left number.
- If your model predicts a pumpkin as orange and it belongs to category 'not-orange' in reality we call it a false negative, shown by the bottom left number.
- If your model predicts a pumpkin as not orange and it belongs to category 'orange' in reality we call it a false positive, shown by the top right number.
- If your model predicts a pumpkin as orange and it belongs to category 'orange' in reality we call it a true positive, shown by the bottom right number.
- If your model predicts a pumpkin as not white and it belongs to category 'not-white' in reality we call it a true negative, shown by the top left number.
- If your model predicts a pumpkin as white and it belongs to category 'not-white' in reality we call it a false negative, shown by the bottom left number.
- If your model predicts a pumpkin as not white and it belongs to category 'white' in reality we call it a false positive, shown by the top right number.
- If your model predicts a pumpkin as white and it belongs to category 'white' in reality we call it a true positive, shown by the bottom right number.
As you might have guessed it's preferable to have a larger number of true positives and true negatives and a lower number of false positives and false negatives, which implies that the model performs better.
How does the confusion matrix relate to precision and recall? Remember, the classification report printed above showed precision (0.83) and recall (0.98).
How does the confusion matrix relate to precision and recall? Remember, the classification report printed above showed precision (0.85) and recall (0.67).
✅ Q: According to the confusion matrix, how did the model do? A: Not too bad; there are a good number of true negatives but also several false negatives.
✅ Q: According to the confusion matrix, how did the model do? A: Not bad; there are a good number of true negatives but also a few false negatives.
Let's revisit the terms we saw earlier with the help of the confusion matrix's mapping of TP/TN and FP/FN:
@ -266,22 +341,33 @@ Let's revisit the terms we saw earlier with the help of the confusion matrix's m
## Visualize the ROC curve of this model
This is not a bad model; its accuracy is in the 80% range so ideally you could use it to predict the color of a pumpkin given a set of variables.
[](https://youtu.be/GApO575jTA0 "ML for beginners - Analyzing Logistic Regression Performance with ROC Curves")
Let's do one more visualization to see the so-called 'ROC' score:
> 🎥 Click the image above for a short video overview of ROC curves
Let's do one more visualization to see the so-called 'ROC' curve:
```python
from sklearn.metrics import roc_curve, roc_auc_score
Using Seaborn again, plot the model's [Receiving Operating Characteristic](https://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html?highlight=roc) or ROC. ROC curves are often used to get a view of the output of a classifier in terms of its true vs. false positives. "ROC curves typically feature true positive rate on the Y axis, and false positive rate on the X axis." Thus, the steepness of the curve and the space between the midpoint line and the curve matter: you want a curve that quickly heads up and over the line. In our case, there are false positives to start with, and then the line heads up and over properly:

Using Matplotlib, plot the model's [Receiving Operating Characteristic](https://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html?highlight=roc) or ROC. ROC curves are often used to get a view of the output of a classifier in terms of its true vs. false positives. "ROC curves typically feature true positive rate on the Y axis, and false positive rate on the X axis." Thus, the steepness of the curve and the space between the midpoint line and the curve matter: you want a curve that quickly heads up and over the line. In our case, there are false positives to start with, and then the line heads up and over properly:

Finally, use Scikit-learn's [`roc_auc_score` API](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html?highlight=roc_auc#sklearn.metrics.roc_auc_score) to compute the actual 'Area Under the Curve' (AUC):
@ -289,7 +375,7 @@ Finally, use Scikit-learn's [`roc_auc_score` API](https://scikit-learn.org/stabl
auc = roc_auc_score(y_test,y_scores[:,1])
print(auc)
```
The result is `0.6976998904709748`. Given that the AUC ranges from 0 to 1, you want a big score, since a model that is 100% correct in its predictions will have an AUC of 1; in this case, the model is _pretty good_.
The result is `0.9749908725812341`. Given that the AUC ranges from 0 to 1, you want a big score, since a model that is 100% correct in its predictions will have an AUC of 1; in this case, the model is _pretty good_.
In future lessons on classifications, you will learn how to iterate to improve your model's scores. But for now, congratulations! You've completed these regression lessons!
@ -15,6 +15,10 @@ The lessons in this section cover types of regression in the context of machine
In this series of lessons, you'll discover the differences between linear and logistic regression, and when you should prefer one over the other.
[](https://youtu.be/XA3OaoW86R8 "ML for beginners - Introduction to Regression models for Machine Learning")
> 🎥 Click the image above for a short video introducing regression models.
In this group of lessons, you will get set up to begin machine learning tasks, including configuring Visual Studio Code to manage notebooks, the common environment for data scientists. You will discover Scikit-learn, a library for machine learning, and you will build your first models, focusing on Regression models in this chapter.
> There are useful low-code tools that can help you learn about working with regression models. Try [Azure ML for this task](https://docs.microsoft.com/learn/modules/create-regression-model-azure-machine-learning-designer/?WT.mc_id=academic-77952-leestott)
@ -44,6 +44,14 @@ Travel with us around the world as we apply these classic techniques to data fro
---
## Video walkthroughs
Some of the lessons are available as short form video. You can find all these in-line in the lessons, or on the [ML for Beginners playlist on the Microsoft Developer YouTube channel](https://aka.ms/ml-beginners-videos) by clicking the image below.
[](https://aka.ms/ml-beginners-videos)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}