[](https://youtu.be/11AnOn_OAcE "Preparing and Visualizing data video - Click to Watch!")
> 🎥 Click the image above for a video covering key aspects of this lesson
## Asking the right question of your data
The question you need answered will determine what type of ML algorithms you will leverage. And the quality of the answer you get back will be heavily dependent on the nature of your data.
@ -37,7 +41,7 @@ This data is in the public domain. It can be downloaded in many separate files,
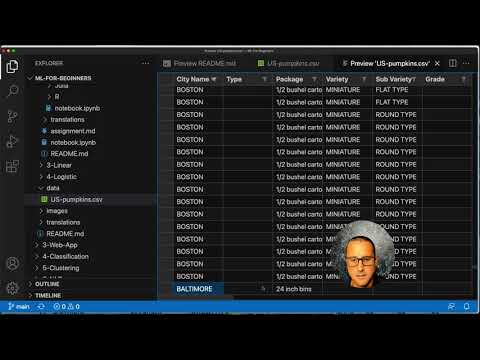
What do you notice about this data? You already saw that there is a mix of strings, numbers, blanks and strange values that you need to make sense of.
What question can you ask of this data, using a Regression technique? What about "Predict the price of a pumpkin for sale during a given month". Looking again at the data, there are some changes you need to make to create the data structure necessary for the task.
What question can you ask of this data, using a Regression technique? What about "Predict the price of a pumpkin for sale during a given month". Looking again at the data, there are some changes you need to make to create the data structure necessary for the task.
## Exercise - analyze the pumpkin data
Let's use [Pandas](https://pandas.pydata.org/), (the name stands for `Python Data Analysis`) a tool very useful for shaping data, to analyze and prepare this pumpkin data.
@ -69,7 +73,7 @@ Open the _notebook.ipynb_ file in Visual Studio Code and import the spreadsheet
There is missing data, but maybe it won't matter for the task at hand.
1. To make your dataframe easier to work with, drop several of its columns, using `drop()`, keeping only the columns you need:
1. To make your dataframe easier to work with, drop several of its columns, using `drop()`, keeping only the columns you need:
@ -137,7 +141,7 @@ Now, you can analyze the pricing per unit based on their bushel measurement. If
## Visualization Strategies
Part of the data scientist's role is to demonstrate the quality and nature of the data they are working with. To do this, they often create interesting visualizations, or plots, graphs, and charts, showing different aspects of data. In this way, they are able to visually show relationships and gaps that are otherwise hard to uncover.
Part of the data scientist's role is to demonstrate the quality and nature of the data they are working with. To do this, they often create interesting visualizations, or plots, graphs, and charts, showing different aspects of data. In this way, they are able to visually show relationships and gaps that are otherwise hard to uncover.
Visualizations can also help determine the machine learning technique most appropriate for the data. A scatterplot that seems to follow a line, for example, indicates that the data is a good candidate for a linear regression exercise.