|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-audio.md | 4 weeks ago | |
| pi-microphone.md | 4 weeks ago | |
| pi-speech-to-text.md | 4 weeks ago | |
| virtual-device-audio.md | 4 weeks ago | |
| virtual-device-microphone.md | 4 weeks ago | |
| virtual-device-speech-to-text.md | 4 weeks ago | |
| wio-terminal-audio.md | 4 weeks ago | |
| wio-terminal-microphone.md | 4 weeks ago | |
| wio-terminal-speech-to-text.md | 4 weeks ago | |
README.md
آئی او ٹی ڈیوائس کے ساتھ تقریر کو پہچاننا
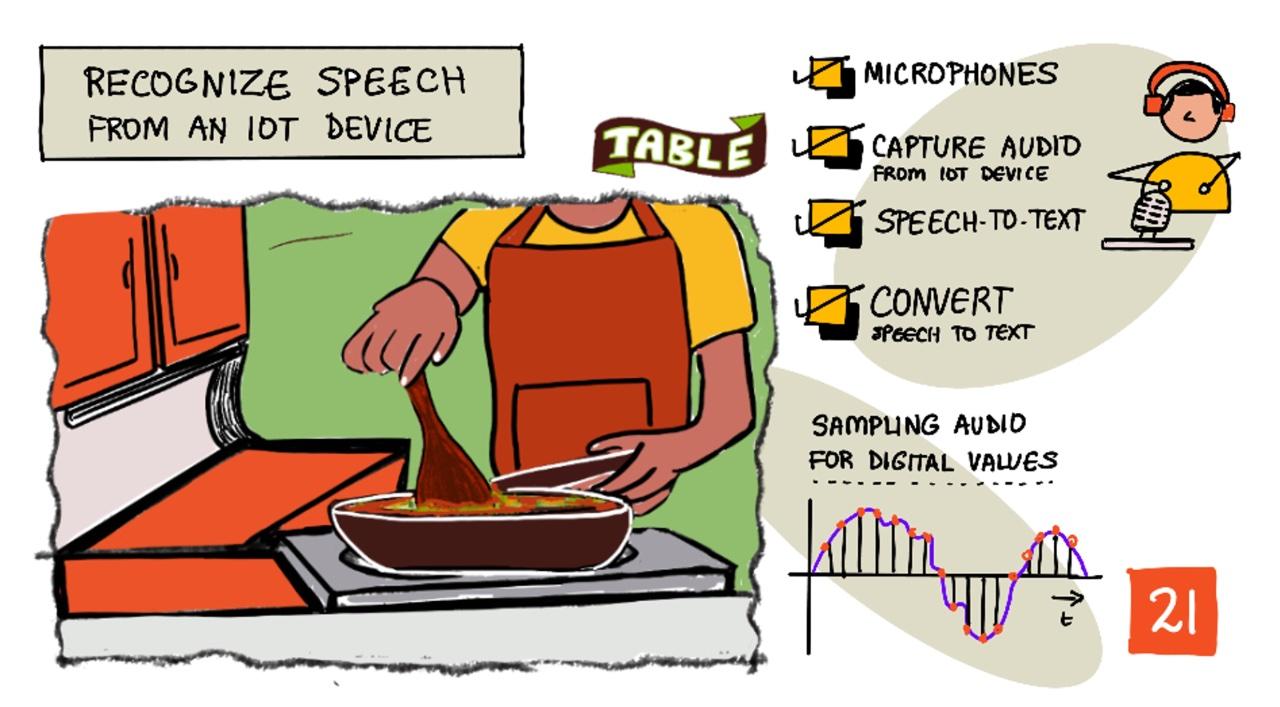
خاکہ نیتیا نرسمہن کی طرف سے۔ بڑی تصویر دیکھنے کے لیے تصویر پر کلک کریں۔
یہ ویڈیو Azure Speech Service کا ایک جائزہ پیش کرتی ہے، جو اس سبق میں شامل کیا جائے گا:

🎥 ویڈیو دیکھنے کے لیے اوپر دی گئی تصویر پر کلک کریں
لیکچر سے پہلے کا کوئز
تعارف
'الیکسا، 12 منٹ کا ٹائمر سیٹ کرو'
'الیکسا، ٹائمر کی حالت بتاؤ'
'الیکسا، 8 منٹ کا ٹائمر سیٹ کرو جس کا نام بھاپ والے بروکلی ہو'
سمارٹ ڈیوائسز ہماری زندگیوں میں تیزی سے عام ہو رہی ہیں۔ نہ صرف سمارٹ اسپیکرز جیسے ہوم پوڈز، ایکوز اور گوگل ہومز کی صورت میں، بلکہ یہ ہمارے فونز، گھڑیوں، حتیٰ کہ لائٹ فٹنگز اور تھرموسٹیٹس میں بھی شامل ہو رہی ہیں۔
💁 میرے گھر میں کم از کم 19 ایسے ڈیوائسز ہیں جن میں وائس اسسٹنٹس موجود ہیں، اور یہ صرف وہ ہیں جن کے بارے میں مجھے معلوم ہے!
وائس کنٹرول ان لوگوں کے لیے رسائی کو بڑھاتا ہے جن کی حرکت محدود ہے۔ چاہے یہ کوئی مستقل معذوری ہو جیسے بازوؤں کے بغیر پیدا ہونا، یا عارضی معذوری جیسے بازو ٹوٹ جانا، یا ہاتھوں میں خریداری یا بچوں کا سامان ہونے کی وجہ سے مصروف ہونا، ہماری آواز کے ذریعے گھروں کو کنٹرول کرنے کی صلاحیت ایک نئی دنیا کی رسائی کھولتی ہے۔ 'ارے سری، میرا گیراج بند کرو' چلانا، جبکہ آپ ایک بچے کو سنبھال رہے ہوں اور ایک شرارتی بچے سے نمٹ رہے ہوں، زندگی میں ایک چھوٹا لیکن مؤثر بہتری ہو سکتی ہے۔
وائس اسسٹنٹس کے سب سے مشہور استعمالات میں سے ایک ٹائمر سیٹ کرنا ہے، خاص طور پر کچن ٹائمر۔ صرف اپنی آواز سے متعدد ٹائمر سیٹ کرنے کی صلاحیت کچن میں بہت مددگار ثابت ہوتی ہے - آٹے کو گوندھنے، سوپ کو ہلانے، یا اپنے ہاتھوں سے ڈمپلنگ فلنگ صاف کرنے کی ضرورت نہیں۔
اس سبق میں آپ آئی او ٹی ڈیوائسز میں وائس ریکگنیشن شامل کرنے کے بارے میں سیکھیں گے۔ آپ مائیکروفونز کو سینسرز کے طور پر سمجھیں گے، آئی او ٹی ڈیوائس سے منسلک مائیکروفون سے آڈیو کیپچر کرنے کا طریقہ، اور سنا گیا مواد ٹیکسٹ میں تبدیل کرنے کے لیے AI کا استعمال کریں گے۔ اس پروجیکٹ کے باقی حصے میں آپ ایک سمارٹ کچن ٹائمر بنائیں گے، جو آپ کی آواز کے ذریعے مختلف زبانوں میں ٹائمر سیٹ کرنے کے قابل ہوگا۔
اس سبق میں ہم درج ذیل موضوعات کا احاطہ کریں گے:
- مائیکروفونز
- اپنے آئی او ٹی ڈیوائس سے آڈیو کیپچر کریں
- تقریر کو متن میں تبدیل کریں
- تقریر کو متن میں تبدیل کرنے کا عمل
مائیکروفونز
مائیکروفونز اینالاگ سینسرز ہیں جو آواز کی لہروں کو برقی سگنلز میں تبدیل کرتے ہیں۔ ہوا میں ارتعاش مائیکروفون کے اجزاء کو معمولی مقدار میں حرکت دیتا ہے، اور یہ معمولی تبدیلیاں برقی سگنلز میں تبدیلی کا باعث بنتی ہیں۔ ان تبدیلیوں کو بڑھا کر برقی آؤٹ پٹ پیدا کیا جاتا ہے۔
مائیکروفون کی اقسام
مائیکروفونز مختلف اقسام میں دستیاب ہیں:
-
ڈائنامک - ڈائنامک مائیکروفونز میں ایک مقناطیس ہوتا ہے جو ایک حرکت پذیر ڈایافرام سے جڑا ہوتا ہے، جو تار کے کوائل میں حرکت کرتے ہوئے برقی کرنٹ پیدا کرتا ہے۔ یہ زیادہ تر لاؤڈ اسپیکرز کے برعکس ہے، جو برقی کرنٹ کو مقناطیس کو حرکت دینے کے لیے استعمال کرتے ہیں، جو ڈایافرام کو حرکت دے کر آواز پیدا کرتا ہے۔ اس کا مطلب ہے کہ اسپیکرز کو ڈائنامک مائیکروفونز کے طور پر استعمال کیا جا سکتا ہے، اور ڈائنامک مائیکروفونز کو اسپیکرز کے طور پر استعمال کیا جا سکتا ہے۔ انٹرکام جیسے آلات میں، جہاں صارف یا تو سن رہا ہوتا ہے یا بول رہا ہوتا ہے، ایک ہی ڈیوائس اسپیکر اور مائیکروفون دونوں کے طور پر کام کر سکتی ہے۔
ڈائنامک مائیکروفونز کو کام کرنے کے لیے بجلی کی ضرورت نہیں ہوتی، برقی سگنل مکمل طور پر مائیکروفون سے پیدا ہوتا ہے۔

-
ربن - ربن مائیکروفونز ڈائنامک مائیکروفونز سے ملتے جلتے ہیں، سوائے اس کے کہ ان میں ڈایافرام کی جگہ دھات کا ربن ہوتا ہے۔ یہ ربن ایک مقناطیسی میدان میں حرکت کرتے ہوئے برقی کرنٹ پیدا کرتا ہے۔ ڈائنامک مائیکروفونز کی طرح، ربن مائیکروفونز کو بھی کام کرنے کے لیے بجلی کی ضرورت نہیں ہوتی۔

-
کنڈینسر - کنڈینسر مائیکروفونز میں ایک پتلا دھاتی ڈایافرام اور ایک مقررہ دھاتی بیک پلیٹ ہوتی ہے۔ ان دونوں پر بجلی لگائی جاتی ہے، اور جیسے ہی ڈایافرام حرکت کرتا ہے، پلیٹوں کے درمیان جامد چارج میں تبدیلی آتی ہے، جو سگنل پیدا کرتی ہے۔ کنڈینسر مائیکروفونز کو کام کرنے کے لیے بجلی کی ضرورت ہوتی ہے، جسے فینٹم پاور کہا جاتا ہے۔
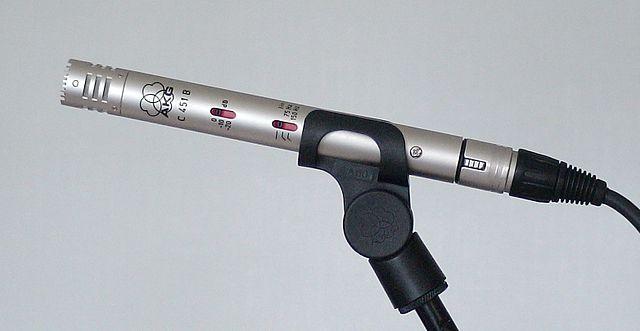
-
میمز - مائیکروالیکٹرو مکینیکل سسٹمز مائیکروفونز، یا MEMS، چپ پر موجود مائیکروفونز ہیں۔ ان میں ایک دباؤ حساس ڈایافرام ہوتا ہے جو سلیکون چپ پر کندہ ہوتا ہے، اور یہ کنڈینسر مائیکروفون کی طرح کام کرتے ہیں۔ یہ مائیکروفونز بہت چھوٹے ہو سکتے ہیں اور سرکٹری میں ضم کیے جا سکتے ہیں۔

اوپر دی گئی تصویر میں، LEFT کے لیبل والا چپ ایک MEMS مائیکروفون ہے، جس کا ڈایافرام ایک ملی میٹر سے بھی کم چوڑا ہے۔
✅ تحقیق کریں: آپ کے ارد گرد کون سے مائیکروفونز موجود ہیں - چاہے وہ آپ کے کمپیوٹر، فون، ہیڈسیٹ یا دیگر آلات میں ہوں۔ وہ کس قسم کے مائیکروفونز ہیں؟
ڈیجیٹل آڈیو
آڈیو ایک اینالاگ سگنل ہے جو بہت باریک معلومات لے کر جاتا ہے۔ اس سگنل کو ڈیجیٹل میں تبدیل کرنے کے لیے، آڈیو کو ایک سیکنڈ میں ہزاروں بار سیمپل کیا جانا ضروری ہے۔
🎓 سیمپلنگ آڈیو سگنل کو ایک ڈیجیٹل ویلیو میں تبدیل کرنے کا عمل ہے جو اس وقت سگنل کی نمائندگی کرتا ہے۔
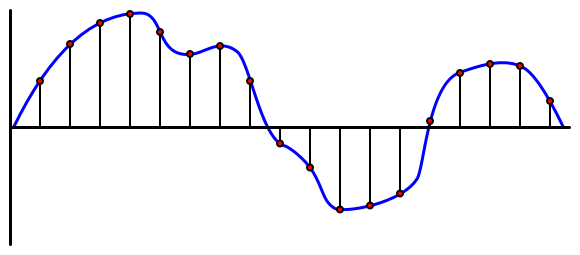
ڈیجیٹل آڈیو کو پلس کوڈ ماڈیولیشن (PCM) کے ذریعے سیمپل کیا جاتا ہے۔ PCM میں سگنل کے وولٹیج کو پڑھنا اور ایک مقررہ سائز کے مطابق اس وولٹیج کے قریب ترین ڈسکریٹ ویلیو کا انتخاب شامل ہے۔
💁 آپ PCM کو پلس وڈتھ ماڈیولیشن (PWM) کے سینسر ورژن کے طور پر سمجھ سکتے ہیں (PWM کو شروع کرنے کے پروجیکٹ کے سبق 3 میں کور کیا گیا تھا)۔ PCM اینالاگ سگنل کو ڈیجیٹل میں تبدیل کرتا ہے، جبکہ PWM ڈیجیٹل سگنل کو اینالاگ میں تبدیل کرتا ہے۔
مثال کے طور پر، زیادہ تر اسٹریمنگ میوزک سروسز 16 بٹ یا 24 بٹ آڈیو پیش کرتی ہیں۔ اس کا مطلب ہے کہ وہ وولٹیج کو ایک ویلیو میں تبدیل کرتے ہیں جو 16 بٹ انٹیجر یا 24 بٹ انٹیجر میں فٹ ہو۔ 16 بٹ آڈیو ویلیو کو -32,768 سے 32,767 کی رینج میں فٹ کرتا ہے، جبکہ 24 بٹ -8,388,608 سے 8,388,607 کی رینج میں۔ جتنے زیادہ بٹس ہوں گے، سیمپل ہمارے کانوں کے اصل سننے کے قریب ہوگا۔
💁 آپ نے 8 بٹ آڈیو کے بارے میں سنا ہوگا، جسے اکثر LoFi کہا جاتا ہے۔ یہ آڈیو صرف 8 بٹس کے ساتھ سیمپل کیا جاتا ہے، یعنی -128 سے 127۔ ابتدائی کمپیوٹر آڈیو ہارڈویئر کی حدود کی وجہ سے 8 بٹس تک محدود تھا، اس لیے یہ اکثر ریٹرو گیمنگ میں دیکھا جاتا ہے۔
یہ سیمپلز ایک سیکنڈ میں ہزاروں بار لیے جاتے ہیں، جو کہ KHz (ایک سیکنڈ میں ہزاروں ریڈنگز) میں ماپا جاتا ہے۔ اسٹریمنگ میوزک سروسز زیادہ تر آڈیو کے لیے 48KHz استعمال کرتی ہیں، لیکن کچھ 'لاس لیس' آڈیو 96KHz یا یہاں تک کہ 192KHz تک استعمال کرتی ہیں۔ سیمپل ریٹ جتنا زیادہ ہوگا، آڈیو اصل کے قریب ہوگا، ایک حد تک۔ اس بات پر بحث ہے کہ آیا انسان 48KHz سے اوپر کے فرق کو محسوس کر سکتا ہے یا نہیں۔
✅ تحقیق کریں: اگر آپ اسٹریمنگ میوزک سروس استعمال کرتے ہیں، تو یہ کون سا سیمپل ریٹ اور سائز استعمال کرتی ہے؟ اگر آپ CDs استعمال کرتے ہیں، تو CD آڈیو کا سیمپل ریٹ اور سائز کیا ہے؟
آڈیو ڈیٹا کے لیے مختلف فارمیٹس موجود ہیں۔ آپ نے شاید mp3 فائلز کے بارے میں سنا ہوگا - آڈیو ڈیٹا جو کوالٹی کھوئے بغیر چھوٹا کیا گیا ہو۔ غیر کمپریسڈ آڈیو اکثر WAV فائل کے طور پر محفوظ کیا جاتا ہے - یہ ایک فائل ہوتی ہے جس میں 44 بائٹس کی ہیڈر معلومات ہوتی ہے، اس کے بعد خام آڈیو ڈیٹا ہوتا ہے۔ ہیڈر میں سیمپل ریٹ (مثال کے طور پر 16000 برائے 16KHz)، سیمپل سائز (16 برائے 16 بٹ)، اور چینلز کی تعداد جیسی معلومات شامل ہوتی ہیں۔ ہیڈر کے بعد، WAV فائل میں خام آڈیو ڈیٹا شامل ہوتا ہے۔
🎓 چینلز اس بات کی نشاندہی کرتے ہیں کہ آڈیو کتنے مختلف آڈیو اسٹریمز پر مشتمل ہے۔ مثال کے طور پر، اسٹیریو آڈیو کے لیے بائیں اور دائیں کے ساتھ 2 چینلز ہوں گے۔ ہوم تھیٹر سسٹم کے لیے 7.1 سراؤنڈ ساؤنڈ کے لیے یہ 8 ہوں گے۔
آڈیو ڈیٹا کا سائز
آڈیو ڈیٹا نسبتاً بڑا ہوتا ہے۔ مثال کے طور پر، غیر کمپریسڈ 16 بٹ آڈیو کو 16KHz پر کیپچر کرنا (جو تقریر کو متن میں تبدیل کرنے کے ماڈل کے لیے کافی ہے)، ہر سیکنڈ کے آڈیو کے لیے 32KB ڈیٹا لیتا ہے:
- 16 بٹ کا مطلب ہے ہر سیمپل کے لیے 2 بائٹس (1 بائٹ 8 بٹس کے برابر ہے)۔
- 16KHz کا مطلب ہے ایک سیکنڈ میں 16,000 سیمپلز۔
- 16,000 x 2 بائٹس = 32,000 بائٹس فی سیکنڈ۔
یہ ایک چھوٹی مقدار لگتی ہے، لیکن اگر آپ ایک مائیکرو کنٹرولر استعمال کر رہے ہیں جس کی میموری محدود ہے، تو یہ بہت زیادہ ہو سکتی ہے۔ مثال کے طور پر، Wio Terminal میں 192KB میموری ہے، اور اس میں پروگرام کوڈ اور ویریبلز کو بھی اسٹور کرنا ہوتا ہے۔ چاہے آپ کا پروگرام کوڈ بہت چھوٹا ہو، آپ 5 سیکنڈ سے زیادہ آڈیو کیپچر نہیں کر سکتے۔
مائیکرو کنٹرولرز اضافی اسٹوریج تک رسائی حاصل کر سکتے ہیں، جیسے SD کارڈز یا فلیش میموری۔ جب آپ ایک آئی او ٹی ڈیوائس بنا رہے ہوں جو آڈیو کیپچر کرتا ہو، تو آپ کو یہ یقینی بنانا ہوگا کہ آپ کے پاس اضافی اسٹوریج موجود ہے، اور آپ کا کوڈ مائیکروفون سے کیپچر کیے گئے آڈیو کو براہ راست اس اسٹوریج پر لکھتا ہے۔ جب آپ اسے کلاؤڈ پر بھیج رہے ہوں، تو آپ کو اسٹوریج سے ویب ریکویسٹ تک آڈیو کو اسٹریم کرنا ہوگا۔ اس طرح آپ میموری ختم ہونے سے بچ سکتے ہیں، جو پورے آڈیو ڈیٹا کو ایک ساتھ میموری میں رکھنے کی کوشش سے ہو سکتا ہے۔
اپنے آئی او ٹی ڈیوائس سے آڈیو کیپچر کریں
آپ کا آئی او ٹی ڈیوائس مائیکروفون سے منسلک ہو سکتا ہے تاکہ آڈیو کیپچر کیا جا سکے، جو متن میں تبدیل کرنے کے لیے تیار ہو۔ یہ اسپیکرز سے بھی منسلک ہو سکتا ہے تاکہ آڈیو آؤٹ پٹ فراہم کیا جا سکے۔ بعد کے اسباق میں یہ آڈیو فیڈبیک دینے کے لیے استعمال ہوگا، لیکن مائیکروفون کی جانچ کے لیے اسپیکرز کو ابھی ترتیب دینا مفید ہے۔
کام - اپنے مائیکروفون اور اسپیکرز کو ترتیب دیں
اپنے آئی او ٹی ڈیوائس کے لیے مائیکروفون اور اسپیکرز کو ترتیب دینے کے لیے متعلقہ گائیڈ پر عمل کریں:
کام - آڈیو کیپچر کریں
اپنے آئی او ٹی ڈیوائس پر آڈیو کیپچر کرنے کے لیے متعلقہ گائیڈ پر عمل کریں:
تقریر کو متن میں تبدیل کریں
تقریر کو متن میں تبدیل کرنا، یا تقریر کی پہچان، AI کا استعمال کرتے ہوئے آڈیو سگنل میں موجود الفاظ کو متن میں تبدیل کرنے کا عمل ہے۔
تقریر کی پہچان کے ماڈلز
تقریر کو متن میں تبدیل کرنے کے لیے، آڈیو سگنل کے سیمپلز کو گروپ کیا جاتا ہے اور مشین لرننگ ماڈل میں فیڈ کیا جاتا ہے، جو ایک ری کرنٹ نیورل نیٹ ورک (RNN) پر مبنی ہوتا ہے۔ یہ مشین لرننگ ماڈل کی ایک قسم ہے جو پچھلے ڈیٹا کا استعمال کرتے ہوئے آنے والے ڈیٹا کے بارے میں فیصلہ کر سکتا ہے۔ مثال کے طور پر، RNN ایک آڈیو سیمپل بلاک کو 'Hel' کی آواز کے طور پر شناخت کر سکتا ہے، اور جب اسے ایک اور بلاک ملتا ہے جسے وہ 'lo' کی آواز سمجھتا ہے، تو یہ پچھلی آواز کے ساتھ اسے جوڑ سکتا ہے، 'Hello' کو ایک درست لفظ کے طور پر پہچان سکتا ہے، اور اسے نتیجہ کے طور پر منتخب کر سکتا ہے۔
مشین لرننگ ماڈلز ہمیشہ ایک ہی سائز کے ڈیٹا کو قبول کرتے ہیں۔ وہ امیج کلاسفائر جو آپ نے ایک پچھلے سبق میں بنایا تھا، تصاویر کو ایک مقررہ سائز میں تبدیل کرتا ہے اور ان پر عمل کرتا ہے۔ تقریر کے ماڈلز کے ساتھ بھی یہی ہوتا ہے، انہیں مقررہ سائز کے آڈیو چنکس پر عمل کرنا ہوتا ہے۔ تقریر کے ماڈلز کو متعدد پیشین گوئیوں کے نتائج کو یکجا کرنے کے قابل ہونا چاہیے تاکہ جواب حاصل کیا جا سکے، تاکہ وہ 'Hi' اور 'Highway' یا 'flock' اور 'floccinaucinihilipilification' کے درمیان فرق کر سکیں۔
تقریر کے ماڈلز اتنے جدید ہیں کہ وہ سیاق و سباق کو سمجھ سکتے ہیں، اور مزید آوازوں پر عمل کرتے ہوئے اپنے الفاظ کو درست کر سکتے ہیں۔ مثال کے طور پر، اگر آپ کہیں "میں دکانوں پر گیا تاکہ دو کیلے اور ایک سیب بھی لے آؤں"، تو آپ تین ایسے الفاظ استعمال کریں گے جو ایک جیسے لگتے ہیں، لیکن مختلف طریقے سے لکھے جاتے ہیں - to, two اور too۔ تقریر کے ماڈلز سیاق و سباق کو سمجھنے اور لفظ کی مناسب ہجے استعمال کرنے کے قابل ہوتے 💁 کچھ تقریری خدمات میں تخصیص کی اجازت ہوتی ہے تاکہ وہ شور والے ماحول جیسے فیکٹریوں میں بہتر کام کر سکیں، یا صنعت سے متعلق مخصوص الفاظ جیسے کیمیکل کے ناموں کے ساتھ۔ یہ تخصیصات نمونہ آڈیو اور ٹرانسکرپشن فراہم کر کے تربیت دی جاتی ہیں، اور ٹرانسفر لرننگ کے ذریعے کام کرتی ہیں، بالکل اسی طرح جیسے آپ نے پہلے سبق میں چند تصاویر استعمال کر کے ایک امیج کلاسیفائر کو تربیت دی تھی۔
پرائیویسی
جب کسی صارف IoT ڈیوائس میں اسپیک ٹو ٹیکسٹ استعمال کرتے ہیں، تو پرائیویسی انتہائی اہمیت رکھتی ہے۔ یہ ڈیوائسز مسلسل آڈیو سنتی ہیں، اور بطور صارف آپ نہیں چاہتے کہ آپ کی ہر بات کلاؤڈ پر بھیجی جائے اور ٹیکسٹ میں تبدیل ہو۔ نہ صرف یہ انٹرنیٹ بینڈوِڈتھ کا زیادہ استعمال کرے گا، بلکہ اس کے بڑے پرائیویسی اثرات بھی ہیں، خاص طور پر جب کچھ اسمارٹ ڈیوائس بنانے والے بے ترتیب آڈیو منتخب کرتے ہیں تاکہ انسانی تصدیق کے ذریعے ماڈل کو بہتر بنایا جا سکے۔
آپ چاہتے ہیں کہ آپ کی اسمارٹ ڈیوائس صرف اس وقت آڈیو کلاؤڈ پر بھیجے جب آپ اسے استعمال کر رہے ہوں، نہ کہ جب وہ آپ کے گھر میں آڈیو سنتی ہو، جس میں نجی ملاقاتیں یا ذاتی بات چیت شامل ہو سکتی ہیں۔ زیادہ تر اسمارٹ ڈیوائسز ایک وییک ورڈ کے ساتھ کام کرتی ہیں، جیسے "Alexa"، "Hey Siri"، یا "OK Google"، جو ڈیوائس کو 'جاگنے' اور آپ کی بات سننے پر مجبور کرتا ہے جب تک کہ وہ آپ کی گفتگو میں وقفہ محسوس نہ کرے، جو یہ ظاہر کرتا ہے کہ آپ نے ڈیوائس سے بات ختم کر دی ہے۔
🎓 وییک ورڈ ڈیٹیکشن کو کی ورڈ اسپاٹنگ یا کی ورڈ ریکگنیشن بھی کہا جاتا ہے۔
یہ وییک ورڈز ڈیوائس پر ڈیٹیکٹ کیے جاتے ہیں، کلاؤڈ پر نہیں۔ یہ اسمارٹ ڈیوائسز چھوٹے AI ماڈلز رکھتی ہیں جو ڈیوائس پر چلتے ہیں اور وییک ورڈ کو سنتے ہیں، اور جب یہ ڈیٹیکٹ ہو جائے تو آڈیو کو کلاؤڈ پر شناخت کے لیے اسٹریم کرنا شروع کر دیتی ہیں۔ یہ ماڈلز بہت خاص ہوتے ہیں اور صرف وییک ورڈ کو سنتے ہیں۔
💁 کچھ ٹیک کمپنیاں اپنی ڈیوائسز میں مزید پرائیویسی شامل کر رہی ہیں اور اسپیک ٹو ٹیکسٹ کنورژن کو ڈیوائس پر ہی انجام دے رہی ہیں۔ ایپل نے اعلان کیا ہے کہ 2021 کے iOS اور macOS اپڈیٹس کے حصے کے طور پر وہ اسپیک ٹو ٹیکسٹ کنورژن کو ڈیوائس پر سپورٹ کریں گے، اور بہت سی درخواستوں کو کلاؤڈ استعمال کیے بغیر ہینڈل کر سکیں گے۔ یہ ان کے ڈیوائسز میں موجود طاقتور پروسیسرز کی بدولت ممکن ہوا ہے جو ML ماڈلز کو چلا سکتے ہیں۔
✅ آپ کے خیال میں کلاؤڈ پر بھیجی گئی آڈیو کو اسٹور کرنے کے پرائیویسی اور اخلاقی اثرات کیا ہیں؟ کیا یہ آڈیو اسٹور کی جانی چاہیے، اور اگر ہاں، تو کیسے؟ کیا آپ سمجھتے ہیں کہ قانون نافذ کرنے کے لیے ریکارڈنگز کا استعمال پرائیویسی کے نقصان کے لیے ایک اچھا سودا ہے؟
وییک ورڈ ڈیٹیکشن عام طور پر ایک تکنیک استعمال کرتا ہے جسے TinyML کہا جاتا ہے، یعنی ML ماڈلز کو مائیکرو کنٹرولرز پر چلانے کے قابل بنانا۔ یہ ماڈلز سائز میں چھوٹے ہوتے ہیں اور چلانے کے لیے بہت کم توانائی استعمال کرتے ہیں۔
وییک ورڈ ماڈل کو ٹرین کرنے اور استعمال کرنے کی پیچیدگی سے بچنے کے لیے، اس سبق میں آپ جو اسمارٹ ٹائمر بنا رہے ہیں وہ اسپیک ریکگنیشن کو آن کرنے کے لیے ایک بٹن استعمال کرے گا۔
💁 اگر آپ وییک ورڈ ڈیٹیکشن ماڈل بنانے کی کوشش کرنا چاہتے ہیں جو Wio Terminal یا Raspberry Pi پر چل سکے، تو Edge Impulse کے اس آپ کی آواز پر ردعمل دینے والے ٹیوٹوریل کو دیکھیں۔ اگر آپ اپنے کمپیوٹر کو استعمال کرنا چاہتے ہیں، تو Microsoft Docs پر Custom Keyword quickstart کے ساتھ شروعات کریں۔
اسپیک کو ٹیکسٹ میں تبدیل کریں
![]()
بالکل اسی طرح جیسے ایک پہلے پروجیکٹ میں امیج کلاسیفیکیشن کے ساتھ، پہلے سے تیار شدہ AI سروسز موجود ہیں جو آڈیو فائل کو اسپیک کے طور پر لے کر اسے ٹیکسٹ میں تبدیل کر سکتی ہیں۔ ان میں سے ایک سروس اسپیک سروس ہے، جو Cognitive Services کا حصہ ہے، پہلے سے تیار شدہ AI سروسز جو آپ اپنی ایپس میں استعمال کر سکتے ہیں۔
کام - اسپیک AI ریسورس کو کنفیگر کریں
-
اس پروجیکٹ کے لیے ایک ریسورس گروپ بنائیں جس کا نام
smart-timerہو۔ -
مفت اسپیک ریسورس بنانے کے لیے درج ذیل کمانڈ استعمال کریں:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location><location>کو اس مقام سے تبدیل کریں جو آپ نے ریسورس گروپ بناتے وقت استعمال کیا تھا۔ -
آپ کو اپنے کوڈ سے اسپیک ریسورس تک رسائی کے لیے ایک API key کی ضرورت ہوگی۔ درج ذیل کمانڈ چلائیں تاکہ key حاصل کریں:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tablekeys میں سے ایک کی کاپی لے لیں۔
کام - اسپیک کو ٹیکسٹ میں تبدیل کریں
اپنے IoT ڈیوائس پر اسپیک کو ٹیکسٹ میں تبدیل کرنے کے لیے متعلقہ گائیڈ پر کام کریں:
🚀 چیلنج
اسپیک ریکگنیشن کافی عرصے سے موجود ہے اور مسلسل بہتر ہو رہی ہے۔ موجودہ صلاحیتوں پر تحقیق کریں اور موازنہ کریں کہ یہ وقت کے ساتھ کیسے ترقی کر چکی ہیں، بشمول مشین ٹرانسکرپشنز کی درستگی انسانوں کے مقابلے میں۔
آپ کے خیال میں اسپیک ریکگنیشن کا مستقبل کیا ہے؟
لیکچر کے بعد کوئز
جائزہ اور خود مطالعہ
- مختلف مائیکروفون کی اقسام اور ان کے کام کرنے کے طریقے کے بارے میں پڑھیں Musician's HQ کے آرٹیکل میں۔
- Cognitive Services اسپیک سروس کے بارے میں مزید پڑھیں Microsoft Docs پر اسپیک سروس کی دستاویزات میں۔
- کی ورڈ اسپاٹنگ کے بارے میں پڑھیں Microsoft Docs پر کی ورڈ ریکگنیشن کی دستاویزات میں۔
اسائنمنٹ
ڈسکلیمر:
یہ دستاویز AI ترجمہ سروس Co-op Translator کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے پوری کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا خامیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے لیے ہم ذمہ دار نہیں ہیں۔