|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
Ställ in en timer och ge muntlig feedback
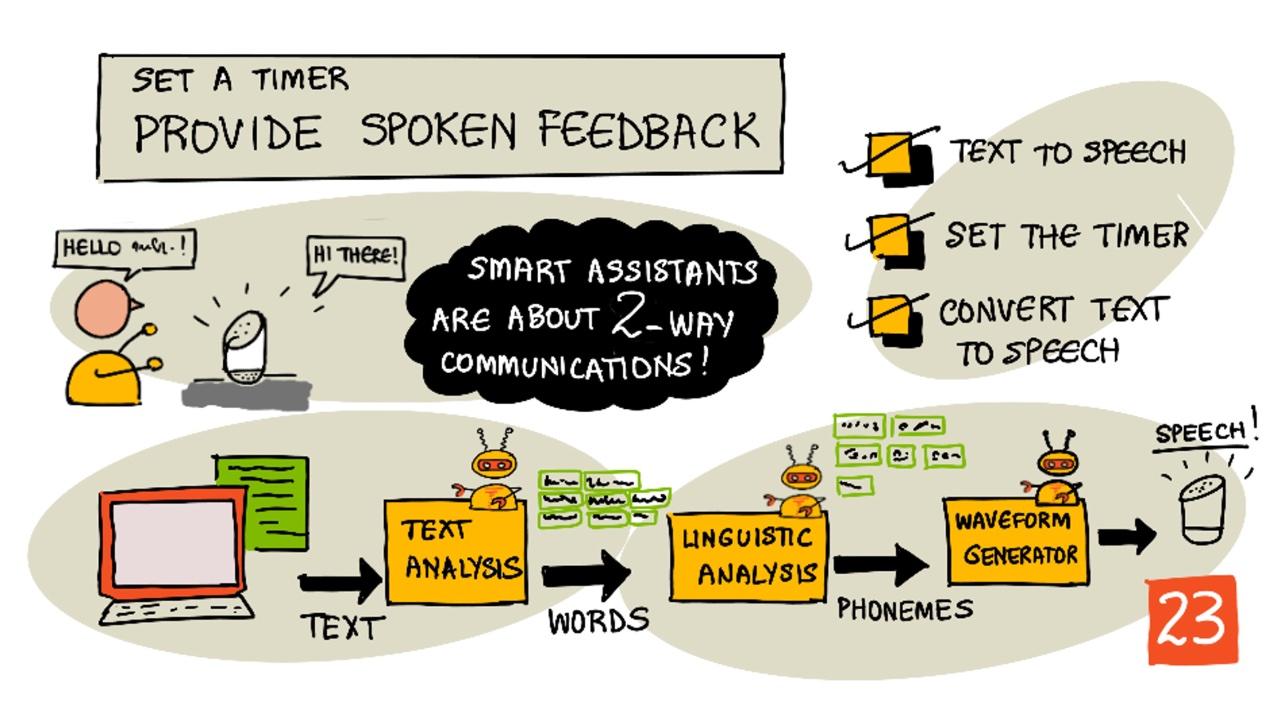
Sketchnote av Nitya Narasimhan. Klicka på bilden för en större version.
Quiz före föreläsningen
Introduktion
Smarta assistenter är inte envägskommunikationsenheter. Du pratar med dem, och de svarar:
"Alexa, sätt en timer på 3 minuter"
"Okej, din timer är inställd på 3 minuter"
Under de senaste två lektionerna lärde du dig hur man tar tal och skapar text, och sedan extraherar en begäran om att ställa in en timer från den texten. I denna lektion kommer du att lära dig hur man ställer in timern på IoT-enheten, svarar användaren med talade ord som bekräftar deras timer och meddelar dem när timern är klar.
I denna lektion kommer vi att täcka:
Text till tal
Text till tal, som namnet antyder, är processen att konvertera text till ljud som innehåller texten som talade ord. Den grundläggande principen är att bryta ner orden i texten till deras beståndsdelar (kända som fonem) och sätta ihop ljud för dessa ljud, antingen med förinspelat ljud eller med ljud som genereras av AI-modeller.

Text-till-tal-system har vanligtvis tre steg:
- Textanalys
- Språklig analys
- Våggenerering
Textanalys
Textanalys innebär att ta den angivna texten och konvertera den till ord som kan användas för att generera tal. Till exempel, om du konverterar "Hej världen", behövs ingen textanalys, de två orden kan konverteras till tal. Om du har "1234" däremot, kan detta behöva konverteras antingen till orden "Tusen tvåhundra trettiofyra" eller "Ett, två, tre, fyra" beroende på sammanhanget. För "Jag har 1234 äpplen" skulle det vara "Tusen tvåhundra trettiofyra", men för "Barnet räknade till 1234" skulle det vara "Ett, två, tre, fyra".
De ord som skapas varierar inte bara för språket, utan även för språklokalen. Till exempel, på amerikansk engelska skulle 120 vara "One hundred twenty", medan det på brittisk engelska skulle vara "One hundred and twenty", med användning av "and" efter hundratalet.
✅ Några andra exempel som kräver textanalys inkluderar "in" som en förkortning för tum och "st" som en förkortning för helgon och gata. Kan du komma på andra exempel på ditt språk där ord är tvetydiga utan sammanhang?
När orden har definierats skickas de för språklig analys.
Språklig analys
Språklig analys bryter ner orden till fonem. Fonem baseras inte bara på de bokstäver som används, utan även på andra bokstäver i ordet. Till exempel, på engelska är 'a'-ljudet i 'car' och 'care' olika. Det engelska språket har 44 olika fonem för de 26 bokstäverna i alfabetet, vissa delas av olika bokstäver, som samma fonem som används i början av 'circle' och 'serpent'.
✅ Gör lite research: Vilka är fonemen för ditt språk?
När orden har konverterats till fonem behöver dessa fonem ytterligare data för att stödja intonation, justera ton eller varaktighet beroende på sammanhanget. Ett exempel är att på engelska kan tonhöjning användas för att omvandla en mening till en fråga, där en höjd tonhöjd för det sista ordet antyder en fråga.
Till exempel - meningen "Du har ett äpple" är ett påstående som säger att du har ett äpple. Om tonhöjden går upp i slutet, ökar för ordet äpple, blir det frågan "Du har ett äpple?", som frågar om du har ett äpple. Den språkliga analysen behöver använda frågetecknet i slutet för att besluta att öka tonhöjden.
När fonemen har genererats kan de skickas för våggenerering för att producera ljudutgången.
Våggenerering
De första elektroniska text-till-tal-systemen använde enskilda ljudinspelningar för varje fonem, vilket ledde till mycket monotona, robotliknande röster. Den språkliga analysen skulle producera fonem, dessa skulle laddas från en databas med ljud och sättas ihop för att skapa ljudet.
✅ Gör lite research: Hitta några ljudinspelningar från tidiga talsyntessystem. Jämför dem med modern talsyntes, som den som används i smarta assistenter.
Mer modern våggenerering använder ML-modeller byggda med djupinlärning (mycket stora neurala nätverk som fungerar på ett liknande sätt som neuroner i hjärnan) för att producera mer naturliga röster som kan vara omöjliga att skilja från mänskliga röster.
💁 Några av dessa ML-modeller kan tränas om med hjälp av transfer learning för att låta som riktiga människor. Detta innebär att använda rösten som ett säkerhetssystem, något som banker alltmer försöker göra, inte längre är en bra idé eftersom vem som helst med en inspelning på några minuter av din röst kan imitera dig.
Dessa stora ML-modeller tränas för att kombinera alla tre stegen till end-to-end talsyntes.
Ställ in timern
För att ställa in timern behöver din IoT-enhet anropa REST-slutpunkten du skapade med serverlös kod och sedan använda det resulterande antalet sekunder för att ställa in en timer.
Uppgift - anropa den serverlösa funktionen för att få timer-tiden
Följ den relevanta guiden för att anropa REST-slutpunkten från din IoT-enhet och ställ in en timer för den önskade tiden:
Konvertera text till tal
Samma talservice som du använde för att konvertera tal till text kan användas för att konvertera text tillbaka till tal, och detta kan spelas upp via en högtalare på din IoT-enhet. Texten som ska konverteras skickas till talservicen, tillsammans med typen av ljud som krävs (såsom samplingsfrekvensen), och binär data som innehåller ljudet returneras.
När du skickar denna begäran gör du det med Speech Synthesis Markup Language (SSML), ett XML-baserat markeringsspråk för talsyntesapplikationer. Detta definierar inte bara texten som ska konverteras, utan även textens språk, rösten som ska användas, och kan till och med användas för att definiera hastighet, volym och tonhöjd för vissa eller alla ord i texten.
Till exempel definierar denna SSML en begäran om att konvertera texten "Din 3 minuter och 5 sekunder timer har ställts in" till tal med en brittisk engelsk röst kallad en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 De flesta text-till-tal-system har flera röster för olika språk, med relevanta accenter såsom en brittisk engelsk röst med engelsk accent och en nyzeeländsk engelsk röst med nyzeeländsk accent.
Uppgift - konvertera text till tal
Arbeta igenom den relevanta guiden för att konvertera text till tal med din IoT-enhet:
🚀 Utmaning
SSML har sätt att ändra hur ord uttalas, såsom att lägga till betoning på vissa ord, lägga till pauser eller ändra tonhöjd. Testa några av dessa, skicka olika SSML från din IoT-enhet och jämför resultatet. Du kan läsa mer om SSML, inklusive hur man ändrar hur ord uttalas, i Speech Synthesis Markup Language (SSML) Version 1.1-specifikationen från World Wide Web Consortium.
Quiz efter föreläsningen
Granskning & Självstudier
- Läs mer om talsyntes på talsyntessidan på Wikipedia
- Läs mer om hur brottslingar använder talsyntes för att stjäla på fake voices 'help cyber crooks steal cash'-artikeln på BBC News
- Lär dig mer om riskerna för röstskådespelare från syntetiserade versioner av deras röster i denna TikTok-stämning belyser hur AI utnyttjar röstskådespelare-artikeln på Vice
Uppgift
Ansvarsfriskrivning:
Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet, bör du vara medveten om att automatiserade översättningar kan innehålla fel eller felaktigheter. Det ursprungliga dokumentet på dess ursprungliga språk bör betraktas som den auktoritativa källan. För kritisk information rekommenderas professionell mänsklig översättning. Vi ansvarar inte för eventuella missförstånd eller feltolkningar som uppstår vid användning av denna översättning.