|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-audio.md | 4 weeks ago | |
| pi-microphone.md | 4 weeks ago | |
| pi-speech-to-text.md | 4 weeks ago | |
| virtual-device-audio.md | 4 weeks ago | |
| virtual-device-microphone.md | 4 weeks ago | |
| virtual-device-speech-to-text.md | 4 weeks ago | |
| wio-terminal-audio.md | 4 weeks ago | |
| wio-terminal-microphone.md | 4 weeks ago | |
| wio-terminal-speech-to-text.md | 4 weeks ago | |
README.md
Känna igen tal med en IoT-enhet
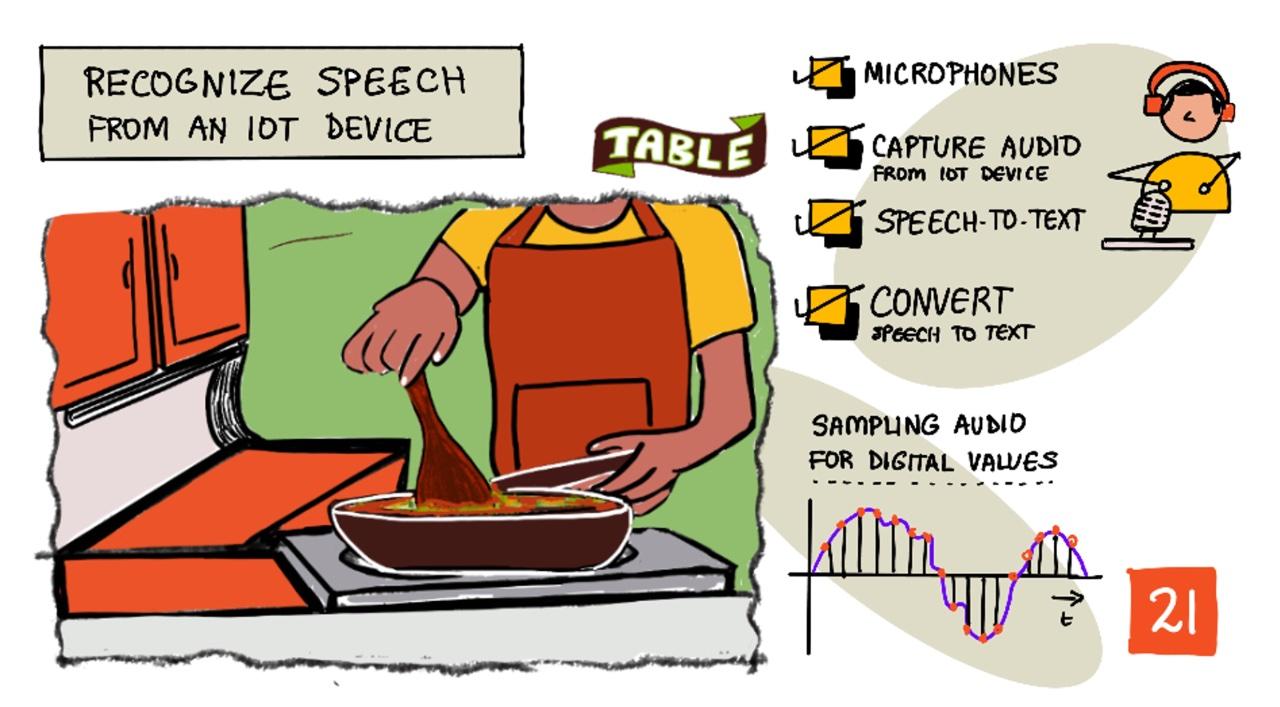
Sketchnote av Nitya Narasimhan. Klicka på bilden för en större version.
Den här videon ger en översikt av Azure talservice, ett ämne som kommer att behandlas i denna lektion:

🎥 Klicka på bilden ovan för att se en video
Quiz före föreläsningen
Introduktion
'Alexa, sätt en timer på 12 minuter'
'Alexa, timerstatus'
'Alexa, sätt en timer på 8 minuter som heter ångkok broccoli'
Smarta enheter blir alltmer vanliga. Inte bara som smarta högtalare som HomePods, Echos och Google Homes, utan även inbyggda i våra telefoner, klockor och till och med lampor och termostater.
💁 Jag har minst 19 enheter i mitt hem som har röstassistenter, och det är bara de jag känner till!
Röststyrning ökar tillgängligheten genom att låta personer med begränsad rörelseförmåga interagera med enheter. Oavsett om det handlar om en permanent funktionsnedsättning, som att vara född utan armar, eller en tillfällig skada som brutna armar, eller att ha händerna fulla med shopping eller små barn, kan möjligheten att styra våra hem med rösten istället för händerna öppna upp en värld av tillgång. Att ropa 'Hej Siri, stäng garageporten' medan man hanterar ett blöjbyte och en trotsig småtting kan vara en liten men effektiv förbättring i livet.
En av de mer populära användningarna för röstassistenter är att ställa in timers, särskilt kökstimers. Att kunna ställa in flera timers med bara rösten är en stor hjälp i köket - ingen anledning att avbryta knådning av deg, omrörning av soppa eller rengöra händerna från dumplingsfyllning för att använda en fysisk timer.
I denna lektion kommer du att lära dig hur man bygger in röstigenkänning i IoT-enheter. Du kommer att lära dig om mikrofoner som sensorer, hur man fångar ljud från en mikrofon ansluten till en IoT-enhet och hur man använder AI för att konvertera det som hörs till text. Under resten av detta projekt kommer du att bygga en smart kökstimer som kan ställa in timers med din röst på flera språk.
I denna lektion kommer vi att behandla:
Mikrofoner
Mikrofoner är analoga sensorer som omvandlar ljudvågor till elektriska signaler. Vibrationer i luften får komponenter i mikrofonen att röra sig små mängder, och dessa orsakar små förändringar i elektriska signaler. Dessa förändringar förstärks sedan för att generera en elektrisk output.
Mikrofontyper
Mikrofoner finns i olika typer:
-
Dynamisk - Dynamiska mikrofoner har en magnet som är fäst vid en rörlig membran som rör sig i en trådspole och skapar en elektrisk ström. Detta är motsatsen till de flesta högtalare, som använder en elektrisk ström för att flytta en magnet i en trådspole och flytta ett membran för att skapa ljud. Detta innebär att högtalare kan användas som dynamiska mikrofoner, och dynamiska mikrofoner kan användas som högtalare. I enheter som intercoms där en användare antingen lyssnar eller talar, men inte båda, kan en enhet fungera som både högtalare och mikrofon.
Dynamiska mikrofoner behöver ingen ström för att fungera, den elektriska signalen skapas helt av mikrofonen.

-
Band - Bandmikrofoner liknar dynamiska mikrofoner, förutom att de har ett metallband istället för ett membran. Detta band rör sig i ett magnetfält och genererar en elektrisk ström. Precis som dynamiska mikrofoner behöver bandmikrofoner ingen ström för att fungera.

-
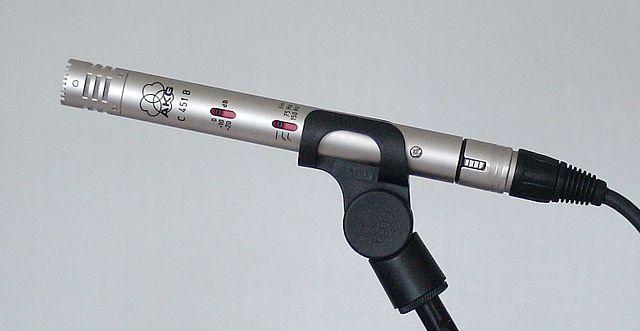
Kondensator - Kondensatormikrofoner har ett tunt metallmembran och en fast metallbakplatta. Elektricitet appliceras på båda dessa och när membranet vibrerar ändras den statiska laddningen mellan plattorna och genererar en signal. Kondensatormikrofoner behöver ström för att fungera - kallad Phantom power.
-
MEMS - Mikroelektromekaniska systemmikrofoner, eller MEMS, är mikrofoner på ett chip. De har ett tryckkänsligt membran etsad på ett kiselchip och fungerar liknande en kondensatormikrofon. Dessa mikrofoner kan vara mycket små och integreras i kretsar.

På bilden ovan är chipet märkt LEFT en MEMS-mikrofon, med ett litet membran mindre än en millimeter brett.
✅ Gör lite forskning: Vilka mikrofoner har du runt dig - antingen i din dator, din telefon, ditt headset eller i andra enheter. Vilken typ av mikrofoner är de?
Digitalt ljud
Ljud är en analog signal som bär mycket finfördelad information. För att konvertera denna signal till digitalt måste ljudet samplas många tusen gånger per sekund.
🎓 Sampling innebär att konvertera ljudsignalen till ett digitalt värde som representerar signalen vid den tidpunkten.
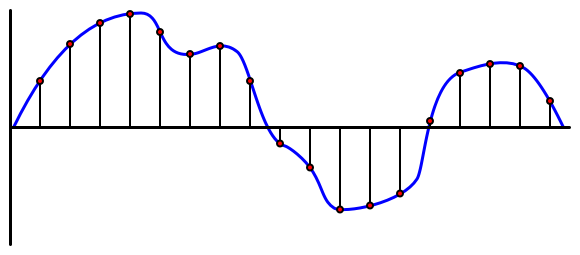
Digitalt ljud samplas med hjälp av Pulse Code Modulation, eller PCM. PCM innebär att läsa spänningen i signalen och välja det närmaste diskreta värdet till den spänningen med en definierad storlek.
💁 Du kan tänka på PCM som sensorversionen av pulsbreddsmodulering, eller PWM (PWM behandlades tidigare i lektion 3 i introduktionsprojektet). PCM innebär att konvertera en analog signal till digital, PWM innebär att konvertera en digital signal till analog.
Till exempel erbjuder de flesta streamingtjänster för musik 16-bitars eller 24-bitars ljud. Detta innebär att de konverterar spänningen till ett värde som passar in i ett 16-bitars heltal eller 24-bitars heltal. 16-bitars ljud passar värdet i ett nummer som sträcker sig från -32,768 till 32,767, 24-bitars är i intervallet −8,388,608 till 8,388,607. Ju fler bitar, desto närmare är samplingen det våra öron faktiskt hör.
💁 Du kanske har hört talas om 8-bitars ljud, ofta kallat LoFi. Detta är ljud som samplas med endast 8 bitar, alltså -128 till 127. Den första datorljudet var begränsat till 8 bitar på grund av hårdvarubegränsningar, så detta ses ofta i retrospel.
Dessa samplingar tas många tusen gånger per sekund, med väldefinierade samplingsfrekvenser mätta i KHz (tusen avläsningar per sekund). Streamingtjänster för musik använder 48KHz för de flesta ljud, men vissa 'förlustfria' ljud använder upp till 96KHz eller till och med 192KHz. Ju högre samplingsfrekvens, desto närmare originalet kommer ljudet att vara, upp till en viss punkt. Det finns debatt om huruvida människor kan märka skillnaden över 48KHz.
✅ Gör lite forskning: Om du använder en streamingtjänst för musik, vilken samplingsfrekvens och storlek använder den? Om du använder CD-skivor, vad är samplingsfrekvensen och storleken på CD-ljud?
Det finns ett antal olika format för ljuddata. Du har förmodligen hört talas om mp3-filer - ljuddata som komprimeras för att göra den mindre utan att förlora någon kvalitet. Okomprimerat ljud lagras ofta som en WAV-fil - detta är en fil med 44 byte headerinformation, följt av rå ljuddata. Headern innehåller information som samplingsfrekvensen (till exempel 16000 för 16KHz) och samplingsstorleken (16 för 16-bitars), samt antalet kanaler. Efter headern innehåller WAV-filen den råa ljuddatan.
🎓 Kanaler hänvisar till hur många olika ljudströmmar som utgör ljudet. Till exempel, för stereoljud med vänster och höger, skulle det finnas 2 kanaler. För 7.1 surroundljud för ett hemmabiosystem skulle detta vara 8.
Ljuddatas storlek
Ljuddata är relativt stora. Till exempel, att fånga okomprimerat 16-bitars ljud vid 16KHz (en tillräckligt bra frekvens för användning med tal-till-text-modeller), tar 32KB data för varje sekund av ljud:
- 16-bitars innebär 2 byte per sampling (1 byte är 8 bitar).
- 16KHz är 16,000 samplingar per sekund.
- 16,000 x 2 byte = 32,000 byte per sekund.
Detta låter som en liten mängd data, men om du använder en mikrokontroller med begränsat minne kan detta vara mycket. Till exempel har Wio Terminal 192KB minne, och det måste lagra programkod och variabler. Även om din programkod var liten, skulle du inte kunna fånga mer än 5 sekunder av ljud.
Mikrokontroller kan komma åt ytterligare lagring, såsom SD-kort eller flashminne. När du bygger en IoT-enhet som fångar ljud måste du säkerställa att du inte bara har ytterligare lagring, utan att din kod skriver det ljud som fångas från din mikrofon direkt till den lagringen, och när du skickar det till molnet, strömmar från lagring till webbförfrågan. På så sätt kan du undvika att få slut på minne genom att försöka hålla hela ljudblocket i minnet samtidigt.
Fånga ljud från din IoT-enhet
Din IoT-enhet kan anslutas till en mikrofon för att fånga ljud, redo att konverteras till text. Den kan också anslutas till högtalare för att spela upp ljud. I senare lektioner kommer detta att användas för att ge ljudfeedback, men det är användbart att konfigurera högtalare nu för att testa mikrofonen.
Uppgift - konfigurera din mikrofon och högtalare
Följ den relevanta guiden för att konfigurera mikrofonen och högtalarna för din IoT-enhet:
Uppgift - fånga ljud
Följ den relevanta guiden för att fånga ljud på din IoT-enhet:
Tal till text
Tal till text, eller taligenkänning, innebär att använda AI för att konvertera ord i en ljudsignal till text.
Taligenkänningsmodeller
För att konvertera tal till text grupperas samplingar från ljudsignalen och matas in i en maskininlärningsmodell baserad på ett Recurrent Neural Network (RNN). Detta är en typ av maskininlärningsmodell som kan använda tidigare data för att fatta beslut om inkommande data. Till exempel kan RNN upptäcka ett block av ljudsamplingar som ljudet 'Hel', och när det får ett annat som det tror är ljudet 'lo', kan det kombinera detta med det tidigare ljudet, hitta att 'Hello' är ett giltigt ord och välja det som resultat.
ML-modeller accepterar alltid data av samma storlek varje gång. Bildklassificeraren du byggde i en tidigare lektion ändrar storleken på bilder till en fast storlek och bearbetar dem. Samma sak gäller för talmodeller, de måste bearbeta ljudbitar av fast storlek. Talmodeller måste kunna kombinera resultaten av flera förutsägelser för att få svaret, för att kunna skilja mellan 'Hej' och 'Motorväg', eller 'flock' och 'floccinaucinihilipilification'.
Talmodeller är också tillräckligt avancerade för att förstå sammanhang och kan korrigera de ord de upptäcker när fler ljud bearbetas. Till exempel, om du säger "Jag gick till affären för att köpa två bananer och ett äpple också", skulle du använda tre ord som låter likadana men stavas olika - till, två och också. Talmodeller kan förstå sammanhanget och använda den lämpliga stavningen av ordet. 💁 Vissa taligenkänningstjänster tillåter anpassning för att fungera bättre i bullriga miljöer som fabriker, eller med branschspecifika ord som kemiska namn. Dessa anpassningar tränas genom att tillhandahålla exempel på ljud och en transkription, och fungerar med hjälp av transfer learning, precis som när du tränade en bildklassificerare med bara några få bilder i en tidigare lektion.
Sekretess
När man använder tal-till-text på en konsument-IoT-enhet är sekretess otroligt viktigt. Dessa enheter lyssnar kontinuerligt på ljud, så som konsument vill du inte att allt du säger skickas till molnet och omvandlas till text. Detta skulle inte bara använda mycket internetbandbredd, utan det har också stora sekretessimplikationer, särskilt när vissa tillverkare av smarta enheter slumpmässigt väljer ljud för människor att validera mot den genererade texten för att förbättra deras modell.
Du vill bara att din smarta enhet ska skicka ljud till molnet för bearbetning när du använder den, inte när den hör ljud i ditt hem, ljud som kan inkludera privata möten eller intima interaktioner. De flesta smarta enheter fungerar med ett väckningsord, en nyckelfras som "Alexa", "Hej Siri" eller "OK Google" som får enheten att 'vakna' och lyssna på vad du säger tills den upptäcker en paus i ditt tal, vilket indikerar att du har slutat prata med enheten.
🎓 Väckningsordsdetektion kallas också för Keyword spotting eller Keyword recognition.
Dessa väckningsord upptäcks på enheten, inte i molnet. Dessa smarta enheter har små AI-modeller som körs på enheten och lyssnar efter väckningsordet, och när det upptäcks börjar de strömma ljudet till molnet för igenkänning. Dessa modeller är mycket specialiserade och lyssnar bara efter väckningsordet.
💁 Vissa teknikföretag lägger till mer sekretess i sina enheter och gör en del av tal-till-text-konverteringen på enheten. Apple har meddelat att som en del av deras iOS- och macOS-uppdateringar 2021 kommer de att stödja tal-till-text-konvertering på enheten och kunna hantera många förfrågningar utan att behöva använda molnet. Detta är möjligt tack vare kraftfulla processorer i deras enheter som kan köra ML-modeller.
✅ Vad tycker du är de sekretess- och etiska implikationerna av att lagra ljud som skickas till molnet? Bör detta ljud lagras, och i så fall hur? Tycker du att användningen av inspelningar för brottsbekämpning är en bra kompromiss för förlusten av sekretess?
Väckningsordsdetektion använder vanligtvis en teknik som kallas TinyML, vilket innebär att ML-modeller konverteras för att kunna köras på mikrokontroller. Dessa modeller är små i storlek och förbrukar mycket lite ström för att köras.
För att undvika komplexiteten i att träna och använda en väckningsordsmodell kommer den smarta timern du bygger i denna lektion att använda en knapp för att aktivera taligenkänning.
💁 Om du vill prova att skapa en väckningsordsdetektionsmodell för att köra på Wio Terminal eller Raspberry Pi, kolla in denna handledning om att svara på din röst från Edge Impulse. Om du vill använda din dator för detta kan du prova komma igång med Custom Keyword snabbstart på Microsoft Docs.
Konvertera tal till text
![]()
Precis som med bildklassificering i ett tidigare projekt finns det förbyggda AI-tjänster som kan ta tal som en ljudfil och konvertera det till text. En sådan tjänst är Speech Service, en del av Cognitive Services, förbyggda AI-tjänster som du kan använda i dina appar.
Uppgift - konfigurera en AI-resurs för tal
-
Skapa en resursgrupp för detta projekt som heter
smart-timer. -
Använd följande kommando för att skapa en gratis talresurs:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Ersätt
<location>med platsen du använde när du skapade resursgruppen. -
Du kommer att behöva en API-nyckel för att komma åt talresursen från din kod. Kör följande kommando för att få nyckeln:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableTa en kopia av en av nycklarna.
Uppgift - konvertera tal till text
Följ den relevanta guiden för att konvertera tal till text på din IoT-enhet:
🚀 Utmaning
Taligenkänning har funnits länge och förbättras kontinuerligt. Undersök de nuvarande möjligheterna och jämför hur dessa har utvecklats över tid, inklusive hur exakta maskintranskriptioner är jämfört med mänskliga.
Vad tror du framtiden har att erbjuda för taligenkänning?
Efterföreläsningsquiz
Granskning & Självstudier
- Läs om de olika mikrofontyperna och hur de fungerar i artikeln vad är skillnaden mellan dynamiska och kondensatormikrofoner på Musician's HQ.
- Läs mer om Cognitive Services tal-tjänst i dokumentationen om tal-tjänsten på Microsoft Docs.
- Läs om keyword spotting i dokumentationen om keyword recognition på Microsoft Docs.
Uppgift
Ansvarsfriskrivning:
Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet, bör det noteras att automatiska översättningar kan innehålla fel eller felaktigheter. Det ursprungliga dokumentet på dess ursprungliga språk bör betraktas som den auktoritativa källan. För kritisk information rekommenderas professionell mänsklig översättning. Vi ansvarar inte för eventuella missförstånd eller feltolkningar som uppstår vid användning av denna översättning.