|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
| pi-audio.md | 3 weeks ago | |
| pi-microphone.md | 3 weeks ago | |
| pi-speech-to-text.md | 3 weeks ago | |
| virtual-device-audio.md | 3 weeks ago | |
| virtual-device-microphone.md | 3 weeks ago | |
| virtual-device-speech-to-text.md | 3 weeks ago | |
| wio-terminal-audio.md | 3 weeks ago | |
| wio-terminal-microphone.md | 3 weeks ago | |
| wio-terminal-speech-to-text.md | 3 weeks ago | |
README.md
Rozpoznávanie reči pomocou IoT zariadenia
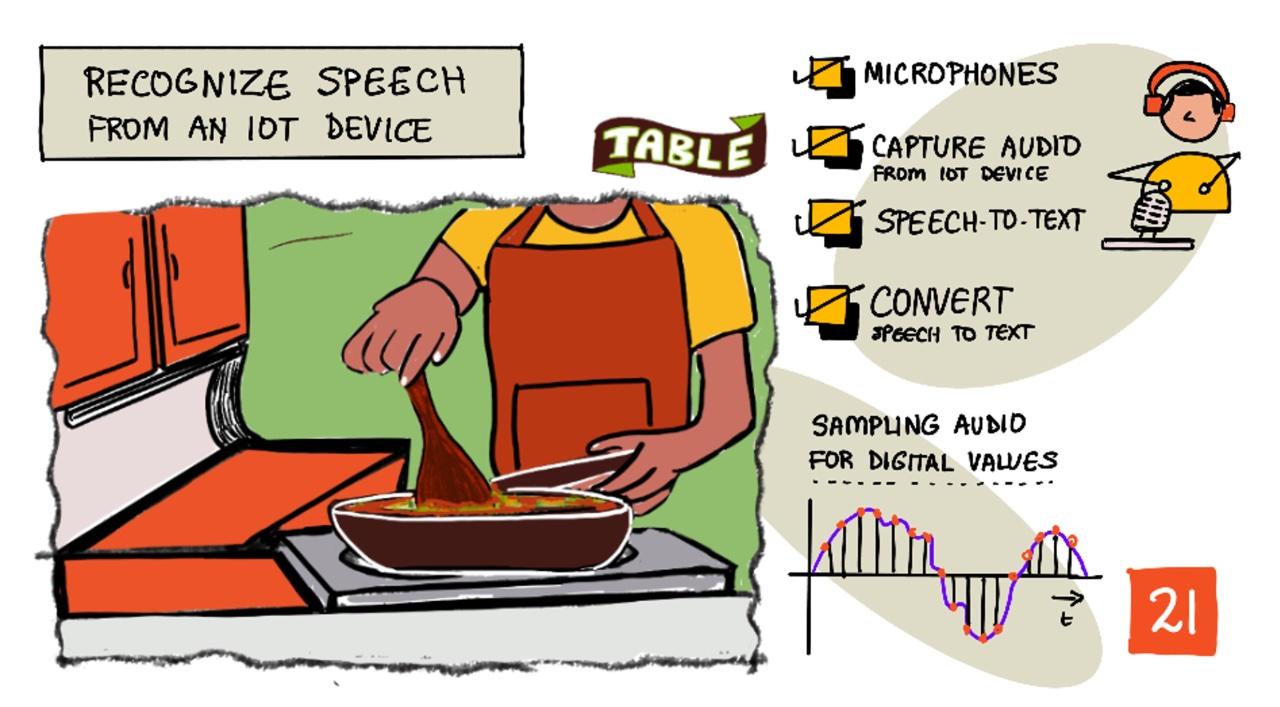
Sketchnote od Nitya Narasimhan. Kliknite na obrázok pre väčšiu verziu.
Toto video poskytuje prehľad o Azure Speech Service, téme, ktorá bude pokrytá v tejto lekcii:

🎥 Kliknite na obrázok vyššie a pozrite si video
Kvíz pred prednáškou
Úvod
'Alexa, nastav časovač na 12 minút'
'Alexa, aký je stav časovača?'
'Alexa, nastav časovač na 8 minút s názvom para brokolica'
Inteligentné zariadenia sa stávajú čoraz bežnejšími. Nielen ako inteligentné reproduktory ako HomePods, Echos a Google Homes, ale aj ako súčasť našich telefónov, hodiniek, a dokonca aj svietidiel a termostatov.
💁 V mojom dome mám aspoň 19 zariadení s hlasovými asistentmi, a to sú len tie, o ktorých viem!
Hlasové ovládanie zvyšuje prístupnosť tým, že umožňuje ľuďom s obmedzenou pohyblivosťou interagovať so zariadeniami. Či už ide o trvalé postihnutie, ako je narodenie bez rúk, dočasné postihnutie, ako sú zlomené ruky, alebo situácie, keď máte ruky plné nákupov alebo malých detí, možnosť ovládať naše domovy hlasom namiesto rúk otvára svet prístupnosti. Kričať 'Hej Siri, zatvor moju garáž' pri prebaľovaní dieťaťa a zvládaní neposlušného batoľaťa môže byť malým, ale účinným zlepšením života.
Jedným z najobľúbenejších využití hlasových asistentov je nastavovanie časovačov, najmä kuchynských. Možnosť nastaviť viacero časovačov len hlasom je veľkou pomocou v kuchyni - nemusíte prestať miesiť cesto, miešať polievku alebo si čistiť ruky od plnky na knedle, aby ste použili fyzický časovač.
V tejto lekcii sa naučíte, ako zabudovať rozpoznávanie hlasu do IoT zariadení. Naučíte sa o mikrofónoch ako senzoroch, ako zachytiť zvuk z mikrofónu pripojeného k IoT zariadeniu a ako použiť AI na prevod toho, čo sa počuje, na text. Počas zvyšku tohto projektu si postavíte inteligentný kuchynský časovač, ktorý dokáže nastaviť časovače pomocou vášho hlasu vo viacerých jazykoch.
V tejto lekcii sa budeme venovať:
Mikrofóny
Mikrofóny sú analógové senzory, ktoré premieňajú zvukové vlny na elektrické signály. Vibrácie vo vzduchu spôsobujú, že komponenty v mikrofóne sa pohybujú o veľmi malé množstvá, čo spôsobuje malé zmeny v elektrických signáloch. Tieto zmeny sa potom zosilňujú, aby sa vytvoril elektrický výstup.
Typy mikrofónov
Mikrofóny existujú v rôznych typoch:
-
Dynamické - Dynamické mikrofóny majú magnet pripojený k pohyblivej membráne, ktorá sa pohybuje v cievke drôtu a vytvára elektrický prúd. Toto je opak väčšiny reproduktorov, ktoré používajú elektrický prúd na pohyb magnetu v cievke drôtu, čím pohybujú membránou a vytvárajú zvuk. To znamená, že reproduktory môžu byť použité ako dynamické mikrofóny a dynamické mikrofóny môžu byť použité ako reproduktory. V zariadeniach, ako sú interkomy, kde používateľ buď počúva, alebo hovorí, ale nie oboje naraz, jedno zariadenie môže fungovať ako reproduktor aj mikrofón.
Dynamické mikrofóny nepotrebujú na svoju činnosť napájanie, elektrický signál sa vytvára výlučne z mikrofónu.

-
Páskové - Páskové mikrofóny sú podobné dynamickým mikrofónom, ale namiesto membrány majú kovovú pásku. Táto páska sa pohybuje v magnetickom poli a generuje elektrický prúd. Rovnako ako dynamické mikrofóny, páskové mikrofóny nepotrebujú napájanie na svoju činnosť.

-
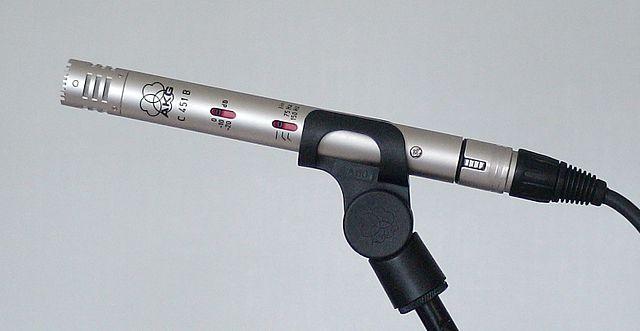
Kondenzátorové - Kondenzátorové mikrofóny majú tenkú kovovú membránu a pevný kovový zadný plát. Elektrina sa aplikuje na obe tieto časti a keď membrána vibruje, statický náboj medzi platňami sa mení a generuje signál. Kondenzátorové mikrofóny potrebujú na svoju činnosť napájanie - nazývané Phantom power.
-
MEMS - Mikrofóny na báze mikroelektromechanických systémov (MEMS) sú mikrofóny na čipe. Majú tlakovo citlivú membránu vyrytú na kremíkovom čipe a fungujú podobne ako kondenzátorové mikrofóny. Tieto mikrofóny môžu byť veľmi malé a integrované do obvodov.

Na obrázku vyššie je čip označený LEFT MEMS mikrofón s malou membránou menšou ako milimeter.
✅ Urobte si prieskum: Aké mikrofóny máte okolo seba - či už vo vašom počítači, telefóne, slúchadlách alebo v iných zariadeniach. Aký typ mikrofónov to je?
Digitálny zvuk
Zvuk je analógový signál, ktorý nesie veľmi jemné informácie. Na prevod tohto signálu na digitálny je potrebné zvuk vzorkovať tisícekrát za sekundu.
🎓 Vzorkovanie je proces prevodu zvukového signálu na digitálnu hodnotu, ktorá reprezentuje signál v danom časovom okamihu.
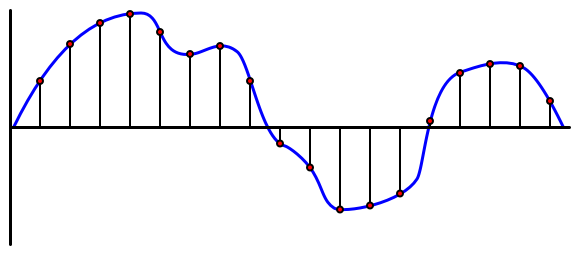
Digitálny zvuk sa vzorkuje pomocou Pulznej kódovej modulácie (PCM). PCM zahŕňa čítanie napätia signálu a výber najbližšej diskrétnej hodnoty k tomuto napätiu pomocou definovanej veľkosti.
💁 PCM si môžete predstaviť ako senzorovú verziu pulznej šírkovej modulácie (PWM). (PWM bolo pokryté v lekcii 3 projektu pre začiatočníkov). PCM zahŕňa prevod analógového signálu na digitálny, PWM zahŕňa prevod digitálneho signálu na analógový.
Napríklad väčšina streamovacích hudobných služieb ponúka 16-bitový alebo 24-bitový zvuk. To znamená, že prevádzajú napätie na hodnotu, ktorá sa zmestí do 16-bitového alebo 24-bitového celého čísla. 16-bitový zvuk sa zmestí do rozsahu -32,768 až 32,767, 24-bitový do rozsahu −8,388,608 až 8,388,607. Čím viac bitov, tým bližšie je vzorka k tomu, čo naše uši skutočne počujú.
💁 Možno ste počuli o 8-bitovom zvuku, často označovanom ako LoFi. Ide o zvuk vzorkovaný iba pomocou 8 bitov, teda -128 až 127. Prvé počítačové zvuky boli obmedzené na 8 bitov kvôli hardvérovým obmedzeniam, takže sa často objavujú v retro hrách.
Tieto vzorky sa odoberajú tisícekrát za sekundu, pričom sa používajú dobre definované vzorkovacie frekvencie merané v KHz (tisíce odberov za sekundu). Streamovacie hudobné služby používajú 48KHz pre väčšinu zvuku, ale niektoré 'bezstratové' zvuky používajú až 96KHz alebo dokonca 192KHz. Čím vyššia je vzorkovacia frekvencia, tým bližšie je zvuk originálu, až do určitého bodu. Existuje debata, či ľudia dokážu rozlíšiť rozdiel nad 48KHz.
✅ Urobte si prieskum: Ak používate streamovaciu hudobnú službu, akú vzorkovaciu frekvenciu a veľkosť používa? Ak používate CD, aká je vzorkovacia frekvencia a veľkosť zvuku na CD?
Existuje množstvo rôznych formátov pre zvukové dáta. Pravdepodobne ste už počuli o mp3 súboroch - zvukových dátach, ktoré sú komprimované, aby boli menšie bez straty kvality. Nezkomprimovaný zvuk sa často ukladá ako WAV súbor - tento súbor obsahuje 44 bajtov hlavičkových informácií, po ktorých nasledujú surové zvukové dáta. Hlavička obsahuje informácie ako vzorkovacia frekvencia (napríklad 16000 pre 16KHz) a veľkosť vzorky (16 pre 16-bitov), a počet kanálov. Po hlavičke obsahuje WAV súbor surové zvukové dáta.
🎓 Kanály označujú, koľko rôznych zvukových prúdov tvorí zvuk. Napríklad pre stereo zvuk s ľavým a pravým kanálom by boli 2 kanály. Pre 7.1 priestorový zvuk pre domáce kino by to bolo 8.
Veľkosť zvukových dát
Zvukové dáta sú relatívne veľké. Napríklad, zachytávanie nekomprimovaného 16-bitového zvuku pri 16KHz (dostatočná frekvencia pre modely na prevod reči na text) zaberá 32KB dát na každú sekundu zvuku:
- 16-bit znamená 2 bajty na vzorku (1 bajt má 8 bitov).
- 16KHz je 16,000 vzoriek za sekundu.
- 16,000 x 2 bajty = 32,000 bajtov za sekundu.
To sa môže zdať ako malé množstvo dát, ale ak používate mikrokontrolér s obmedzenou pamäťou, môže to byť veľa. Napríklad Wio Terminal má 192KB pamäte, a tá musí ukladať programový kód a premenné. Aj keby bol váš programový kód veľmi malý, nemohli by ste zachytiť viac ako 5 sekúnd zvuku.
Mikrokontroléry môžu pristupovať k dodatočnému úložisku, ako sú SD karty alebo flash pamäť. Pri budovaní IoT zariadenia, ktoré zachytáva zvuk, budete musieť zabezpečiť nielen to, že máte dodatočné úložisko, ale aj to, že váš kód zapisuje zachytený zvuk z mikrofónu priamo na toto úložisko, a pri odosielaní do cloudu streamuje z úložiska do webovej požiadavky. Týmto spôsobom sa môžete vyhnúť vyčerpaniu pamäte tým, že sa pokúsite držať celý blok zvukových dát v pamäti naraz.
Zachytávanie zvuku z vášho IoT zariadenia
Vaše IoT zariadenie môže byť pripojené k mikrofónu na zachytávanie zvuku, pripravené na prevod na text. Môže byť tiež pripojené k reproduktorom na výstup zvuku. V neskorších lekciách sa to použije na poskytovanie zvukovej spätnej väzby, ale je užitočné nastaviť reproduktory teraz na testovanie mikrofónu.
Úloha - nakonfigurujte váš mikrofón a reproduktory
Prejdite si príslušného sprievodcu na konfiguráciu mikrofónu a reproduktorov pre vaše IoT zariadenie:
- Arduino - Wio Terminal
- Jednodoskový počítač - Raspberry Pi
- Jednodoskový počítač - Virtuálne zariadenie
Úloha - zachytávanie zvuku
Prejdite si príslušného sprievodcu na zachytávanie zvuku na vašom IoT zariadení:
- Arduino - Wio Terminal
- Jednodoskový počítač - Raspberry Pi
- Jednodoskový počítač - Virtuálne zariadenie
Prevod reči na text
Prevod reči na text, alebo rozpoznávanie reči, zahŕňa použitie AI na prevod slov v zvukovom signáli na text.
Modely na rozpoznávanie reči
Na prevod reči na text sa vzorky zo zvukového signálu zoskupujú a posielajú do modelu strojového učenia založeného na Recurrent Neural Network (RNN). Tento typ modelu strojového učenia dokáže použiť predchádzajúce dáta na rozhodovanie o prichádzajúcich dátach. Napríklad RNN by mohla detegovať jeden blok zvukových vzoriek ako zvuk 'Hel', a keď dostane ďalší, ktorý považuje za zvuk 'lo', môže to skombinovať s predchádzajúcim zvukom, zistiť, že 'Hello' je platné slovo, a vybrať to ako výsledok.
Modely strojového učenia vždy prijímajú dáta rovnakej veľkosti. Klasifikátor obrázkov, ktorý ste vytvorili v predchádzajúcej lekcii, mení veľkosť obrázkov na pevnú veľkosť a spracováva ich. To isté platí pre modely reči, ktoré musia spracovávať pevne veľké zvukové bloky. Modely reči musia byť schopné kombinovať výstupy viacerých predpovedí, aby získali odpoveď, čo im umožňuje rozlíšiť medzi 'Hi' a 'Highway', alebo 'flock' a 'floccinaucinihilipilification'.
Modely reči sú tiež dostatočne pokročilé na to, aby pochopili kontext a mohli opraviť slová, ktoré detegujú, ako sa spracováva viac zvukov. Napríklad, ak poviete "I went to the shops to get two bananas and an apple too", použili by ste tri slová, ktoré znejú rovnako, ale sú napísané odlišne - to, two a too. Modely reči dokážu pochopiť kontext a použiť správny pravopis slova. 💁 Niektoré služby reči umožňujú prispôsobenie, aby lepšie fungovali v hlučnom prostredí, ako sú továrne, alebo s odvetvovo špecifickými slovami, ako sú chemické názvy. Tieto prispôsobenia sa trénujú poskytnutím vzorového zvuku a prepisu a fungujú pomocou transferového učenia, rovnako ako ste v predchádzajúcej lekcii trénovali klasifikátor obrázkov pomocou iba niekoľkých obrázkov.
Ochrana súkromia
Pri používaní prevodu reči na text v spotrebiteľskom IoT zariadení je ochrana súkromia mimoriadne dôležitá. Tieto zariadenia neustále počúvajú zvuk, takže ako spotrebiteľ nechcete, aby všetko, čo poviete, bolo odosielané do cloudu a prevádzané na text. Nielenže to spotrebuje veľa internetovej šírky pásma, ale má to aj obrovské dôsledky na ochranu súkromia, najmä keď niektorí výrobcovia inteligentných zariadení náhodne vyberajú zvuk na overenie ľuďmi voči vygenerovanému textu, aby zlepšili svoj model.
Chcete, aby vaše inteligentné zariadenie odosielalo zvuk do cloudu na spracovanie iba vtedy, keď ho používate, nie keď zachytí zvuk vo vašej domácnosti, ktorý môže zahŕňať súkromné stretnutia alebo intímne interakcie. Väčšina inteligentných zariadení funguje na základe aktivačného slova, kľúčovej frázy, ako je „Alexa“, „Hey Siri“ alebo „OK Google“, ktorá spôsobí, že zariadenie sa „prebudí“ a počúva, čo hovoríte, až kým nezistí pauzu vo vašej reči, čo naznačuje, že ste dokončili komunikáciu so zariadením.
🎓 Detekcia aktivačného slova sa tiež označuje ako rozpoznávanie kľúčových slov alebo vyhľadávanie kľúčových slov.
Tieto aktivačné slová sú detekované priamo na zariadení, nie v cloude. Tieto inteligentné zariadenia majú malé AI modely, ktoré bežia na zariadení, počúvajú aktivačné slovo a po jeho detekcii začnú streamovať zvuk do cloudu na rozpoznanie. Tieto modely sú veľmi špecializované a počúvajú iba aktivačné slovo.
💁 Niektoré technologické spoločnosti pridávajú do svojich zariadení viac ochrany súkromia a časť prevodu reči na text vykonávajú priamo na zariadení. Apple oznámil, že ako súčasť aktualizácií iOS a macOS v roku 2021 budú podporovať prevod reči na text na zariadení a zvládnu mnohé požiadavky bez potreby cloudu. To je možné vďaka výkonným procesorom v ich zariadeniach, ktoré dokážu spúšťať ML modely.
✅ Aké si myslíte, že sú dôsledky na ochranu súkromia a etiku pri ukladaní zvuku odoslaného do cloudu? Mal by byť tento zvuk ukladaný, a ak áno, ako? Myslíte si, že použitie nahrávok na účely presadzovania práva je dobrým kompromisom za stratu súkromia?
Detekcia aktivačného slova zvyčajne využíva techniku známu ako TinyML, čo znamená konverziu ML modelov tak, aby mohli bežať na mikrokontroléroch. Tieto modely sú malé a spotrebujú veľmi málo energie.
Aby ste sa vyhli zložitosti trénovania a používania modelu na detekciu aktivačného slova, inteligentný časovač, ktorý vytvárate v tejto lekcii, bude používať tlačidlo na zapnutie rozpoznávania reči.
💁 Ak si chcete vyskúšať vytvorenie modelu na detekciu aktivačného slova, ktorý bude bežať na Wio Terminal alebo Raspberry Pi, pozrite si tento návod na reagovanie na váš hlas od Edge Impulse. Ak chcete použiť svoj počítač na tento účel, môžete vyskúšať rýchly začiatok s vlastným kľúčovým slovom na Microsoft Docs.
Prevod reči na text
![]()
Rovnako ako pri klasifikácii obrázkov v predchádzajúcom projekte, existujú predpripravené AI služby, ktoré dokážu previesť reč ako zvukový súbor na text. Jednou z takýchto služieb je Speech Service, ktorá je súčasťou Cognitive Services, predpripravených AI služieb, ktoré môžete použiť vo svojich aplikáciách.
Úloha - nakonfigurujte AI zdroj pre reč
-
Vytvorte skupinu zdrojov pre tento projekt s názvom
smart-timer. -
Použite nasledujúci príkaz na vytvorenie bezplatného zdroja pre reč:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Nahraďte
<location>miestom, ktoré ste použili pri vytváraní skupiny zdrojov. -
Na prístup k zdroju reči z vášho kódu budete potrebovať API kľúč. Spustite nasledujúci príkaz na získanie kľúča:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableSkopírujte si jeden z kľúčov.
Úloha - prevod reči na text
Postupujte podľa príslušného návodu na prevod reči na text na vašom IoT zariadení:
- Arduino - Wio Terminal
- Jednodoskový počítač - Raspberry Pi
- Jednodoskový počítač - Virtuálne zariadenie
🚀 Výzva
Rozpoznávanie reči existuje už dlho a neustále sa zlepšuje. Preskúmajte aktuálne schopnosti a porovnajte, ako sa vyvíjali v priebehu času, vrátane toho, aká presná je strojová transkripcia v porovnaní s ľudskou.
Čo si myslíte, že prinesie budúcnosť rozpoznávania reči?
Kvíz po prednáške
Prehľad a samoštúdium
- Prečítajte si o rôznych typoch mikrofónov a o tom, ako fungujú, v článku aký je rozdiel medzi dynamickými a kondenzátorovými mikrofónmi na Musician's HQ.
- Prečítajte si viac o službe reči v Cognitive Services v dokumentácii o službe reči na Microsoft Docs.
- Prečítajte si o vyhľadávaní kľúčových slov v dokumentácii o rozpoznávaní kľúčových slov na Microsoft Docs.
Zadanie
Upozornenie:
Tento dokument bol preložený pomocou služby AI prekladu Co-op Translator. Aj keď sa snažíme o presnosť, prosím, berte na vedomie, že automatizované preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho pôvodnom jazyku by mal byť považovaný za autoritatívny zdroj. Pre kritické informácie sa odporúča profesionálny ľudský preklad. Nie sme zodpovední za akékoľvek nedorozumenia alebo nesprávne interpretácie vyplývajúce z použitia tohto prekladu.