|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
Ustaw timer i udziel odpowiedzi głosowej
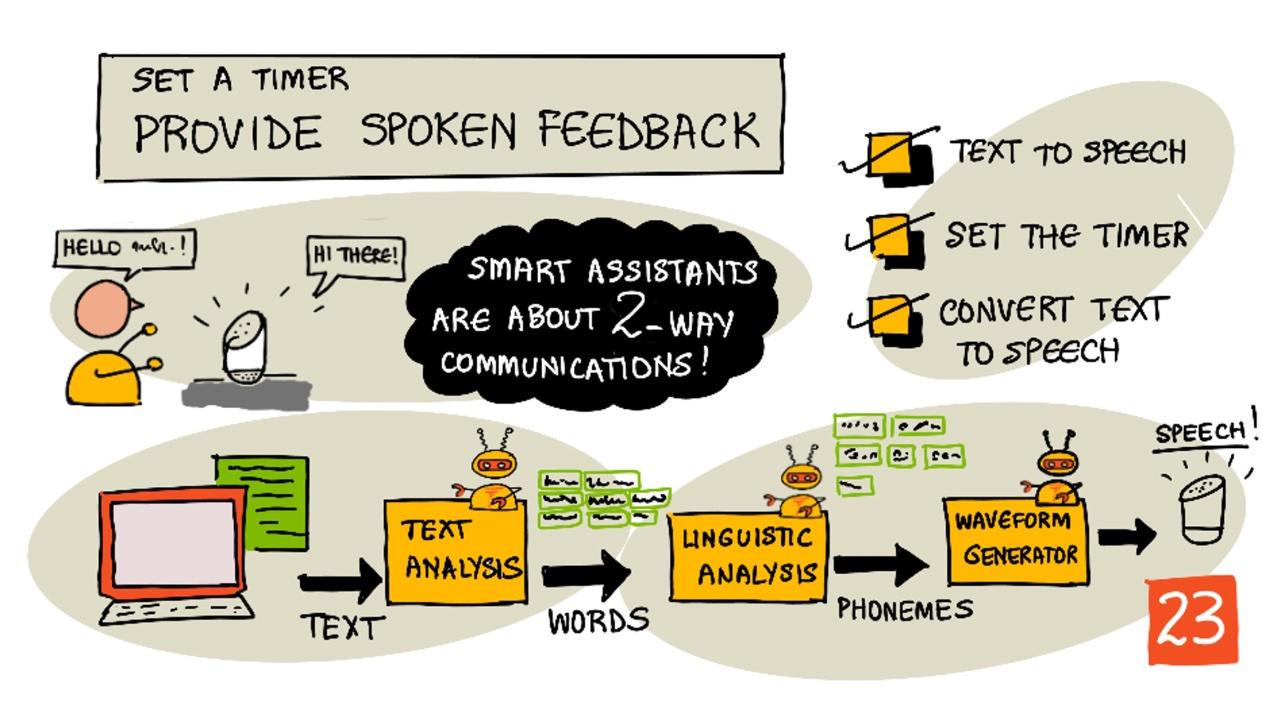
Szkic autorstwa Nitya Narasimhan. Kliknij obrazek, aby zobaczyć większą wersję.
Quiz przed wykładem
Wprowadzenie
Inteligentni asystenci nie są urządzeniami komunikacyjnymi działającymi w jedną stronę. Rozmawiasz z nimi, a one odpowiadają:
"Alexa, ustaw timer na 3 minuty"
"Ok, Twój timer został ustawiony na 3 minuty"
W ostatnich dwóch lekcjach nauczyłeś się, jak przekształcić mowę w tekst, a następnie wyodrębnić z tego tekstu polecenie ustawienia timera. W tej lekcji dowiesz się, jak ustawić timer na urządzeniu IoT, odpowiedzieć użytkownikowi słowami potwierdzającymi ustawienie timera oraz powiadomić go, gdy timer się zakończy.
W tej lekcji omówimy:
Tekst na mowę
Tekst na mowę, jak sama nazwa wskazuje, to proces przekształcania tekstu w dźwięk zawierający wypowiedziane słowa. Podstawowa zasada polega na rozłożeniu słów w tekście na ich składowe dźwięki (zwane fonemami) i połączeniu tych dźwięków w całość, używając nagrań audio lub dźwięków generowanych przez modele AI.

Systemy tekst na mowę zazwyczaj składają się z 3 etapów:
- Analiza tekstu
- Analiza lingwistyczna
- Generowanie fali dźwiękowej
Analiza tekstu
Analiza tekstu polega na przekształceniu dostarczonego tekstu w słowa, które mogą być użyte do generowania mowy. Na przykład, jeśli konwertujesz "Hello world", nie jest potrzebna analiza tekstu, ponieważ te dwa słowa można bezpośrednio przekształcić w mowę. Jeśli jednak masz "1234", może być konieczne przekształcenie tego w "Jeden tysiąc dwieście trzydzieści cztery" lub "Jeden, dwa, trzy, cztery" w zależności od kontekstu. W przypadku "Mam 1234 jabłka" będzie to "Jeden tysiąc dwieście trzydzieści cztery", ale w przypadku "Dziecko policzyło 1234" będzie to "Jeden, dwa, trzy, cztery".
Słowa różnią się nie tylko w zależności od języka, ale także od lokalizacji tego języka. Na przykład w amerykańskim angielskim 120 to "One hundred twenty", a w brytyjskim angielskim "One hundred and twenty", z użyciem "and" po setkach.
✅ Inne przykłady wymagające analizy tekstu to "in" jako skrót od cali oraz "st" jako skrót od świętego lub ulicy. Czy potrafisz wymyślić inne przykłady w swoim języku, gdzie słowa są niejednoznaczne bez kontekstu?
Po zdefiniowaniu słów są one przesyłane do analizy lingwistycznej.
Analiza lingwistyczna
Analiza lingwistyczna rozkłada słowa na fonemy. Fonemy zależą nie tylko od użytych liter, ale także od innych liter w słowie. Na przykład w języku angielskim dźwięk 'a' w 'car' i 'care' jest różny. Język angielski ma 44 różne fonemy dla 26 liter alfabetu, niektóre wspólne dla różnych liter, na przykład ten sam fonem używany na początku 'circle' i 'serpent'.
✅ Zrób badania: Jakie są fonemy w Twoim języku?
Po przekształceniu słów w fonemy, fonemy te potrzebują dodatkowych danych wspierających intonację, dostosowując ton lub długość w zależności od kontekstu. Na przykład w języku angielskim podwyższenie tonu może przekształcić zdanie w pytanie, podnosząc ton ostatniego słowa.
Na przykład - zdanie "Masz jabłko" jest stwierdzeniem, że masz jabłko. Jeśli ton wzrasta na końcu, zwiększając się dla słowa jabłko, staje się pytaniem "Masz jabłko?", pytając, czy masz jabłko. Analiza lingwistyczna musi użyć znaku zapytania na końcu, aby zdecydować o podwyższeniu tonu.
Po wygenerowaniu fonemów są one przesyłane do generowania fali dźwiękowej w celu uzyskania wyjścia audio.
Generowanie fali dźwiękowej
Pierwsze elektroniczne systemy tekst na mowę używały pojedynczych nagrań audio dla każdego fonemu, co prowadziło do bardzo monotonnych, robotycznych głosów. Analiza lingwistyczna generowała fonemy, które były ładowane z bazy danych dźwięków i łączone w całość, aby stworzyć dźwięk.
✅ Zrób badania: Znajdź nagrania audio z wczesnych systemów syntezy mowy. Porównaj je z nowoczesną syntezą mowy, taką jak ta używana w inteligentnych asystentach.
Nowoczesne generowanie fali dźwiękowej wykorzystuje modele ML zbudowane przy użyciu głębokiego uczenia (bardzo dużych sieci neuronowych działających podobnie do neuronów w mózgu), aby tworzyć bardziej naturalnie brzmiące głosy, które mogą być nieodróżnialne od ludzkich.
💁 Niektóre z tych modeli ML mogą być ponownie trenowane za pomocą transfer learning, aby brzmieć jak prawdziwi ludzie. Oznacza to, że używanie głosu jako systemu bezpieczeństwa, co coraz częściej próbują robić banki, nie jest już dobrym pomysłem, ponieważ każdy, kto ma nagranie kilku minut Twojego głosu, może Cię podszyć.
Te duże modele ML są trenowane, aby łączyć wszystkie trzy kroki w kompleksowe systemy syntezy mowy.
Ustawienie timera
Aby ustawić timer, Twoje urządzenie IoT musi wywołać punkt końcowy REST, który stworzyłeś za pomocą kodu serverless, a następnie użyć wynikowej liczby sekund do ustawienia timera.
Zadanie - wywołanie funkcji serverless w celu uzyskania czasu timera
Postępuj zgodnie z odpowiednim przewodnikiem, aby wywołać punkt końcowy REST z Twojego urządzenia IoT i ustawić timer na wymagany czas:
Konwersja tekstu na mowę
Ta sama usługa mowy, której używałeś do konwersji mowy na tekst, może być użyta do konwersji tekstu z powrotem na mowę, którą można odtworzyć przez głośnik na Twoim urządzeniu IoT. Tekst do konwersji jest przesyłany do usługi mowy wraz z typem wymaganego dźwięku (takim jak częstotliwość próbkowania), a dane binarne zawierające dźwięk są zwracane.
Podczas wysyłania tego żądania używasz Speech Synthesis Markup Language (SSML), języka znaczników opartego na XML dla aplikacji syntezy mowy. Określa on nie tylko tekst do konwersji, ale także język tekstu, głos do użycia, a nawet może być używany do definiowania szybkości, głośności i tonu dla niektórych lub wszystkich słów w tekście.
Na przykład, ten SSML definiuje żądanie konwersji tekstu "Twój timer na 3 minuty i 5 sekund został ustawiony" na mowę przy użyciu brytyjskiego głosu angielskiego en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 Większość systemów tekst na mowę ma wiele głosów dla różnych języków, z odpowiednimi akcentami, takimi jak brytyjski głos angielski z angielskim akcentem i nowozelandzki głos angielski z nowozelandzkim akcentem.
Zadanie - konwersja tekstu na mowę
Przejdź przez odpowiedni przewodnik, aby skonwertować tekst na mowę za pomocą swojego urządzenia IoT:
- Arduino - Wio Terminal
- Komputer jednopłytkowy - Raspberry Pi
- Komputer jednopłytkowy - Wirtualne urządzenie
🚀 Wyzwanie
SSML ma sposoby na zmianę sposobu wypowiadania słów, takie jak dodanie nacisku na określone słowa, dodanie pauz lub zmiana tonu. Wypróbuj niektóre z tych funkcji, wysyłając różne SSML z Twojego urządzenia IoT i porównując wyniki. Możesz przeczytać więcej o SSML, w tym o tym, jak zmienić sposób wypowiadania słów, w specyfikacji Speech Synthesis Markup Language (SSML) Version 1.1 od World Wide Web Consortium.
Quiz po wykładzie
Przegląd i samodzielna nauka
- Przeczytaj więcej o syntezie mowy na stronie o syntezie mowy na Wikipedii
- Przeczytaj więcej o sposobach, w jakie przestępcy wykorzystują syntezę mowy do kradzieży w historii o fałszywych głosach 'pomagających cyberprzestępcom kraść pieniądze' na BBC News
- Dowiedz się więcej o zagrożeniach dla aktorów głosowych wynikających z syntezowanych wersji ich głosów w artykule na Vice o pozwie TikTok, który podkreśla, jak AI szkodzi aktorom głosowym
Zadanie
Zastrzeżenie:
Ten dokument został przetłumaczony za pomocą usługi tłumaczenia AI Co-op Translator. Chociaż dokładamy wszelkich starań, aby tłumaczenie było precyzyjne, prosimy pamiętać, że automatyczne tłumaczenia mogą zawierać błędy lub nieścisłości. Oryginalny dokument w jego rodzimym języku powinien być uznawany za autorytatywne źródło. W przypadku informacji o kluczowym znaczeniu zaleca się skorzystanie z profesjonalnego tłumaczenia przez człowieka. Nie ponosimy odpowiedzialności za jakiekolwiek nieporozumienia lub błędne interpretacje wynikające z użycia tego tłumaczenia.