|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Trenuj detektor jakości owoców
Szkic autorstwa Nitya Narasimhan. Kliknij obraz, aby zobaczyć większą wersję.
Ten film przedstawia przegląd usługi Azure Custom Vision, która zostanie omówiona w tej lekcji.

🎥 Kliknij obraz powyżej, aby obejrzeć film
Quiz przed lekcją
Wprowadzenie
Niedawny rozwój Sztucznej Inteligencji (AI) i Uczenia Maszynowego (ML) dostarcza dzisiejszym programistom szerokiego wachlarza możliwości. Modele ML mogą być trenowane do rozpoznawania różnych rzeczy na obrazach, w tym niedojrzałych owoców, co może być wykorzystane w urządzeniach IoT do sortowania produktów podczas zbiorów lub w trakcie przetwarzania w fabrykach czy magazynach.
W tej lekcji dowiesz się o klasyfikacji obrazów – wykorzystaniu modeli ML do rozróżniania obrazów różnych obiektów. Nauczysz się, jak trenować klasyfikator obrazów, aby odróżniał owoce dobrej jakości od złej, np. niedojrzałe, przejrzałe, obite lub zgniłe.
W tej lekcji omówimy:
- Wykorzystanie AI i ML do sortowania żywności
- Klasyfikacja obrazów za pomocą Uczenia Maszynowego
- Trenowanie klasyfikatora obrazów
- Testowanie klasyfikatora obrazów
- Ponowne trenowanie klasyfikatora obrazów
Wykorzystanie AI i ML do sortowania żywności
Wyżywienie globalnej populacji jest trudne, zwłaszcza po cenach, które sprawiają, że jedzenie jest dostępne dla wszystkich. Jednym z największych kosztów jest praca, dlatego rolnicy coraz częściej sięgają po automatyzację i narzędzia takie jak IoT, aby obniżyć koszty pracy. Zbiory ręczne są pracochłonne (i często wyczerpujące fizycznie), dlatego są zastępowane przez maszyny, zwłaszcza w bogatszych krajach. Mimo oszczędności wynikających z użycia maszyn, istnieje wada – brak możliwości sortowania żywności podczas zbiorów.
Nie wszystkie plony dojrzewają równomiernie. Na przykład pomidory mogą mieć jeszcze zielone owoce na krzaku, gdy większość jest gotowa do zbioru. Chociaż zbieranie ich zbyt wcześnie jest marnotrawstwem, dla rolnika jest taniej i łatwiej zebrać wszystko za pomocą maszyn, a niedojrzałe owoce wyrzucić później.
✅ Przyjrzyj się różnym owocom lub warzywom, które rosną w pobliżu – na farmach, w ogrodzie lub w sklepach. Czy wszystkie są w tym samym stopniu dojrzałe, czy widzisz różnice?
Wzrost automatyzacji zbiorów przeniósł sortowanie produktów z pola do fabryki. Żywność trafiała na długie taśmy przenośnikowe, gdzie zespoły ludzi usuwały produkty niespełniające standardów jakości. Zbiory były tańsze dzięki maszynom, ale nadal istniał koszt ręcznego sortowania żywności.
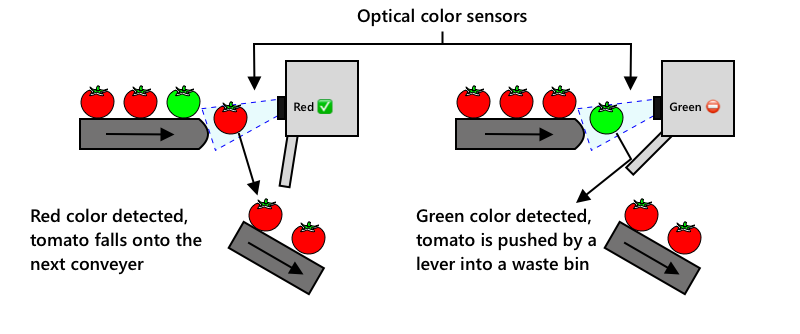
Kolejną ewolucją było wykorzystanie maszyn do sortowania, wbudowanych w kombajny lub używanych w zakładach przetwórczych. Pierwsza generacja tych maszyn używała czujników optycznych do wykrywania kolorów, sterując siłownikami, które przerzucały zielone pomidory do kosza na odpady za pomocą dźwigni lub strumieni powietrza, pozostawiając czerwone pomidory na taśmach przenośnikowych.
W tym filmie, gdy pomidory spadają z jednej taśmy na drugą, zielone pomidory są wykrywane i przerzucane do kosza za pomocą dźwigni.
✅ Jakie warunki musiałyby być spełnione w fabryce lub na polu, aby te czujniki optyczne działały poprawnie?
Najnowocześniejsze maszyny sortujące wykorzystują AI i ML, używając modeli trenowanych do rozróżniania dobrych produktów od złych, nie tylko na podstawie oczywistych różnic kolorystycznych, takich jak zielone vs czerwone pomidory, ale także subtelniejszych różnic w wyglądzie, które mogą wskazywać na choroby lub obicia.
Klasyfikacja obrazów za pomocą Uczenia Maszynowego
Tradycyjne programowanie polega na tym, że bierzesz dane, stosujesz do nich algorytm i otrzymujesz wynik. Na przykład w poprzednim projekcie używałeś współrzędnych GPS i geofencing, stosując algorytm dostarczony przez Azure Maps, aby uzyskać wynik, czy punkt znajduje się wewnątrz, czy na zewnątrz geofencing. Wprowadzasz więcej danych, otrzymujesz więcej wyników.
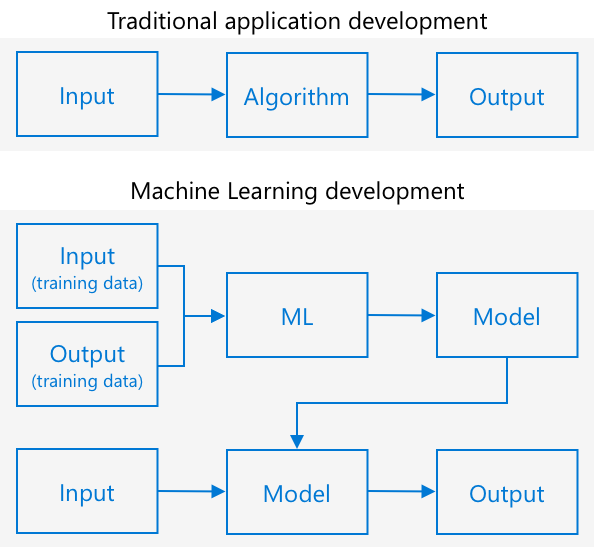
Uczenie maszynowe odwraca ten proces – zaczynasz od danych i znanych wyników, a algorytm uczenia maszynowego uczy się na podstawie tych danych. Następnie możesz użyć wytrenowanego algorytmu, zwanego modelem uczenia maszynowego lub modelem, aby wprowadzić nowe dane i uzyskać nowe wyniki.
🎓 Proces uczenia się algorytmu uczenia maszynowego na podstawie danych nazywa się trenowaniem. Dane wejściowe i znane wyniki nazywane są danymi treningowymi.
Na przykład możesz dostarczyć modelowi miliony zdjęć niedojrzałych bananów jako dane treningowe z wynikiem niedojrzały, oraz miliony zdjęć dojrzałych bananów z wynikiem dojrzały. Algorytm ML stworzy model na podstawie tych danych. Następnie możesz dostarczyć temu modelowi nowe zdjęcie banana, a on przewidzi, czy jest dojrzały, czy niedojrzały.
🎓 Wyniki modeli ML nazywane są przewidywaniami.

Modele ML nie dają odpowiedzi binarnej, zamiast tego podają prawdopodobieństwa. Na przykład model może otrzymać zdjęcie banana i przewidzieć dojrzały na poziomie 99,7% oraz niedojrzały na poziomie 0,3%. Twój kod wybierze najlepsze przewidywanie i zdecyduje, że banan jest dojrzały.
Model ML używany do wykrywania obrazów, takich jak ten, nazywa się klasyfikatorem obrazów – otrzymuje oznaczone obrazy, a następnie klasyfikuje nowe obrazy na podstawie tych oznaczeń.
💁 To uproszczenie, istnieje wiele innych sposobów trenowania modeli, które nie zawsze wymagają oznaczonych wyników, takich jak uczenie nienadzorowane. Jeśli chcesz dowiedzieć się więcej o ML, sprawdź ML dla początkujących, 24-lekcyjny kurs o Uczeniu Maszynowym.
Trenowanie klasyfikatora obrazów
Aby skutecznie wytrenować klasyfikator obrazów, potrzebujesz milionów obrazów. Jak się okazuje, gdy już masz klasyfikator obrazów wytrenowany na milionach lub miliardach różnych obrazów, możesz go ponownie wykorzystać i wytrenować na małym zestawie obrazów, uzyskując świetne wyniki dzięki procesowi zwanemu transfer learning.
🎓 Transfer learning to proces przenoszenia wiedzy z istniejącego modelu ML do nowego modelu na podstawie nowych danych.
Gdy klasyfikator obrazów został wytrenowany na szerokiej gamie obrazów, jego wewnętrzne mechanizmy są świetne w rozpoznawaniu kształtów, kolorów i wzorów. Transfer learning pozwala modelowi wykorzystać to, czego już nauczył się w rozpoznawaniu części obrazu, aby rozpoznawać nowe obrazy.
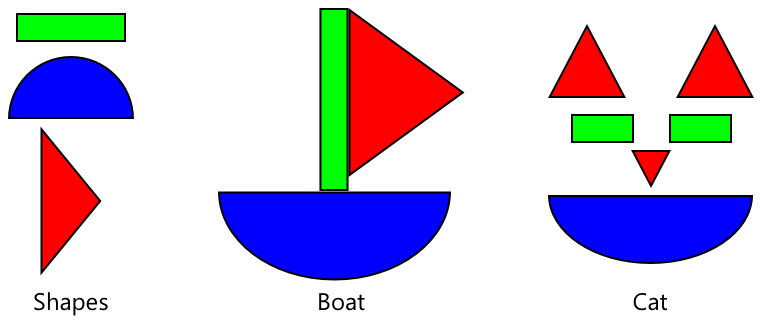
Możesz to porównać do książek dla dzieci o kształtach, gdzie po rozpoznaniu półkola, prostokąta i trójkąta możesz rozpoznać żaglówkę lub kota w zależności od konfiguracji tych kształtów. Klasyfikator obrazów rozpoznaje kształty, a transfer learning uczy go, jaka kombinacja tworzy łódkę, kota – lub dojrzałego banana.
Istnieje wiele narzędzi, które mogą Ci w tym pomóc, w tym usługi w chmurze, które umożliwiają trenowanie modelu, a następnie korzystanie z niego za pośrednictwem API internetowego.
💁 Trenowanie tych modeli wymaga dużej mocy obliczeniowej, zwykle za pomocą procesorów graficznych (GPU). Ten sam specjalistyczny sprzęt, który sprawia, że gry na Twoim Xboxie wyglądają niesamowicie, może być również używany do trenowania modeli uczenia maszynowego. Dzięki chmurze możesz wynająć czas na potężnych komputerach z GPU, aby trenować te modele, uzyskując dostęp do potrzebnej mocy obliczeniowej tylko na czas, który jest Ci potrzebny.
Custom Vision
Custom Vision to narzędzie w chmurze do trenowania klasyfikatorów obrazów. Pozwala trenować klasyfikator, używając jedynie niewielkiej liczby obrazów. Możesz przesyłać obrazy przez portal internetowy, API lub SDK, przypisując każdemu obrazowi tag, który określa jego klasyfikację. Następnie trenujesz model i testujesz go, aby sprawdzić, jak dobrze działa. Gdy jesteś zadowolony z modelu, możesz opublikować jego wersje, które można uzyskać za pośrednictwem API internetowego lub SDK.
![]()
💁 Możesz wytrenować model Custom Vision, używając zaledwie 5 obrazów na klasyfikację, ale więcej to lepiej. Lepsze wyniki uzyskasz, mając co najmniej 30 obrazów.
Custom Vision jest częścią gamy narzędzi AI od Microsoftu, zwanych Cognitive Services. Są to narzędzia AI, które można używać bez trenowania lub z niewielką ilością trenowania. Obejmują one rozpoznawanie mowy i tłumaczenie, rozumienie języka i analizę obrazów. Są dostępne w ramach darmowego poziomu jako usługi w Azure.
💁 Darmowy poziom jest wystarczający, aby stworzyć model, wytrenować go, a następnie używać go do pracy deweloperskiej. Możesz przeczytać o limitach darmowego poziomu na stronie Custom Vision Limits and quotas na Microsoft docs.
Zadanie – utwórz zasób Cognitive Services
Aby korzystać z Custom Vision, najpierw musisz utworzyć dwa zasoby Cognitive Services w Azure za pomocą Azure CLI: jeden do trenowania Custom Vision, a drugi do przewidywań Custom Vision.
-
Utwórz grupę zasobów dla tego projektu o nazwie
fruit-quality-detector. -
Użyj poniższego polecenia, aby utworzyć darmowy zasób do trenowania Custom Vision:
az cognitiveservices account create --name fruit-quality-detector-training \ --resource-group fruit-quality-detector \ --kind CustomVision.Training \ --sku F0 \ --yes \ --location <location>Zastąp
<location>lokalizacją, której użyłeś podczas tworzenia grupy zasobów.To polecenie utworzy zasób do trenowania Custom Vision w Twojej grupie zasobów. Będzie on nazywał się
fruit-quality-detector-trainingi używał SKUF0, które jest darmowym poziomem. Opcja--yesoznacza, że zgadzasz się na warunki korzystania z Cognitive Services.
💁 Użyj SKU
S0, jeśli masz już darmowe konto korzystające z dowolnych Cognitive Services.
-
Użyj poniższego polecenia, aby utworzyć darmowy zasób do przewidywań Custom Vision:
az cognitiveservices account create --name fruit-quality-detector-prediction \ --resource-group fruit-quality-detector \ --kind CustomVision.Prediction \ --sku F0 \ --yes \ --location <location>Zastąp
<location>lokalizacją, której użyłeś podczas tworzenia grupy zasobów.To polecenie utworzy zasób do przewidywań Custom Vision w Twojej grupie zasobów. Będzie on nazywał się
fruit-quality-detector-predictioni używał SKUF0, które jest darmowym poziomem. Opcja--yesoznacza, że zgadzasz się na warunki korzystania z Cognitive Services.
Zadanie – utwórz projekt klasyfikatora obrazów
-
Otwórz portal Custom Vision na CustomVision.ai i zaloguj się za pomocą konta Microsoft, którego używasz do swojego konta Azure.
-
Postępuj zgodnie z sekcją create a new Project w quickstart na Microsoft docs, aby utworzyć nowy projekt Custom Vision. Interfejs użytkownika może się zmieniać, a te dokumenty są zawsze najbardziej aktualnym źródłem informacji.
Nazwij swój projekt
fruit-quality-detector.Podczas tworzenia projektu upewnij się, że używasz zasobu
fruit-quality-detector-training, który utworzyłeś wcześniej. Wybierz typ projektu Classification, typ klasyfikacji Multiclass oraz domenę Food.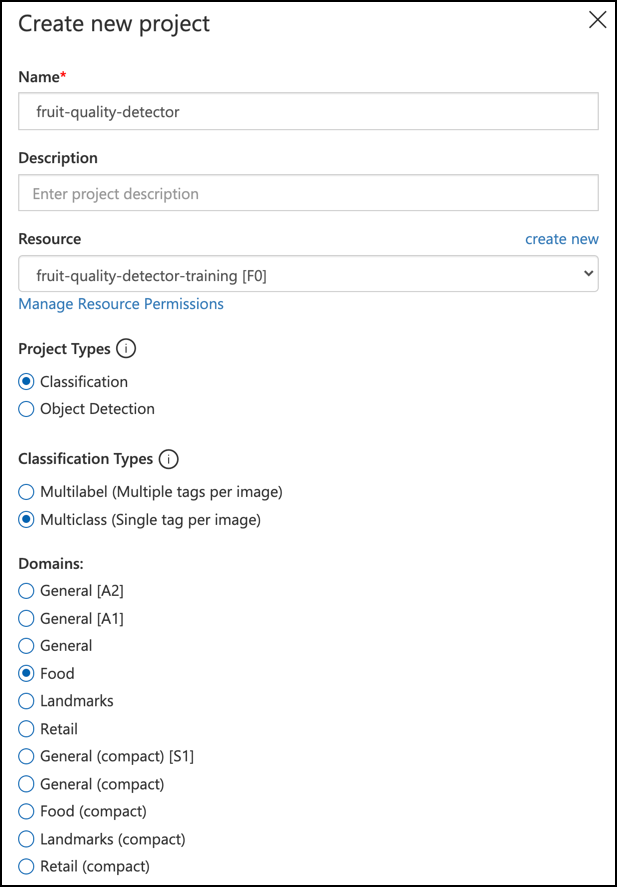
✅ Poświęć trochę czasu na zapoznanie się z interfejsem użytkownika Custom Vision dla swojego klasyfikatora obrazów.
Zadanie – trenuj swój projekt klasyfikatora obrazów
Aby wytrenować klasyfikator obrazów, będziesz potrzebować wielu zdjęć owoców, zarówno dobrej, jak i złej jakości, aby oznaczyć je jako dobre i złe, na przykład dojrzałe i przejrzałe banany. 💁 Te klasyfikatory mogą klasyfikować obrazy wszystkiego, więc jeśli nie masz pod ręką owoców o różnej jakości, możesz użyć dwóch różnych rodzajów owoców albo kotów i psów! Idealnie każde zdjęcie powinno przedstawiać tylko owoc, z jednolitym tłem lub różnorodnymi tłami. Upewnij się, że w tle nie ma niczego, co wskazywałoby na dojrzałość lub niedojrzałość owocu.
💁 Ważne jest, aby unikać specyficznych teł lub przedmiotów niezwiązanych z klasyfikowanym obiektem dla każdego tagu. W przeciwnym razie klasyfikator może opierać swoje decyzje na tle. Istniał klasyfikator raka skóry, który był trenowany na zdjęciach znamion – zarówno normalnych, jak i rakowych. Na zdjęciach znamion rakowych zawsze znajdowały się linijki do pomiaru ich rozmiaru. Okazało się, że klasyfikator był niemal w 100% skuteczny w rozpoznawaniu linijek na zdjęciach, a nie rakowych znamion.
Klasyfikatory obrazów działają na bardzo niskiej rozdzielczości. Na przykład Custom Vision może przyjmować obrazy treningowe i predykcyjne o rozdzielczości do 10240x10240, ale trenuje i uruchamia model na obrazach o rozdzielczości 227x227. Większe obrazy są zmniejszane do tego rozmiaru, więc upewnij się, że klasyfikowany obiekt zajmuje dużą część obrazu. W przeciwnym razie może być zbyt mały w zmniejszonym obrazie używanym przez klasyfikator.
-
Zbierz zdjęcia dla swojego klasyfikatora. Potrzebujesz co najmniej 5 zdjęć dla każdej etykiety, aby wytrenować klasyfikator, ale im więcej, tym lepiej. Potrzebujesz również kilku dodatkowych zdjęć do przetestowania klasyfikatora. Wszystkie te zdjęcia powinny przedstawiać różne ujęcia tego samego obiektu. Na przykład:
-
Używając 2 dojrzałych bananów, zrób kilka zdjęć każdego z nich z różnych kątów, wykonując co najmniej 7 zdjęć (5 do treningu, 2 do testów), ale najlepiej więcej.

-
Powtórz ten sam proces, używając 2 niedojrzałych bananów.
Powinieneś mieć co najmniej 10 zdjęć treningowych, z co najmniej 5 dojrzałymi i 5 niedojrzałymi, oraz 4 zdjęcia testowe – 2 dojrzałe, 2 niedojrzałe. Twoje zdjęcia powinny być w formacie png lub jpeg, o rozmiarze mniejszym niż 6 MB. Jeśli tworzysz je na przykład za pomocą iPhone'a, mogą być to obrazy w wysokiej rozdzielczości w formacie HEIC, które trzeba będzie przekonwertować i ewentualnie zmniejszyć. Im więcej zdjęć, tym lepiej, i powinieneś mieć podobną liczbę zdjęć dojrzałych i niedojrzałych.
Jeśli nie masz zarówno dojrzałych, jak i niedojrzałych owoców, możesz użyć różnych owoców lub dowolnych dwóch dostępnych obiektów. Możesz także znaleźć przykładowe obrazy w folderze images przedstawiające dojrzałe i niedojrzałe banany, które możesz wykorzystać.
-
-
Postępuj zgodnie z sekcją przesyłania i tagowania obrazów w szybkim przewodniku po tworzeniu klasyfikatora w dokumentacji Microsoft, aby przesłać swoje zdjęcia treningowe. Oznacz dojrzałe owoce jako
ripe, a niedojrzałe jakounripe.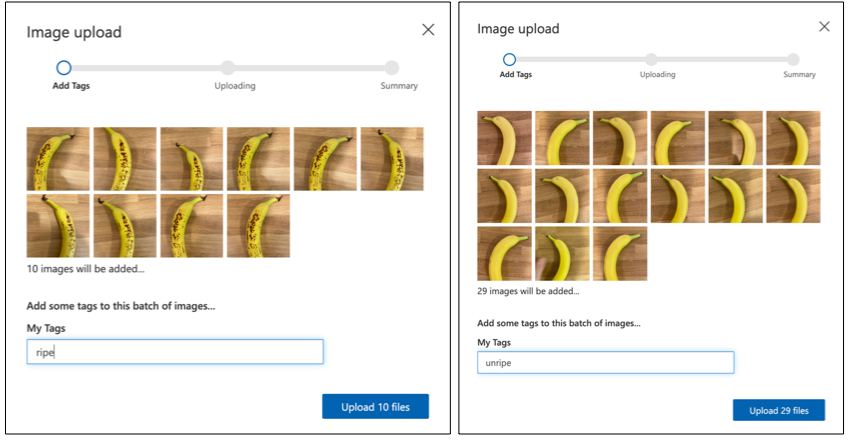
-
Postępuj zgodnie z sekcją trenowania klasyfikatora w szybkim przewodniku po tworzeniu klasyfikatora w dokumentacji Microsoft, aby wytrenować klasyfikator obrazów na przesłanych zdjęciach.
Otrzymasz możliwość wyboru typu treningu. Wybierz Quick Training.
Klasyfikator rozpocznie trening. Proces ten zajmie kilka minut.
🍌 Jeśli zdecydujesz się zjeść swoje owoce podczas trenowania klasyfikatora, upewnij się, że masz wystarczającą liczbę zdjęć do testów!
Przetestuj swój klasyfikator obrazów
Gdy klasyfikator zostanie wytrenowany, możesz go przetestować, dostarczając nowe zdjęcie do klasyfikacji.
Zadanie – przetestuj swój klasyfikator obrazów
-
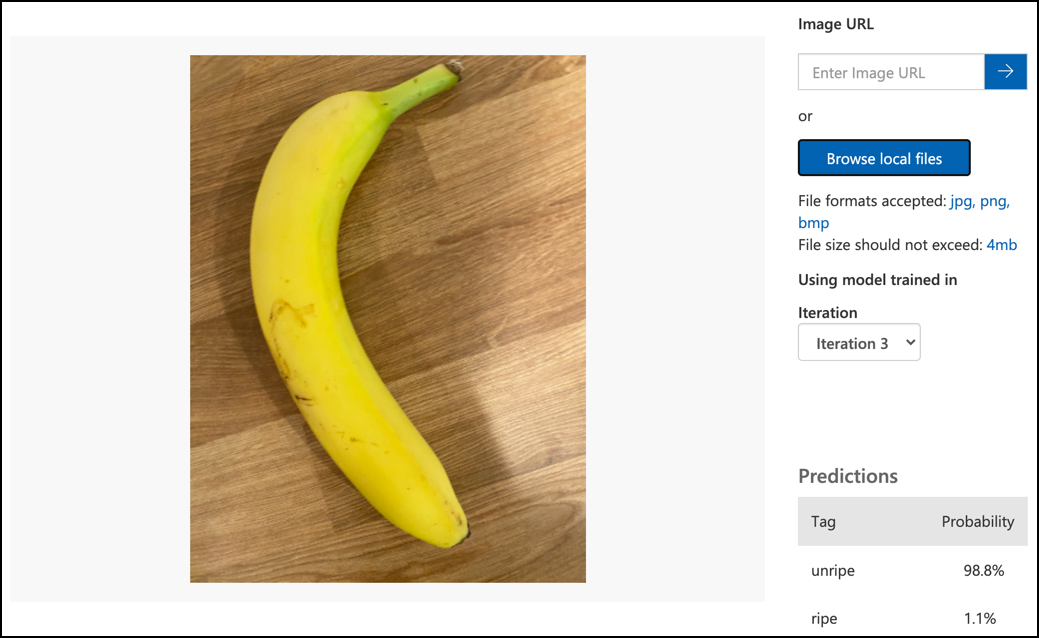
Postępuj zgodnie z dokumentacją testowania modelu w dokumentacji Microsoft, aby przetestować swój klasyfikator obrazów. Użyj zdjęć testowych, które stworzyłeś wcześniej, a nie tych, które wykorzystałeś do treningu.
-
Wypróbuj wszystkie zdjęcia testowe, do których masz dostęp, i zaobserwuj prawdopodobieństwa.
Ponowne trenowanie klasyfikatora obrazów
Podczas testowania klasyfikatora może się okazać, że wyniki nie są zgodne z oczekiwaniami. Klasyfikatory obrazów wykorzystują uczenie maszynowe do przewidywania, co znajduje się na zdjęciu, na podstawie prawdopodobieństw, że określone cechy obrazu odpowiadają danej etykiecie. Klasyfikator nie rozumie, co znajduje się na zdjęciu – nie wie, czym jest banan ani co sprawia, że banan to banan, a nie łódź. Możesz poprawić swój klasyfikator, ponownie go trenując na zdjęciach, które zostały źle sklasyfikowane.
Za każdym razem, gdy dokonujesz predykcji za pomocą opcji szybkiego testu, obraz i wyniki są przechowywane. Możesz użyć tych zdjęć do ponownego trenowania modelu.
Zadanie – ponownie wytrenuj swój klasyfikator obrazów
-
Postępuj zgodnie z dokumentacją dotyczącą używania przewidywanych obrazów do trenowania w dokumentacji Microsoft, aby ponownie wytrenować swój model, używając poprawnej etykiety dla każdego zdjęcia.
-
Po ponownym wytrenowaniu modelu przetestuj go na nowych zdjęciach.
🚀 Wyzwanie
Jak myślisz, co by się stało, gdybyś użył zdjęcia truskawki w modelu wytrenowanym na bananach, zdjęcia dmuchanego banana, osoby w kostiumie banana, a nawet żółtej postaci z kreskówki, takiej jak ktoś z Simpsonów?
Wypróbuj to i zobacz, jakie będą przewidywania. Możesz znaleźć zdjęcia do przetestowania, korzystając z wyszukiwarki obrazów Bing.
Quiz po wykładzie
Przegląd i samodzielna nauka
- Podczas trenowania klasyfikatora zauważyłeś wartości Precision, Recall i AP, które oceniają utworzony model. Przeczytaj, czym są te wartości, korzystając z sekcji oceny klasyfikatora w szybkim przewodniku po tworzeniu klasyfikatora w dokumentacji Microsoft.
- Przeczytaj, jak poprawić swój klasyfikator, korzystając z poradnika poprawy modelu Custom Vision w dokumentacji Microsoft.
Zadanie
Wytrenuj klasyfikator dla wielu owoców i warzyw
Zastrzeżenie:
Ten dokument został przetłumaczony za pomocą usługi tłumaczenia AI Co-op Translator. Chociaż dokładamy wszelkich starań, aby tłumaczenie było precyzyjne, prosimy pamiętać, że automatyczne tłumaczenia mogą zawierać błędy lub nieścisłości. Oryginalny dokument w jego rodzimym języku powinien być uznawany za autorytatywne źródło. W przypadku informacji o kluczowym znaczeniu zaleca się skorzystanie z profesjonalnego tłumaczenia przez człowieka. Nie ponosimy odpowiedzialności za jakiekolwiek nieporozumienia lub błędne interpretacje wynikające z użycia tego tłumaczenia.