|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
Stel een timer in en geef gesproken feedback
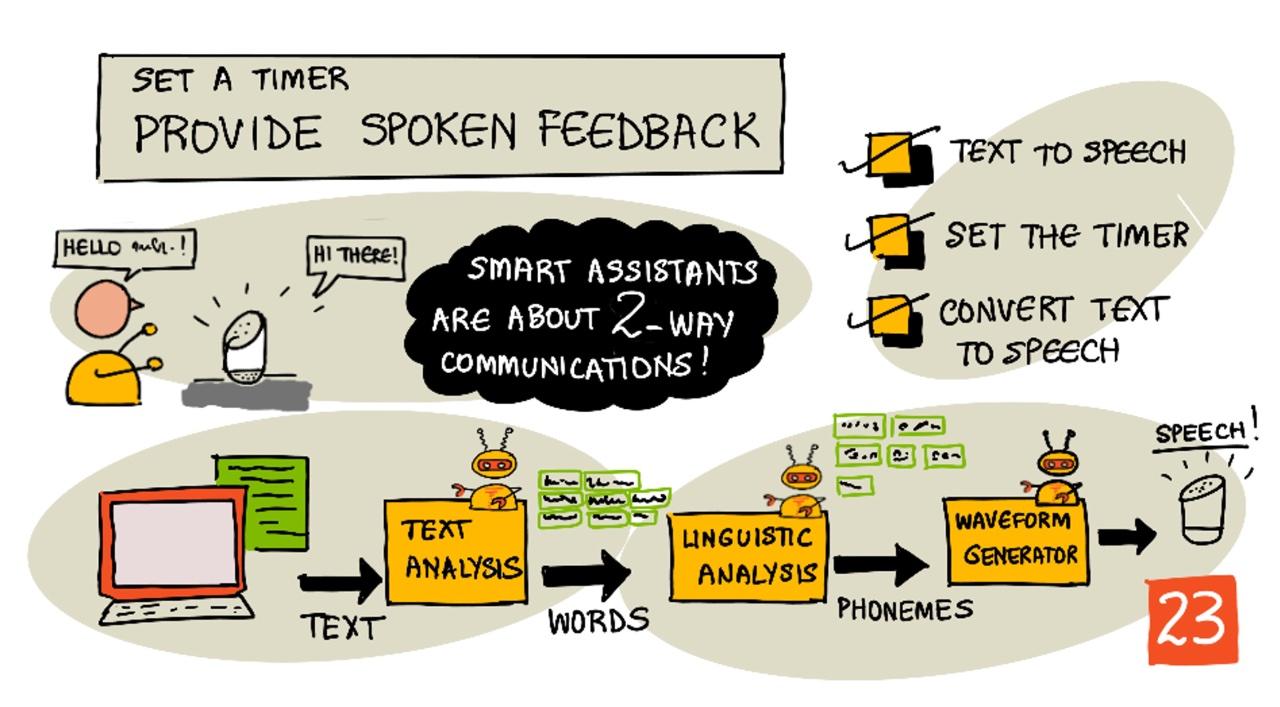
Sketchnote door Nitya Narasimhan. Klik op de afbeelding voor een grotere versie.
Quiz voorafgaand aan de les
Introductie
Slimme assistenten zijn geen eenrichtingscommunicatieapparaten. Je spreekt tegen ze, en ze reageren:
"Alexa, stel een timer in van 3 minuten"
"Oké, je timer is ingesteld op 3 minuten"
In de afgelopen 2 lessen heb je geleerd hoe je spraak kunt omzetten in tekst en vervolgens een verzoek om een timer in te stellen uit die tekst kunt halen. In deze les leer je hoe je de timer instelt op het IoT-apparaat, de gebruiker bevestigt met gesproken woorden dat de timer is ingesteld, en hen waarschuwt wanneer de timer is afgelopen.
In deze les behandelen we:
Tekst naar spraak
Tekst naar spraak, zoals de naam al aangeeft, is het proces van het omzetten van tekst in audio die de tekst als gesproken woorden bevat. Het basisprincipe is om de woorden in de tekst op te splitsen in hun samenstellende klanken (bekend als fonemen) en audio voor die klanken samen te voegen, hetzij met vooraf opgenomen audio, hetzij met audio die door AI-modellen wordt gegenereerd.

Tekst-naar-spraak-systemen hebben doorgaans 3 fasen:
- Tekstanalyse
- Taalkundige analyse
- Golfvormgeneratie
Tekstanalyse
Tekstanalyse houdt in dat de gegeven tekst wordt omgezet in woorden die kunnen worden gebruikt om spraak te genereren. Bijvoorbeeld, als je "Hallo wereld" omzet, is er geen tekstanalyse nodig; de twee woorden kunnen direct worden omgezet in spraak. Als je echter "1234" hebt, moet dit mogelijk worden omgezet in de woorden "Duizend tweehonderd vierendertig" of "Eén, twee, drie, vier", afhankelijk van de context. Voor "Ik heb 1234 appels" zou het "Duizend tweehonderd vierendertig" zijn, maar voor "Het kind telde 1234" zou het "Eén, twee, drie, vier" zijn.
De woorden die worden gecreëerd variëren niet alleen per taal, maar ook per regio binnen die taal. Bijvoorbeeld, in Amerikaans Engels is 120 "One hundred twenty", terwijl het in Brits Engels "One hundred and twenty" is, met het gebruik van "and" na de honderden.
✅ Andere voorbeelden die tekstanalyse vereisen zijn "in" als afkorting van inch, en "st" als afkorting van saint en street. Kun je andere voorbeelden bedenken in jouw taal van woorden die dubbelzinnig zijn zonder context?
Zodra de woorden zijn gedefinieerd, worden ze doorgestuurd voor taalkundige analyse.
Taalkundige analyse
Taalkundige analyse breekt de woorden op in fonemen. Fonemen zijn gebaseerd op niet alleen de letters die worden gebruikt, maar ook de andere letters in het woord. Bijvoorbeeld, in het Engels is de 'a'-klank in 'car' en 'care' verschillend. De Engelse taal heeft 44 verschillende fonemen voor de 26 letters in het alfabet, sommige gedeeld door verschillende letters, zoals hetzelfde foneem dat wordt gebruikt aan het begin van 'circle' en 'serpent'.
✅ Doe wat onderzoek: Wat zijn de fonemen voor jouw taal?
Zodra de woorden zijn omgezet in fonemen, hebben deze fonemen aanvullende gegevens nodig om intonatie te ondersteunen, waarbij de toon of duur wordt aangepast afhankelijk van de context. Een voorbeeld is dat in het Engels een verhoogde toonhoogte kan worden gebruikt om een zin om te zetten in een vraag, waarbij een verhoogde toonhoogte voor het laatste woord een vraag impliceert.
Bijvoorbeeld - de zin "You have an apple" is een verklaring dat je een appel hebt. Als de toonhoogte aan het einde stijgt, toenemend voor het woord "apple", wordt het de vraag "You have an apple?", waarbij wordt gevraagd of je een appel hebt. De taalkundige analyse moet het vraagteken aan het einde gebruiken om te beslissen om de toonhoogte te verhogen.
Zodra de fonemen zijn gegenereerd, kunnen ze worden doorgestuurd voor golfvormgeneratie om de audio-output te produceren.
Golfvormgeneratie
De eerste elektronische tekst-naar-spraak-systemen gebruikten enkele audio-opnames voor elk foneem, wat leidde tot zeer monotone, robotachtige stemmen. De taalkundige analyse zou fonemen produceren, deze zouden worden geladen uit een database van geluiden en aan elkaar worden gekoppeld om de audio te maken.
✅ Doe wat onderzoek: Zoek enkele audio-opnames van vroege spraaksynthesesystemen. Vergelijk ze met moderne spraaksynthese, zoals die wordt gebruikt in slimme assistenten.
Modernere golfvormgeneratie maakt gebruik van ML-modellen die zijn gebouwd met behulp van deep learning (zeer grote neurale netwerken die op een vergelijkbare manier werken als neuronen in de hersenen) om meer natuurlijk klinkende stemmen te produceren die niet te onderscheiden zijn van menselijke stemmen.
💁 Sommige van deze ML-modellen kunnen opnieuw worden getraind met behulp van transfer learning om te klinken als echte mensen. Dit betekent dat het gebruik van stem als een beveiligingssysteem, iets wat banken steeds vaker proberen, geen goed idee meer is, omdat iedereen met een opname van een paar minuten van jouw stem jou kan imiteren.
Deze grote ML-modellen worden getraind om alle drie de stappen te combineren tot end-to-end spraaksynthesizers.
De timer instellen
Om de timer in te stellen, moet je IoT-apparaat de REST-eindpunt aanroepen die je hebt gemaakt met serverloze code, en vervolgens het resulterende aantal seconden gebruiken om een timer in te stellen.
Taak - roep de serverloze functie aan om de tijd van de timer te verkrijgen
Volg de relevante gids om het REST-eindpunt aan te roepen vanaf je IoT-apparaat en stel een timer in voor de vereiste tijd:
Tekst omzetten naar spraak
Dezelfde spraakservice die je gebruikte om spraak om te zetten naar tekst kan worden gebruikt om tekst terug om te zetten naar spraak, en dit kan worden afgespeeld via een luidspreker op je IoT-apparaat. De tekst die moet worden omgezet wordt naar de spraakservice gestuurd, samen met het type audio dat nodig is (zoals de samplefrequentie), en binaire gegevens die de audio bevatten worden geretourneerd.
Wanneer je dit verzoek verzendt, doe je dit met behulp van Speech Synthesis Markup Language (SSML), een XML-gebaseerde opmaaktaal voor spraaksynthesetoepassingen. Dit definieert niet alleen de tekst die moet worden omgezet, maar ook de taal van de tekst, de stem die moet worden gebruikt, en kan zelfs worden gebruikt om snelheid, volume en toonhoogte te definiëren voor sommige of alle woorden in de tekst.
Bijvoorbeeld, deze SSML definieert een verzoek om de tekst "Je timer van 3 minuten en 5 seconden is ingesteld" om te zetten naar spraak met een Britse Engelse stem genaamd en-GB-MiaNeural.
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 De meeste tekst-naar-spraak-systemen hebben meerdere stemmen voor verschillende talen, met relevante accenten zoals een Britse Engelse stem met een Engels accent en een Nieuw-Zeelandse Engelse stem met een Nieuw-Zeelands accent.
Taak - tekst omzetten naar spraak
Werk door de relevante gids om tekst om te zetten naar spraak met je IoT-apparaat:
🚀 Uitdaging
SSML heeft manieren om te veranderen hoe woorden worden uitgesproken, zoals het toevoegen van nadruk op bepaalde woorden, het toevoegen van pauzes, of het veranderen van toonhoogte. Probeer enkele van deze uit door verschillende SSML vanaf je IoT-apparaat te verzenden en de output te vergelijken. Je kunt meer lezen over SSML, inclusief hoe je kunt veranderen hoe woorden worden uitgesproken, in de Speech Synthesis Markup Language (SSML) Version 1.1 specificatie van het World Wide Web consortium.
Quiz na de les
Review & Zelfstudie
- Lees meer over spraaksynthese op de spraaksynthesepagina op Wikipedia
- Lees meer over manieren waarop criminelen spraaksynthese gebruiken om te stelen in het nepstemmen 'helpen cybercriminelen geld te stelen' verhaal op BBC nieuws
- Leer meer over de risico's voor stemacteurs van gesynthetiseerde versies van hun stemmen in het dit TikTok-rechtszaak benadrukt hoe AI stemacteurs benadeelt artikel op Vice
Opdracht
Disclaimer:
Dit document is vertaald met behulp van de AI-vertalingsservice Co-op Translator. Hoewel we ons best doen voor nauwkeurigheid, dient u zich ervan bewust te zijn dat geautomatiseerde vertalingen fouten of onnauwkeurigheden kunnen bevatten. Het originele document in zijn oorspronkelijke taal moet worden beschouwd als de gezaghebbende bron. Voor cruciale informatie wordt professionele menselijke vertaling aanbevolen. Wij zijn niet aansprakelijk voor eventuele misverstanden of verkeerde interpretaties die voortvloeien uit het gebruik van deze vertaling.