|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-audio.md | 4 weeks ago | |
| pi-microphone.md | 4 weeks ago | |
| pi-speech-to-text.md | 4 weeks ago | |
| virtual-device-audio.md | 4 weeks ago | |
| virtual-device-microphone.md | 4 weeks ago | |
| virtual-device-speech-to-text.md | 4 weeks ago | |
| wio-terminal-audio.md | 4 weeks ago | |
| wio-terminal-microphone.md | 4 weeks ago | |
| wio-terminal-speech-to-text.md | 4 weeks ago | |
README.md
Spraak herkennen met een IoT-apparaat
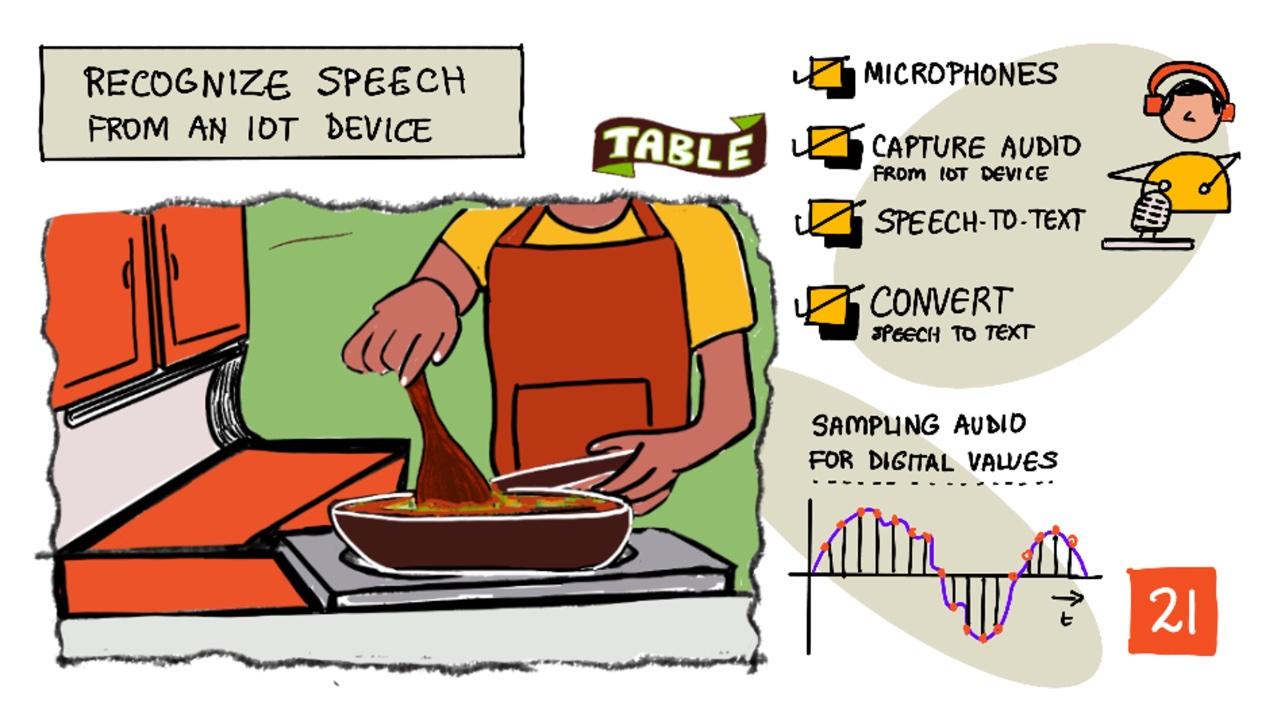
Sketchnote door Nitya Narasimhan. Klik op de afbeelding voor een grotere versie.
Deze video geeft een overzicht van de Azure spraakservice, een onderwerp dat in deze les wordt behandeld:

🎥 Klik op de afbeelding hierboven om een video te bekijken
Quiz voorafgaand aan de les
Introductie
'Alexa, zet een timer van 12 minuten'
'Alexa, wat is de status van de timer?'
'Alexa, zet een timer van 8 minuten genaamd broccoli stomen'
Slimme apparaten worden steeds alomtegenwoordiger. Niet alleen als slimme luidsprekers zoals HomePods, Echos en Google Homes, maar ook ingebouwd in onze telefoons, horloges, en zelfs lampen en thermostaten.
💁 Ik heb minstens 19 apparaten in mijn huis met spraakassistenten, en dat zijn alleen de apparaten waarvan ik het zeker weet!
Spraakbesturing verhoogt de toegankelijkheid door mensen met beperkte mobiliteit in staat te stellen apparaten te bedienen. Of het nu gaat om een permanente beperking, zoals geboren worden zonder armen, een tijdelijke beperking zoals gebroken armen, of simpelweg je handen vol hebben met boodschappen of jonge kinderen, het kunnen bedienen van ons huis met onze stem in plaats van onze handen opent een wereld van mogelijkheden. Roepen 'Hey Siri, sluit mijn garagedeur' terwijl je een baby verschoont en een onhandelbare peuter in toom houdt, kan een kleine maar effectieve verbetering van het leven zijn.
Een van de meest populaire toepassingen van spraakassistenten is het instellen van timers, vooral keukentimers. Het kunnen instellen van meerdere timers met alleen je stem is een grote hulp in de keuken - je hoeft niet te stoppen met het kneden van deeg, het roeren van soep, of het schoonmaken van je handen van dumplingvulling om een fysieke timer te gebruiken.
In deze les leer je hoe je spraakherkenning kunt integreren in IoT-apparaten. Je leert over microfoons als sensoren, hoe je audio kunt vastleggen van een microfoon die is aangesloten op een IoT-apparaat, en hoe je AI kunt gebruiken om wat wordt gehoord om te zetten in tekst. Gedurende de rest van dit project bouw je een slimme keukentimer, waarmee je timers kunt instellen met je stem in meerdere talen.
In deze les behandelen we:
Microfoons
Microfoons zijn analoge sensoren die geluidsgolven omzetten in elektrische signalen. Trillingen in de lucht zorgen ervoor dat onderdelen in de microfoon kleine bewegingen maken, wat kleine veranderingen in elektrische signalen veroorzaakt. Deze veranderingen worden vervolgens versterkt om een elektrisch outputsignaal te genereren.
Microfoontypes
Microfoons zijn er in verschillende soorten:
-
Dynamisch - Dynamische microfoons hebben een magneet die is bevestigd aan een bewegend membraan dat beweegt in een spoel van draad en een elektrische stroom creëert. Dit is het tegenovergestelde van de meeste luidsprekers, die een elektrische stroom gebruiken om een magneet in een spoel van draad te bewegen, waardoor een membraan geluid creëert. Dit betekent dat luidsprekers kunnen worden gebruikt als dynamische microfoons, en dynamische microfoons kunnen worden gebruikt als luidsprekers. In apparaten zoals intercoms, waar een gebruiker luistert of spreekt, maar niet beide, kan één apparaat zowel als luidspreker als microfoon fungeren.
Dynamische microfoons hebben geen stroom nodig om te werken; het elektrische signaal wordt volledig door de microfoon zelf gegenereerd.

-
Ribbon - Ribbon-microfoons lijken op dynamische microfoons, behalve dat ze een metalen lint hebben in plaats van een membraan. Dit lint beweegt in een magnetisch veld en genereert een elektrische stroom. Net als dynamische microfoons hebben ribbon-microfoons geen stroom nodig om te werken.

-
Condensator - Condensatormicrofoons hebben een dun metalen membraan en een vaste metalen achterplaat. Elektriciteit wordt toegepast op beide en terwijl het membraan trilt, verandert de statische lading tussen de platen, wat een signaal genereert. Condensatormicrofoons hebben stroom nodig om te werken - dit wordt Phantom power genoemd.
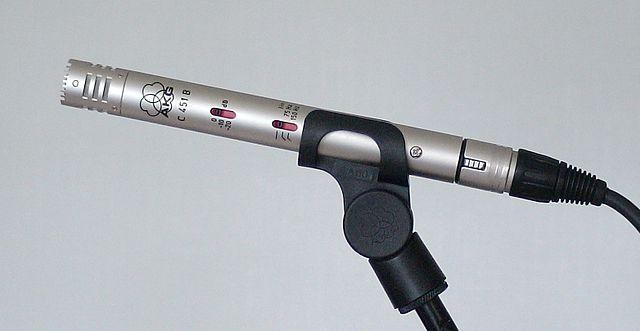
-
MEMS - Micro-elektromechanische systemen microfoons, of MEMS, zijn microfoons op een chip. Ze hebben een drukgevoelig membraan dat is geëtst op een siliciumchip en werken vergelijkbaar met een condensatormicrofoon. Deze microfoons kunnen zeer klein zijn en geïntegreerd in schakelingen.

In de afbeelding hierboven is de chip met het label LEFT een MEMS-microfoon, met een klein membraan van minder dan een millimeter breed.
✅ Doe wat onderzoek: Welke microfoons heb je om je heen - in je computer, je telefoon, je headset of andere apparaten? Wat voor soort microfoons zijn het?
Digitale audio
Audio is een analoog signaal dat zeer gedetailleerde informatie bevat. Om dit signaal naar digitaal te converteren, moet de audio duizenden keren per seconde worden bemonsterd.
🎓 Bemonstering is het omzetten van het audiosignaal in een digitale waarde die het signaal op dat moment vertegenwoordigt.
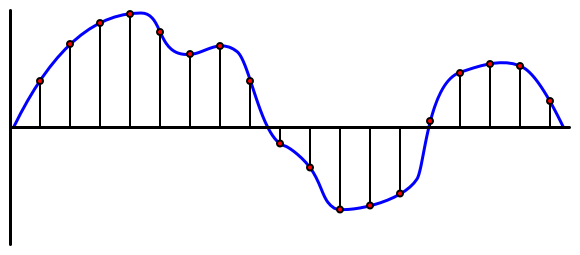
Digitale audio wordt bemonsterd met behulp van Pulse Code Modulation, of PCM. PCM houdt in dat de spanning van het signaal wordt gelezen en de dichtstbijzijnde discrete waarde wordt geselecteerd die overeenkomt met die spanning, met behulp van een gedefinieerde grootte.
💁 Je kunt PCM zien als de sensorversie van pulsbreedtemodulatie, of PWM (PWM werd behandeld in les 3 van het introductieproject). PCM houdt in dat een analoog signaal wordt omgezet naar digitaal, PWM houdt in dat een digitaal signaal wordt omgezet naar analoog.
Bijvoorbeeld, de meeste streaming muziekdiensten bieden 16-bit of 24-bit audio. Dit betekent dat ze de spanning omzetten in een waarde die past in een 16-bit integer of 24-bit integer. 16-bit audio past de waarde in een getal dat varieert van -32.768 tot 32.767, 24-bit varieert van −8.388.608 tot 8.388.607. Hoe meer bits, hoe dichter de sample bij wat onze oren daadwerkelijk horen.
💁 Je hebt misschien gehoord van 8-bit audio, vaak aangeduid als LoFi. Dit is audio die wordt bemonsterd met slechts 8 bits, dus -128 tot 127. De eerste computeraudio was beperkt tot 8 bits vanwege hardwarebeperkingen, dus dit wordt vaak gezien in retro gaming.
Deze samples worden duizenden keren per seconde genomen, met goed gedefinieerde bemonsteringsfrequenties gemeten in KHz (duizenden metingen per seconde). Streaming muziekdiensten gebruiken 48KHz voor de meeste audio, maar sommige 'lossless' audio gebruikt tot 96KHz of zelfs 192KHz. Hoe hoger de bemonsteringsfrequentie, hoe dichter bij het origineel de audio zal zijn, tot op zekere hoogte. Er is discussie over of mensen het verschil boven 48KHz kunnen horen.
✅ Doe wat onderzoek: Als je een streaming muziekdienst gebruikt, welke bemonsteringsfrequentie en grootte gebruikt deze? Als je cd's gebruikt, wat is de bemonsteringsfrequentie en grootte van cd-audio?
Er zijn een aantal verschillende formaten voor audiodata. Je hebt waarschijnlijk gehoord van mp3-bestanden - audiodata die is gecomprimeerd om kleiner te zijn zonder kwaliteitsverlies. Ongecomprimeerde audio wordt vaak opgeslagen als een WAV-bestand - dit is een bestand met 44 bytes aan headerinformatie, gevolgd door ruwe audiodata. De header bevat informatie zoals de bemonsteringsfrequentie (bijvoorbeeld 16000 voor 16KHz) en bemonsteringsgrootte (16 voor 16-bit), en het aantal kanalen. Na de header bevat het WAV-bestand de ruwe audiodata.
🎓 Kanalen verwijzen naar hoeveel verschillende audiostreams deel uitmaken van de audio. Bijvoorbeeld, voor stereo-audio met links en rechts zouden er 2 kanalen zijn. Voor 7.1 surround sound voor een thuisbioscoopsysteem zouden dit er 8 zijn.
Grootte van audiodata
Audiodata is relatief groot. Bijvoorbeeld, het vastleggen van ongecomprimeerde 16-bit audio bij 16KHz (een voldoende frequentie voor gebruik met spraak-naar-tekstmodellen) neemt 32KB aan data per seconde audio in beslag:
- 16-bit betekent 2 bytes per sample (1 byte is 8 bits).
- 16KHz is 16.000 samples per seconde.
- 16.000 x 2 bytes = 32.000 bytes per seconde.
Dit klinkt als een kleine hoeveelheid data, maar als je een microcontroller met beperkte geheugenruimte gebruikt, kan dit veel zijn. Bijvoorbeeld, de Wio Terminal heeft 192KB aan geheugen, en dat moet programma's en variabelen opslaan. Zelfs als je programma klein is, kun je niet meer dan 5 seconden audio vastleggen.
Microcontrollers kunnen toegang krijgen tot extra opslag, zoals SD-kaarten of flashgeheugen. Bij het bouwen van een IoT-apparaat dat audio vastlegt, moet je ervoor zorgen dat je niet alleen extra opslag hebt, maar dat je code de audio die is vastgelegd van je microfoon direct naar die opslag schrijft. Wanneer je het naar de cloud stuurt, stream je van opslag naar de webaanvraag. Op die manier kun je voorkomen dat je geheugen opraakt door te proberen het hele blok audiodata in één keer in het geheugen te houden.
Audio vastleggen van je IoT-apparaat
Je IoT-apparaat kan worden aangesloten op een microfoon om audio vast te leggen, klaar om te worden omgezet naar tekst. Het kan ook worden aangesloten op luidsprekers om audio uit te voeren. In latere lessen zal dit worden gebruikt om audiofeedback te geven, maar het is handig om nu luidsprekers in te stellen om de microfoon te testen.
Taak - configureer je microfoon en luidsprekers
Werk de relevante handleiding door om de microfoon en luidsprekers voor je IoT-apparaat te configureren:
- Arduino - Wio Terminal
- Single-board computer - Raspberry Pi
- Single-board computer - Virtueel apparaat
Taak - audio vastleggen
Werk de relevante handleiding door om audio vast te leggen op je IoT-apparaat:
- Arduino - Wio Terminal
- Single-board computer - Raspberry Pi
- Single-board computer - Virtueel apparaat
Spraak naar tekst
Spraak naar tekst, of spraakherkenning, houdt in dat AI wordt gebruikt om woorden in een audiosignaal om te zetten naar tekst.
Spraakherkenningsmodellen
Om spraak om te zetten naar tekst, worden samples van het audiosignaal gegroepeerd en ingevoerd in een machine learning-model gebaseerd op een Recurrent Neural Network (RNN). Dit is een type machine learning-model dat eerdere data kan gebruiken om een beslissing te nemen over binnenkomende data. Bijvoorbeeld, het RNN kan één blok audiosamples detecteren als het geluid 'Hel', en wanneer het een ander blok ontvangt dat het denkt dat het geluid 'lo' is, kan het dit combineren met het vorige geluid, ontdekken dat 'Hello' een geldig woord is en dat als uitkomst selecteren.
ML-modellen accepteren altijd data van dezelfde grootte elke keer. De beeldclassifier die je in een eerdere les hebt gebouwd, past afbeeldingen aan naar een vaste grootte en verwerkt ze. Hetzelfde geldt voor spraakmodellen; ze moeten vaste blokken audio verwerken. De spraakmodellen moeten in staat zijn om de uitkomsten van meerdere voorspellingen te combineren om het antwoord te krijgen, zodat ze onderscheid kunnen maken tussen 'Hi' en 'Highway', of 'flock' en 'floccinaucinihilipilification'.
Spraakmodellen zijn ook geavanceerd genoeg om context te begrijpen en kunnen de woorden die ze detecteren corrigeren naarmate meer geluiden worden verwerkt. Bijvoorbeeld, als je zegt "Ik ging naar de winkel om twee bananen en een appel ook te halen", gebruik je drie woorden die hetzelfde klinken, maar anders worden gespeld - to, two en too. Spraakmodellen kunnen de context begrijpen en de juiste spelling van het woord gebruiken. 💁 Sommige spraakdiensten bieden de mogelijkheid tot aanpassing, zodat ze beter functioneren in lawaaierige omgevingen zoals fabrieken, of met vakjargon zoals chemische namen. Deze aanpassingen worden getraind door voorbeeldaudio en een transcriptie aan te leveren, en werken met transfer learning, vergelijkbaar met hoe je eerder een beeldclassifier hebt getraind met slechts een paar afbeeldingen.
Privacy
Bij het gebruik van spraak-naar-tekst in een consument IoT-apparaat is privacy ontzettend belangrijk. Deze apparaten luisteren continu naar audio, en als consument wil je niet dat alles wat je zegt naar de cloud wordt gestuurd en omgezet in tekst. Dit zou niet alleen veel internetbandbreedte gebruiken, maar het heeft ook enorme privacygevolgen, vooral wanneer sommige fabrikanten van slimme apparaten willekeurig audio selecteren voor mensen om te valideren tegen de gegenereerde tekst om hun model te verbeteren.
Je wilt dat je slimme apparaat alleen audio naar de cloud stuurt voor verwerking wanneer je het daadwerkelijk gebruikt, niet wanneer het audio hoort in je huis, audio die privévergaderingen of intieme interacties kan bevatten. De manier waarop de meeste slimme apparaten werken is met een wekwoord, een sleutelzin zoals "Alexa", "Hey Siri" of "OK Google" die ervoor zorgt dat het apparaat 'wakker wordt' en luistert naar wat je zegt totdat het een pauze in je spraak detecteert, wat aangeeft dat je klaar bent met praten tegen het apparaat.
🎓 Wekwoorddetectie wordt ook wel Keyword spotting of Keyword recognition genoemd.
Deze wekwoorden worden op het apparaat gedetecteerd, niet in de cloud. Deze slimme apparaten hebben kleine AI-modellen die op het apparaat draaien en luisteren naar het wekwoord. Wanneer het wekwoord wordt gedetecteerd, begint het apparaat de audio naar de cloud te streamen voor herkenning. Deze modellen zijn zeer gespecialiseerd en luisteren alleen naar het wekwoord.
💁 Sommige technologiebedrijven voegen meer privacy toe aan hun apparaten door een deel van de spraak-naar-tekst-conversie op het apparaat zelf uit te voeren. Apple heeft aangekondigd dat ze als onderdeel van hun 2021 iOS- en macOS-updates de spraak-naar-tekst-conversie op het apparaat zullen ondersteunen en veel verzoeken kunnen afhandelen zonder de cloud te gebruiken. Dit is mogelijk dankzij krachtige processors in hun apparaten die ML-modellen kunnen draaien.
✅ Wat denk je dat de privacy- en ethische implicaties zijn van het opslaan van audio die naar de cloud wordt gestuurd? Moet deze audio worden opgeslagen, en zo ja, hoe? Denk je dat het gebruik van opnames voor wetshandhaving een goede afweging is voor het verlies van privacy?
Wekwoorddetectie maakt meestal gebruik van een techniek genaamd TinyML, waarbij ML-modellen worden omgezet zodat ze kunnen draaien op microcontrollers. Deze modellen zijn klein van formaat en verbruiken zeer weinig energie.
Om de complexiteit van het trainen en gebruiken van een wekwoordmodel te vermijden, zal de slimme timer die je in deze les bouwt een knop gebruiken om de spraakherkenning in te schakelen.
💁 Als je een wekwoorddetectiemodel wilt maken om te draaien op de Wio Terminal of Raspberry Pi, bekijk dan deze tutorial over reageren op je stem van Edge Impulse. Als je je computer hiervoor wilt gebruiken, kun je de quickstart voor Custom Keyword op de Microsoft Docs proberen.
Spraak omzetten naar tekst
![]()
Net zoals bij beeldclassificatie in een eerder project, zijn er vooraf gebouwde AI-diensten die spraak als audiobestand kunnen nemen en omzetten naar tekst. Een van deze diensten is de Speech Service, onderdeel van de Cognitive Services, vooraf gebouwde AI-diensten die je in je apps kunt gebruiken.
Taak - configureer een spraak-AI-resource
-
Maak een Resource Group voor dit project genaamd
smart-timer. -
Gebruik de volgende opdracht om een gratis spraakresource te maken:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>Vervang
<location>door de locatie die je hebt gebruikt bij het maken van de Resource Group. -
Je hebt een API-sleutel nodig om toegang te krijgen tot de spraakresource vanuit je code. Voer de volgende opdracht uit om de sleutel te verkrijgen:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableMaak een kopie van een van de sleutels.
Taak - spraak omzetten naar tekst
Werk de relevante handleiding door om spraak om te zetten naar tekst op je IoT-apparaat:
- Arduino - Wio Terminal
- Single-board computer - Raspberry Pi
- Single-board computer - Virtueel apparaat
🚀 Uitdaging
Spraakherkenning bestaat al lange tijd en blijft zich verbeteren. Onderzoek de huidige mogelijkheden en vergelijk hoe deze zich in de loop der tijd hebben ontwikkeld, inclusief hoe nauwkeurig machine-transcripties zijn in vergelijking met menselijke transcripties.
Wat denk je dat de toekomst brengt voor spraakherkenning?
Quiz na de les
Review & Zelfstudie
- Lees over de verschillende microfoontypes en hoe ze werken in het artikel over het verschil tussen dynamische en condensatormicrofoons op Musician's HQ.
- Lees meer over de Cognitive Services spraakdienst in de spraakdienstdocumentatie op Microsoft Docs.
- Lees over keyword spotting in de keyword recognition documentatie op Microsoft Docs.
Opdracht
Disclaimer:
Dit document is vertaald met behulp van de AI-vertalingsservice Co-op Translator. Hoewel we streven naar nauwkeurigheid, dient u zich ervan bewust te zijn dat geautomatiseerde vertalingen fouten of onnauwkeurigheden kunnen bevatten. Het originele document in zijn oorspronkelijke taal moet worden beschouwd als de gezaghebbende bron. Voor kritieke informatie wordt professionele menselijke vertaling aanbevolen. Wij zijn niet aansprakelijk voor misverstanden of verkeerde interpretaties die voortvloeien uit het gebruik van deze vertaling.