|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
टाइमर सेट करा आणि बोलून फीडबॅक द्या
स्केच नोट्स नित्य नरसिंहन यांनी तयार केले. मोठ्या आवृत्तीसाठी प्रतिमेवर क्लिक करा.
व्याख्यानपूर्व प्रश्नमंजूषा
परिचय
स्मार्ट सहाय्यक हे एकतर्फी संवाद साधणारी उपकरणे नाहीत. तुम्ही त्यांच्याशी बोलता आणि ते प्रतिसाद देतात:
"अलेक्सा, ३ मिनिटांचा टाइमर सेट करा"
"ठीक आहे, तुमचा टाइमर ३ मिनिटांसाठी सेट केला आहे"
गेल्या दोन धड्यांमध्ये तुम्ही शिकले की भाषणाचे टेक्स्टमध्ये रूपांतर कसे करायचे आणि त्या टेक्स्टमधून टाइमर सेट करण्याची विनंती कशी काढायची. या धड्यात तुम्ही शिकाल की IoT उपकरणावर टाइमर कसा सेट करायचा, वापरकर्त्याला त्यांच्या टाइमरची पुष्टी देणारे शब्द बोलून प्रतिसाद द्यायचा आणि टाइमर संपल्यावर त्यांना सतर्क करायचे.
या धड्यात आपण कव्हर करू:
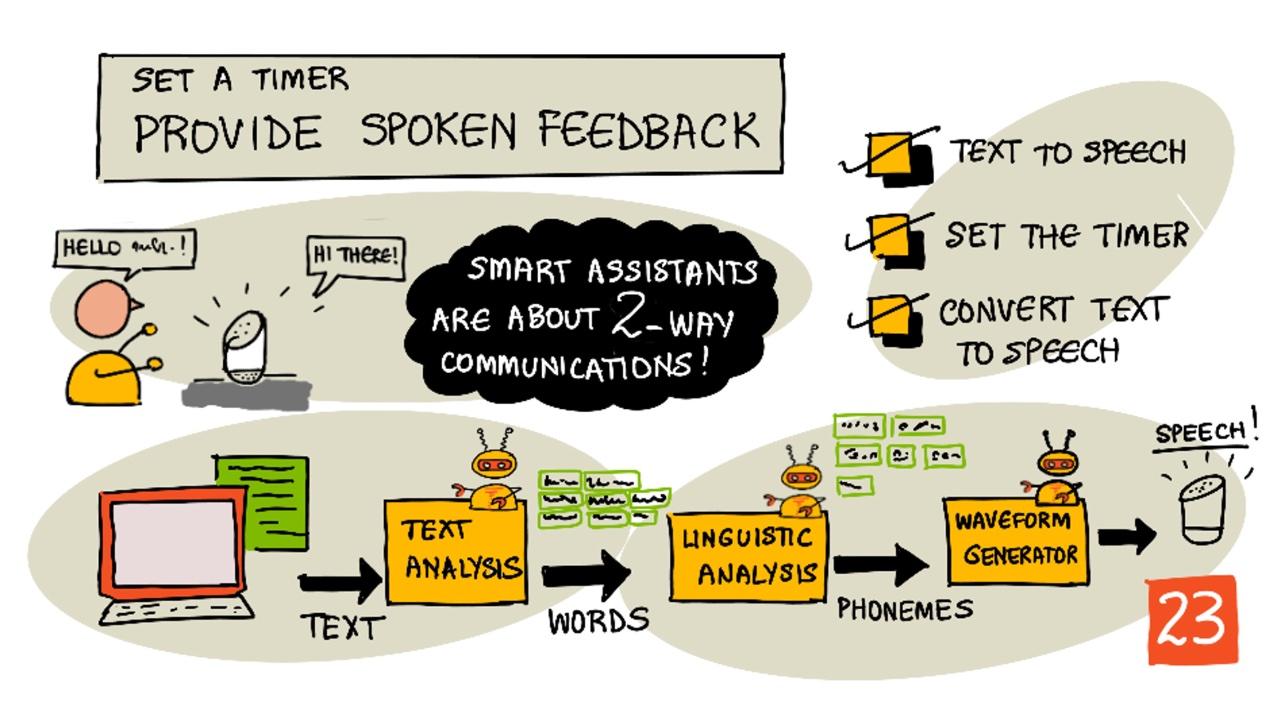
टेक्स्ट ते भाषण
टेक्स्ट ते भाषण, नावाप्रमाणेच, टेक्स्टचे ऑडिओमध्ये रूपांतर करण्याची प्रक्रिया आहे ज्यामध्ये टेक्स्ट बोललेल्या शब्दांप्रमाणे असते. मूलभूत तत्त्व म्हणजे टेक्स्टमधील शब्दांचे घटक ध्वनींमध्ये (ज्याला फोनीम्स म्हणतात) विभाजन करणे आणि त्या ध्वनींसाठी ऑडिओ एकत्र करणे, प्री-रेकॉर्ड केलेल्या ऑडिओचा वापर करून किंवा AI मॉडेल्सद्वारे ऑडिओ तयार करून.

टेक्स्ट ते भाषण प्रणालींमध्ये सामान्यतः ३ टप्पे असतात:
- टेक्स्ट विश्लेषण
- भाषिक विश्लेषण
- वेव्ह-फॉर्म निर्मिती
टेक्स्ट विश्लेषण
टेक्स्ट विश्लेषणामध्ये दिलेला टेक्स्ट घेऊन तो भाषण तयार करण्यासाठी वापरता येणाऱ्या शब्दांमध्ये रूपांतरित करणे समाविष्ट आहे. उदाहरणार्थ, जर तुम्ही "Hello world" चे रूपांतर केले, तर कोणतेही टेक्स्ट विश्लेषण आवश्यक नाही, हे दोन शब्द भाषणात रूपांतरित करता येतील. परंतु जर तुम्ही "1234" चे रूपांतर केले, तर ते "One thousand, two hundred thirty four" किंवा "One, two, three, four" मध्ये रूपांतरित करावे लागेल, संदर्भानुसार. "I have 1234 apples" साठी ते "One thousand, two hundred thirty four" असेल, परंतु "The child counted 1234" साठी ते "One, two, three, four" असेल.
शब्द केवळ भाषेसाठीच नव्हे तर त्या भाषेच्या स्थानिक स्वरूपासाठीही बदलतात. उदाहरणार्थ, अमेरिकन इंग्रजीमध्ये 120 हे "One hundred twenty" असेल, तर ब्रिटिश इंग्रजीमध्ये ते "One hundred and twenty" असेल, ज्यामध्ये "and" चा वापर शंभरानंतर होतो.
✅ काही इतर उदाहरणे ज्यांना टेक्स्ट विश्लेषण आवश्यक आहे ती म्हणजे "in" हे inch चे संक्षिप्त रूप आणि "st" हे saint आणि street चे संक्षिप्त रूप. तुमच्या भाषेत संदर्भाशिवाय अस्पष्ट असलेल्या शब्दांची इतर उदाहरणे तुम्ही विचार करू शकता का?
एकदा शब्द निश्चित झाल्यावर ते भाषिक विश्लेषणासाठी पाठवले जातात.
भाषिक विश्लेषण
भाषिक विश्लेषण शब्दांना फोनीम्समध्ये विभाजित करते. फोनीम्स केवळ वापरलेल्या अक्षरांवरच आधारित नसतात, तर शब्दातील इतर अक्षरांवरही आधारित असतात. उदाहरणार्थ, इंग्रजीमध्ये 'car' आणि 'care' मधील 'a' चा ध्वनी वेगळा आहे. इंग्रजी भाषेत 26 अक्षरांसाठी 44 वेगवेगळे फोनीम्स आहेत, काही वेगवेगळ्या अक्षरांद्वारे सामायिक केले जातात, जसे 'circle' आणि 'serpent' च्या सुरुवातीस वापरलेला समान फोनीम.
✅ संशोधन करा: तुमच्या भाषेसाठी फोनीम्स काय आहेत?
एकदा शब्द फोनीम्समध्ये रूपांतरित झाले की, संदर्भानुसार टोन किंवा कालावधी समायोजित करण्यासाठी फोनीम्सना अतिरिक्त डेटा आवश्यक असतो. एक उदाहरण म्हणजे इंग्रजीमध्ये पिच वाढवून वाक्याला प्रश्नात रूपांतरित करता येते, शेवटच्या शब्दासाठी वाढलेला पिच प्रश्न सूचित करतो.
उदाहरणार्थ - "You have an apple" हे वाक्य एक विधान आहे जे सांगते की तुमच्याकडे एक सफरचंद आहे. जर शेवटी पिच वाढले, विशेषतः 'apple' साठी, तर ते "You have an apple?" असा प्रश्न बनतो, विचारत आहे की तुमच्याकडे सफरचंद आहे का. भाषिक विश्लेषणाला शेवटी असलेल्या प्रश्नचिन्हाचा वापर करून पिच वाढवायचे आहे.
एकदा फोनीम्स तयार झाल्यावर, ऑडिओ आउटपुट तयार करण्यासाठी ते वेव्ह-फॉर्म निर्मितीसाठी पाठवले जातात.
वेव्ह-फॉर्म निर्मिती
पहिल्या इलेक्ट्रॉनिक टेक्स्ट ते भाषण प्रणालींनी प्रत्येक फोनीमसाठी एकल ऑडिओ रेकॉर्डिंग वापरले, ज्यामुळे अतिशय एकसंध, रोबोटिक आवाज निर्माण झाले. भाषिक विश्लेषण फोनीम्स तयार करेल, हे फोनीम्स ऑडिओ डेटाबेसमधून लोड केले जातील आणि ऑडिओ तयार करण्यासाठी एकत्र केले जातील.
✅ संशोधन करा: सुरुवातीच्या भाषण संश्लेषण प्रणालींचे काही ऑडिओ रेकॉर्डिंग शोधा. आधुनिक भाषण संश्लेषणाशी तुलना करा, जसे स्मार्ट सहाय्यकांमध्ये वापरले जाते.
अधिक आधुनिक वेव्ह-फॉर्म निर्मिती डीप लर्निंग वापरून तयार केलेल्या ML मॉडेल्सचा वापर करते (म्हणजे मोठ्या न्यूरल नेटवर्क्स जे मेंदूतील न्यूरॉन्ससारखे कार्य करतात) जे अधिक नैसर्गिक आवाज तयार करतात, जे मानवांपासून वेगळे ओळखता येत नाहीत.
💁 या ML मॉडेल्सना ट्रान्सफर लर्निंग वापरून वास्तविक लोकांसारखे आवाज तयार करण्यासाठी पुन्हा प्रशिक्षण दिले जाऊ शकते. याचा अर्थ असा की आवाज सुरक्षा प्रणाली म्हणून वापरणे, जे बँका वाढत्या प्रमाणात वापरत आहेत, चांगली कल्पना नाही कारण तुमच्या आवाजाच्या काही मिनिटांच्या रेकॉर्डिंगसह कोणीही तुमची नक्कल करू शकतो.
हे मोठे ML मॉडेल्स तीन टप्प्यांना एकत्र करून एंड-टू-एंड भाषण संश्लेषक तयार करण्यासाठी प्रशिक्षण घेत आहेत.
टाइमर सेट करा
टाइमर सेट करण्यासाठी, तुमच्या IoT उपकरणाला तुम्ही तयार केलेल्या सर्व्हरलेस कोडचा REST एंडपॉइंट कॉल करावा लागेल, आणि परिणामी सेकंदांचा वापर करून टाइमर सेट करावा लागेल.
कार्य - सर्व्हरलेस फंक्शन कॉल करून टाइमर वेळ मिळवा
तुमच्या IoT उपकरणावरून REST एंडपॉइंट कॉल करण्यासाठी आणि आवश्यक वेळेसाठी टाइमर सेट करण्यासाठी संबंधित मार्गदर्शक अनुसरण करा:
टेक्स्टचे भाषणात रूपांतर करा
तुम्ही भाषणाचे टेक्स्टमध्ये रूपांतर करण्यासाठी वापरलेली तीच भाषण सेवा टेक्स्ट परत भाषणात रूपांतर करण्यासाठी वापरली जाऊ शकते, आणि हे ऑडिओ तुमच्या IoT उपकरणावर स्पीकरद्वारे प्ले केले जाऊ शकते. रूपांतरित करण्यासाठी टेक्स्ट भाषण सेवेला पाठवले जाते, ऑडिओ प्रकारासह (जसे नमुना दर), आणि ऑडिओ असलेला बायनरी डेटा परत केला जातो.
जेव्हा तुम्ही ही विनंती पाठवता, तेव्हा तुम्ही Speech Synthesis Markup Language (SSML) वापरून पाठवता, जे भाषण संश्लेषण अनुप्रयोगांसाठी XML-आधारित मार्कअप भाषा आहे. हे केवळ रूपांतरित करण्यासाठी टेक्स्टच नाही तर टेक्स्टची भाषा, वापरण्यासाठी आवाज, आणि काही किंवा सर्व शब्दांसाठी गती, आवाज, आणि पिच देखील परिभाषित करू शकते.
उदाहरणार्थ, हे SSML "Your 3 minute 5 second time has been set" टेक्स्टला ब्रिटिश इंग्रजी आवाज en-GB-MiaNeural वापरून भाषणात रूपांतरित करण्याची विनंती परिभाषित करते.
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 बहुतेक टेक्स्ट ते भाषण प्रणालींमध्ये वेगवेगळ्या भाषांसाठी अनेक आवाज असतात, संबंधित उच्चारांसह जसे ब्रिटिश इंग्रजी आवाज इंग्रजी उच्चारांसह आणि न्यूझीलंड इंग्रजी आवाज न्यूझीलंड उच्चारांसह.
कार्य - टेक्स्टचे भाषणात रूपांतर करा
तुमच्या IoT उपकरणाचा वापर करून टेक्स्टचे भाषणात रूपांतर करण्यासाठी संबंधित मार्गदर्शक अनुसरण करा:
🚀 आव्हान
SSML मध्ये शब्द कसे बोलले जातात ते बदलण्याचे मार्ग आहेत, जसे काही शब्दांवर जोर देणे, विराम जोडणे, किंवा पिच बदलणे. हे वापरून पहा, तुमच्या IoT उपकरणावरून वेगवेगळे SSML पाठवा आणि आउटपुटची तुलना करा. SSML बद्दल अधिक वाचा, ज्यामध्ये शब्द कसे बोलले जातात ते बदलण्याचे मार्ग Speech Synthesis Markup Language (SSML) Version 1.1 specification from the World Wide Web consortium मध्ये दिले आहेत.
व्याख्यानोत्तर प्रश्नमंजूषा
पुनरावलोकन आणि स्व-अभ्यास
- भाषण संश्लेषणाबद्दल अधिक वाचा विकिपीडियावर भाषण संश्लेषण पृष्ठ
- भाषण संश्लेषणाचा वापर करून गुन्हेगार पैसे कसे चोरत आहेत याबद्दल अधिक वाचा बीबीसीच्या बातम्यांवरील 'fake voices 'help cyber crooks steal cash' कथा
- AI च्या आवाजाच्या संश्लेषणामुळे आवाज कलाकारांना होणाऱ्या धोक्यांबद्दल अधिक जाणून घ्या Vice वरील 'this TikTok lawsuit is highlighting how AI is screwing over voice actors' लेख
असाइनमेंट
अस्वीकरण:
हा दस्तऐवज AI भाषांतर सेवा Co-op Translator चा वापर करून भाषांतरित करण्यात आला आहे. आम्ही अचूकतेसाठी प्रयत्नशील असलो तरी कृपया लक्षात ठेवा की स्वयंचलित भाषांतरे त्रुटी किंवा अचूकतेच्या अभावाने युक्त असू शकतात. मूळ भाषेतील दस्तऐवज हा अधिकृत स्रोत मानला जावा. महत्त्वाच्या माहितीसाठी व्यावसायिक मानवी भाषांतराची शिफारस केली जाते. या भाषांतराचा वापर करून उद्भवलेल्या कोणत्याही गैरसमज किंवा चुकीच्या अर्थासाठी आम्ही जबाबदार राहणार नाही.