|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
주식 감지기 학습하기
스케치노트: Nitya Narasimhan. 이미지를 클릭하면 더 큰 버전을 볼 수 있습니다.
이 비디오는 Azure Custom Vision 서비스의 객체 감지 개요를 제공합니다. 이 서비스는 이번 강의에서 다룰 예정입니다.

🎥 위 이미지를 클릭하여 비디오를 시청하세요.
강의 전 퀴즈
소개
이전 프로젝트에서는 AI를 사용하여 이미지 분류기를 학습시켰습니다. 이 모델은 이미지에 익은 과일이나 익지 않은 과일과 같은 특정 항목이 포함되어 있는지 판단할 수 있습니다. 이미지와 함께 사용할 수 있는 또 다른 유형의 AI 모델은 객체 감지입니다. 이러한 모델은 이미지를 태그로 분류하는 대신 객체를 인식하도록 학습되며, 이미지를 분석하여 객체가 어디에 있는지 감지할 수 있습니다. 이를 통해 이미지에서 객체를 세는 것이 가능합니다.
이번 강의에서는 객체 감지에 대해 배우고, 이를 소매업에서 어떻게 활용할 수 있는지 알아봅니다. 또한 클라우드에서 객체 감지기를 학습시키는 방법도 배울 것입니다.
이번 강의에서 다룰 내용은 다음과 같습니다:
객체 감지
객체 감지는 AI를 사용하여 이미지에서 객체를 감지하는 것을 포함합니다. 이전 프로젝트에서 학습한 이미지 분류기와는 달리, 객체 감지는 이미지 전체에 대해 가장 적합한 태그를 예측하는 것이 아니라 이미지에서 하나 이상의 객체를 찾는 것입니다.
객체 감지 vs 이미지 분류
이미지 분류는 이미지 전체를 분류하는 것입니다. 즉, 이미지가 각 태그와 일치할 확률을 계산합니다. 모델 학습에 사용된 모든 태그에 대한 확률을 반환합니다.

위 예시에서 두 이미지는 캐슈넛 통과 토마토 페이스트 캔을 분류하도록 학습된 모델을 사용하여 분류되었습니다. 첫 번째 이미지는 캐슈넛 통이며, 이미지 분류기의 결과는 다음과 같습니다:
| 태그 | 확률 |
|---|---|
캐슈넛 |
98.4% |
토마토 페이스트 |
1.6% |
두 번째 이미지는 토마토 페이스트 캔이며, 결과는 다음과 같습니다:
| 태그 | 확률 |
|---|---|
캐슈넛 |
0.7% |
토마토 페이스트 |
99.3% |
이 값을 사용하여 이미지에 무엇이 있는지 예측할 수 있습니다. 하지만 이미지에 여러 개의 토마토 페이스트 캔이나 캐슈넛과 토마토 페이스트가 모두 포함되어 있다면 결과가 원하는 대로 나오지 않을 가능성이 높습니다. 이때 객체 감지가 필요합니다.
객체 감지는 모델을 학습시켜 객체를 인식하도록 합니다. 객체가 포함된 이미지를 제공하고 각 이미지가 특정 태그인지 알려주는 대신, 이미지에서 특정 객체가 포함된 부분을 강조 표시하고 태그를 지정합니다. 이미지에 단일 객체를 태그하거나 여러 객체를 태그할 수 있습니다. 이렇게 하면 모델이 객체 자체가 어떻게 생겼는지 학습하게 됩니다.
예측 시 태그와 확률 목록 대신 감지된 객체 목록, 객체를 포함하는 경계 상자와 해당 태그와 일치할 확률을 반환합니다.
🎓 경계 상자는 객체 주위의 상자입니다.

위 이미지는 캐슈넛 통과 세 개의 토마토 페이스트 캔을 포함하고 있습니다. 객체 감지기는 캐슈넛을 감지하여 캐슈넛을 포함하는 경계 상자와 해당 객체를 포함할 확률(97.6%)을 반환합니다. 또한 세 개의 토마토 페이스트 캔을 감지하여 각각의 캔에 대해 별도의 경계 상자를 제공합니다. 각 경계 상자는 해당 태그와 일치할 확률을 포함합니다.
✅ 이미지 기반 AI 모델을 사용하고 싶은 다양한 시나리오를 생각해보세요. 어떤 시나리오가 분류를 필요로 하고, 어떤 시나리오가 객체 감지를 필요로 할까요?
객체 감지가 작동하는 방식
객체 감지는 복잡한 ML 모델을 사용합니다. 이러한 모델은 이미지를 여러 셀로 나눈 다음, 경계 상자의 중심이 모델 학습에 사용된 이미지와 일치하는지 확인합니다. 이는 이미지 분류기를 이미지의 다른 부분에 실행하여 일치 여부를 확인하는 것과 비슷합니다.
💁 이는 매우 간단히 설명한 것입니다. 객체 감지에는 다양한 기술이 있으며, Wikipedia의 객체 감지 페이지에서 더 자세히 읽어볼 수 있습니다.
객체 감지를 수행할 수 있는 다양한 모델이 있습니다. 특히 유명한 모델 중 하나는 YOLO (You Only Look Once)로, 매우 빠르며 사람, 개, 병, 자동차 등 20가지 객체를 감지할 수 있습니다.
✅ pjreddie.com/darknet/yolo/에서 YOLO 모델에 대해 읽어보세요.
객체 감지 모델은 전이 학습을 사용하여 사용자 정의 객체를 감지하도록 재학습할 수 있습니다.
소매업에서 객체 감지 활용
객체 감지는 소매업에서 다양한 용도로 사용될 수 있습니다. 몇 가지 예는 다음과 같습니다:
- 재고 확인 및 계산 - 선반에 재고가 부족한 경우를 인식. 재고가 너무 적으면 직원이나 로봇에게 알림을 보내 선반을 다시 채우도록 할 수 있습니다.
- 마스크 감지 - 공중 보건 이벤트 동안 마스크 정책이 있는 매장에서 마스크를 착용한 사람과 착용하지 않은 사람을 인식.
- 자동 결제 - 자동화된 매장에서 선반에서 선택된 항목을 감지하고 고객에게 적절히 청구.
- 위험 감지 - 바닥에 깨진 물건이나 유출된 액체를 인식하여 청소 팀에 알림.
✅ 연구해보세요: 소매업에서 객체 감지의 다른 사용 사례는 무엇이 있을까요?
객체 감지기 학습
Custom Vision을 사용하여 객체 감지기를 학습시킬 수 있습니다. 이는 이미지 분류기를 학습시킨 방식과 유사합니다.
작업 - 객체 감지기 생성
-
stock-detector라는 이름의 리소스 그룹을 생성합니다. -
stock-detector리소스 그룹에서 무료 Custom Vision 학습 리소스와 무료 Custom Vision 예측 리소스를 생성합니다. 이름은 각각stock-detector-training과stock-detector-prediction으로 지정합니다.💁 무료 학습 및 예측 리소스는 하나만 가질 수 있으므로 이전 강의에서 사용한 프로젝트를 정리했는지 확인하세요.
⚠️ 프로젝트 4, 강의 1의 학습 및 예측 리소스 생성 지침을 참조하세요.
-
CustomVision.ai에서 Custom Vision 포털을 실행하고 Azure 계정에 사용한 Microsoft 계정으로 로그인합니다.
-
Microsoft Docs의 Build an object detector quickstart의 새 프로젝트 생성 섹션을 따라 새 Custom Vision 프로젝트를 생성합니다. UI는 변경될 수 있으므로 이 문서가 항상 최신 참조입니다.
프로젝트 이름을
stock-detector로 지정합니다.프로젝트를 생성할 때 이전에 생성한
stock-detector-training리소스를 사용하세요. 객체 감지 프로젝트 유형과 선반 위 제품 도메인을 선택합니다.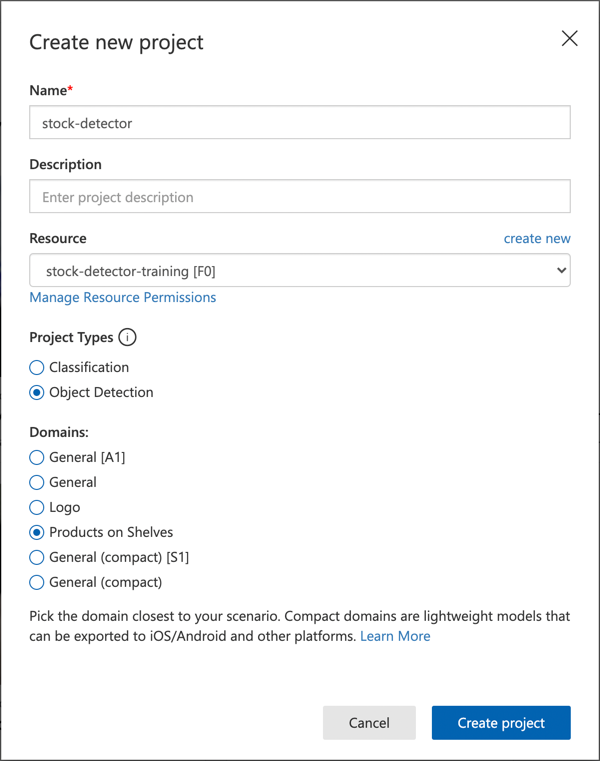
✅ 선반 위 제품 도메인은 매장 선반의 재고를 감지하는 데 특화되어 있습니다. Microsoft Docs의 도메인 선택 문서에서 다른 도메인에 대해 더 읽어보세요.
✅ 객체 감지기를 위한 Custom Vision UI를 탐색해보세요.
작업 - 객체 감지기 학습
모델을 학습시키려면 감지하려는 객체가 포함된 이미지 세트가 필요합니다.
-
감지하려는 객체가 포함된 이미지를 수집합니다. 각 객체를 감지하려면 최소 15개의 이미지가 필요하며, 다양한 각도와 조명 조건에서 촬영된 이미지가 필요합니다. 더 많을수록 좋습니다. 이 객체 감지기는 선반 위 제품 도메인을 사용하므로 객체를 매장 선반처럼 배치하여 이미지를 설정하세요. 모델을 테스트하려면 몇 개의 이미지도 필요합니다. 여러 객체를 감지하려는 경우 모든 객체가 포함된 테스트 이미지를 준비하세요.
💁 여러 다른 객체가 포함된 이미지는 이미지에 포함된 모든 객체에 대해 15개 이미지 최소 요구 사항에 포함됩니다.
이미지는 png 또는 jpeg 형식이어야 하며, 크기가 6MB보다 작아야 합니다. 예를 들어 iPhone으로 이미지를 생성하면 고해상도 HEIC 이미지일 수 있으므로 변환 및 축소가 필요할 수 있습니다. 더 많은 이미지가 좋으며, 익은 것과 익지 않은 것의 수가 비슷해야 합니다.
모델은 선반 위 제품을 대상으로 설계되었으므로 객체를 선반 위에 놓고 사진을 찍어보세요.
images 폴더에서 사용할 수 있는 캐슈넛과 토마토 페이스트의 예제 이미지를 찾을 수 있습니다.
-
Microsoft Docs의 Build an object detector quickstart의 이미지 업로드 및 태그 지정 섹션을 따라 학습 이미지를 업로드하세요. 감지하려는 객체 유형에 따라 관련 태그를 생성하세요.
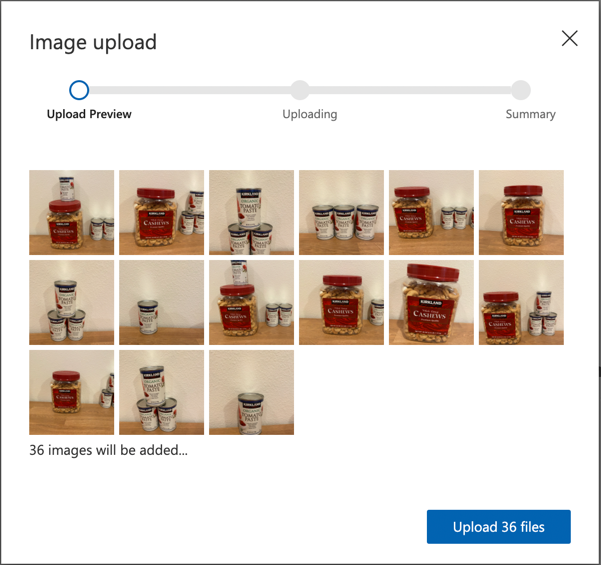
객체에 대한 경계 상자를 그릴 때 객체 주위에 딱 맞게 그리세요. 모든 이미지를 윤곽을 그리는 데 시간이 걸릴 수 있지만, 도구가 경계 상자를 감지하여 작업 속도를 높일 수 있습니다.

💁 각 객체에 대해 15개 이상의 이미지가 있는 경우, 15개로 학습한 후 제안된 태그 기능을 사용할 수 있습니다. 이 기능은 학습된 모델을 사용하여 태그가 없는 이미지에서 객체를 감지합니다. 감지된 객체를 확인하거나 거부하고 경계 상자를 다시 그릴 수 있습니다. 이는 시간을 많이 절약할 수 있습니다.
-
Microsoft Docs의 Build an object detector quickstart의 감지기 학습 섹션을 따라 태그가 지정된 이미지로 객체 감지기를 학습시키세요.
학습 유형을 선택할 때 빠른 학습을 선택하세요.
객체 감지기가 학습을 시작합니다. 학습이 완료되기까지 몇 분이 걸릴 수 있습니다.
객체 감지기 테스트
객체 감지기가 학습되면 새로운 이미지를 제공하여 객체를 감지하는지 테스트할 수 있습니다.
작업 - 객체 감지기 테스트
-
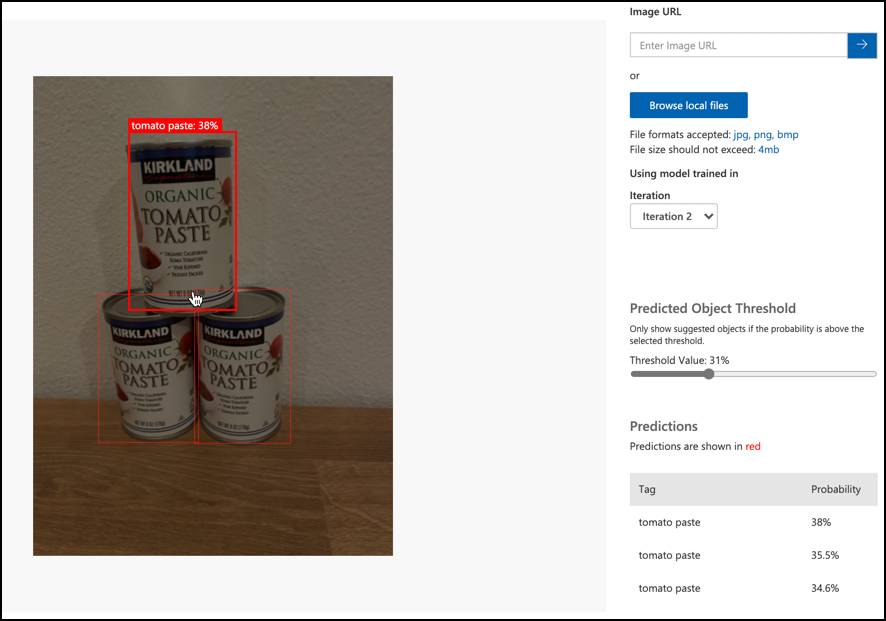
빠른 테스트 버튼을 사용하여 테스트 이미지를 업로드하고 객체가 감지되는지 확인하세요. 학습에 사용한 이미지가 아닌, 이전에 준비한 테스트 이미지를 사용하세요.
-
사용할 수 있는 모든 테스트 이미지를 시도하고 확률을 관찰하세요.
객체 감지기 재학습
객체 감지기를 테스트할 때 예상한 결과가 나오지 않을 수 있습니다. 이전 프로젝트의 이미지 분류기와 마찬가지로, 객체 감지기를 잘못된 결과를 제공한 이미지로 재학습시켜 개선할 수 있습니다.
빠른 테스트 옵션을 사용하여 예측을 수행할 때마다 이미지와 결과가 저장됩니다. 이러한 이미지를 사용하여 모델을 재학습시킬 수 있습니다.
-
예측 탭을 사용하여 테스트에 사용한 이미지를 찾으세요.
-
정확한 감지를 확인하고, 잘못된 감지를 삭제하며, 누락된 객체를 추가하세요.
-
모델을 재학습하고 다시 테스트하세요.
🚀 도전 과제
토마토 페이스트와 잘게 썬 토마토 같은 비슷한 모양의 항목을 객체 감지기에 사용하면 어떻게 될까요?
비슷한 모양의 항목이 있다면, 객체 감지기에 해당 항목의 이미지를 추가하여 테스트해보세요.
강의 후 퀴즈
복습 및 자기 학습
- 객체 감지기를 훈련시킬 때 생성된 모델을 평가하는 Precision (정밀도), Recall (재현율), mAP (평균 정밀도) 값을 확인했을 것입니다. 이러한 값이 무엇을 의미하는지 Microsoft 문서의 객체 감지기 빠른 시작 가이드의 "감지기 평가" 섹션을 읽고 알아보세요.
- 객체 감지에 대해 더 알고 싶다면 Wikipedia의 객체 감지 페이지를 참고하세요.
과제
면책 조항:
이 문서는 AI 번역 서비스 Co-op Translator를 사용하여 번역되었습니다. 정확성을 위해 최선을 다하고 있지만, 자동 번역에는 오류나 부정확성이 포함될 수 있습니다. 원본 문서를 해당 언어로 작성된 상태에서 권위 있는 자료로 간주해야 합니다. 중요한 정보의 경우, 전문적인 인간 번역을 권장합니다. 이 번역 사용으로 인해 발생하는 오해나 잘못된 해석에 대해 당사는 책임을 지지 않습니다.