|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
과일 품질 감지기 훈련하기
스케치노트 제공: Nitya Narasimhan. 이미지를 클릭하면 더 큰 버전을 볼 수 있습니다.
이 비디오는 Azure Custom Vision 서비스에 대한 개요를 제공합니다. 이 서비스는 이번 강의에서 다룰 예정입니다.

🎥 위 이미지를 클릭하여 비디오를 시청하세요.
강의 전 퀴즈
소개
최근 인공지능(AI)과 머신러닝(ML)의 발전은 오늘날 개발자들에게 다양한 기능을 제공하고 있습니다. ML 모델은 이미지에서 덜 익은 과일과 같은 다양한 대상을 인식하도록 훈련될 수 있으며, 이는 IoT 장치에서 수확 중이거나 공장 또는 창고에서 처리 중인 농산물을 분류하는 데 사용될 수 있습니다.
이번 강의에서는 이미지 분류, 즉 ML 모델을 사용하여 서로 다른 이미지를 구별하는 방법에 대해 배웁니다. 좋은 과일과 나쁜 과일(덜 익었거나 너무 익었거나, 멍들었거나 썩은)을 구별하는 이미지 분류기를 훈련하는 방법을 배우게 됩니다.
이번 강의에서 다룰 내용은 다음과 같습니다:
AI와 ML을 사용한 식품 분류
전 세계 인구를 먹여 살리는 일은 어렵습니다. 특히 모든 사람이 감당할 수 있는 가격으로 음식을 제공하는 것은 더욱 어렵습니다. 가장 큰 비용 중 하나는 노동비이며, 농부들은 점점 더 자동화와 IoT 같은 도구를 사용하여 노동비를 줄이고 있습니다. 손으로 수확하는 일은 노동 집약적이고 (종종 허리를 다치게 하는) 힘든 작업이며, 특히 부유한 국가에서는 기계로 대체되고 있습니다. 하지만 기계를 사용하여 수확 비용을 절감하는 데는 단점이 있습니다. 바로 수확 중에 식품을 분류하는 능력입니다.
모든 작물이 고르게 익는 것은 아닙니다. 예를 들어, 토마토는 대부분이 수확 준비가 되었을 때에도 덩굴에 여전히 녹색 과일이 남아 있을 수 있습니다. 이러한 과일을 일찍 수확하는 것은 낭비이지만, 농부에게는 기계를 사용하여 모든 것을 수확하고 나중에 덜 익은 농산물을 폐기하는 것이 더 저렴하고 쉽습니다.
✅ 근처 농장이나 정원, 또는 상점에서 자라는 다양한 과일이나 채소를 살펴보세요. 모두 같은 익은 상태인가요, 아니면 차이가 있나요?
자동 수확의 발전은 농산물 분류를 수확 현장에서 공장으로 옮겼습니다. 식품은 긴 컨베이어 벨트를 따라 이동하며, 팀이 품질 기준에 맞지 않는 농산물을 제거하는 작업을 수행했습니다. 기계를 사용하여 수확 비용은 줄었지만, 여전히 식품을 수작업으로 분류하는 데 비용이 들었습니다.
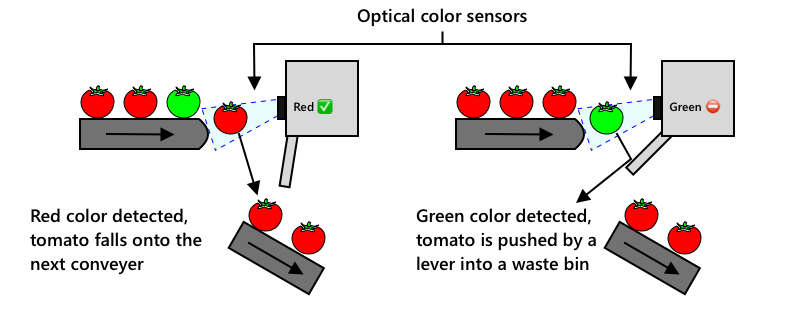
다음 단계는 수확기나 가공 공장에서 기계를 사용하여 분류하는 것이었습니다. 초기 기계는 광학 센서를 사용하여 색상을 감지하고, 레버나 공기 분사기를 사용하여 녹색 토마토를 폐기물 통으로 밀어내고 빨간 토마토는 컨베이어 벨트 네트워크를 따라 계속 이동하도록 했습니다.
이 비디오에서는 토마토가 한 컨베이어 벨트에서 다른 컨베이어 벨트로 떨어질 때, 녹색 토마토가 감지되어 레버로 폐기물 통으로 밀려나는 모습을 보여줍니다.
✅ 이러한 광학 센서가 제대로 작동하려면 공장이나 들판에서 어떤 조건이 필요할까요?
최신 분류 기계는 AI와 ML을 활용하여 발전했습니다. 이 기계들은 단순히 녹색 토마토와 빨간 토마토 같은 명백한 색상 차이뿐만 아니라, 질병이나 멍과 같은 미묘한 외관 차이를 통해 좋은 농산물과 나쁜 농산물을 구별하도록 훈련된 모델을 사용합니다.
머신러닝을 통한 이미지 분류
전통적인 프로그래밍에서는 데이터를 가져와 알고리즘을 적용하고 결과를 얻습니다. 예를 들어, 이전 프로젝트에서는 GPS 좌표와 지오펜스를 가져와 Azure Maps에서 제공한 알고리즘을 적용하여 해당 지점이 지오펜스 안에 있는지 밖에 있는지 결과를 얻었습니다. 더 많은 데이터를 입력하면 더 많은 결과를 얻을 수 있습니다.
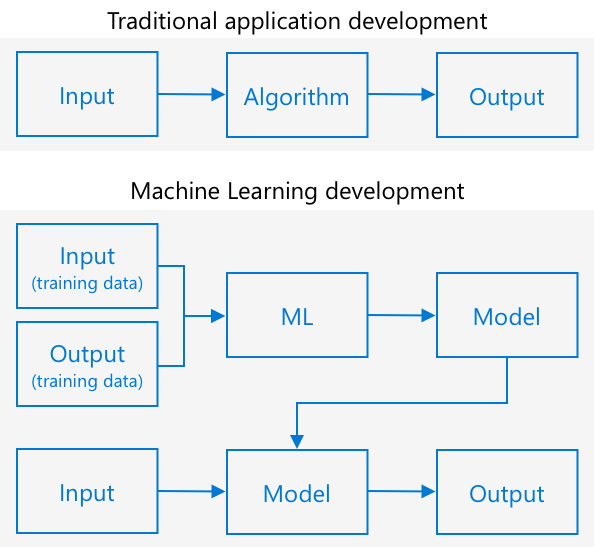
머신러닝은 이 과정을 뒤집습니다. 데이터를 알고 있는 출력과 함께 시작하고, 머신러닝 알고리즘이 데이터를 학습합니다. 그런 다음 훈련된 알고리즘(머신러닝 모델 또는 모델이라고 함)을 사용하여 새로운 데이터를 입력하고 새로운 출력을 얻을 수 있습니다.
🎓 머신러닝 알고리즘이 데이터를 학습하는 과정을 *훈련(training)*이라고 합니다. 입력과 알려진 출력은 *훈련 데이터(training data)*라고 합니다.
예를 들어, 모델에 덜 익은 바나나 사진 수백만 장을 입력 훈련 데이터로 제공하고, 출력 훈련 데이터를 덜 익음으로 설정하며, 익은 바나나 사진 수백만 장을 훈련 데이터로 제공하고 출력 훈련 데이터를 익음으로 설정할 수 있습니다. ML 알고리즘은 이 데이터를 기반으로 모델을 생성합니다. 그런 다음 이 모델에 새로운 바나나 사진을 제공하면, 그 사진이 익었는지 덜 익었는지 예측합니다.
🎓 ML 모델의 결과는 *예측(predictions)*이라고 합니다.

ML 모델은 이진 답변을 제공하지 않고, 대신 확률을 제공합니다. 예를 들어, 모델이 바나나 사진을 받아 익음 99.7%, 덜 익음 0.3%로 예측할 수 있습니다. 그런 다음 코드는 가장 높은 확률의 예측을 선택하여 바나나가 익었다고 결정합니다.
이미지를 감지하는 데 사용되는 ML 모델은 *이미지 분류기(image classifier)*라고 불립니다. 이 모델은 라벨이 지정된 이미지를 제공받아, 이러한 라벨을 기반으로 새로운 이미지를 분류합니다.
💁 이는 단순화된 설명이며, 라벨이 지정된 출력이 필요하지 않은 비지도 학습(unsupervised learning)과 같은 다른 모델 훈련 방법도 있습니다. ML에 대해 더 배우고 싶다면 ML for beginners, 머신러닝에 대한 24강 커리큘럼을 확인하세요.
이미지 분류기 훈련하기
이미지 분류기를 성공적으로 훈련하려면 수백만 장의 이미지가 필요합니다. 하지만, 수백만 또는 수십억 개의 다양한 이미지로 훈련된 이미지 분류기를 재사용하고, 소량의 이미지를 사용하여 재훈련하면 좋은 결과를 얻을 수 있습니다. 이를 *전이 학습(transfer learning)*이라고 합니다.
🎓 전이 학습은 기존 ML 모델의 학습을 새로운 데이터에 기반한 새로운 모델로 전이하는 것을 말합니다.
이미지 분류기가 다양한 이미지를 인식하도록 훈련되면, 내부적으로 모양, 색상, 패턴을 인식하는 데 매우 능숙해집니다. 전이 학습은 모델이 이미 학습한 이미지 요소를 활용하여 새로운 이미지를 인식하도록 합니다.
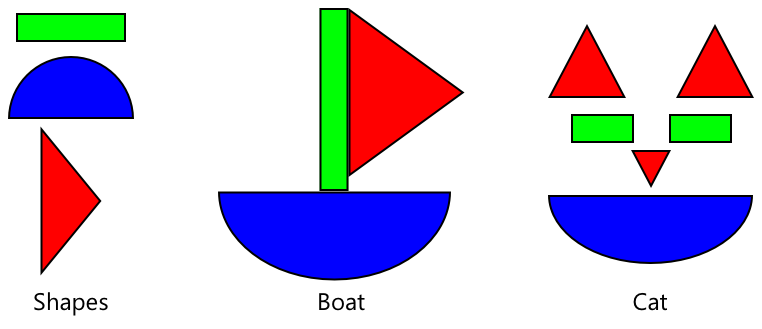
이를 어린이용 모양 책과 비슷하게 생각할 수 있습니다. 반원, 직사각형, 삼각형을 인식할 수 있다면, 이 모양의 조합으로 돛단배나 고양이를 인식할 수 있습니다. 이미지 분류기는 모양을 인식하고, 전이 학습은 어떤 조합이 돛단배나 고양이, 또는 익은 바나나를 만드는지 학습합니다.
이를 도와주는 다양한 도구가 있으며, 클라우드 기반 서비스는 모델을 훈련하고 웹 API를 통해 사용할 수 있도록 도와줍니다.
💁 이러한 모델을 훈련하려면 많은 컴퓨터 성능이 필요하며, 주로 그래픽 처리 장치(GPU)를 사용합니다. Xbox 게임을 멋지게 보이게 만드는 동일한 하드웨어가 머신러닝 모델을 훈련하는 데도 사용될 수 있습니다. 클라우드를 사용하면 GPU가 장착된 강력한 컴퓨터를 임대하여 모델을 훈련할 수 있으며, 필요한 시간 동안만 컴퓨팅 성능을 사용할 수 있습니다.
Custom Vision
Custom Vision은 이미지 분류기를 훈련하기 위한 클라우드 기반 도구입니다. 소량의 이미지만으로도 분류기를 훈련할 수 있습니다. 웹 포털, 웹 API 또는 SDK를 통해 이미지를 업로드하고, 각 이미지에 해당 이미지의 분류를 나타내는 태그를 지정할 수 있습니다. 그런 다음 모델을 훈련하고, 성능을 테스트합니다. 모델에 만족하면, 웹 API 또는 SDK를 통해 액세스할 수 있는 버전을 게시할 수 있습니다.
![]()
💁 Custom Vision 모델은 분류당 최소 5개의 이미지로 훈련할 수 있지만, 더 많은 이미지가 더 좋습니다. 최소 30개의 이미지로 더 나은 결과를 얻을 수 있습니다.
Custom Vision은 Microsoft의 AI 도구 모음인 Cognitive Services의 일부입니다. 이 도구들은 훈련 없이 또는 소량의 훈련으로 사용할 수 있는 AI 도구들로, 음성 인식 및 번역, 언어 이해, 이미지 분석 등을 포함합니다. Azure에서 무료 계층으로 제공됩니다.
💁 무료 계층은 모델을 생성하고 훈련하며 개발 작업에 사용할 수 있는 충분한 용량을 제공합니다. 무료 계층의 제한 사항은 Microsoft 문서의 Custom Vision 제한 및 할당량 페이지에서 확인할 수 있습니다.
작업 - Cognitive Services 리소스 생성
Custom Vision을 사용하려면 먼저 Azure CLI를 사용하여 Custom Vision 훈련용 리소스와 Custom Vision 예측용 리소스 두 개를 생성해야 합니다.
-
이 프로젝트를 위한
fruit-quality-detector라는 리소스 그룹을 생성합니다. -
다음 명령어를 사용하여 무료 Custom Vision 훈련 리소스를 생성합니다:
az cognitiveservices account create --name fruit-quality-detector-training \ --resource-group fruit-quality-detector \ --kind CustomVision.Training \ --sku F0 \ --yes \ --location <location><location>을 리소스 그룹을 생성할 때 사용한 위치로 바꿉니다.이 명령어는
fruit-quality-detector-training이라는 이름의 Custom Vision 훈련 리소스를 리소스 그룹에 생성하며, 무료 계층인F0SKU를 사용합니다.--yes옵션은 Cognitive Services의 약관에 동의함을 의미합니다.
💁 Cognitive Services의 무료 계정을 이미 사용 중이라면
S0SKU를 사용하세요.
-
다음 명령어를 사용하여 무료 Custom Vision 예측 리소스를 생성합니다:
az cognitiveservices account create --name fruit-quality-detector-prediction \ --resource-group fruit-quality-detector \ --kind CustomVision.Prediction \ --sku F0 \ --yes \ --location <location><location>을 리소스 그룹을 생성할 때 사용한 위치로 바꿉니다.이 명령어는
fruit-quality-detector-prediction이라는 이름의 Custom Vision 예측 리소스를 리소스 그룹에 생성하며, 무료 계층인F0SKU를 사용합니다.--yes옵션은 Cognitive Services의 약관에 동의함을 의미합니다.
작업 - 이미지 분류기 프로젝트 생성
-
CustomVision.ai 포털을 열고, Azure 계정에 사용한 Microsoft 계정으로 로그인합니다.
-
Microsoft 문서의 분류기 빠른 시작 가이드에서 새 프로젝트 생성 섹션을 따라 새 Custom Vision 프로젝트를 생성합니다. UI는 변경될 수 있으므로, 이 문서가 항상 최신 참조 자료입니다.
프로젝트 이름을
fruit-quality-detector로 설정합니다.프로젝트를 생성할 때, 이전에 생성한
fruit-quality-detector-training리소스를 사용하세요. 분류(Classification) 프로젝트 유형, 다중 클래스(Multiclass) 분류 유형, 식품(Food) 도메인을 선택합니다.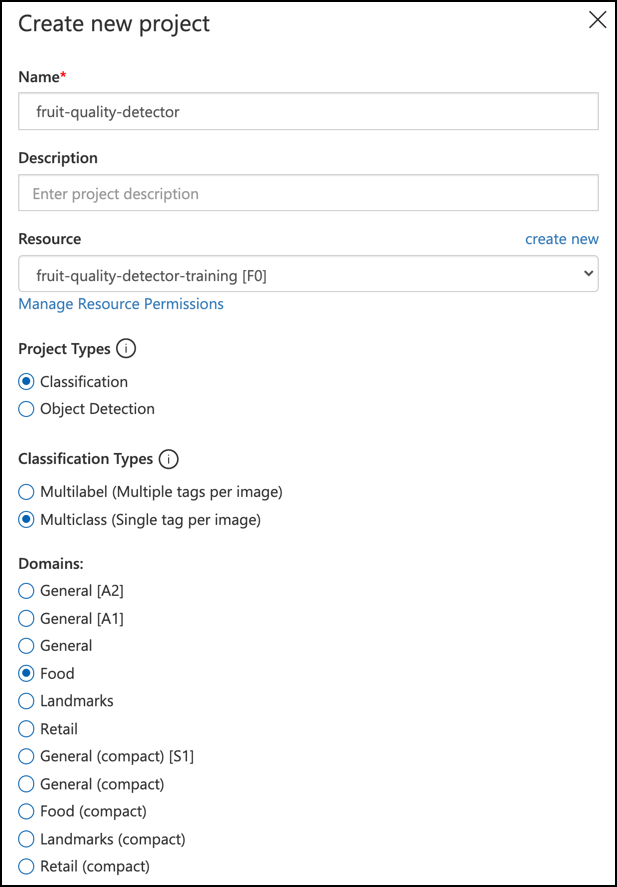
✅ 이미지 분류기를 위한 Custom Vision UI를 탐색하는 데 시간을 가져보세요.
작업 - 이미지 분류기 프로젝트 훈련
이미지 분류기를 훈련하려면, 좋은 품질과 나쁜 품질의 과일 사진(예: 익은 바나나와 너무 익은 바나나)을 다수 준비하여 각각을 좋은(good)과 나쁜(bad)으로 태그해야 합니다. 💁 이 분류기는 어떤 이미지든 분류할 수 있으므로, 품질이 다른 과일이 없다면 두 가지 다른 종류의 과일이나 고양이와 개를 사용할 수도 있습니다! 이상적으로 각 사진은 과일만 포함되어야 하며, 배경은 일관되거나 다양한 배경을 사용할 수 있습니다. 배경에 익은 과일과 덜 익은 과일을 구분할 수 있는 특정 요소가 포함되지 않도록 주의하세요.
💁 특정 배경이나 분류와 관련 없는 특정 항목이 태그별로 포함되어 있으면, 분류기가 배경을 기준으로 분류할 가능성이 있습니다. 예를 들어, 피부암 분류기를 정상 및 암성 점을 대상으로 훈련시켰을 때, 암성 점에는 크기를 측정하기 위해 항상 자가 포함되어 있었습니다. 결과적으로 분류기는 암성 점이 아닌 사진 속 자를 거의 100% 정확도로 식별하는 데 성공했습니다.
이미지 분류기는 매우 낮은 해상도로 실행됩니다. 예를 들어, Custom Vision은 최대 10240x10240 크기의 훈련 및 예측 이미지를 처리할 수 있지만, 모델은 227x227 크기의 이미지로 훈련되고 실행됩니다. 더 큰 이미지는 이 크기로 축소되므로, 분류하려는 대상이 이미지에서 큰 부분을 차지하도록 해야 합니다. 그렇지 않으면 분류기가 사용하는 작은 이미지에서 너무 작게 보일 수 있습니다.
-
분류기를 위한 사진을 모으세요. 각 라벨을 훈련시키기 위해 최소 5장의 사진이 필요하며, 많을수록 좋습니다. 또한 분류기를 테스트하기 위해 몇 장의 추가 이미지를 준비해야 합니다. 이 이미지는 동일한 대상을 다른 각도에서 찍은 서로 다른 사진이어야 합니다. 예를 들어:
-
익은 바나나 2개를 사용하여 각각 다른 각도에서 최소 7장의 사진(훈련용 5장, 테스트용 2장)을 찍으세요. 이상적으로는 더 많은 사진을 찍는 것이 좋습니다.

-
같은 과정을 덜 익은 바나나 2개로 반복하세요.
최소 10장의 훈련 이미지를 준비하세요. 익은 바나나 5장, 덜 익은 바나나 5장, 그리고 테스트용으로 익은 바나나 2장, 덜 익은 바나나 2장. 이미지는 png 또는 jpeg 형식이어야 하며, 크기는 6MB 이하이어야 합니다. 예를 들어 iPhone으로 이미지를 생성하면 고해상도 HEIC 형식일 수 있으므로 변환 및 축소가 필요할 수 있습니다. 이미지가 많을수록 좋으며, 익은 과일과 덜 익은 과일의 수가 비슷해야 합니다.
익은 과일과 덜 익은 과일이 모두 없다면, 다른 과일이나 사용 가능한 두 개의 물체를 사용할 수 있습니다. 또한 images 폴더에서 익은 바나나와 덜 익은 바나나의 예제 이미지를 찾아 사용할 수 있습니다.
-
-
Microsoft 문서의 분류기 빠른 시작에서 이미지 업로드 및 태그 지정 섹션을 따라 훈련 이미지를 업로드하세요. 익은 과일은
ripe로, 덜 익은 과일은unripe로 태그를 지정하세요.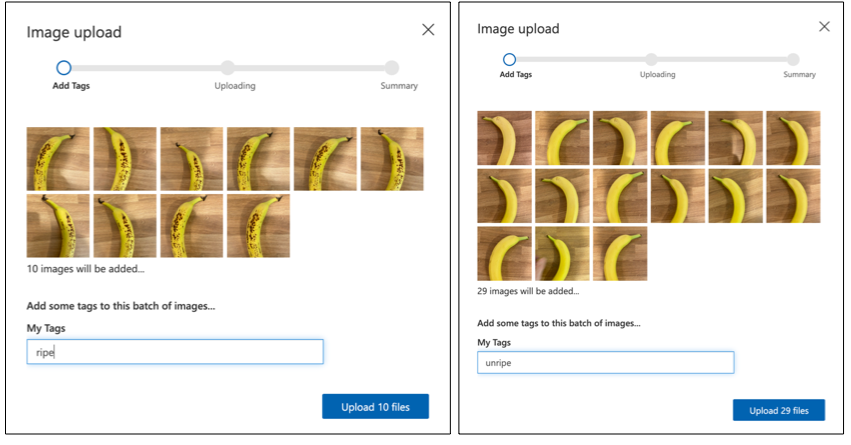
-
Microsoft 문서의 분류기 훈련 섹션을 따라 업로드한 이미지로 이미지 분류기를 훈련시키세요.
훈련 유형을 선택할 때 **빠른 훈련(Quick Training)**을 선택하세요.
분류기가 훈련을 시작합니다. 훈련이 완료되기까지 몇 분이 소요됩니다.
🍌 분류기가 훈련되는 동안 과일을 먹기로 했다면, 먼저 테스트용 이미지를 충분히 준비했는지 확인하세요!
이미지 분류기 테스트하기
분류기가 훈련된 후, 새로운 이미지를 제공하여 분류기를 테스트할 수 있습니다.
작업 - 이미지 분류기 테스트하기
-
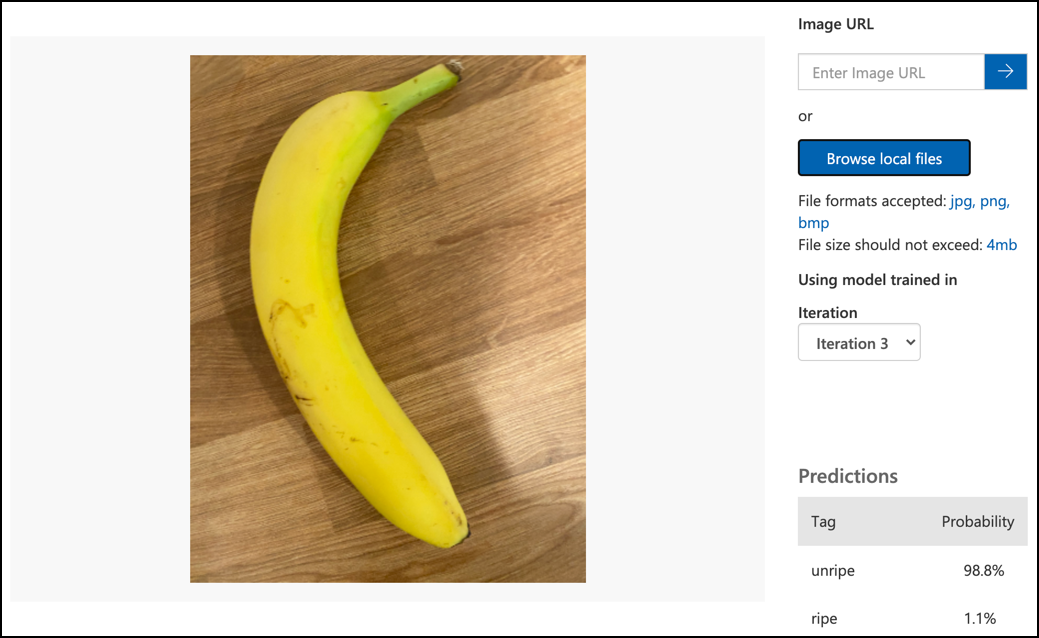
Microsoft 문서의 모델 테스트 섹션을 따라 이미지 분류기를 테스트하세요. 이전에 준비한 테스트 이미지를 사용하고, 훈련에 사용한 이미지는 사용하지 마세요.
-
사용할 수 있는 모든 테스트 이미지를 시도하고 확률을 관찰하세요.
이미지 분류기 재훈련하기
분류기를 테스트할 때 예상한 결과가 나오지 않을 수 있습니다. 이미지 분류기는 이미지에 있는 특정 특징이 특정 라벨과 일치할 확률을 기반으로 예측을 수행합니다. 이미지에 무엇이 있는지 이해하지 못하며, 바나나가 무엇인지 또는 바나나가 배가 아닌 바나나로 구분되는 이유를 이해하지 못합니다. 분류기가 잘못된 결과를 내는 이미지를 사용하여 재훈련하면 분류기를 개선할 수 있습니다.
빠른 테스트 옵션을 사용하여 예측을 수행할 때마다 이미지와 결과가 저장됩니다. 이러한 이미지를 사용하여 모델을 재훈련할 수 있습니다.
작업 - 이미지 분류기 재훈련하기
-
Microsoft 문서의 예측된 이미지를 사용한 훈련 섹션을 따라 각 이미지에 올바른 태그를 지정하여 모델을 재훈련하세요.
-
모델이 재훈련된 후 새로운 이미지로 테스트하세요.
🚀 도전
바나나로 훈련된 모델에 딸기 사진을 사용하거나, 바나나 모양의 풍선, 바나나 의상을 입은 사람, 또는 심지어 심슨 가족 같은 노란색 만화 캐릭터 사진을 사용하면 어떤 일이 일어날지 생각해보세요.
직접 시도해보고 예측 결과를 확인하세요. Bing 이미지 검색을 사용하여 시도할 이미지를 찾아볼 수 있습니다.
강의 후 퀴즈
복습 및 자기 학습
- 분류기를 훈련시킬 때 생성된 모델을 평가하는 Precision, Recall, AP 값을 확인했을 것입니다. Microsoft 문서의 분류기 평가 섹션을 읽고 이러한 값이 무엇인지 알아보세요.
- Microsoft 문서의 Custom Vision 모델 개선 방법을 읽고 분류기를 개선하는 방법을 알아보세요.
과제
면책 조항:
이 문서는 AI 번역 서비스 Co-op Translator를 사용하여 번역되었습니다. 정확성을 위해 최선을 다하고 있지만, 자동 번역에는 오류나 부정확성이 포함될 수 있습니다. 원본 문서의 원어 버전을 권위 있는 출처로 간주해야 합니다. 중요한 정보의 경우, 전문적인 인간 번역을 권장합니다. 이 번역 사용으로 인해 발생하는 오해나 잘못된 해석에 대해 책임을 지지 않습니다.