|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
果物の品質検出器を訓練する
スケッチノート作成者:Nitya Narasimhan。画像をクリックすると拡大版が表示されます。
このビデオでは、Azure Custom Vision サービスの概要を説明しています。このレッスンで取り上げる内容です。

🎥 上の画像をクリックしてビデオを視聴してください
講義前のクイズ
はじめに
近年の人工知能(AI)や機械学習(ML)の進化により、今日の開発者に幅広い能力が提供されています。MLモデルは画像内のさまざまなものを認識するように訓練することができ、未熟な果物を認識することも可能です。これにより、IoTデバイスを使用して収穫中や工場や倉庫での処理中に農産物を仕分けることができます。
このレッスンでは、画像分類について学びます。MLモデルを使用して異なるものの画像を区別する方法です。良い果物と悪い果物(未熟、熟しすぎ、傷ついたもの、腐ったもの)を区別する画像分類器を訓練する方法を学びます。
このレッスンで取り上げる内容は以下の通りです:
AIとMLを使った食品の仕分け
世界の人口を養うことは困難です。特に、すべての人が手頃な価格で食料を手に入れられるようにするには大変です。最大のコストの一つは労働力であり、農家は労働コストを削減するために自動化やIoTのようなツールにますます依存しています。手作業での収穫は労働集約的(そしてしばしば過酷な作業)であり、特に裕福な国々では機械による収穫に置き換えられています。機械を使用することで収穫コストは削減されますが、収穫中に食品を仕分ける能力が失われるという欠点があります。
すべての作物が均一に熟すわけではありません。例えばトマトは、大部分が収穫可能な状態になっていても、まだ緑色の果実が残っていることがあります。これらを早く収穫するのは無駄ですが、農家にとっては機械を使ってすべてを収穫し、未熟な作物を後で廃棄する方が安価で簡単です。
✅ 農場や庭、またはお店で育っているさまざまな果物や野菜を観察してみてください。それらはすべて同じ熟度ですか、それともばらつきがありますか?
自動収穫の普及により、農産物の仕分けは収穫から工場へと移行しました。食品は長いコンベアベルトで運ばれ、チームが品質基準を満たさないものを取り除く作業を行います。機械による収穫でコストは削減されましたが、食品を手作業で仕分けるコストは依然として存在しました。
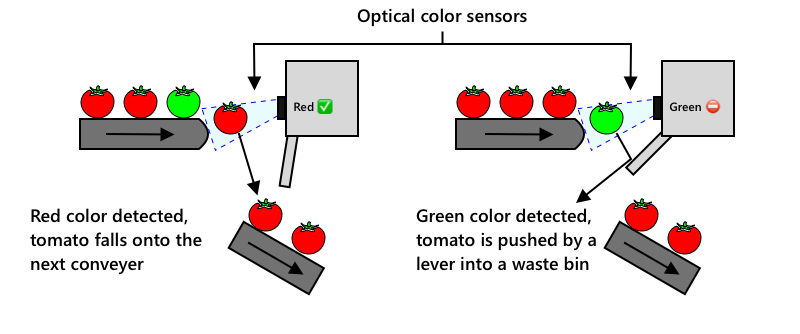
次の進化は、収穫機や加工工場に組み込まれた機械を使用して仕分けを行うことでした。これらの機械の第一世代は、光学センサーを使用して色を検出し、アクチュエーターを制御して緑のトマトをレバーや空気の噴射で廃棄箱に押し込み、赤いトマトをコンベアベルトのネットワークにそのまま流す仕組みでした。
このビデオでは、トマトが一つのコンベアベルトから別のベルトに落ちる際に、緑のトマトが検出され、レバーで廃棄箱に弾かれる様子が示されています。
✅ 工場や畑でこれらの光学センサーが正しく機能するためには、どのような条件が必要だと思いますか?
これらの仕分け機の最新の進化形は、AIとMLを活用しています。モデルを訓練して、緑のトマトと赤いトマトのような明らかな色の違いだけでなく、病気や傷を示す微妙な外観の違いを識別できるようにしています。
機械学習による画像分類
従来のプログラミングでは、データを取得し、そのデータにアルゴリズムを適用して出力を得ます。例えば、前回のプロジェクトでは、GPS座標とジオフェンスを取得し、Azure Mapsが提供するアルゴリズムを適用して、そのポイントがジオフェンス内か外かの結果を得ました。より多くのデータを入力すれば、より多くの出力が得られます。
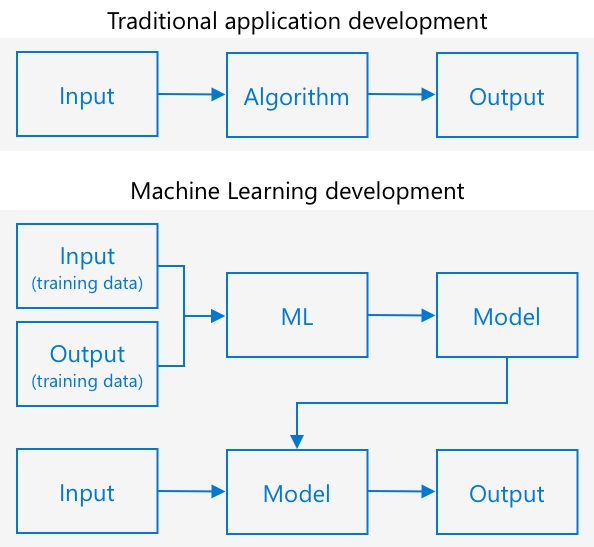
機械学習ではこれが逆になります。データと既知の出力から始め、機械学習アルゴリズムがデータから学習します。その後、この訓練されたアルゴリズム(機械学習モデルまたはモデルと呼ばれる)を使用して新しいデータを入力し、新しい出力を得ることができます。
🎓 機械学習アルゴリズムがデータから学習するプロセスを訓練と呼びます。入力データと既知の出力は訓練データと呼ばれます。
例えば、未熟なバナナの写真を何百万枚もモデルに入力データとして与え、訓練出力を未熟と設定し、熟したバナナの写真を何百万枚も訓練データとして与え、出力を熟したと設定します。MLアルゴリズムはこのデータを基にモデルを作成します。その後、このモデルに新しいバナナの写真を与えると、その写真が熟しているか未熟であるかを予測します。
🎓 MLモデルの結果は予測と呼ばれます。

MLモデルは二択の答えを出すのではなく、確率を提供します。例えば、モデルがバナナの写真を与えられた場合、熟しているが99.7%、未熟が0.3%と予測するかもしれません。コードは最も高い予測を選び、そのバナナが熟していると判断します。
画像を検出するために使用されるMLモデルは画像分類器と呼ばれます。ラベル付けされた画像を与えられ、それに基づいて新しい画像を分類します。
💁 これは簡略化した説明です。ラベル付けされた出力を必要としない教師なし学習など、他にも多くのモデル訓練方法があります。MLについてもっと学びたい場合は、ML for beginners(機械学習の24レッスンカリキュラム)をチェックしてください。
画像分類器を訓練する
画像分類器を成功裏に訓練するには、何百万枚もの画像が必要です。しかし、何百万枚、何十億枚ものさまざまな画像で訓練された画像分類器があれば、それを再利用して少量の画像で再訓練し、優れた結果を得ることができます。このプロセスは転移学習と呼ばれます。
🎓 転移学習とは、既存のMLモデルの学習を新しいデータに基づいた新しいモデルに転移することです。
一度幅広い画像で訓練された画像分類器は、形状、色、パターンを認識する能力に優れています。転移学習により、画像の部分を認識する能力を活用して、新しい画像を認識することができます。
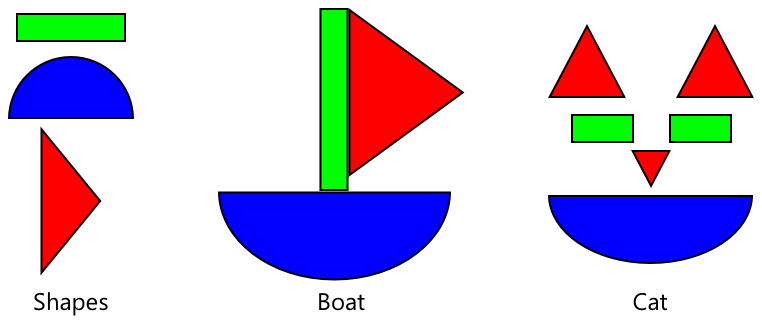
これは、子供向けの形状絵本のようなものです。半円、長方形、三角形を認識できれば、それらの配置によって帆船や猫を認識できるようになります。画像分類器は形状を認識し、転移学習によって帆船や猫、あるいは熟したバナナを構成する組み合わせを学びます。
これを実現するためのツールは幅広く存在し、クラウドベースのサービスを利用してモデルを訓練し、Web APIを通じて使用することができます。
💁 これらのモデルを訓練するには大量の計算能力が必要です。通常はグラフィックス処理ユニット(GPU)を使用します。Xboxのゲームを美しく見せるための特殊なハードウェアは、機械学習モデルの訓練にも使用できます。クラウドを利用することで、これらのモデルを訓練するために必要な強力なコンピュータを時間単位で借りることができ、必要な計算能力を必要な時間だけ利用できます。
Custom Vision
Custom Visionは、画像分類器を訓練するためのクラウドベースのツールです。少量の画像を使用して分類器を訓練することができます。画像をWebポータル、Web API、またはSDKを通じてアップロードし、各画像にその分類を示すタグを付けます。その後、モデルを訓練し、どれだけうまく機能するかをテストします。モデルに満足したら、Web APIやSDKを通じてアクセス可能なバージョンを公開できます。
![]()
💁 Custom Visionモデルは、分類ごとに最低5枚の画像で訓練できますが、多い方が良いです。少なくとも30枚の画像があると、より良い結果が得られます。
Custom Visionは、MicrosoftのAIツール群であるCognitive Servicesの一部です。これらは、訓練なし、または少量の訓練で使用できるAIツールです。音声認識や翻訳、言語理解、画像分析などが含まれます。これらはAzureのサービスとして無料枠で利用可能です。
💁 無料枠は、モデルを作成し、訓練し、開発作業に使用するには十分です。無料枠の制限については、Microsoft DocsのCustom Visionの制限とクォータのページをご覧ください。
タスク - Cognitive Servicesリソースを作成する
Custom Visionを使用するには、Azure CLIを使用してAzureに2つのCognitive Servicesリソースを作成する必要があります。1つはCustom Visionの訓練用、もう1つはCustom Visionの予測用です。
-
このプロジェクト用に
fruit-quality-detectorという名前のリソースグループを作成します。 -
以下のコマンドを使用して、無料のCustom Vision訓練リソースを作成します:
az cognitiveservices account create --name fruit-quality-detector-training \ --resource-group fruit-quality-detector \ --kind CustomVision.Training \ --sku F0 \ --yes \ --location <location><location>をリソースグループを作成した場所に置き換えてください。これにより、リソースグループ内にCustom Vision訓練リソースが作成されます。このリソースは
fruit-quality-detector-trainingと呼ばれ、無料枠であるF0スキューを使用します。--yesオプションは、Cognitive Servicesの利用規約に同意することを意味します。
💁 すでにCognitive Servicesの無料アカウントを使用している場合は、
S0スキューを使用してください。
-
以下のコマンドを使用して、無料のCustom Vision予測リソースを作成します:
az cognitiveservices account create --name fruit-quality-detector-prediction \ --resource-group fruit-quality-detector \ --kind CustomVision.Prediction \ --sku F0 \ --yes \ --location <location><location>をリソースグループを作成した場所に置き換えてください。これにより、リソースグループ内にCustom Vision予測リソースが作成されます。このリソースは
fruit-quality-detector-predictionと呼ばれ、無料枠であるF0スキューを使用します。--yesオプションは、Cognitive Servicesの利用規約に同意することを意味します。
タスク - 画像分類器プロジェクトを作成する
-
CustomVision.aiのCustom Visionポータルを開き、Azureアカウントで使用しているMicrosoftアカウントでサインインします。
-
Microsoft Docsの画像分類器クイックスタートの新しいプロジェクト作成セクションに従って、新しいCustom Visionプロジェクトを作成します。UIは変更される可能性があるため、これらのドキュメントが常に最新の参考資料です。
プロジェクト名を
fruit-quality-detectorとします。プロジェクトを作成する際、先ほど作成した
fruit-quality-detector-trainingリソースを使用してください。分類プロジェクトタイプ、マルチクラス分類タイプ、食品ドメインを選択します。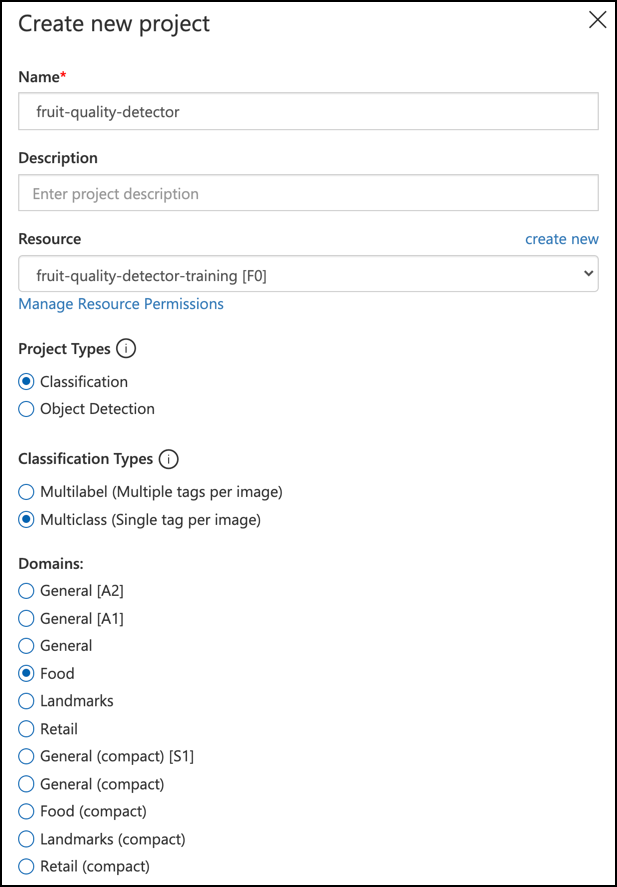
✅ 画像分類器のCustom Vision UIを探索する時間を取ってみてください。
タスク - 画像分類器プロジェクトを訓練する
画像分類器を訓練するには、良い品質と悪い品質の果物の写真が複数必要です。例えば、熟したバナナと熟しすぎたバナナなどを良いと悪いとしてタグ付けします。 💁 これらの分類器は、どんなものの画像でも分類できます。そのため、品質の異なる果物が手元にない場合は、異なる種類の果物や、猫と犬を使うこともできます! 理想的には、各写真には果物だけが写っているべきです。背景は一貫性があるか、または多様性があるべきですが、熟しているか未熟であるかを特定するような背景は避けてください。
💁 特定の背景や分類対象に関連しないアイテムがタグごとに含まれていると、分類器が背景に基づいて分類してしまう可能性があります。例えば、皮膚がんの分類器が正常なほくろとがん性のほくろを学習した際、がん性のほくろにはサイズを測るための定規が写っていました。その結果、分類器はがん性のほくろではなく、写真内の定規をほぼ100%の精度で識別するようになってしまいました。
画像分類器は非常に低解像度で動作します。例えば、Custom Visionでは最大10240x10240のトレーニングおよび予測画像を使用できますが、モデルは227x227の画像でトレーニングおよび実行されます。大きな画像はこのサイズに縮小されるため、分類対象が画像の大部分を占めるようにしないと、分類器が使用する小さな画像では対象が小さすぎる可能性があります。
-
分類器用の写真を集めます。各ラベルに対して少なくとも5枚の写真が必要ですが、多ければ多いほど良いです。また、分類器をテストするための追加の画像も必要です。これらの画像はすべて同じ対象の異なる画像であるべきです。例えば:
-
熟したバナナ2本を使用し、それぞれを異なる角度から撮影して少なくとも7枚の写真を撮ります(5枚はトレーニング用、2枚はテスト用)。理想的にはもっと多く撮影してください。

-
同じプロセスを未熟なバナナ2本でも繰り返します。
少なくとも10枚のトレーニング画像(熟したもの5枚、未熟なもの5枚)と4枚のテスト画像(熟したもの2枚、未熟なもの2枚)が必要です。画像はpngまたはjpeg形式で、6MB以下であるべきです。例えばiPhoneで作成した場合、高解像度のHEIC画像になる可能性があるため、変換して縮小する必要があります。画像は多ければ多いほど良く、熟したものと未熟なものの数を均等にするべきです。
熟した果物と未熟な果物の両方がない場合は、異なる果物や手元にある任意の2つの物体を使用できます。また、熟したバナナと未熟なバナナの例画像をimagesフォルダーで見つけることができます。
-
-
Microsoft Docsの分類器クイックスタートの画像アップロードとタグ付けセクションに従い、トレーニング画像をアップロードします。熟した果物には
ripe、未熟な果物にはunripeというタグを付けます。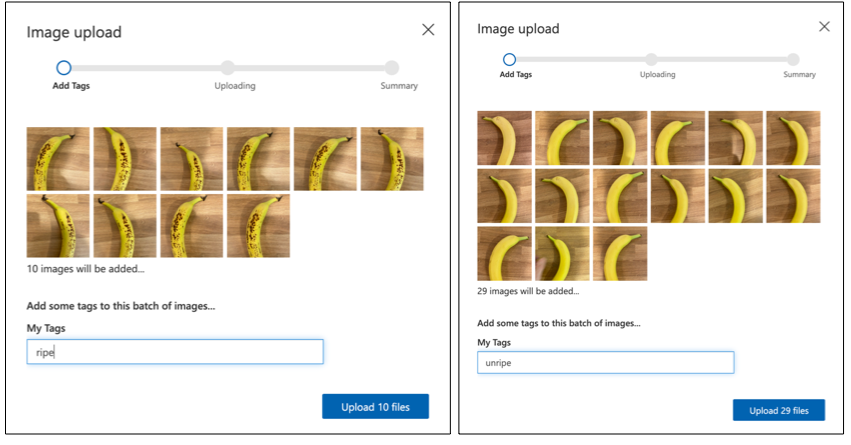
-
Microsoft Docsの分類器クイックスタートの分類器をトレーニングするセクションに従い、アップロードした画像で画像分類器をトレーニングします。
トレーニングタイプの選択肢が表示されます。Quick Trainingを選択してください。
分類器がトレーニングを開始します。トレーニングが完了するまで数分かかります。
🍌 分類器のトレーニング中に果物を食べる場合は、テスト用の画像が十分にあることを確認してください!
画像分類器をテストする
分類器がトレーニングされたら、新しい画像を与えて分類をテストすることができます。
タスク - 画像分類器をテストする
-
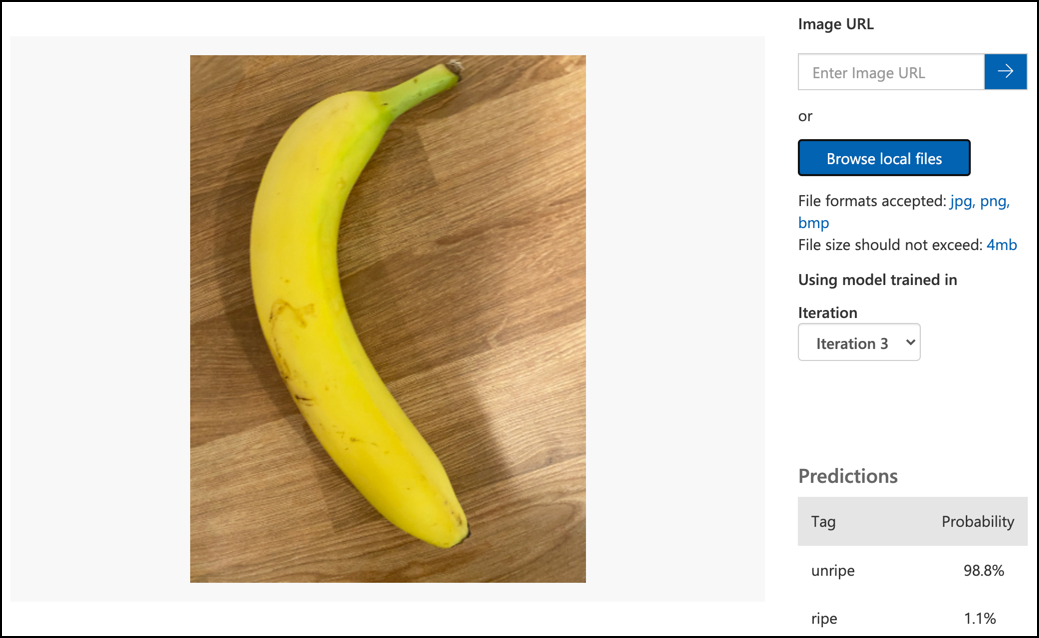
Microsoft Docsのモデルをテストするドキュメントに従い、画像分類器をテストします。以前に作成したテスト画像を使用し、トレーニングに使用した画像は使用しないでください。
-
利用可能なすべてのテスト画像を試し、確率を観察してください。
画像分類器を再トレーニングする
分類器をテストした際、期待した結果が得られない場合があります。画像分類器は、画像内の特定の特徴が特定のラベルに一致する確率に基づいて予測を行います。画像の内容を理解しているわけではなく、バナナが何であるかやバナナがボートではなくバナナである理由を理解しているわけではありません。分類器が間違った結果を出した画像を使用して再トレーニングすることで、分類器を改善することができます。
クイックテストオプションを使用して予測を行うたびに、画像と結果が保存されます。これらの画像を使用してモデルを再トレーニングすることができます。
タスク - 画像分類器を再トレーニングする
-
Microsoft Docsの予測画像をトレーニングに使用するドキュメントに従い、各画像に正しいタグを付けてモデルを再トレーニングします。
-
モデルを再トレーニングしたら、新しい画像でテストしてください。
🚀 チャレンジ
バナナでトレーニングされたモデルにイチゴの写真を使用したらどうなると思いますか?または、空気で膨らませたバナナ、バナナの衣装を着た人、さらには黄色いアニメキャラクター(例えばシンプソンズのキャラクター)を使用したらどうなるでしょうか?
試してみて、予測結果を確認してください。Bing画像検索を使用して試す画像を見つけることができます。
講義後のクイズ
レビューと自己学習
- 分類器をトレーニングした際、作成されたモデルを評価するためのPrecision、Recall、APの値が表示されます。Microsoft Docsの分類器クイックスタートの分類器を評価するセクションを使用してこれらの値について調べてください。
- Microsoft DocsのCustom Visionモデルを改善する方法を読んで分類器を改善する方法について学んでください。
課題
免責事項:
この文書は、AI翻訳サービス Co-op Translator を使用して翻訳されています。正確性を追求しておりますが、自動翻訳には誤りや不正確な部分が含まれる可能性があることをご承知ください。元の言語で記載された文書が正式な情報源とみなされるべきです。重要な情報については、専門の人間による翻訳を推奨します。この翻訳の使用に起因する誤解や誤解釈について、当社は一切の責任を負いません。