|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
| pi-text-to-speech.md | 3 weeks ago | |
| single-board-computer-set-timer.md | 3 weeks ago | |
| virtual-device-text-to-speech.md | 3 weeks ago | |
| wio-terminal-set-timer.md | 3 weeks ago | |
| wio-terminal-text-to-speech.md | 3 weeks ago | |
README.md
Postavite mjerač vremena i pružite povratne informacije putem govora
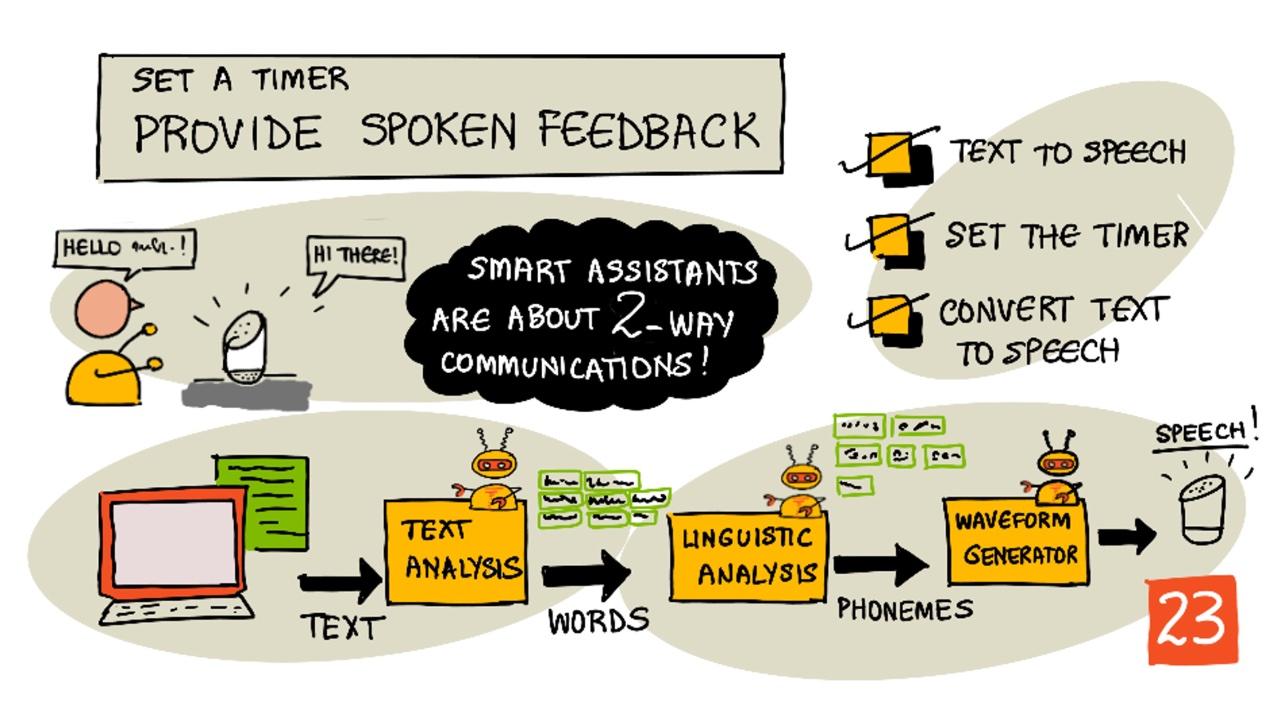
Sketchnote autor Nitya Narasimhan. Kliknite na sliku za veću verziju.
Kviz prije predavanja
Uvod
Pametni asistenti nisu uređaji za jednosmjernu komunikaciju. Vi govorite njima, a oni odgovaraju:
"Alexa, postavi mjerač vremena na 3 minute"
"U redu, vaš mjerač vremena je postavljen na 3 minute"
U posljednje dvije lekcije naučili ste kako pretvoriti govor u tekst, a zatim izvući zahtjev za postavljanje mjerača vremena iz tog teksta. U ovoj lekciji naučit ćete kako postaviti mjerač vremena na IoT uređaju, odgovoriti korisniku govornim riječima koje potvrđuju njihov mjerač vremena i obavijestiti ih kada njihov mjerač vremena završi.
U ovoj lekciji obradit ćemo:
Tekst u govor
Tekst u govor, kako naziv sugerira, proces je pretvaranja teksta u audio koji sadrži tekst kao izgovorene riječi. Osnovni princip je razbijanje riječi u tekstu na njihove sastavne zvukove (poznate kao fonemi) i spajanje audija za te zvukove, bilo korištenjem unaprijed snimljenog audija ili audija generiranog AI modelima.

Sustavi za tekst u govor obično imaju 3 faze:
- Analiza teksta
- Lingvistička analiza
- Generiranje valnog oblika
Analiza teksta
Analiza teksta uključuje uzimanje danog teksta i pretvaranje u riječi koje se mogu koristiti za generiranje govora. Na primjer, ako pretvarate "Hello world", nije potrebna analiza teksta, te dvije riječi mogu se odmah pretvoriti u govor. Ako imate "1234", međutim, to bi moglo trebati pretvoriti u riječi "Jedna tisuća, dvjesto trideset četiri" ili "Jedan, dva, tri, četiri" ovisno o kontekstu. Za "Imam 1234 jabuka", to bi bilo "Jedna tisuća, dvjesto trideset četiri", ali za "Dijete je izbrojalo 1234" to bi bilo "Jedan, dva, tri, četiri".
Riječi koje se generiraju variraju ne samo za jezik, već i za lokalitet tog jezika. Na primjer, u američkom engleskom, 120 bi bilo "One hundred twenty", dok bi u britanskom engleskom bilo "One hundred and twenty", s upotrebom "and" nakon stotina.
✅ Neki drugi primjeri koji zahtijevaju analizu teksta uključuju "in" kao skraćenicu za inč, i "st" kao skraćenicu za svetog i ulicu. Možete li smisliti druge primjere u svom jeziku riječi koje su dvosmislene bez konteksta?
Nakon što su riječi definirane, šalju se na lingvističku analizu.
Lingvistička analiza
Lingvistička analiza razbija riječi na foneme. Fonemi se temelje ne samo na korištenim slovima, već i na drugim slovima u riječi. Na primjer, u engleskom jeziku zvuk 'a' u 'car' i 'care' je različit. Engleski jezik ima 44 različita fonema za 26 slova u abecedi, neki dijeljeni između različitih slova, poput istog fonema koji se koristi na početku 'circle' i 'serpent'.
✅ Istražite: Koji su fonemi za vaš jezik?
Nakon što su riječi pretvorene u foneme, ti fonemi trebaju dodatne podatke za podršku intonaciji, prilagođavajući ton ili trajanje ovisno o kontekstu. Jedan primjer je u engleskom jeziku gdje povećanje tona može pretvoriti rečenicu u pitanje, podižući ton za posljednju riječ implicira pitanje.
Na primjer - rečenica "You have an apple" je izjava koja kaže da imate jabuku. Ako se ton podigne na kraju, povećavajući za riječ apple, postaje pitanje "You have an apple?", pitajući imate li jabuku. Lingvistička analiza mora koristiti upitnik na kraju kako bi odlučila povećati ton.
Nakon što su fonemi generirani, mogu se poslati na generiranje valnog oblika za proizvodnju audio izlaza.
Generiranje valnog oblika
Prvi elektronički sustavi za tekst u govor koristili su pojedinačne audio snimke za svaki fonem, što je dovodilo do vrlo monotonih, robotskih glasova. Lingvistička analiza bi proizvela foneme, oni bi se učitali iz baze podataka zvukova i spojili kako bi se stvorio audio.
✅ Istražite: Pronađite neke audio snimke iz ranih sustava za sintezu govora. Usporedite ih s modernom sintezom govora, poput one koja se koristi u pametnim asistentima.
Modernije generiranje valnog oblika koristi ML modele izgrađene pomoću dubokog učenja (vrlo velike neuronske mreže koje djeluju na sličan način kao neuroni u mozgu) za proizvodnju prirodnijih glasova koji mogu biti neprepoznatljivi od ljudskih.
💁 Neki od ovih ML modela mogu se ponovno trenirati pomoću transfernog učenja kako bi zvučali poput stvarnih ljudi. To znači da korištenje glasa kao sigurnosnog sustava, što banke sve više pokušavaju, više nije dobra ideja jer svatko s nekoliko minuta snimke vašeg glasa može vas imitirati.
Ovi veliki ML modeli treniraju se kako bi kombinirali sve tri koraka u sustave za sintezu govora od kraja do kraja.
Postavljanje mjerača vremena
Za postavljanje mjerača vremena, vaš IoT uređaj treba pozvati REST endpoint koji ste kreirali pomoću serverless koda, a zatim koristiti dobiveni broj sekundi za postavljanje mjerača vremena.
Zadatak - pozovite serverless funkciju za dobivanje vremena mjerača
Slijedite relevantni vodič za pozivanje REST endpointa s vašeg IoT uređaja i postavite mjerač vremena za traženo vrijeme:
Pretvaranje teksta u govor
Ista usluga za govor koju ste koristili za pretvaranje govora u tekst može se koristiti za pretvaranje teksta natrag u govor, a to se može reproducirati putem zvučnika na vašem IoT uređaju. Tekst za pretvaranje šalje se usluzi za govor, zajedno s vrstom traženog audija (kao što je uzorak frekvencije), a binarni podaci koji sadrže audio se vraćaju.
Kada šaljete ovaj zahtjev, šaljete ga koristeći Speech Synthesis Markup Language (SSML), XML-bazirani jezik za označavanje za aplikacije sinteze govora. Ovo definira ne samo tekst koji treba pretvoriti, već i jezik teksta, glas koji treba koristiti, a može se čak koristiti za definiranje brzine, glasnoće i tona za neke ili sve riječi u tekstu.
Na primjer, ovaj SSML definira zahtjev za pretvaranje teksta "Vaš mjerač vremena od 3 minute i 5 sekundi je postavljen" u govor koristeći britanski engleski glas nazvan en-GB-MiaNeural
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 Većina sustava za tekst u govor ima više glasova za različite jezike, s relevantnim naglascima poput britanskog engleskog glasa s engleskim naglaskom i novozelandskog engleskog glasa s novozelandskim naglaskom.
Zadatak - pretvorite tekst u govor
Prođite kroz relevantni vodič za pretvaranje teksta u govor koristeći vaš IoT uređaj:
- Arduino - Wio Terminal
- Jednoplatično računalo - Raspberry Pi
- Jednoplatično računalo - Virtualni uređaj
🚀 Izazov
SSML ima načine za promjenu načina na koji se riječi izgovaraju, poput dodavanja naglaska na određene riječi, dodavanja pauza ili promjene tona. Isprobajte neke od ovih opcija, šaljući različite SSML s vašeg IoT uređaja i uspoređujući rezultate. Više o SSML-u, uključujući kako promijeniti način na koji se riječi izgovaraju, možete pročitati u Speech Synthesis Markup Language (SSML) Version 1.1 specifikaciji od World Wide Web konzorcija.
Kviz nakon predavanja
Pregled i samostalno učenje
- Pročitajte više o sintezi govora na stranici o sintezi govora na Wikipediji
- Pročitajte više o načinima na koje kriminalci koriste sintezu govora za krađu na priča o lažnim glasovima 'pomažu cyber kriminalcima ukrasti novac' na BBC vijestima
- Saznajte više o rizicima za glasovne glumce od sintetiziranih verzija njihovih glasova u ovaj TikTok tužba ističe kako AI ugrožava glasovne glumce članak na Vice
Zadatak
Odricanje od odgovornosti:
Ovaj dokument je preveden pomoću AI usluge za prevođenje Co-op Translator. Iako nastojimo osigurati točnost, imajte na umu da automatski prijevodi mogu sadržavati pogreške ili netočnosti. Izvorni dokument na izvornom jeziku treba smatrati autoritativnim izvorom. Za kritične informacije preporučuje se profesionalni prijevod od strane ljudskog prevoditelja. Ne preuzimamo odgovornost za bilo kakve nesporazume ili pogrešne interpretacije koje proizlaze iz korištenja ovog prijevoda.