|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
設定計時器並提供語音回饋
手繪筆記由 Nitya Narasimhan 提供。點擊圖片查看更大版本。
課前測驗
簡介
智慧助理並非單向的溝通設備。你對它說話,它會回應你:
「Alexa,設定一個三分鐘的計時器」
「好的,您的計時器已設定為三分鐘」
在前兩節課中,你學會了如何將語音轉換為文字,然後從文字中提取設定計時器的請求。在本課中,你將學習如何在物聯網設備上設定計時器,並以語音回應用戶確認計時器已設定,並在計時器結束時提醒他們。
本課將涵蓋以下內容:
文字轉語音
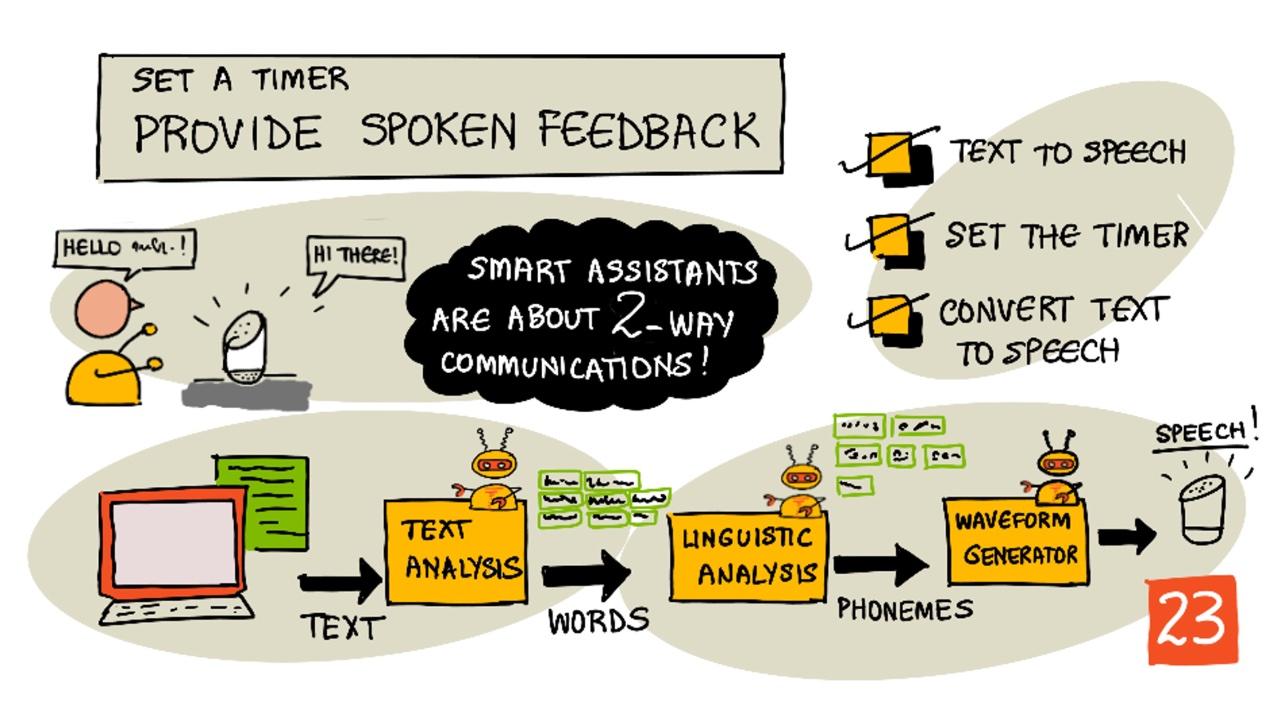
顧名思義,文字轉語音是將文字轉換為包含語音的音頻的過程。其基本原理是將文字中的單詞分解為其組成的聲音(稱為音素),然後將這些聲音的音頻拼接在一起,這些音頻可以是預錄的,也可以是由人工智慧模型生成的。

文字轉語音系統通常有三個階段:
- 文字分析
- 語言學分析
- 波形生成
文字分析
文字分析是將提供的文字轉換為可以用於生成語音的單詞。例如,如果你轉換「Hello world」,則不需要進行文字分析,這兩個單詞可以直接轉換為語音。然而,如果是「1234」,則可能需要根據上下文將其轉換為「一千二百三十四」或「一二三四」。例如,「我有1234個蘋果」應該是「一千二百三十四」,而「孩子數到1234」則應該是「一二三四」。
單詞的生成不僅取決於語言,還取決於該語言的地區。例如,在美式英語中,120是「One hundred twenty」,而在英式英語中則是「One hundred and twenty」,多了一個「and」。
✅ 其他需要文字分析的例子包括「in」作為英寸的縮寫,以及「st」作為聖人或街道的縮寫。你能想到在你的語言中有哪些單詞在沒有上下文時會產生歧義嗎?
一旦單詞被定義,它們將被送往語言學分析。
語言學分析
語言學分析將單詞分解為音素。音素不僅基於使用的字母,還基於單詞中的其他字母。例如,在英語中,「car」和「care」中的「a」發音是不同的。英語中有44個不同的音素,而字母表只有26個字母,有些音素由不同的字母共享,例如「circle」和「serpent」開頭的音素相同。
✅ 做一些研究:你的語言有哪些音素?
當單詞被轉換為音素後,這些音素需要額外的數據來支持語調,根據上下文調整音調或持續時間。例如,在英語中,音調的升高可以將一個句子轉換為疑問句,最後一個單詞的音調升高暗示這是一個問題。
例如,句子「You have an apple」是一個陳述句,表示你有一個蘋果。如果最後一個單詞「apple」的音調升高,則變成了問題「You have an apple?」,詢問你是否有一個蘋果。語言學分析需要使用句末的問號來決定是否提高音調。
一旦生成了音素,它們將被送往波形生成階段以生成音頻輸出。
波形生成
最早的電子文字轉語音系統使用每個音素的單一音頻錄音,導致聲音非常單調、機械化。語言學分析生成音素後,這些音素會從聲音數據庫中加載並拼接在一起生成音頻。
✅ 做一些研究:找一些早期語音合成系統的音頻錄音。將其與現代語音合成(如智慧助理中使用的語音)進行比較。
更現代的波形生成使用基於深度學習的機器學習模型(非常大的神經網絡,類似於大腦中的神經元)來生成更自然的聲音,這些聲音可以與人類的聲音無法區分。
💁 一些機器學習模型可以通過遷移學習重新訓練,模仿真實人物的聲音。這意味著使用聲音作為安全系統(例如銀行越來越多地嘗試的方式)已不再安全,因為任何人只需幾分鐘的聲音錄音就可以模仿你。
這些大型機器學習模型正在被訓練以將三個步驟結合為端到端的語音合成器。
設定計時器
要設定計時器,你的物聯網設備需要調用你使用無伺服器代碼創建的 REST 端點,然後使用返回的秒數來設定計時器。
任務 - 調用無伺服器函數以獲取計時器時間
按照相關指南從你的物聯網設備調用 REST 端點,並為所需的時間設定計時器:
將文字轉換為語音
你用於將語音轉換為文字的語音服務也可以用於將文字轉換回語音,並通過物聯網設備上的揚聲器播放。要轉換的文字會被發送到語音服務,並附上所需的音頻類型(例如採樣率),然後返回包含音頻的二進制數據。
當你發送此請求時,你會使用語音合成標記語言(SSML),這是一種基於 XML 的語音合成應用標記語言。它不僅定義了要轉換的文字,還定義了文字的語言、使用的語音,甚至可以用於定義某些或所有文字的速度、音量和音調。
例如,以下 SSML 定義了一個請求,將文字「Your 3 minute 5 second time has been set」轉換為語音,使用名為 en-GB-MiaNeural 的英式英語語音:
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 大多數文字轉語音系統為不同語言提供多種語音,並帶有相關的口音,例如帶有英國口音的英式英語語音和帶有紐西蘭口音的紐西蘭英語語音。
任務 - 將文字轉換為語音
按照相關指南使用你的物聯網設備將文字轉換為語音:
🚀 挑戰
SSML 提供了改變單詞發音方式的方法,例如對某些單詞加重語氣、添加停頓或改變音調。嘗試這些功能,從你的物聯網設備發送不同的 SSML 並比較輸出效果。你可以在 世界萬維網聯盟的《語音合成標記語言 (SSML) 1.1 版規範》中閱讀更多關於 SSML 的內容,包括如何改變單詞的發音方式。
課後測驗
回顧與自學
- 在 維基百科的語音合成頁面上閱讀更多關於語音合成的內容
- 在 BBC 新聞的「假聲音幫助網絡罪犯偷錢」報導中了解更多犯罪分子如何利用語音合成進行盜竊
- 在 Vice 的文章《這場 TikTok 訴訟突顯了 AI 如何損害配音演員》中了解更多語音演員因合成聲音面臨的風險
作業
免責聲明:
本文件已使用人工智能翻譯服務 Co-op Translator 進行翻譯。雖然我們致力於提供準確的翻譯,但請注意,自動翻譯可能包含錯誤或不準確之處。原始語言的文件應被視為權威來源。對於重要信息,建議使用專業人工翻譯。我們對因使用此翻譯而引起的任何誤解或錯誤解釋概不負責。