|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-text-to-speech.md | 4 weeks ago | |
| single-board-computer-set-timer.md | 4 weeks ago | |
| virtual-device-text-to-speech.md | 4 weeks ago | |
| wio-terminal-set-timer.md | 4 weeks ago | |
| wio-terminal-text-to-speech.md | 4 weeks ago | |
README.md
टाइमर सेट करें और मौखिक प्रतिक्रिया दें
स्केच नोट नित्या नरसिम्हन द्वारा। बड़ी छवि देखने के लिए क्लिक करें।
प्री-लेक्चर क्विज़
परिचय
स्मार्ट असिस्टेंट एकतरफा संचार उपकरण नहीं हैं। आप उनसे बात करते हैं, और वे जवाब देते हैं:
"एलेक्सा, 3 मिनट का टाइमर सेट करो।"
"ठीक है, आपका टाइमर 3 मिनट के लिए सेट कर दिया गया है।"
पिछले 2 पाठों में आपने सीखा कि कैसे आवाज को टेक्स्ट में बदलें और फिर उस टेक्स्ट से टाइमर सेट करने का अनुरोध निकालें। इस पाठ में आप सीखेंगे कि IoT डिवाइस पर टाइमर कैसे सेट करें, उपयोगकर्ता को उनके टाइमर की पुष्टि करते हुए मौखिक प्रतिक्रिया दें, और जब उनका टाइमर समाप्त हो जाए तो उन्हें सूचित करें।
इस पाठ में हम निम्नलिखित विषयों को कवर करेंगे:
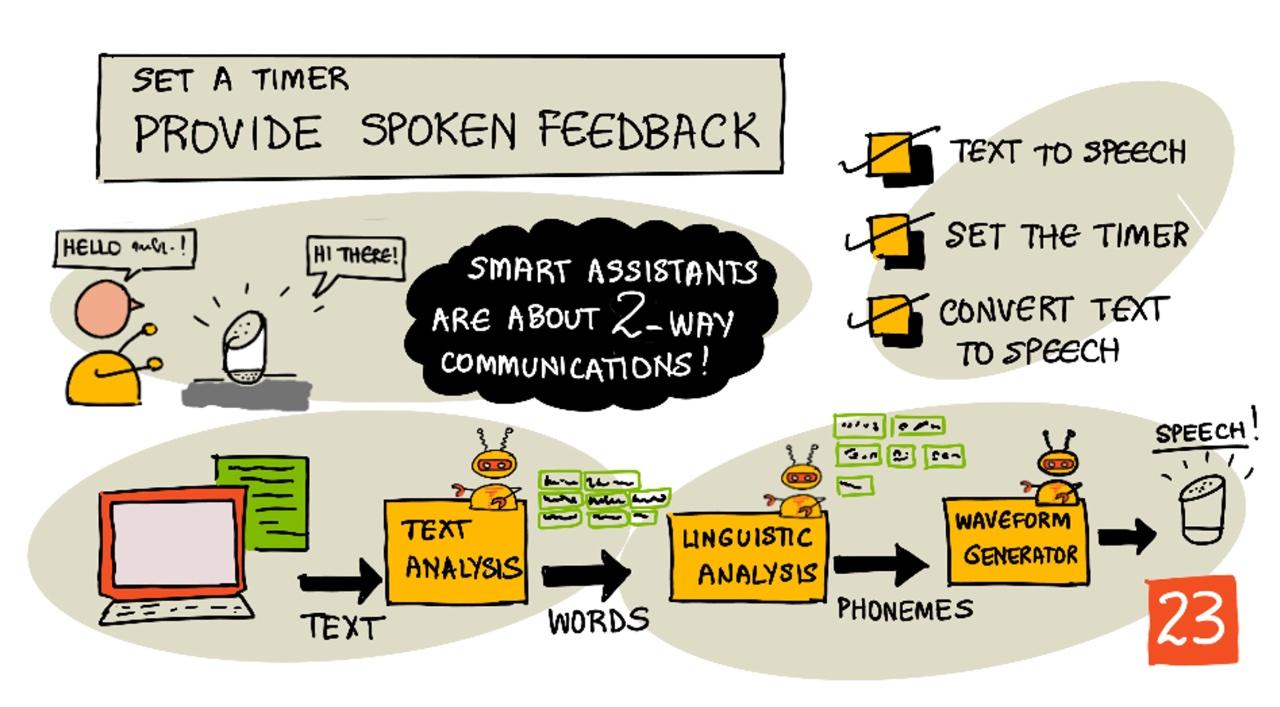
टेक्स्ट को आवाज में बदलना
टेक्स्ट को आवाज में बदलने की प्रक्रिया, जैसा कि नाम से पता चलता है, टेक्स्ट को ऑडियो में बदलने की प्रक्रिया है जिसमें टेक्स्ट को बोले गए शब्दों के रूप में प्रस्तुत किया जाता है। इसका मूल सिद्धांत टेक्स्ट में शब्दों को उनके घटक ध्वनियों (जिन्हें फोनीम्स कहा जाता है) में तोड़ना है और उन ध्वनियों के लिए ऑडियो को जोड़ना है, या तो पहले से रिकॉर्ड किए गए ऑडियो का उपयोग करके या AI मॉडल द्वारा उत्पन्न ऑडियो का उपयोग करके।

टेक्स्ट को आवाज में बदलने की प्रणाली में आमतौर पर 3 चरण होते हैं:
- टेक्स्ट विश्लेषण
- भाषाई विश्लेषण
- वेव-फॉर्म जनरेशन
टेक्स्ट विश्लेषण
टेक्स्ट विश्लेषण में दिए गए टेक्स्ट को लेना और इसे ऐसे शब्दों में बदलना शामिल है जिन्हें आवाज में बदला जा सकता है। उदाहरण के लिए, यदि आप "हैलो वर्ल्ड" को बदलते हैं, तो कोई टेक्स्ट विश्लेषण की आवश्यकता नहीं है, इन दो शब्दों को सीधे आवाज में बदला जा सकता है। लेकिन यदि आपके पास "1234" है, तो इसे संदर्भ के आधार पर "वन थाउज़ेंड, टू हंड्रेड थर्टी फोर" या "वन, टू, थ्री, फोर" में बदलने की आवश्यकता हो सकती है। उदाहरण के लिए, "मेरे पास 1234 सेब हैं" में इसे "वन थाउज़ेंड, टू हंड्रेड थर्टी फोर" में बदला जाएगा, लेकिन "बच्चे ने 1234 गिने" में इसे "वन, टू, थ्री, फोर" में बदला जाएगा।
शब्द न केवल भाषा के लिए बल्कि उस भाषा के स्थानीय संदर्भ के लिए भी भिन्न होते हैं। उदाहरण के लिए, अमेरिकी अंग्रेजी में 120 को "वन हंड्रेड ट्वेंटी" कहा जाएगा, जबकि ब्रिटिश अंग्रेजी में इसे "वन हंड्रेड एंड ट्वेंटी" कहा जाएगा, जिसमें "एंड" का उपयोग किया जाता है।
✅ कुछ अन्य उदाहरण जो टेक्स्ट विश्लेषण की आवश्यकता रखते हैं, उनमें "in" को इंच के संक्षिप्त रूप के रूप में और "st" को संत या सड़क के संक्षिप्त रूप के रूप में शामिल किया जा सकता है। क्या आप अपनी भाषा में ऐसे अन्य उदाहरण सोच सकते हैं जिनमें संदर्भ के बिना शब्द अस्पष्ट हो सकते हैं?
एक बार जब शब्द परिभाषित हो जाते हैं, तो उन्हें भाषाई विश्लेषण के लिए भेजा जाता है।
भाषाई विश्लेषण
भाषाई विश्लेषण शब्दों को फोनीम्स में तोड़ता है। फोनीम्स केवल अक्षरों पर आधारित नहीं होते, बल्कि शब्द में अन्य अक्षरों पर भी निर्भर करते हैं। उदाहरण के लिए, अंग्रेजी में 'a' की ध्वनि 'car' और 'care' में अलग होती है। अंग्रेजी भाषा में 26 अक्षरों के लिए 44 अलग-अलग फोनीम्स होते हैं, जिनमें से कुछ अलग-अलग अक्षरों द्वारा साझा किए जाते हैं, जैसे 'circle' और 'serpent' के शुरू में उपयोग किए गए समान फोनीम।
✅ शोध करें: आपकी भाषा के लिए फोनीम्स क्या हैं?
एक बार जब शब्दों को फोनीम्स में बदल दिया जाता है, तो इन फोनीम्स को अतिरिक्त डेटा की आवश्यकता होती है ताकि स्वर, टोन, या अवधि को संदर्भ के अनुसार समायोजित किया जा सके। उदाहरण के लिए, अंग्रेजी में पिच बढ़ाने का उपयोग एक वाक्य को प्रश्न में बदलने के लिए किया जा सकता है, जहां अंतिम शब्द के लिए बढ़ी हुई पिच प्रश्न का संकेत देती है।
उदाहरण के लिए - वाक्य "आपके पास एक सेब है" एक कथन है जो कहता है कि आपके पास एक सेब है। यदि पिच अंत में बढ़ जाती है, विशेष रूप से "सेब" शब्द के लिए, तो यह प्रश्न बन जाता है "आपके पास एक सेब है?", यह पूछते हुए कि क्या आपके पास एक सेब है। भाषाई विश्लेषण को प्रश्न चिह्न का उपयोग करके पिच बढ़ाने का निर्णय लेना होता है।
एक बार जब फोनीम्स उत्पन्न हो जाते हैं, तो उन्हें ऑडियो आउटपुट उत्पन्न करने के लिए वेव-फॉर्म जनरेशन के लिए भेजा जाता है।
वेव-फॉर्म जनरेशन
पहले इलेक्ट्रॉनिक टेक्स्ट-टू-स्पीच सिस्टम प्रत्येक फोनीम के लिए एकल ऑडियो रिकॉर्डिंग का उपयोग करते थे, जिससे बहुत ही नीरस, रोबोटिक आवाजें उत्पन्न होती थीं। भाषाई विश्लेषण फोनीम्स उत्पन्न करता था, जिन्हें ध्वनियों के डेटाबेस से लोड किया जाता था और ऑडियो बनाने के लिए जोड़ा जाता था।
✅ शोध करें: शुरुआती स्पीच सिंथेसिस सिस्टम से कुछ ऑडियो रिकॉर्डिंग खोजें। इसे आधुनिक स्पीच सिंथेसिस, जैसे स्मार्ट असिस्टेंट में उपयोग किए जाने वाले सिस्टम से तुलना करें।
अधिक आधुनिक वेव-फॉर्म जनरेशन डीप लर्निंग (बहुत बड़े न्यूरल नेटवर्क जो मस्तिष्क में न्यूरॉन्स के समान तरीके से काम करते हैं) का उपयोग करके बनाए गए ML मॉडल का उपयोग करता है ताकि अधिक प्राकृतिक आवाजें उत्पन्न की जा सकें जो मनुष्यों से अलग नहीं लगतीं।
💁 इनमें से कुछ ML मॉडल को ट्रांसफर लर्निंग का उपयोग करके वास्तविक लोगों की तरह आवाज देने के लिए पुनः प्रशिक्षित किया जा सकता है। इसका मतलब है कि आवाज को सुरक्षा प्रणाली के रूप में उपयोग करना, जिसे बैंक तेजी से अपनाने की कोशिश कर रहे हैं, अब एक अच्छा विचार नहीं है क्योंकि कोई भी आपकी आवाज की कुछ मिनटों की रिकॉर्डिंग के साथ आपकी नकल कर सकता है।
ये बड़े ML मॉडल सभी तीन चरणों को एकीकृत करने के लिए प्रशिक्षित किए जा रहे हैं ताकि एंड-टू-एंड स्पीच सिंथेसाइज़र बनाए जा सकें।
टाइमर सेट करना
टाइमर सेट करने के लिए, आपके IoT डिवाइस को सर्वरलेस कोड का उपयोग करके बनाए गए REST एंडपॉइंट को कॉल करना होगा, और फिर प्राप्त सेकंड की संख्या का उपयोग करके टाइमर सेट करना होगा।
कार्य - सर्वरलेस फ़ंक्शन को कॉल करके टाइमर का समय प्राप्त करें
अपने IoT डिवाइस से REST एंडपॉइंट को कॉल करने और आवश्यक समय के लिए टाइमर सेट करने के लिए संबंधित गाइड का पालन करें:
टेक्स्ट को आवाज में बदलने की प्रक्रिया
वही स्पीच सर्विस जिसका उपयोग आपने आवाज को टेक्स्ट में बदलने के लिए किया था, टेक्स्ट को वापस आवाज में बदलने के लिए भी उपयोग की जा सकती है, और इसे आपके IoT डिवाइस के स्पीकर के माध्यम से चलाया जा सकता है। बदलने के लिए टेक्स्ट को स्पीच सर्विस को भेजा जाता है, साथ ही आवश्यक ऑडियो प्रकार (जैसे सैंपल रेट), और बाइनरी डेटा जिसमें ऑडियो होता है, वापस किया जाता है।
जब आप यह अनुरोध भेजते हैं, तो आप इसे स्पीच सिंथेसिस मार्कअप लैंग्वेज (SSML) का उपयोग करके भेजते हैं, जो स्पीच सिंथेसिस एप्लिकेशन के लिए XML-आधारित मार्कअप लैंग्वेज है। यह न केवल बदलने के लिए टेक्स्ट को परिभाषित करता है, बल्कि टेक्स्ट की भाषा, उपयोग करने वाली आवाज, और यहां तक कि कुछ या सभी शब्दों के लिए गति, वॉल्यूम, और पिच को भी परिभाषित कर सकता है।
उदाहरण के लिए, यह SSML ब्रिटिश अंग्रेजी आवाज en-GB-MiaNeural का उपयोग करके "आपका 3 मिनट 5 सेकंड का टाइमर सेट कर दिया गया है" टेक्स्ट को आवाज में बदलने का अनुरोध परिभाषित करता है:
<speak version='1.0' xml:lang='en-GB'>
<voice xml:lang='en-GB' name='en-GB-MiaNeural'>
Your 3 minute 5 second time has been set
</voice>
</speak>
💁 अधिकांश टेक्स्ट-टू-स्पीच सिस्टम में विभिन्न भाषाओं के लिए कई आवाजें होती हैं, जैसे ब्रिटिश अंग्रेजी आवाज अंग्रेजी उच्चारण के साथ और न्यूज़ीलैंड अंग्रेजी आवाज न्यूज़ीलैंड उच्चारण के साथ।
कार्य - टेक्स्ट को आवाज में बदलें
अपने IoT डिवाइस का उपयोग करके टेक्स्ट को आवाज में बदलने के लिए संबंधित गाइड का पालन करें:
🚀 चुनौती
SSML में शब्दों को बोलने के तरीके को बदलने के तरीके हैं, जैसे कुछ शब्दों पर जोर देना, विराम जोड़ना, या पिच बदलना। इन्हें आज़माएं, अपने IoT डिवाइस से अलग-अलग SSML भेजें और आउटपुट की तुलना करें। आप SSML के बारे में अधिक पढ़ सकते हैं, जिसमें शब्दों को बोलने के तरीके को बदलने के तरीके शामिल हैं, वर्ल्ड वाइड वेब कंसोर्टियम के स्पीच सिंथेसिस मार्कअप लैंग्वेज (SSML) संस्करण 1.1 विनिर्देश में।
पोस्ट-लेक्चर क्विज़
समीक्षा और स्व-अध्ययन
- स्पीच सिंथेसिस के बारे में अधिक पढ़ें विकिपीडिया पर स्पीच सिंथेसिस पेज पर।
- अपराधियों द्वारा नकली आवाज़ों का उपयोग करके पैसे चुराने के तरीकों के बारे में अधिक पढ़ें बीबीसी न्यूज़ पर 'नकली आवाज़ें साइबर अपराधियों को नकदी चुराने में मदद करती हैं' कहानी पर।
- आवाज अभिनेताओं के लिए उनके आवाज़ों के सिंथेसाइज़ किए गए संस्करणों से उत्पन्न जोखिमों के बारे में अधिक जानें वाइस पर 'यह टिकटॉक मुकदमा दिखा रहा है कि कैसे AI आवाज अभिनेताओं को नुकसान पहुंचा रहा है' लेख में।
असाइनमेंट
अस्वीकरण:
यह दस्तावेज़ AI अनुवाद सेवा Co-op Translator का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता सुनिश्चित करने का प्रयास करते हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम जिम्मेदार नहीं हैं।