|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Speichere Standortdaten
Sketchnote von Nitya Narasimhan. Klicken Sie auf das Bild für eine größere Version.
Quiz vor der Vorlesung
Einführung
In der letzten Lektion haben Sie gelernt, wie Sie mit einem GPS-Sensor Standortdaten erfassen können. Um diese Daten zu nutzen, um den Standort eines mit Lebensmitteln beladenen Lastwagens und seine Reise zu visualisieren, müssen sie an einen IoT-Dienst in der Cloud gesendet und dort gespeichert werden.
In dieser Lektion lernen Sie die verschiedenen Möglichkeiten kennen, IoT-Daten zu speichern, und erfahren, wie Sie Daten aus Ihrem IoT-Dienst mit serverlosem Code speichern können.
In dieser Lektion behandeln wir:
- Strukturierte und unstrukturierte Daten
- GPS-Daten an einen IoT-Hub senden
- Heiße, warme und kalte Pfade
- GPS-Ereignisse mit serverlosem Code verarbeiten
- Azure Storage Accounts
- Serverlosen Code mit Speicher verbinden
Strukturierte und unstrukturierte Daten
Computersysteme arbeiten mit Daten, die in unterschiedlichsten Formen und Größen vorliegen können. Sie können von einzelnen Zahlen über große Textmengen bis hin zu Videos und Bildern reichen, ebenso wie IoT-Daten. Daten lassen sich in der Regel in zwei Kategorien einteilen: strukturierte Daten und unstrukturierte Daten.
-
Strukturierte Daten sind Daten mit einer klar definierten, starren Struktur, die sich nicht ändert und normalerweise Tabellen mit Beziehungen abbildet. Ein Beispiel sind die persönlichen Daten einer Person, einschließlich ihres Namens, Geburtsdatums und ihrer Adresse.
-
Unstrukturierte Daten sind Daten ohne eine klar definierte, starre Struktur, einschließlich Daten, die ihre Struktur häufig ändern können. Ein Beispiel sind Dokumente wie schriftliche Texte oder Tabellenkalkulationen.
✅ Machen Sie eine kleine Recherche: Können Sie weitere Beispiele für strukturierte und unstrukturierte Daten nennen?
💁 Es gibt auch halbstrukturierte Daten, die zwar strukturiert sind, aber nicht in feste Datentabellen passen.
IoT-Daten werden normalerweise als unstrukturierte Daten betrachtet.
Stellen Sie sich vor, Sie würden IoT-Geräte in eine Fahrzeugflotte für eine große kommerzielle Farm integrieren. Sie könnten unterschiedliche Geräte für verschiedene Fahrzeugtypen verwenden. Zum Beispiel:
- Für landwirtschaftliche Fahrzeuge wie Traktoren möchten Sie GPS-Daten, um sicherzustellen, dass sie auf den richtigen Feldern arbeiten.
- Für Lieferwagen, die Lebensmittel zu Lagerhäusern transportieren, möchten Sie GPS-Daten sowie Geschwindigkeits- und Beschleunigungsdaten, um sicherzustellen, dass der Fahrer sicher fährt, sowie Fahreridentität und Start-/Stopp-Daten, um die Einhaltung der lokalen Arbeitszeitgesetze zu gewährleisten.
- Für Kühlwagen möchten Sie auch Temperaturdaten, um sicherzustellen, dass die Lebensmittel während des Transports nicht zu heiß oder kalt werden und verderben.
Diese Daten können sich ständig ändern. Wenn sich beispielsweise das Anhänger eines Lastwagens ändert, sendet das IoT-Gerät möglicherweise nur Temperaturdaten, wenn ein Kühlanhänger verwendet wird.
✅ Welche anderen IoT-Daten könnten erfasst werden? Denken Sie an die Arten von Ladungen, die Lastwagen transportieren können, sowie an Wartungsdaten.
Diese Daten variieren von Fahrzeug zu Fahrzeug, werden jedoch alle an denselben IoT-Dienst zur Verarbeitung gesendet. Der IoT-Dienst muss in der Lage sein, diese unstrukturierten Daten zu verarbeiten, sie so zu speichern, dass sie durchsucht oder analysiert werden können, und gleichzeitig mit unterschiedlichen Strukturen dieser Daten arbeiten.
SQL- vs. NoSQL-Speicher
Datenbanken sind Dienste, die es ermöglichen, Daten zu speichern und abzufragen. Datenbanken gibt es in zwei Typen: SQL und NoSQL.
SQL-Datenbanken
Die ersten Datenbanken waren relationale Datenbankmanagementsysteme (RDBMS) oder relationale Datenbanken. Diese werden auch als SQL-Datenbanken bezeichnet, da sie die Structured Query Language (SQL) verwenden, um Daten hinzuzufügen, zu entfernen, zu aktualisieren oder abzufragen. Diese Datenbanken bestehen aus einem Schema – einer klar definierten Menge von Datentabellen, ähnlich einer Tabellenkalkulation. Jede Tabelle hat mehrere benannte Spalten. Wenn Sie Daten einfügen, fügen Sie der Tabelle eine Zeile hinzu und geben Werte in jede der Spalten ein. Dies hält die Daten in einer sehr starren Struktur – obwohl Sie Spalten leer lassen können, müssen Sie, wenn Sie eine neue Spalte hinzufügen möchten, dies in der Datenbank tun und Werte für die vorhandenen Zeilen einfügen. Diese Datenbanken sind relational – eine Tabelle kann eine Beziehung zu einer anderen haben.
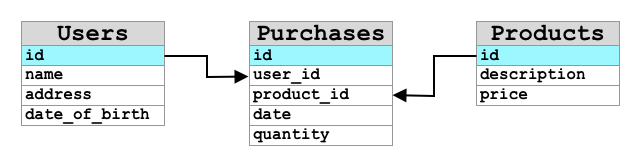
Wenn Sie beispielsweise die persönlichen Daten eines Benutzers in einer Tabelle speichern, hätten Sie eine Art interne eindeutige ID pro Benutzer, die in einer Zeile einer Tabelle verwendet wird, die den Namen und die Adresse des Benutzers enthält. Wenn Sie dann andere Details zu diesem Benutzer speichern möchten, wie z. B. seine Einkäufe, in einer anderen Tabelle, hätten Sie eine Spalte in der neuen Tabelle für die Benutzer-ID. Wenn Sie einen Benutzer suchen, können Sie seine ID verwenden, um seine persönlichen Daten aus einer Tabelle und seine Einkäufe aus einer anderen zu erhalten.
SQL-Datenbanken eignen sich ideal zum Speichern strukturierter Daten und wenn Sie sicherstellen möchten, dass die Daten Ihrem Schema entsprechen.
✅ Wenn Sie SQL noch nicht verwendet haben, nehmen Sie sich einen Moment Zeit, um auf der SQL-Seite auf Wikipedia darüber zu lesen.
Einige bekannte SQL-Datenbanken sind Microsoft SQL Server, MySQL und PostgreSQL.
✅ Machen Sie eine kleine Recherche: Lesen Sie über einige dieser SQL-Datenbanken und ihre Funktionen.
NoSQL-Datenbanken
NoSQL-Datenbanken werden als NoSQL bezeichnet, da sie nicht die gleiche starre Struktur wie SQL-Datenbanken haben. Sie werden auch als Dokumentendatenbanken bezeichnet, da sie unstrukturierte Daten wie Dokumente speichern können.
💁 Trotz ihres Namens erlauben einige NoSQL-Datenbanken die Verwendung von SQL, um die Daten abzufragen.
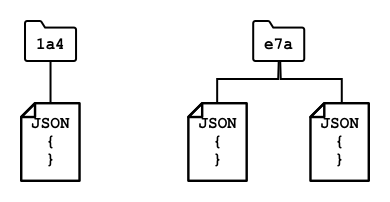
NoSQL-Datenbanken haben kein vordefiniertes Schema, das einschränkt, wie Daten gespeichert werden. Stattdessen können Sie beliebige unstrukturierte Daten einfügen, normalerweise in Form von JSON-Dokumenten. Diese Dokumente können in Ordnern organisiert werden, ähnlich wie Dateien auf Ihrem Computer. Jedes Dokument kann unterschiedliche Felder im Vergleich zu anderen Dokumenten haben – wenn Sie beispielsweise IoT-Daten von Ihren landwirtschaftlichen Fahrzeugen speichern, könnten einige Felder für Beschleunigungs- und Geschwindigkeitsdaten haben, andere Felder für die Temperatur im Anhänger. Wenn Sie einen neuen Lastwagentyp hinzufügen, z. B. einen mit eingebauten Waagen zur Verfolgung des Gewichts der transportierten Produkte, könnte Ihr IoT-Gerät dieses neue Feld hinzufügen, und es könnte gespeichert werden, ohne dass Änderungen an der Datenbank erforderlich sind.
Einige bekannte NoSQL-Datenbanken sind Azure CosmosDB, MongoDB und CouchDB.
✅ Machen Sie eine kleine Recherche: Lesen Sie über einige dieser NoSQL-Datenbanken und ihre Funktionen.
In dieser Lektion werden Sie NoSQL-Speicher verwenden, um IoT-Daten zu speichern.
GPS-Daten an einen IoT-Hub senden
In der letzten Lektion haben Sie GPS-Daten von einem GPS-Sensor erfasst, der mit Ihrem IoT-Gerät verbunden ist. Um diese IoT-Daten in der Cloud zu speichern, müssen Sie sie an einen IoT-Dienst senden. Sie werden erneut Azure IoT Hub verwenden, denselben IoT-Cloud-Dienst, den Sie im vorherigen Projekt verwendet haben.
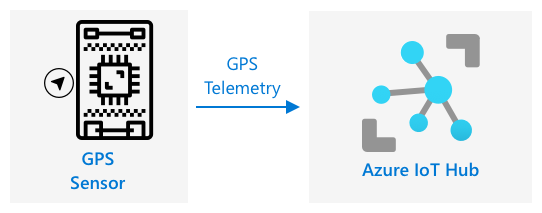
Aufgabe – GPS-Daten an einen IoT-Hub senden
-
Erstellen Sie einen neuen IoT-Hub mit der kostenlosen Stufe.
⚠️ Sie können die Anweisungen zum Erstellen eines IoT-Hubs aus Projekt 2, Lektion 4 bei Bedarf verwenden.
Denken Sie daran, eine neue Ressourcengruppe zu erstellen. Benennen Sie die neue Ressourcengruppe
gps-sensorund den neuen IoT-Hub mit einem eindeutigen Namen basierend aufgps-sensor, z. B.gps-sensor-<Ihr Name>.💁 Wenn Sie Ihren IoT-Hub aus dem vorherigen Projekt noch haben, können Sie ihn erneut verwenden. Denken Sie daran, den Namen dieses IoT-Hubs und die Ressourcengruppe, in der er sich befindet, zu verwenden, wenn Sie andere Dienste erstellen.
-
Fügen Sie dem IoT-Hub ein neues Gerät hinzu. Nennen Sie dieses Gerät
gps-sensor. Holen Sie sich die Verbindungszeichenfolge für das Gerät. -
Aktualisieren Sie Ihren Gerätekode, um die GPS-Daten an den neuen IoT-Hub zu senden, indem Sie die Verbindungszeichenfolge des Geräts aus dem vorherigen Schritt verwenden.
⚠️ Sie können die Anweisungen zum Verbinden Ihres Geräts mit einem IoT-Dienst aus Projekt 2, Lektion 4 bei Bedarf verwenden.
-
Senden Sie die GPS-Daten im JSON-Format wie folgt:
{ "gps" : { "lat" : <latitude>, "lon" : <longitude> } } -
Senden Sie GPS-Daten jede Minute, um Ihr tägliches Nachrichtenkontingent nicht zu überschreiten.
Wenn Sie das Wio Terminal verwenden, denken Sie daran, alle notwendigen Bibliotheken hinzuzufügen und die Zeit mit einem NTP-Server einzustellen. Ihr Code muss auch sicherstellen, dass alle Daten vom seriellen Port gelesen wurden, bevor die GPS-Position gesendet wird, und dabei den vorhandenen Code aus der letzten Lektion verwenden. Verwenden Sie den folgenden Code, um das JSON-Dokument zu erstellen:
DynamicJsonDocument doc(1024);
doc["gps"]["lat"] = gps.location.lat();
doc["gps"]["lon"] = gps.location.lng();
Wenn Sie ein virtuelles IoT-Gerät verwenden, denken Sie daran, alle benötigten Bibliotheken mit einer virtuellen Umgebung zu installieren.
Für sowohl den Raspberry Pi als auch das virtuelle IoT-Gerät verwenden Sie den vorhandenen Code aus der letzten Lektion, um die Breitengrad- und Längengradwerte zu erhalten, und senden Sie sie dann im richtigen JSON-Format mit dem folgenden Code:
message_json = { "gps" : { "lat":lat, "lon":lon } }
print("Sending telemetry", message_json)
message = Message(json.dumps(message_json))
💁 Sie finden diesen Code im Ordner code/wio-terminal, code/pi oder code/virtual-device.
Führen Sie Ihren Gerätekode aus und stellen Sie sicher, dass Nachrichten mit dem CLI-Befehl az iot hub monitor-events in den IoT-Hub fließen.
Heiße, warme und kalte Pfade
Daten, die von einem IoT-Gerät in die Cloud fließen, werden nicht immer in Echtzeit verarbeitet. Einige Daten müssen in Echtzeit verarbeitet werden, andere können kurz nach dem Empfang verarbeitet werden, und andere können viel später verarbeitet werden. Der Datenfluss zu verschiedenen Diensten, die die Daten zu unterschiedlichen Zeiten verarbeiten, wird als heiße, warme und kalte Pfade bezeichnet.
Heißer Pfad
Der heiße Pfad bezieht sich auf Daten, die in Echtzeit oder nahezu in Echtzeit verarbeitet werden müssen. Sie würden heiße Pfaddaten für Warnungen verwenden, z. B. wenn ein Fahrzeug sich einem Depot nähert oder die Temperatur in einem Kühlwagen zu hoch ist.
Um heiße Pfaddaten zu verwenden, würde Ihr Code auf Ereignisse reagieren, sobald sie von Ihren Cloud-Diensten empfangen werden.
Warmer Pfad
Der warme Pfad bezieht sich auf Daten, die kurz nach dem Empfang verarbeitet werden können, beispielsweise für Berichte oder kurzfristige Analysen. Sie würden warme Pfaddaten für tägliche Berichte über Fahrzeugkilometer verwenden, basierend auf Daten, die am Vortag gesammelt wurden.
Warme Pfaddaten werden gespeichert, sobald sie von dem Cloud-Dienst empfangen werden, in einer Art Speicher, der schnell zugänglich ist.
Kalter Pfad
Der kalte Pfad bezieht sich auf historische Daten, die langfristig gespeichert werden, um bei Bedarf verarbeitet zu werden. Beispielsweise könnten Sie den kalten Pfad verwenden, um jährliche Kilometerberichte für Fahrzeuge zu erhalten oder Analysen zu Routen durchzuführen, um die optimalste Route zur Reduzierung der Kraftstoffkosten zu finden.
Kalte Pfaddaten werden in Data Warehouses gespeichert – Datenbanken, die für die Speicherung großer Datenmengen ausgelegt sind, die sich nie ändern und schnell und einfach abgefragt werden können. Normalerweise hätten Sie in Ihrer Cloud-Anwendung einen regelmäßigen Job, der zu einer bestimmten Zeit täglich, wöchentlich oder monatlich ausgeführt wird, um Daten aus dem warmen Pfadspeicher in das Data Warehouse zu verschieben.
✅ Denken Sie über die Daten nach, die Sie bisher in diesen Lektionen erfasst haben. Sind es heiße, warme oder kalte Pfaddaten?
GPS-Ereignisse mit serverlosem Code verarbeiten
Sobald Daten in Ihren IoT-Hub fließen, können Sie serverlosen Code schreiben, um auf Ereignisse zu hören, die an den Event-Hub-kompatiblen Endpunkt veröffentlicht werden. Dies ist der warme Pfad – diese Daten werden gespeichert und in der nächsten Lektion für Berichte über die Reise verwendet.
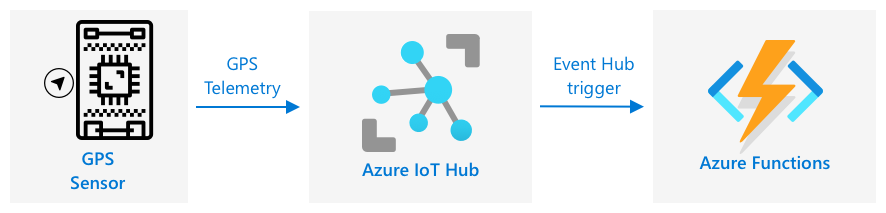
Aufgabe – GPS-Ereignisse mit serverlosem Code verarbeiten
- Erstellen Sie eine Azure Functions-App mit der Azure Functions CLI. Verwenden Sie die Python-Laufzeit und erstellen Sie sie in einem Ordner namens
gps-trigger, und verwenden Sie denselben Namen für den Functions-App-Projektnamen. Stellen Sie sicher, dass Sie eine virtuelle Umgebung dafür erstellen.
⚠️ Sie können die Anweisungen zum Erstellen eines Azure Functions-Projekts aus Projekt 2, Lektion 5 bei Bedarf einsehen.
-
Fügen Sie einen IoT-Hub-Ereignisauslöser hinzu, der den mit dem Event Hub kompatiblen Endpunkt des IoT-Hubs verwendet.
⚠️ Sie können bei Bedarf die Anleitung zum Erstellen eines IoT-Hub-Ereignisauslösers aus Projekt 2, Lektion 5 konsultieren.
-
Legen Sie die Verbindungszeichenfolge des mit dem Event Hub kompatiblen Endpunkts in der Datei
local.settings.jsonfest und verwenden Sie den Schlüssel für diesen Eintrag in der Dateifunction.json. -
Verwenden Sie die Azurite-App als lokalen Speicheremulator.
-
Führen Sie Ihre Functions-App aus, um sicherzustellen, dass sie Ereignisse von Ihrem GPS-Gerät empfängt. Stellen Sie sicher, dass Ihr IoT-Gerät ebenfalls läuft und GPS-Daten sendet.
Python EventHub trigger processed an event: {"gps": {"lat": 47.73481, "lon": -122.25701}}
Azure Storage Accounts
![]()
Azure Storage Accounts ist ein universeller Speicherdienst, der Daten auf verschiedene Arten speichern kann. Sie können Daten als Blobs, in Warteschlangen, in Tabellen oder als Dateien speichern – und das alles gleichzeitig.
Blob-Speicher
Das Wort Blob steht für "Binary Large Objects", hat sich jedoch als Begriff für unstrukturierte Daten etabliert. Sie können beliebige Daten im Blob-Speicher speichern, von JSON-Dokumenten mit IoT-Daten bis hin zu Bild- und Videodateien. Blob-Speicher verwendet das Konzept von Containern, benannten Buckets, in denen Daten gespeichert werden können, ähnlich wie Tabellen in einer relationalen Datenbank. Diese Container können einen oder mehrere Ordner enthalten, in denen Blobs gespeichert werden, und jeder Ordner kann weitere Ordner enthalten, ähnlich wie Dateien auf der Festplatte Ihres Computers gespeichert werden.
In dieser Lektion verwenden Sie Blob-Speicher, um IoT-Daten zu speichern.
✅ Machen Sie sich schlau: Lesen Sie mehr über Azure Blob Storage
Tabellen-Speicher
Tabellen-Speicher ermöglicht es Ihnen, semi-strukturierte Daten zu speichern. Tabellen-Speicher ist eigentlich eine NoSQL-Datenbank, die keine vorherige Definition von Tabellen erfordert, aber darauf ausgelegt ist, Daten in einer oder mehreren Tabellen zu speichern, wobei eindeutige Schlüssel jede Zeile definieren.
✅ Machen Sie sich schlau: Lesen Sie mehr über Azure Table Storage
Warteschlangen-Speicher
Warteschlangen-Speicher ermöglicht es Ihnen, Nachrichten mit einer Größe von bis zu 64 KB in einer Warteschlange zu speichern. Sie können Nachrichten am Ende der Warteschlange hinzufügen und sie am Anfang lesen. Warteschlangen speichern Nachrichten unbegrenzt, solange Speicherplatz verfügbar ist, sodass Nachrichten langfristig gespeichert und bei Bedarf abgerufen werden können. Beispielsweise könnten Sie GPS-Daten täglich für einen Monat in eine Warteschlange einfügen und am Ende des Monats alle Nachrichten aus der Warteschlange verarbeiten.
✅ Machen Sie sich schlau: Lesen Sie mehr über Azure Queue Storage
Datei-Speicher
Datei-Speicher ist die Speicherung von Dateien in der Cloud, und Apps oder Geräte können über standardisierte Protokolle darauf zugreifen. Sie können Dateien in den Datei-Speicher schreiben und ihn dann als Laufwerk auf Ihrem PC oder Mac einbinden.
✅ Machen Sie sich schlau: Lesen Sie mehr über Azure File Storage
Verbinden Sie Ihren serverlosen Code mit dem Speicher
Ihre Functions-App muss nun eine Verbindung zum Blob-Speicher herstellen, um die Nachrichten vom IoT-Hub zu speichern. Es gibt zwei Möglichkeiten, dies zu tun:
- Innerhalb des Funktionscodes eine Verbindung zum Blob-Speicher herstellen, indem Sie das Blob-Speicher-Python-SDK verwenden und die Daten als Blobs speichern.
- Eine Output-Funktionsbindung verwenden, um den Rückgabewert der Funktion an den Blob-Speicher zu binden und das Blob automatisch speichern zu lassen.
In dieser Lektion verwenden Sie das Python-SDK, um zu sehen, wie Sie mit dem Blob-Speicher interagieren können.

Die Daten werden als JSON-Blob im folgenden Format gespeichert:
{
"device_id": <device_id>,
"timestamp" : <time>,
"gps" :
{
"lat" : <latitude>,
"lon" : <longitude>
}
}
Aufgabe - Verbinden Sie Ihren serverlosen Code mit dem Speicher
-
Erstellen Sie ein Azure Storage-Konto. Nennen Sie es beispielsweise
gps<Ihr Name>.⚠️ Sie können bei Bedarf die Anleitung zum Erstellen eines Storage-Kontos aus Projekt 2, Lektion 5 konsultieren.
Wenn Sie noch ein Storage-Konto aus dem vorherigen Projekt haben, können Sie dieses wiederverwenden.
💁 Sie können dasselbe Storage-Konto verwenden, um Ihre Azure Functions-App später in dieser Lektion bereitzustellen.
-
Führen Sie den folgenden Befehl aus, um die Verbindungszeichenfolge für das Storage-Konto zu erhalten:
az storage account show-connection-string --output table \ --name <storage_name>Ersetzen Sie
<storage_name>durch den Namen des Storage-Kontos, das Sie im vorherigen Schritt erstellt haben. -
Fügen Sie der Datei
local.settings.jsoneinen neuen Eintrag für die Verbindungszeichenfolge Ihres Storage-Kontos hinzu, und verwenden Sie den Wert aus dem vorherigen Schritt. Nennen Sie ihnSTORAGE_CONNECTION_STRING. -
Fügen Sie der Datei
requirements.txtFolgendes hinzu, um die Azure Storage Pip-Pakete zu installieren:azure-storage-blobInstallieren Sie die Pakete aus dieser Datei in Ihrer virtuellen Umgebung.
Wenn Sie einen Fehler erhalten, aktualisieren Sie Ihre Pip-Version in Ihrer virtuellen Umgebung auf die neueste Version mit folgendem Befehl und versuchen Sie es erneut:
pip install --upgrade pip -
Fügen Sie der Datei
__init__.pyfür deniot-hub-triggerdie folgenden Import-Anweisungen hinzu:import json import os import uuid from azure.storage.blob import BlobServiceClient, PublicAccessDas Systemmodul
jsonwird verwendet, um JSON zu lesen und zu schreiben, das Systemmoduloswird verwendet, um die Verbindungszeichenfolge zu lesen, und das Systemmoduluuidwird verwendet, um eine eindeutige ID für die GPS-Messung zu generieren.Das Paket
azure.storage.blobenthält das Python-SDK, um mit dem Blob-Speicher zu arbeiten. -
Fügen Sie vor der Methode
maindie folgende Hilfsfunktion hinzu:def get_or_create_container(name): connection_str = os.environ['STORAGE_CONNECTION_STRING'] blob_service_client = BlobServiceClient.from_connection_string(connection_str) for container in blob_service_client.list_containers(): if container.name == name: return blob_service_client.get_container_client(container.name) return blob_service_client.create_container(name, public_access=PublicAccess.Container)Das Python Blob-SDK hat keine Hilfsmethode, um einen Container zu erstellen, falls dieser nicht existiert. Dieser Code lädt die Verbindungszeichenfolge aus der Datei
local.settings.json(oder den Anwendungs-Einstellungen, sobald sie in der Cloud bereitgestellt sind), erstellt dann eineBlobServiceClient-Klasse, um mit dem Blob-Speicher-Konto zu interagieren. Anschließend wird durch alle Container des Blob-Speicher-Kontos geschleift, um nach einem mit dem angegebenen Namen zu suchen – falls einer gefunden wird, wird eineContainerClient-Klasse zurückgegeben, die mit dem Container interagieren kann, um Blobs zu erstellen. Falls keiner gefunden wird, wird der Container erstellt und der Client für den neuen Container zurückgegeben.Wenn der neue Container erstellt wird, wird öffentlicher Zugriff gewährt, um die Blobs im Container abzufragen. Dies wird in der nächsten Lektion verwendet, um die GPS-Daten auf einer Karte zu visualisieren.
-
Anders als bei der Bodenfeuchtigkeit möchten wir mit diesem Code jedes Ereignis speichern. Fügen Sie daher den folgenden Code innerhalb der Schleife
for event in events:in der Funktionmainunterhalb derlogging-Anweisung hinzu:device_id = event.iothub_metadata['connection-device-id'] blob_name = f'{device_id}/{str(uuid.uuid1())}.json'Dieser Code ruft die Geräte-ID aus den Ereignis-Metadaten ab und verwendet sie, um einen Blob-Namen zu erstellen. Blobs können in Ordnern gespeichert werden, und die Geräte-ID wird für den Ordnernamen verwendet, sodass jedes Gerät alle seine GPS-Ereignisse in einem Ordner hat. Der Blob-Name ist dieser Ordner, gefolgt von einem Dokumentnamen, getrennt durch Schrägstriche, ähnlich wie Linux- und macOS-Pfade (ähnlich wie bei Windows, aber Windows verwendet Rückwärtsschrägstriche). Der Dokumentname ist eine eindeutige ID, die mit dem Python-Modul
uuidgeneriert wird, mit der Dateiendungjson.Zum Beispiel könnte der Blob-Name für die Geräte-ID
gps-sensorgps-sensor/a9487ac2-b9cf-11eb-b5cd-1e00621e3648.jsonlauten. -
Fügen Sie den folgenden Code darunter hinzu:
container_client = get_or_create_container('gps-data') blob = container_client.get_blob_client(blob_name)Dieser Code ruft den Container-Client mithilfe der Hilfsklasse
get_or_create_containerab und erhält dann ein Blob-Client-Objekt mithilfe des Blob-Namens. Diese Blob-Clients können sich auf vorhandene Blobs beziehen oder, wie in diesem Fall, auf neue Blobs. -
Fügen Sie den folgenden Code danach hinzu:
event_body = json.loads(event.get_body().decode('utf-8')) blob_body = { 'device_id' : device_id, 'timestamp' : event.iothub_metadata['enqueuedtime'], 'gps': event_body['gps'] }Dies erstellt den Inhalt des Blobs, der in den Blob-Speicher geschrieben wird. Es handelt sich um ein JSON-Dokument, das die Geräte-ID, die Zeit, zu der die Telemetrie an den IoT-Hub gesendet wurde, und die GPS-Koordinaten aus der Telemetrie enthält.
💁 Es ist wichtig, die Zeit zu verwenden, zu der die Nachricht in die Warteschlange gestellt wurde, anstatt die aktuelle Zeit, um die Zeit zu erhalten, zu der die Nachricht gesendet wurde. Sie könnte eine Weile im Hub liegen, bevor sie abgeholt wird, wenn die Functions-App nicht läuft.
-
Fügen Sie den folgenden Code darunter hinzu:
logging.info(f'Writing blob to {blob_name} - {blob_body}') blob.upload_blob(json.dumps(blob_body).encode('utf-8'))Dieser Code protokolliert, dass ein Blob mit seinen Details geschrieben wird, und lädt dann den Blob-Inhalt als Inhalt des neuen Blobs hoch.
-
Führen Sie die Functions-App aus. Sie werden sehen, dass Blobs für alle GPS-Ereignisse in der Ausgabe geschrieben werden:
[2021-05-21T01:31:14.325Z] Python EventHub trigger processed an event: {"gps": {"lat": 47.73092, "lon": -122.26206}} ... [2021-05-21T01:31:14.351Z] Writing blob to gps-sensor/4b6089fe-ba8d-11eb-bc7b-1e00621e3648.json - {'device_id': 'gps-sensor', 'timestamp': '2021-05-21T00:57:53.878Z', 'gps': {'lat': 47.73092, 'lon': -122.26206}}💁 Stellen Sie sicher, dass Sie den IoT-Hub-Ereignismonitor nicht gleichzeitig ausführen.
💁 Sie finden diesen Code im Ordner code/functions.
Aufgabe - Überprüfen Sie die hochgeladenen Blobs
-
Um die erstellten Blobs anzuzeigen, können Sie entweder den Azure Storage Explorer, ein kostenloses Tool, mit dem Sie Ihre Storage-Konten anzeigen und verwalten können, oder die CLI verwenden.
-
Um die CLI zu verwenden, benötigen Sie zunächst einen Kontoschlüssel. Führen Sie den folgenden Befehl aus, um diesen Schlüssel zu erhalten:
az storage account keys list --output table \ --account-name <storage_name>Ersetzen Sie
<storage_name>durch den Namen des Storage-Kontos.Kopieren Sie den Wert von
key1. -
Führen Sie den folgenden Befehl aus, um die Blobs im Container aufzulisten:
az storage blob list --container-name gps-data \ --output table \ --account-name <storage_name> \ --account-key <key1>Ersetzen Sie
<storage_name>durch den Namen des Storage-Kontos und<key1>durch den Wert vonkey1, den Sie im letzten Schritt kopiert haben.Dies listet alle Blobs im Container auf:
Name Blob Type Blob Tier Length Content Type Last Modified Snapshot ---------------------------------------------------- ----------- ----------- -------- ------------------------ ------------------------- ---------- gps-sensor/1810d55e-b9cf-11eb-9f5b-1e00621e3648.json BlockBlob Hot 45 application/octet-stream 2021-05-21T00:54:27+00:00 gps-sensor/18293e46-b9cf-11eb-9f5b-1e00621e3648.json BlockBlob Hot 45 application/octet-stream 2021-05-21T00:54:28+00:00 gps-sensor/1844549c-b9cf-11eb-9f5b-1e00621e3648.json BlockBlob Hot 45 application/octet-stream 2021-05-21T00:54:28+00:00 gps-sensor/1894d714-b9cf-11eb-9f5b-1e00621e3648.json BlockBlob Hot 45 application/octet-stream 2021-05-21T00:54:28+00:00 -
Laden Sie eines der Blobs mit dem folgenden Befehl herunter:
az storage blob download --container-name gps-data \ --account-name <storage_name> \ --account-key <key1> \ --name <blob_name> \ --file <file_name>Ersetzen Sie
<storage_name>durch den Namen des Storage-Kontos und<key1>durch den Wert vonkey1, den Sie im vorherigen Schritt kopiert haben.Ersetzen Sie
<blob_name>durch den vollständigen Namen aus der SpalteNameder Ausgabe des letzten Schritts, einschließlich des Ordnernamens. Ersetzen Sie<file_name>durch den Namen einer lokalen Datei, in die das Blob gespeichert werden soll.
Nach dem Herunterladen können Sie die JSON-Datei in VS Code öffnen und sehen, dass das Blob die GPS-Standortdetails enthält:
{"device_id": "gps-sensor", "timestamp": "2021-05-21T00:57:53.878Z", "gps": {"lat": 47.73092, "lon": -122.26206}} -
Aufgabe - Bereitstellen Ihrer Functions-App in der Cloud
Nachdem Ihre Functions-App funktioniert, können Sie sie in der Cloud bereitstellen.
-
Erstellen Sie eine neue Azure Functions-App, indem Sie das zuvor erstellte Storage-Konto verwenden. Nennen Sie diese beispielsweise
gps-sensor-und fügen Sie einen eindeutigen Identifikator hinzu, wie einige zufällige Wörter oder Ihren Namen.⚠️ Sie können bei Bedarf die Anleitung zum Erstellen einer Functions-App aus Projekt 2, Lektion 5 konsultieren.
-
Laden Sie die Werte
IOT_HUB_CONNECTION_STRINGundSTORAGE_CONNECTION_STRINGin die Anwendungs-Einstellungen hoch.⚠️ Sie können bei Bedarf die Anleitung zum Hochladen von Anwendungs-Einstellungen aus Projekt 2, Lektion 5 konsultieren.
-
Stellen Sie Ihre lokale Functions-App in der Cloud bereit.
⚠️ Sie können die Anweisungen zum Bereitstellen Ihrer Functions-App aus Projekt 2, Lektion 5 bei Bedarf konsultieren.
🚀 Herausforderung
GPS-Daten sind nicht perfekt genau, und die erkannten Standorte können um einige Meter abweichen, insbesondere in Tunneln und Gebieten mit hohen Gebäuden.
Überlege, wie Satellitennavigation dieses Problem lösen könnte. Welche Daten hat dein Navigationssystem, die es ermöglichen würden, bessere Vorhersagen über deinen Standort zu treffen?
Quiz nach der Vorlesung
Überprüfung & Selbststudium
- Lies über strukturierte Daten auf der Wikipedia-Seite zum Datenmodell
- Lies über semi-strukturierte Daten auf der Wikipedia-Seite zu semi-strukturierten Daten
- Lies über unstrukturierte Daten auf der Wikipedia-Seite zu unstrukturierten Daten
- Erfahre mehr über Azure Storage und die verschiedenen Speichertypen in der Azure Storage-Dokumentation
Aufgabe
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, beachten Sie bitte, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die sich aus der Nutzung dieser Übersetzung ergeben.