|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
| pi-audio.md | 4 weeks ago | |
| pi-microphone.md | 4 weeks ago | |
| pi-speech-to-text.md | 4 weeks ago | |
| virtual-device-audio.md | 4 weeks ago | |
| virtual-device-microphone.md | 4 weeks ago | |
| virtual-device-speech-to-text.md | 4 weeks ago | |
| wio-terminal-audio.md | 4 weeks ago | |
| wio-terminal-microphone.md | 4 weeks ago | |
| wio-terminal-speech-to-text.md | 4 weeks ago | |
README.md
التعرف على الكلام باستخدام جهاز إنترنت الأشياء
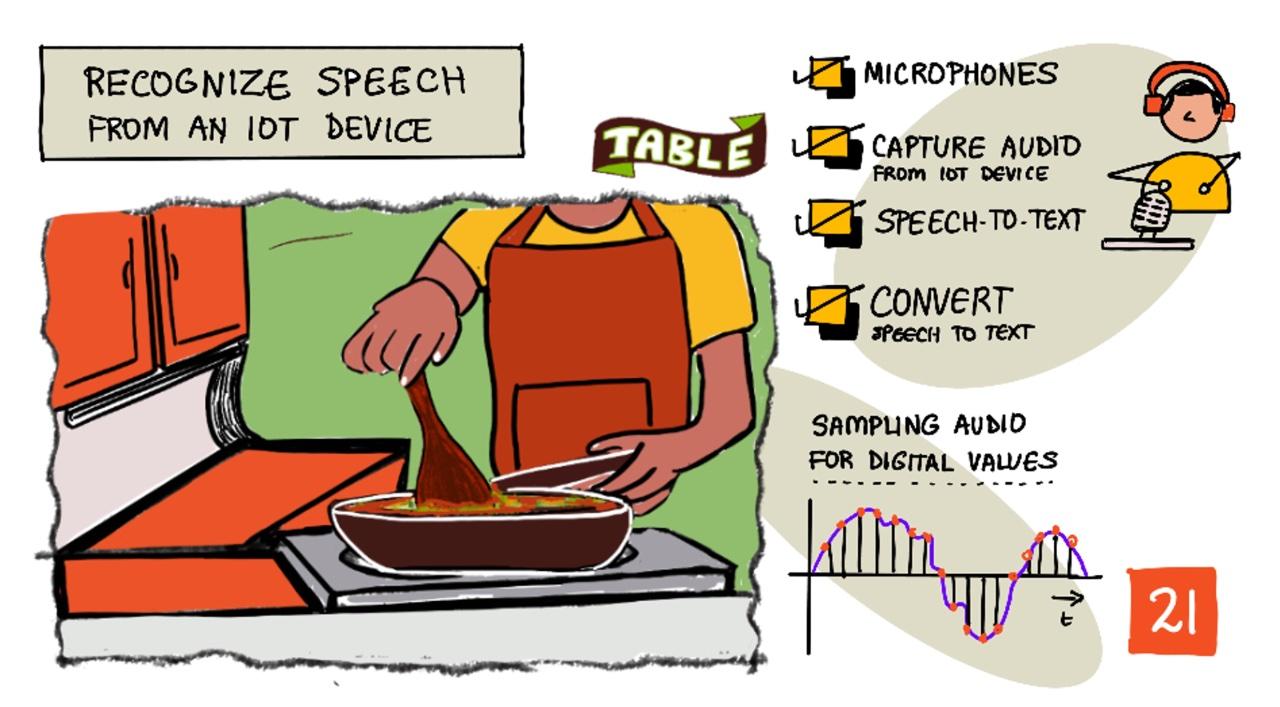
رسم توضيحي بواسطة نيتيا ناراسيمهان. اضغط على الصورة للحصول على نسخة أكبر.
يقدم هذا الفيديو نظرة عامة على خدمة الكلام في Azure، وهو موضوع سيتم تغطيته في هذا الدرس:

🎥 اضغط على الصورة أعلاه لمشاهدة الفيديو
اختبار ما قبل المحاضرة
المقدمة
"أليكسا، اضبطي مؤقت لمدة 12 دقيقة"
"أليكسا، حالة المؤقت"
"أليكسا، اضبطي مؤقت لمدة 8 دقائق باسم تبخير البروكلي"
الأجهزة الذكية أصبحت أكثر انتشارًا يومًا بعد يوم. ليس فقط كمكبرات صوت ذكية مثل HomePods وEchos وGoogle Homes، ولكن أيضًا مدمجة في هواتفنا وساعاتنا وحتى تركيبات الإضاءة وأجهزة تنظيم الحرارة.
💁 لدي على الأقل 19 جهازًا في منزلي تحتوي على مساعدات صوتية، وهذا فقط ما أعرفه!
التحكم الصوتي يزيد من إمكانية الوصول من خلال السماح للأشخاص ذوي الحركة المحدودة بالتفاعل مع الأجهزة. سواء كان ذلك بسبب إعاقة دائمة مثل الولادة بدون أذرع، أو إعاقات مؤقتة مثل كسر الذراعين، أو حتى عندما تكون يداك مشغولة بالتسوق أو رعاية الأطفال الصغار، فإن القدرة على التحكم في منازلنا باستخدام الصوت بدلاً من اليدين تفتح عالمًا من الإمكانيات. الصراخ "يا سيري، أغلق باب المرآب" أثناء التعامل مع تغيير حفاضات طفل ومواجهة طفل صغير مشاغب يمكن أن يكون تحسينًا صغيرًا ولكنه فعال في الحياة.
أحد الاستخدامات الأكثر شيوعًا للمساعدات الصوتية هو ضبط المؤقتات، خاصة مؤقتات المطبخ. القدرة على ضبط مؤقتات متعددة باستخدام صوتك فقط تعتبر مساعدة كبيرة في المطبخ - لا حاجة للتوقف عن عجن العجين، أو تحريك الحساء، أو تنظيف يديك من حشوة الزلابية لاستخدام مؤقت مادي.
في هذا الدرس، ستتعلم كيفية بناء التعرف على الصوت في أجهزة إنترنت الأشياء. ستتعلم عن الميكروفونات كأجهزة استشعار، وكيفية التقاط الصوت من ميكروفون متصل بجهاز إنترنت الأشياء، وكيفية استخدام الذكاء الاصطناعي لتحويل ما يُسمع إلى نص. خلال بقية هذا المشروع، ستقوم ببناء مؤقت مطبخ ذكي، قادر على ضبط المؤقتات باستخدام صوتك وبالعديد من اللغات.
في هذا الدرس سنغطي:
الميكروفونات
الميكروفونات هي أجهزة استشعار تناظرية تحول موجات الصوت إلى إشارات كهربائية. تسبب الاهتزازات في الهواء حركة مكونات داخل الميكروفون بمقادير صغيرة جدًا، مما يؤدي إلى تغييرات صغيرة في الإشارات الكهربائية. يتم تضخيم هذه التغييرات لتوليد إخراج كهربائي.
أنواع الميكروفونات
الميكروفونات تأتي في مجموعة متنوعة من الأنواع:
-
الديناميكية - تحتوي الميكروفونات الديناميكية على مغناطيس متصل بغشاء متحرك يتحرك داخل ملف من الأسلاك، مما يخلق تيارًا كهربائيًا. هذا عكس معظم مكبرات الصوت، التي تستخدم تيارًا كهربائيًا لتحريك مغناطيس داخل ملف من الأسلاك، مما يحرك غشاءً لإنتاج الصوت. هذا يعني أن مكبرات الصوت يمكن استخدامها كميكروفونات ديناميكية، والميكروفونات الديناميكية يمكن استخدامها كمكبرات صوت. في الأجهزة مثل أجهزة الاتصال الداخلي حيث يستمع المستخدم أو يتحدث فقط، يمكن لجهاز واحد أن يعمل كمكبر صوت وميكروفون.
الميكروفونات الديناميكية لا تحتاج إلى طاقة للعمل، حيث يتم إنشاء الإشارة الكهربائية بالكامل من الميكروفون.

-
الشريطية - الميكروفونات الشريطية تشبه الميكروفونات الديناميكية، إلا أنها تحتوي على شريط معدني بدلاً من غشاء. يتحرك هذا الشريط في مجال مغناطيسي، مما يولد تيارًا كهربائيًا. مثل الميكروفونات الديناميكية، الميكروفونات الشريطية لا تحتاج إلى طاقة للعمل.

-
المكثفة - تحتوي الميكروفونات المكثفة على غشاء معدني رقيق ولوحة خلفية معدنية ثابتة. يتم تطبيق الكهرباء على كلاهما، وعندما يهتز الغشاء، تتغير الشحنة الساكنة بين اللوحتين، مما يولد إشارة. تحتاج الميكروفونات المكثفة إلى طاقة للعمل - تُعرف باسم الطاقة الوهمية.
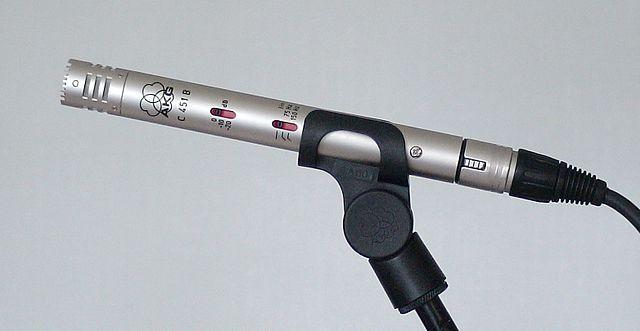
-
MEMS - أنظمة الميكروفونات الكهروميكانيكية الدقيقة، أو MEMS، هي ميكروفونات على شريحة. تحتوي على غشاء حساس للضغط محفور على شريحة سيليكون، وتعمل بشكل مشابه للميكروفون المكثف. يمكن أن تكون هذه الميكروفونات صغيرة جدًا ومتكاملة في الدوائر.

في الصورة أعلاه، الشريحة المسمى LEFT هي ميكروفون MEMS، مع غشاء صغير أقل من ملليمتر عرضًا.
✅ قم ببعض البحث: ما هي أنواع الميكروفونات الموجودة حولك - سواء في جهاز الكمبيوتر الخاص بك، هاتفك، سماعة الرأس أو في أجهزة أخرى. ما نوع هذه الميكروفونات؟
الصوت الرقمي
الصوت هو إشارة تناظرية تحمل معلومات دقيقة جدًا. لتحويل هذه الإشارة إلى رقمية، يجب أخذ عينات الصوت آلاف المرات في الثانية.
🎓 أخذ العينات هو تحويل الإشارة الصوتية إلى قيمة رقمية تمثل الإشارة في تلك اللحظة الزمنية.
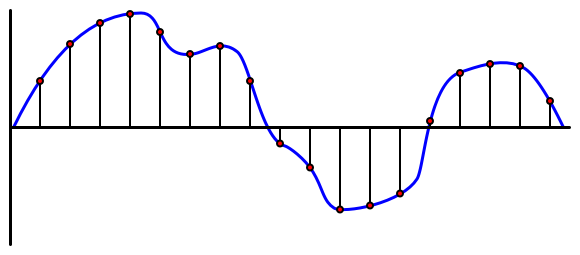
يتم أخذ عينات الصوت الرقمي باستخدام تعديل رمز النبض، أو PCM. PCM يتضمن قراءة الجهد للإشارة، واختيار أقرب قيمة منفصلة لهذا الجهد باستخدام حجم محدد.
💁 يمكنك التفكير في PCM كنسخة استشعارية من تعديل عرض النبض، أو PWM (تم تغطية PWM في الدرس الثالث من مشروع البدء). PCM يتضمن تحويل الإشارة التناظرية إلى رقمية، PWM يتضمن تحويل الإشارة الرقمية إلى تناظرية.
على سبيل المثال، تقدم معظم خدمات بث الموسيقى صوتًا بحجم 16 بت أو 24 بت. هذا يعني أنها تحول الجهد إلى قيمة تناسب عدد صحيح بحجم 16 بت، أو عدد صحيح بحجم 24 بت. الصوت بحجم 16 بت يناسب القيمة في نطاق يتراوح من -32,768 إلى 32,767، والصوت بحجم 24 بت في النطاق −8,388,608 إلى 8,388,607. كلما زاد عدد البتات، كلما اقتربت العينة مما تسمعه آذاننا بالفعل.
💁 ربما سمعت عن الصوت بحجم 8 بت، الذي يُشار إليه غالبًا باسم LoFi. هذا هو الصوت الذي يتم أخذ عيناته باستخدام 8 بت فقط، أي -128 إلى 127. كان الصوت الأول في أجهزة الكمبيوتر محدودًا بـ 8 بت بسبب قيود الأجهزة، لذا يُرى هذا غالبًا في الألعاب القديمة.
تُؤخذ هذه العينات آلاف المرات في الثانية، باستخدام معدلات أخذ عينات محددة جيدًا تُقاس بالكيلوهرتز (آلاف القراءات في الثانية). تستخدم خدمات بث الموسيقى 48 كيلوهرتز لمعظم الصوت، ولكن بعض الصوت "الخالي من الفقدان" يستخدم حتى 96 كيلوهرتز أو حتى 192 كيلوهرتز. كلما زادت معدل أخذ العينات، كلما اقترب الصوت من الأصل، إلى حد معين. هناك جدل حول ما إذا كان البشر يمكنهم التمييز فوق 48 كيلوهرتز.
✅ قم ببعض البحث: إذا كنت تستخدم خدمة بث الموسيقى، ما هو معدل أخذ العينات والحجم الذي تستخدمه؟ إذا كنت تستخدم الأقراص المدمجة، ما هو معدل أخذ العينات وحجم الصوت في الأقراص المدمجة؟
هناك عدد من التنسيقات المختلفة لبيانات الصوت. ربما سمعت عن ملفات mp3 - بيانات صوتية مضغوطة لجعلها أصغر دون فقدان أي جودة. يتم تخزين الصوت غير المضغوط غالبًا كملف WAV - هذا ملف يحتوي على 44 بايت من معلومات الرأس، يتبعها بيانات الصوت الخام. يحتوي الرأس على معلومات مثل معدل أخذ العينات (على سبيل المثال 16000 لـ 16 كيلوهرتز) وحجم العينة (16 لـ 16 بت)، وعدد القنوات. بعد الرأس، يحتوي ملف WAV على بيانات الصوت الخام.
🎓 تشير القنوات إلى عدد تدفقات الصوت المختلفة التي تشكل الصوت. على سبيل المثال، بالنسبة للصوت الاستريو مع اليسار واليمين، ستكون هناك قناتان. بالنسبة للصوت المحيطي 7.1 لنظام المسرح المنزلي، سيكون هناك 8 قنوات.
حجم بيانات الصوت
بيانات الصوت كبيرة نسبيًا. على سبيل المثال، التقاط صوت غير مضغوط بحجم 16 بت عند 16 كيلوهرتز (معدل جيد بما يكفي للاستخدام مع نموذج تحويل الكلام إلى نص)، يتطلب 32 كيلوبايت من البيانات لكل ثانية من الصوت:
- 16 بت تعني 2 بايت لكل عينة (1 بايت هو 8 بت).
- 16 كيلوهرتز تعني 16,000 عينة في الثانية.
- 16,000 × 2 بايت = 32,000 بايت في الثانية.
يبدو هذا ككمية صغيرة من البيانات، ولكن إذا كنت تستخدم متحكمًا دقيقًا بذاكرة محدودة، فقد يكون هذا كثيرًا. على سبيل المثال، يحتوي Wio Terminal على 192 كيلوبايت من الذاكرة، ويحتاج ذلك إلى تخزين كود البرنامج والمتغيرات. حتى لو كان كود البرنامج صغيرًا، لا يمكنك التقاط أكثر من 5 ثوانٍ من الصوت.
يمكن للمتحكمات الدقيقة الوصول إلى تخزين إضافي، مثل بطاقات SD أو ذاكرة الفلاش. عند بناء جهاز إنترنت الأشياء الذي يلتقط الصوت، ستحتاج إلى التأكد من أنك لا تمتلك فقط تخزينًا إضافيًا، ولكن أن الكود الخاص بك يكتب الصوت الذي تم التقاطه من الميكروفون مباشرة إلى هذا التخزين، وعند إرساله إلى السحابة، تقوم بالبث من التخزين إلى الطلب عبر الويب. بهذه الطريقة يمكنك تجنب نفاد الذاكرة عن طريق محاولة الاحتفاظ بكتلة الصوت بالكامل في الذاكرة دفعة واحدة.
التقاط الصوت من جهاز إنترنت الأشياء الخاص بك
يمكن لجهاز إنترنت الأشياء الخاص بك أن يتصل بميكروفون لالتقاط الصوت، جاهز للتحويل إلى نص. يمكن أيضًا أن يتصل بمكبرات صوت لإخراج الصوت. في الدروس اللاحقة، سيتم استخدام ذلك لتقديم ردود صوتية، ولكن من المفيد إعداد مكبرات الصوت الآن لاختبار الميكروفون.
المهمة - إعداد الميكروفون ومكبرات الصوت
قم بتنفيذ الدليل المناسب لإعداد الميكروفون ومكبرات الصوت لجهاز إنترنت الأشياء الخاص بك:
المهمة - التقاط الصوت
قم بتنفيذ الدليل المناسب لالتقاط الصوت على جهاز إنترنت الأشياء الخاص بك:
تحويل الكلام إلى نص
تحويل الكلام إلى نص، أو التعرف على الكلام، يتضمن استخدام الذكاء الاصطناعي لتحويل الكلمات في إشارة الصوت إلى نص.
نماذج التعرف على الكلام
لتحويل الكلام إلى نص، يتم تجميع العينات من إشارة الصوت وتغذيتها إلى نموذج تعلم آلي يعتمد على شبكة عصبية متكررة (RNN). هذا نوع من نماذج التعلم الآلي الذي يمكنه استخدام البيانات السابقة لاتخاذ قرار بشأن البيانات الواردة. على سبيل المثال، يمكن للشبكة العصبية المتكررة اكتشاف كتلة واحدة من عينات الصوت كصوت "Hel"، وعندما تتلقى أخرى تعتقد أنها الصوت "lo"، يمكنها دمج هذا مع الصوت السابق، وتجد أن "Hello" هي كلمة صالحة وتختارها كنتيجة.
نماذج التعلم الآلي دائمًا تقبل بيانات بنفس الحجم في كل مرة. المصنف الصوري الذي بنيته في درس سابق يقوم بتغيير حجم الصور إلى حجم ثابت ومعالجتها. نفس الشيء مع نماذج الكلام، يجب أن تعالج كتل صوتية ثابتة الحجم. يجب أن تكون نماذج الكلام قادرة على دمج نتائج توقعات متعددة للحصول على الإجابة، للسماح لها بالتمييز بين "Hi" و"Highway"، أو "flock" و"floccinaucinihilipilification".
نماذج الكلام متقدمة بما يكفي لفهم السياق، ويمكنها تصحيح الكلمات التي تكتشفها مع معالجة المزيد من الأصوات. على سبيل المثال، إذا قلت "ذهبت إلى المتاجر للحصول على موزتين وتفاحة أيضًا"، ستستخدم ثلاث كلمات تبدو متشابهة ولكن تُكتب بشكل مختلف - to، two وtoo. نماذج الكلام قادرة على فهم السياق واستخدام التهجئة المناسبة للكلمة. 💁 بعض خدمات الكلام تتيح التخصيص لجعلها تعمل بشكل أفضل في البيئات الصاخبة مثل المصانع، أو مع الكلمات الخاصة بالصناعات مثل أسماء المواد الكيميائية. يتم تدريب هذه التخصيصات من خلال تقديم عينات صوتية ونصوص مكتوبة، وتعمل باستخدام التعلم بالنقل، بنفس الطريقة التي قمت بها بتدريب مصنف الصور باستخدام عدد قليل من الصور في درس سابق.
الخصوصية
عند استخدام تحويل الكلام إلى نص في جهاز إنترنت الأشياء للمستهلكين، تكون الخصوصية ذات أهمية كبيرة. هذه الأجهزة تستمع إلى الصوت بشكل مستمر، لذلك كمستهلك لا تريد أن يتم إرسال كل ما تقوله إلى السحابة وتحويله إلى نص. ليس فقط لأن هذا سيستهلك الكثير من عرض النطاق الترددي للإنترنت، بل له أيضًا تداعيات كبيرة على الخصوصية، خاصة عندما يقوم بعض مصنعي الأجهزة الذكية باختيار عشوائي للصوت ليتم التحقق منه بواسطة البشر مقابل النص المُولد لتحسين النموذج.
تريد فقط أن يرسل جهازك الذكي الصوت إلى السحابة للمعالجة عندما تستخدمه، وليس عندما يسمع الصوت في منزلك، الصوت الذي قد يتضمن اجتماعات خاصة أو تفاعلات حميمة. الطريقة التي تعمل بها معظم الأجهزة الذكية هي باستخدام كلمة تنبيه، وهي عبارة مفتاحية مثل "أليكسا"، "هاي سيري"، أو "أوكي جوجل" التي تجعل الجهاز "يستيقظ" ويستمع لما تقوله حتى يكتشف توقفًا في كلامك، مما يشير إلى أنك انتهيت من التحدث إلى الجهاز.
🎓 يُشار إلى اكتشاف كلمة التنبيه أيضًا باسم اكتشاف الكلمات المفتاحية أو التعرف على الكلمات المفتاحية.
يتم اكتشاف كلمات التنبيه على الجهاز نفسه، وليس في السحابة. تحتوي هذه الأجهزة الذكية على نماذج ذكاء اصطناعي صغيرة تعمل على الجهاز وتستمع لكلمة التنبيه، وعندما يتم اكتشافها، تبدأ في بث الصوت إلى السحابة للتعرف عليه. هذه النماذج متخصصة جدًا، وتستمع فقط لكلمة التنبيه.
💁 بعض شركات التكنولوجيا تضيف المزيد من الخصوصية إلى أجهزتها وتقوم ببعض تحويل الكلام إلى نص على الجهاز نفسه. أعلنت شركة آبل أنه كجزء من تحديثات iOS وmacOS لعام 2021، ستدعم تحويل الكلام إلى نص على الجهاز، وستكون قادرة على معالجة العديد من الطلبات دون الحاجة إلى استخدام السحابة. يعود الفضل في ذلك إلى وجود معالجات قوية في أجهزتها يمكنها تشغيل نماذج التعلم الآلي.
✅ ما رأيك في التداعيات الأخلاقية والخصوصية لتخزين الصوت المُرسل إلى السحابة؟ هل يجب تخزين هذا الصوت، وإذا كان الأمر كذلك، كيف؟ هل تعتقد أن استخدام التسجيلات لأغراض إنفاذ القانون هو مقايضة جيدة مقابل فقدان الخصوصية؟
عادةً ما يستخدم اكتشاف كلمة التنبيه تقنية تُعرف باسم TinyML، وهي تحويل نماذج التعلم الآلي لتكون قادرة على العمل على المتحكمات الدقيقة. هذه النماذج صغيرة الحجم وتستهلك طاقة قليلة جدًا للتشغيل.
لتجنب تعقيد تدريب واستخدام نموذج كلمة التنبيه، فإن المؤقت الذكي الذي تقوم ببنائه في هذا الدرس سيستخدم زرًا لتشغيل التعرف على الكلام.
💁 إذا كنت ترغب في تجربة إنشاء نموذج اكتشاف كلمة التنبيه ليعمل على Wio Terminal أو Raspberry Pi، تحقق من هذا الدرس حول الاستجابة لصوتك بواسطة Edge Impulse. إذا كنت ترغب في استخدام جهاز الكمبيوتر الخاص بك للقيام بذلك، يمكنك تجربة البدء باستخدام دليل الكلمات المفتاحية المخصص على مستندات Microsoft.
تحويل الكلام إلى نص
![]()
تمامًا كما هو الحال مع تصنيف الصور في مشروع سابق، هناك خدمات ذكاء اصطناعي مُعدة مسبقًا يمكنها أخذ الكلام كملف صوتي وتحويله إلى نص. إحدى هذه الخدمات هي خدمة الكلام، وهي جزء من خدمات الإدراك، خدمات الذكاء الاصطناعي المُعدة مسبقًا التي يمكنك استخدامها في تطبيقاتك.
المهمة - إعداد مورد ذكاء اصطناعي للكلام
-
قم بإنشاء مجموعة موارد لهذا المشروع باسم
smart-timer. -
استخدم الأمر التالي لإنشاء مورد كلام مجاني:
az cognitiveservices account create --name smart-timer \ --resource-group smart-timer \ --kind SpeechServices \ --sku F0 \ --yes \ --location <location>استبدل
<location>بالموقع الذي استخدمته عند إنشاء مجموعة الموارد. -
ستحتاج إلى مفتاح API للوصول إلى مورد الكلام من الكود الخاص بك. قم بتشغيل الأمر التالي للحصول على المفتاح:
az cognitiveservices account keys list --name smart-timer \ --resource-group smart-timer \ --output tableقم بنسخ أحد المفاتيح.
المهمة - تحويل الكلام إلى نص
اعمل من خلال الدليل المناسب لتحويل الكلام إلى نص على جهاز إنترنت الأشياء الخاص بك:
🚀 التحدي
التعرف على الكلام موجود منذ فترة طويلة، وهو يتحسن باستمرار. قم بالبحث حول القدرات الحالية وقارن كيف تطورت هذه القدرات بمرور الوقت، بما في ذلك مدى دقة النصوص المُحولة بواسطة الآلة مقارنة بالنصوص البشرية.
ما الذي تعتقد أن المستقبل يحمله للتعرف على الكلام؟
اختبار ما بعد المحاضرة
المراجعة والدراسة الذاتية
- اقرأ عن الأنواع المختلفة من الميكروفونات وكيف تعمل في مقالة الفرق بين الميكروفونات الديناميكية والمكثفة على Musician's HQ.
- اقرأ المزيد عن خدمة الكلام في خدمات الإدراك في وثائق خدمة الكلام على مستندات Microsoft.
- اقرأ عن اكتشاف الكلمات المفتاحية في وثائق التعرف على الكلمات المفتاحية على مستندات Microsoft.
الواجب
إخلاء المسؤولية:
تم ترجمة هذا المستند باستخدام خدمة الترجمة بالذكاء الاصطناعي Co-op Translator. بينما نسعى لتحقيق الدقة، يرجى العلم أن الترجمات الآلية قد تحتوي على أخطاء أو معلومات غير دقيقة. يجب اعتبار المستند الأصلي بلغته الأصلية المصدر الرسمي. للحصول على معلومات حاسمة، يُوصى بالاستعانة بترجمة بشرية احترافية. نحن غير مسؤولين عن أي سوء فهم أو تفسيرات خاطئة ناتجة عن استخدام هذه الترجمة.