|
|
2 years ago | |
|---|---|---|
| .. | ||
| README.ko.md | 2 years ago | |
| assignment.hi.md | 3 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.ne.md | 3 years ago | |
README.ko.md
데이터 과학의 라이프 사이클: 분석하기
 |
|---|
| 데이터 과학의 라이프 사이클: 분석하기 - Sketchnote by @nitya |
강의 전 퀴즈
강의 전 퀴즈
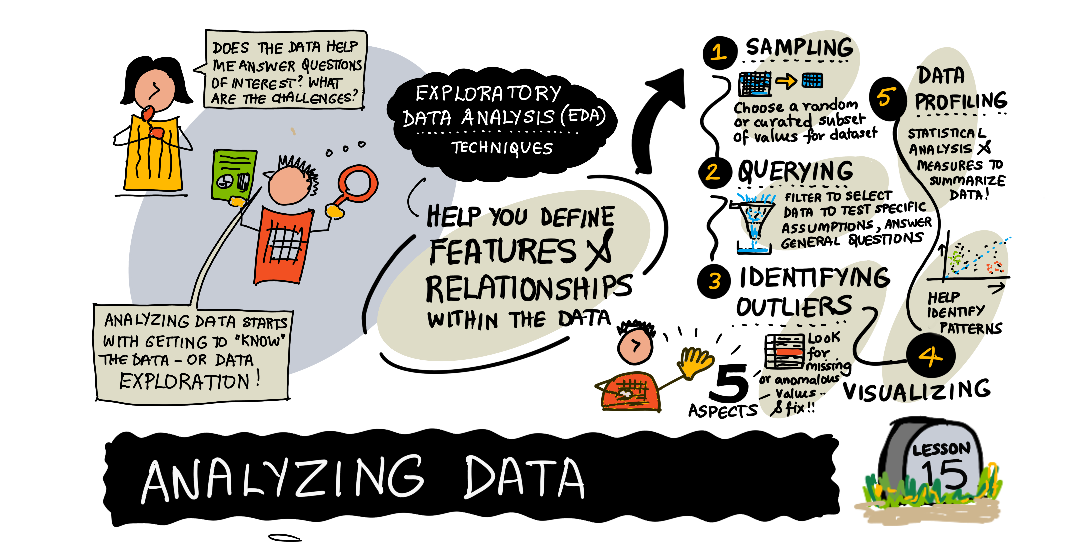
데이터의 라이프사이클을 분석하면 데이터가 제안된 질문에 답하거나 특정 문제를 해결할 수 있음을 확인할 수 있습니다. 또한 이 단계는 모델이 이러한 질문과 문제를 올바르게 해결하는지 확인하는 데 초점을 맞출 수 있습니다. 이 과정에서는 데이터 내의 특징과 관계를 정의하는 기술이며 모델링을 위한 데이터를 준비하는 데 사용할 수 있는 탐색 데이터 분석(Exploratory Data Analysis) 또는 EDA에 초점을 맞춥니다.
Kaggle의 예제 데이터셋을 사용하여 파이썬 및 Pandas 라이브러리에 어떻게 적용할 수 있는지 보여드리겠습니다. 이 데이터셋에는 이메일에서 발견되는 몇 가지 일반적인 단어가 포함되어 있으며 이러한 이메일의 출처는 익명입니다. 이전 디렉터리에 있는 노트북을 사용하여 계속 진행하십시오.
탐색 데이터 분석
라이프사이클의 캡처 단계는 데이터를 획득하는 단계이며 당면한 문제와 질문입니다. 하지만 데이터가 최종 결과를 지원하는 데 도움이 될 수 있는지 어떻게 알 수 있을까요? 데이터 과학자는 데이터를 획득할 때 다음과 같은 질문을 할 수 있습니다.
- 이 문제를 해결할 데이터가 충분한가요?
- 이 문제에 적합한 품질의 데이터입니까?
- 이 데이터를 통해 추가 정보를 발견하게 되면 목표를 바꾸거나 재정의하는 것을 고려해야 하나요? 탐색적 데이터 분석은 데이터를 파악하는 프로세스이며, 이러한 질문에 답하는 데 사용할 수 있을 뿐만 아니라 데이터셋으로 작업하는 데 따른 당면 과제를 파악할 수 있습니다. 이를 달성하기 위해 사용되는 몇 가지 기술에 초점을 맞춰보겠습니다.
데이터 프로파일링, 기술 통계 및 Pandas
이 문제를 해결하기에 충분한 데이터가 있는지 어떻게 평가합니까? 데이터 프로파일링은 기술 통계 기법을 통해 데이터셋에 대한 일반적인 전체 정보를 요약하고 수집할 수 있습니다. 데이터 프로파일링은 우리가 사용할 수 있는 것을 이해하는 데 도움이 되며 기술 통계는 우리가 사용할 수 있는 것이 얼마나 많은지 이해하는 데 도움이 됩니다.
이전 강의에서 우리는 Pandas를 사용하여 [describe() 함수]와 함께 기술 통계를 제공했습니다. 숫자 데이터에 대한 카운트, 최대값 및 최소값, 평균, 표준 편차 및 분위수를 제공합니다. describe() 함수와 같은 기술 통계를 사용하면 얼마나 가지고 있고 더 필요한지를 평가하는 데 도움이 될 수 있습니다.
샘플링 및 쿼리
대규모 데이터셋의 모든 것을 탐색하는 것은 매우 많은 시간이 걸릴 수 있으며 일반적으로 컴퓨터가 수행해야 하는 작업입니다. 그러나 샘플링은 데이터를 이해하는 데 유용한 도구이며 데이터 집합에 무엇이 있고 무엇을 나타내는지를 더 잘 이해할 수 있도록 해줍니다. 표본을 사용하여 확률과 통계량을 적용하여 데이터에 대한 일반적인 결론을 내릴 수 있습니다. 표본 추출하는 데이터의 양에 대한 규칙은 정의되어 있지 않지만, 표본 추출하는 데이터의 양이 많을수록 데이터에 대한 일반화의 정확성을 높일 수 있다는 점에 유의해야 합니다.
Pandas에는 받거나 사용하려는 임의의 샘플 수에 대한 아규먼트를 전달할 수 있는 라이브러리 속 함수sample()이 있습니다.
데이터에 대한 일반적인 쿼리는 몇 가지 일반적인 질문과 이론에 답하는 데 도움이 될 수 있습니다. 샘플링과 달리 쿼리를 사용하면 질문이 있는 데이터의 특정 부분을 제어하고 집중할 수 있습니다.
Pandas 라이브러리의 query() 함수를 사용하면 열을 선택하고 간단한 검색된 행을 통해 데이터에 대한 답변을 제공받을 수 있습니다.
시각화를 통한 탐색
시각화 생성을 시작하기 위해 데이터가 완전히 정리되고 분석될 때까지 기다릴 필요가 없습니다. 실제로 탐색하는 동안 시각적 표현이 있으면 데이터의 패턴, 관계 및 문제를 식별하는 데 도움이 될 수 있습니다. 또한, 시각화는 데이터 관리에 관여하지 않는 사람들과 의사 소통하는 수단을 제공하고 캡처 단계에서 해결되지 않은 추가 질문을 공유하고 명확히 할 수 있는 기회가 될 수 있습니다. 시각적으로 탐색하는 몇 가지 인기 있는 방법에 대해 자세히 알아보려면 section on Visualizations을 참조하세요.
불일치 식별을 위한 탐색
이 강의의 모든 주제는 누락되거나 일치하지 않는 값을 식별하는 데 도움이 될 수 있지만 Pandas는 이러한 값 중 일부를 확인하는 기능을 제공합니다. isna() 또는 isnull()에서 결측값을 확인할 수 있습니다. 데이터 내에서 이러한 값을 탐구할 때 중요한 한 가지 요소는 처음에 이러한 값이 왜 이렇게 되었는지 이유를 탐구하는 것입니다. 이는 문제 해결을 위해 취해야 할 조치를 결정하는 데 도움이 될 수 있습니다.